




作者简介
Hans-Jürgen Schönig, 从90年代就开始使用PostgreSQL。他是CYBERTEC的首席执行官和技术主管,CYBERTEC是该领域的市场领导者之一,自2000年以来为全球无数客户提供服务。
译者简介
朱君鹏,博士研究生。主要研究方向为数据库管理系统,尤其是内存数据库、事务处理系统、软硬件协同设计、日志系统。
校对者简介
赵全明 任职于华为技术有限公司,数据库内核开发工程师,曾参与云数据库及GaussDB多个项目的研发,致力于PostgreSQL在全行业的应用与推广。
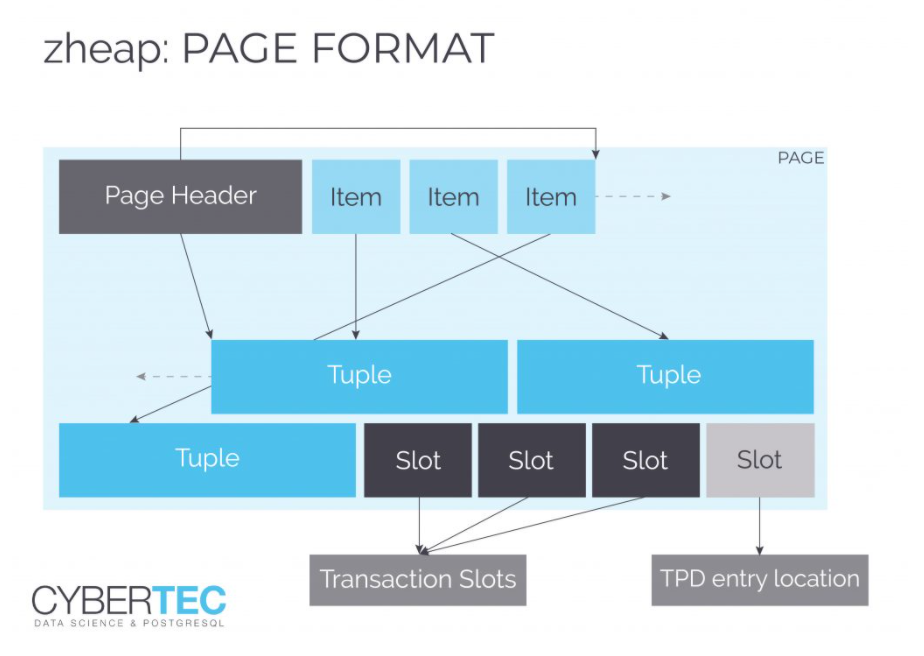
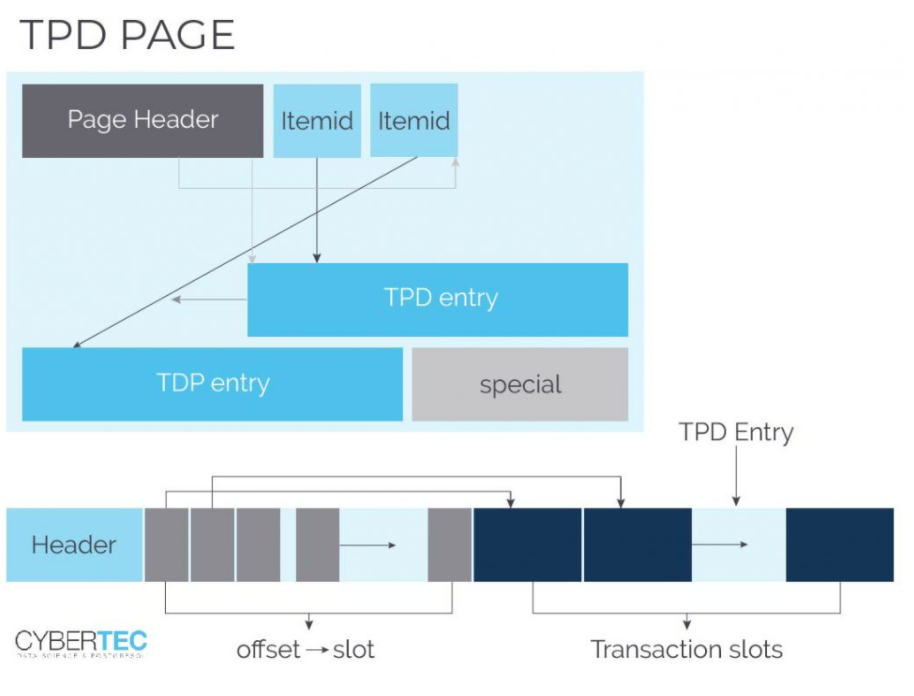
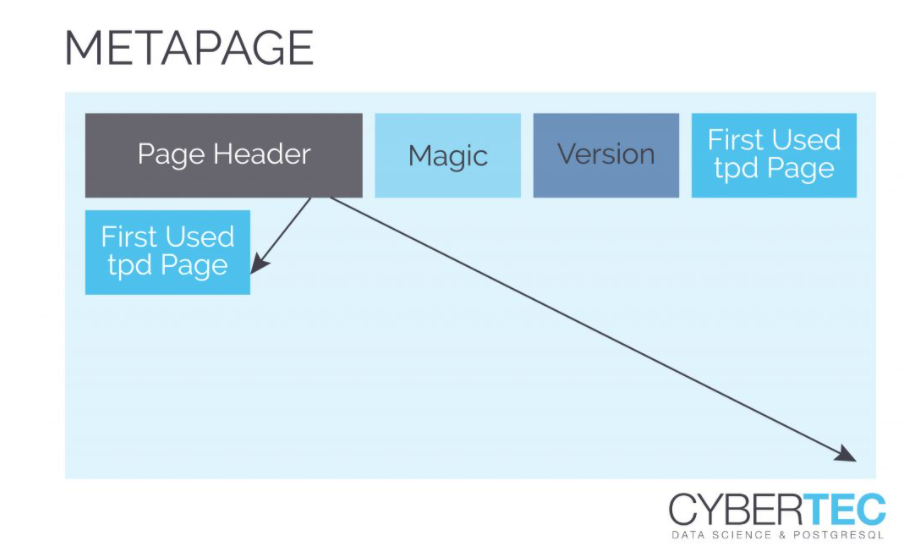
有时一个页面需要许多事务槽。TPD提供了一种灵活的方式来处理这个问题。问题是:zheap在哪里存储TPD数据?答案是:这些特殊页面与标准数据页面交交错在一起。它们只是用一种特殊的方式标记,以确保顺序扫描时不会扫描。为了跟踪这些特殊用途的页面,zheap使用一个元页面来跟踪它们:
TDP只是使事务槽更具伸缩性的一种方法。在块中设置一些槽可以减少过度触碰页面的需要。如果需要更多,那么TPD是一个很好的解决办法。在某种程度上,这是两全其美的。
当事务结束后,事务槽可以重用。
zheap:元组格式
这个难题的下一个重要部分是单个元组的布局:在PostgreSQL中,标准的堆元组有一个20+字节的头,因为所有的事务信息都存储在一个元组中。但在这个例子中并非如此。所有事务信息已经被移动到页级结构(事务槽)中。这一点超级重要:元组头因此减少到只有5个字节。但是这里还有更多的优化:标准元组必须在元组头和实际数据行之间使用CPU对齐(填充),表中每一行都需要占用一些字节。zheap没有这样做,导致存储更紧凑。通过删除按值传递数据类型的填充可以节省额外的空间。所有这些优化都意味着我们可以在表的每一行中节省宝贵的空间。
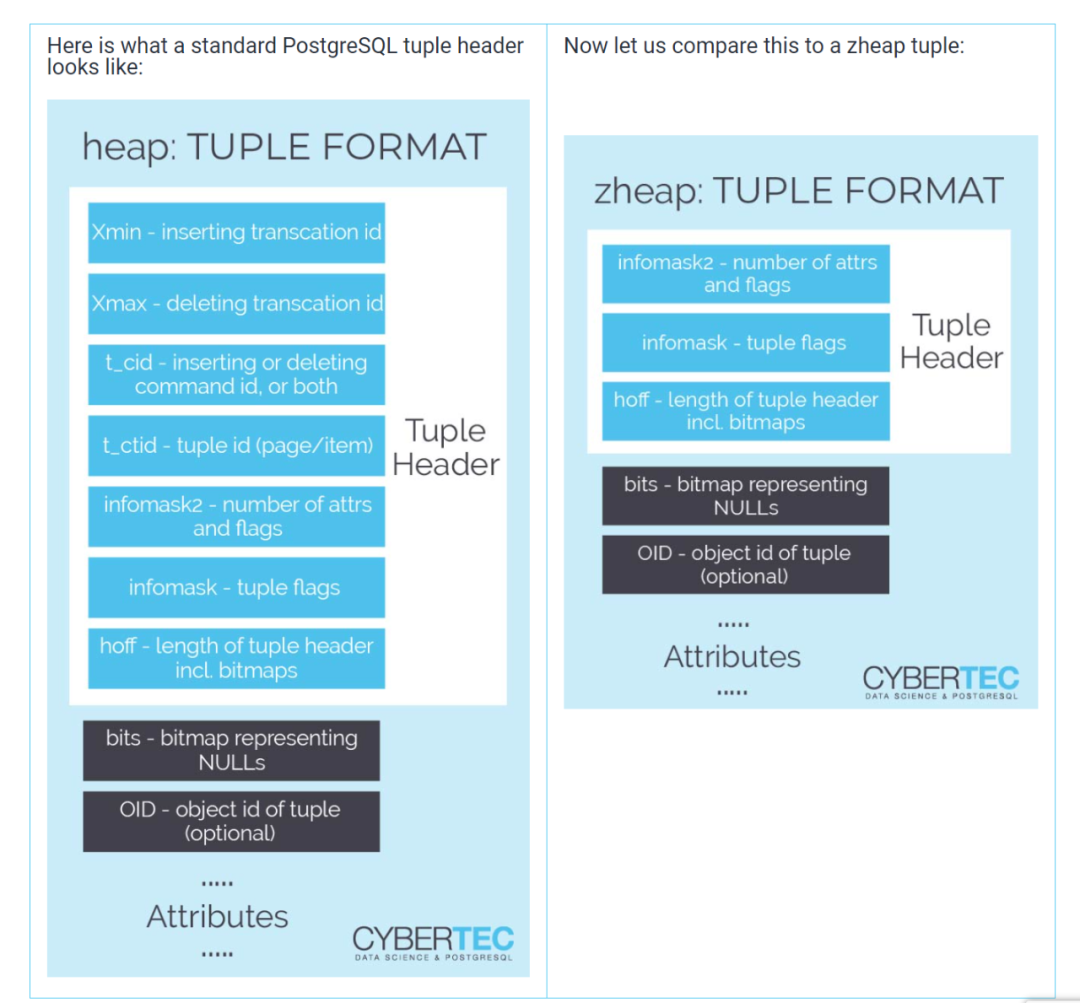
注:左半图为标准PostgreSQL元组头的布局, 右半图为zheap元组头的布局
正如您所看到的,zheap元组比普通的堆元组要小得多。由于事务信息已经统一在事务槽机制中,我们不再需要处理行级别的可见性,反而可以在页面级别更高效地进行处理。
通过缩小存储空间,zheap将有助于提高性能。
UNDO:使事情井然有序
在谈论zheap时,最重要的事情之一是“undo”的概念。首先,这件事的目的是什么?让我们来看看:考虑以下操作:

为了确保事务能够正确地操作,更新不能只是覆盖旧的值并忘记它。原因有二:首先,我们希望支持并发。当数据被修改时,许多用户仍然应该能够读取数据(译者注:MVCC特性:读不阻塞写,写不阻塞读)。其次,更新一行并不一定意味着事务会被提交。因此,我们需要有效地处理回滚。经典的PostgreSQL存储格式将简单地复制标准堆中的行,这将导致我们已经在博客中讨论过的所有膨胀相关问题。
zheap处理事情的方法有点不同: 在进行了修改的情况下,系统会写撤消信息来修复它,以防事务由于某种原因不得不中止。这适用于插入、更新和删除。让我们一个一个地看一下这些操作,看看它是如何工作的:
INSERT:添加行
在INSERT的情况下,zheap必须分配一个事务槽,然后产生一个undo条目,用来处理error的情况。在插入时,TID是undo所需要的最相关的信息。在回滚INSERT后,空间可以立即回收,这是zheap和PostgreSQL中的标准堆表的主要差异。
UPDATE:修改数据
UPDATE语句要复杂得多:基本上有两种情况:
l 新行适合旧的空间
l 新行不适合旧的空间
如果旧行比新行短,我们可以简单地覆盖它,并产生一个包含完整旧行的undo条目。简而言之:我们在zheap中保存新行,在undo中保存旧行的副本,以便在需要时将其复制回来。
如果新行不适合怎么办?在这种情况下,性能会更差,因为zheap本质上不得不执行删除/插入操作,这当然不如就地UPDATE高效。
如下的情况下,可以立即回收空间:
l 将行更新为较短版本时
l 当执行非就地更新时
DELETE:删除行
最后是删除。为了处理行的删除,zheap必须产生一个undo记录,以便在回滚时将旧行放回原地。在删除期间,必须从zheap中删除行。
UNDO和ROLLBACK
到目前为止,我们已经讨论了很多关于UNDO和ROLLBACK的内容。但是,让我们再深入一点,看看UNDO、ROLLBACK等等是如何交互的。
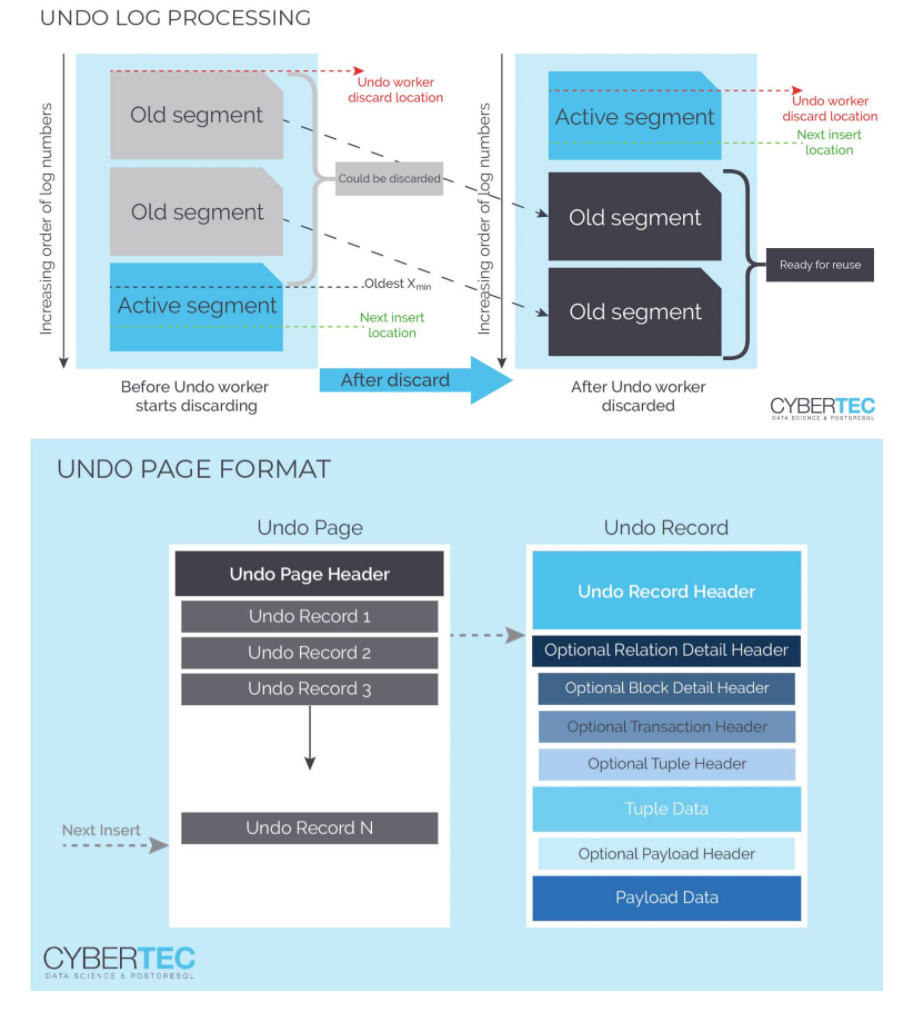
如果发生ROLLBACK,UNDO必须确保恢复表的旧状态。因此,我们之前计划的UNDO操作必须执行。在出现错误的情况下,UNDO操作将作为新事务的一部分来执行,以确保成功。
理想情况下,与单个页面相关的所有UNDO操作都是一次性来应用的,以减少必须的WAL日志数量。这种策略的一个好处是,我们可以将页面级锁定减少到绝对最小,从而减少争用,因此有助于提高性能。
到目前为止,这听起来很简单,但是让我们考虑一个重要的用例:当一个长事务发生时,会发生什么?如果必须一次回滚万亿的数据,会发生什么情况?最终用户当然不喜欢无休止的回滚。同样值得记住的是,我们还必须为回滚期间的崩溃做好准备。
如果undo操作大于某个可配置的阈值,任务将由后台工作进程完成。这是一个非常优雅的解决方案,有助于维护良好的最终用户体验。
索引:简短说明
为了确保zheap可以替代当前堆的方式,重要的是保持索引代码不变。zheap可以使用PostgreSQL的标准访问方法。当然还有办法让事情变得更有效率。但是,此时不需要对索引代码进行更改。这也意味着PostgreSQL中所有可用的索引类型仍然都是完全可用的,没有已知的限制。
最后…
目前,该技术仍处于开发阶段,我们很高兴Heroic Lab为进一步发展该技术所做的贡献。到目前为止,我们已经实现了对zheap的逻辑解码,并添加了对PostgreSQL的支持。我们将继续投入更多的资源来推动该工具,使其能够用于生产。
如果你现在想阅读更多关于PostgreSQL和VACUUM的内容,请查看我们之前关于这个主题的文章。此外,我们也想邀请您继续定期访问我们的博客,以了解更多关于信息技术和其他有趣的技术。
相关链接
https://www.cybertec-postgresql.com/en/reasons-why-vacuum-wont-remove-dead-rows/
PostgreSQL中文社区欢迎广大技术人员投稿
投稿邮箱:press@postgres.cn
