在我们对应用进行调优的过程,通过改进物理设计、使目标语句的执行计划选择代价更小的访 问路径(Access Path)来达到优化目的是一项重要手段,例如,创建新的索引、物化视图
(Materialized View)和分区(Partition)。然而,物理设计的改动,影响的范围就不仅仅是用户所面对的一、两条语句,而是系统中所有与该物理对象有关联的语句。不仅如此,由于存在维护代价 和额外的空间需求。物理设计的修改,可能会在提高某些语句的性能的同时,还会造成其它语句的
性能下降。因此,对物理设计的改动,需要综合整个应用模块或者整个应用系统进行全面分析,找 到受益语句最多、负面影响在接受范围之内的物理设计建议。
SQL 访问建议器(SQL Access Advisor)结合了查询优化器(Optimizer),通过对的结构分析、找到潜在的可以帮助语句提供性能的新的物理对象(索引、物化视图),再综合这些物理对象对工 作负载当中的其它语句的影响以及语句的重要性,对它们进行合并、位置调整或者丢弃,最终找到 一系列最理想的物理访问路径优化措施。
下面以创建索引建议为例,解释 SQL 访问建议器是如何选择新的索引,使它们对系统的性能改进帮助最大、负面影响最小。
8.5.1 建议器选择新索引分析过程
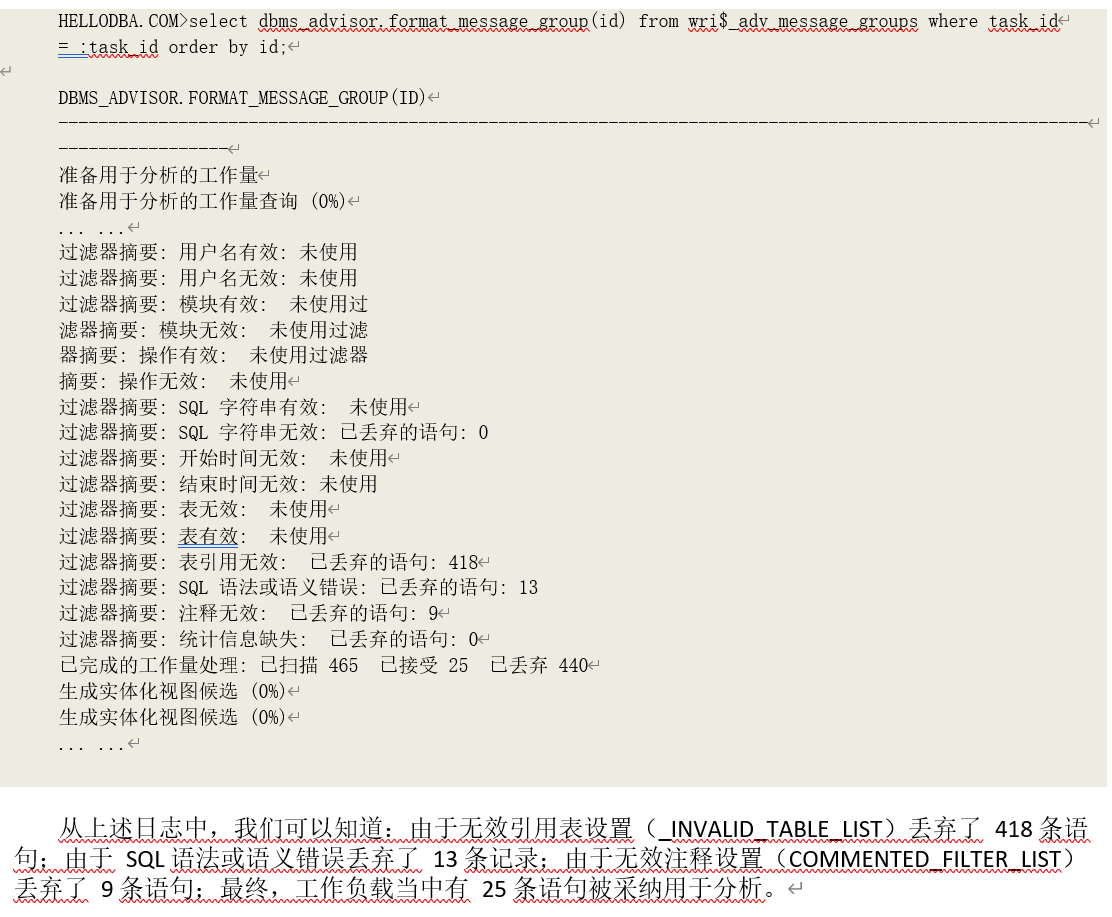
为了能全面的分析物理对象对整个模块(或者系统)的影响,分析器需要对工作负载当中的所有语句进行逐个分析。但是,如果是一个大的工作负载,包含的语句数量非常庞大,Oracle 将需要耗费大量的时间和资源完成全面分析。因此,实际上被分析的语句数量是会受到多个参数的直接或 间接影响的,例如 SQL_LIMIT。在初始化阶段,建议器要对整个工作负载进行分析,根据配置过滤语句、获得必要数据(例如语句执行计划统计数据、引用对象的统计数据等)。
语句重要性(IMPORTANCE)顺序
由某条语句分析得出新索引,也不会对所有其它语句进行交差分析,而是根据语句在工作负载当中的重要性按顺序分析语句:最重要的语句被最先分析,后续语句的分析要综合考虑前面已经被分析的语句。默认情况下,建议器会以执行计划代价(OPTIMZIER_COST)和用户自定义的优先级别
(PRIORITY)作为决定语句重要性的参考计算数据。用户也可以通过参数(ORDER_LIST)修改其计 算重要性的参照数据。
分析备选索引
在对每条语句进行分析时,建议器会调用优化器来分析语句结构,例如 WHERE 子句、关联谓词、子查询、GROUP BY 子句和 OREDER BY 子句。由这些语句结构分析可以获得备选索引。例如, 语句中存在 WHERE 条件“COL1 = a”,则可以考虑在字段 COL1 上创建索引。Oracle 同时还会为每
天备选索引生成一个临时的内存结构、并获得必须的统计数据来模拟真实索引,使得优化器在分析 语句执行计划时可以考虑到备选索引。
WHERE 子句分析
在 WHERE 子句中出现的谓词条件字段,都可能成为潜在的索引字段,并且,对于多字段组合索引来说,索引字段顺序不同,其逻辑和物理结构也不相同。如果 WHERE 子句的字段数非常多, 那么可能的潜在索引数量会非常庞大。假如某张表在 WHERE 子句中有 A、B 两个字段,那么可能的潜在索引可以是(A)、(B)、(A, B)、(B, A)。因此,当存在多个谓词条件字段时,备选索引的选择需要根据其选择率(计算方式可以参照前面章节)和关心匹配方式遵循以下一些原则:
• 先分析等于匹配的字段、再分析非等于匹配字段;
• 按照每个匹配条件的选择率由低向高分析字段,即选择性最好的字段被最先分析、加入备 选索引;
• 每增加一个字段,需要重新计算复合条件的选择率(计算方式可以参照前面章节);
• 如果存在 OR 关系,则优化器使用 UNION ALL 对语句做“或”扩张(OR Expansion),将其分为两个查询块分别分析;
并且,在满足以下条件之一时,不再像备选索引当中增加字段:
• 当增加了一个非等于匹配字段后不再增加字段;
• 当选择率达到表选择率限制(1/TABROWS,TABROWS 为表的数据记录数)时不再增加字段;
• 当达到索引字段大小限制(_MAXIDXCOLSIZE)时不再增加字段;
此外,如果存在多个非等于匹配、并且等于匹配条件的复合选择率没有达到现在,则可能会分别加入非等于匹配字段生成多个备选索引。并且,对于生成的备选索引,如果其字段接近于查询所 需要的全部字段(包括 SELECT 子句及其它子句中字段)时,例如,仅差 1 一个字段
(_IDXONLYCOLS)时,则会将剩余字段也加入备选索引,从而使得仅需要访问索引就可以获得所需 要的数据,避免对表的访问。
对于单个字段的备选索引,如果其基数(Cardinality)与表的基数的比例小于一定数值
(_BITMAPCARD)时,会将该备选索引作为一个位图索引而不是 B*Tree 索引。当然,位图索引的维护成本是比较高的,因此如果其维护成本过高————插入和删除数据的语句数占访问表语句总 数的比例超出限制值(_NOBITMAPTHRESHOLD)时————则不会为其建立位图索引。即满足以下 条件时,不建立位图索引:
(TotalDMLs(INS) + TotalDMLs(DEL))/TotalAccesses > _NOBITMAPTHRESHOLD
其中,
• TotalDMLs(INS)为向索引所在表的插入数据的语句数量;
• TotalDMLs(DEL)为删除该表数据的语句数量为;
• TotalAccesses 为需要访问该表的查询(包括增、删、改、查所有操作)数量;
关联谓词分析
进行关联操作时,数据集的关联顺序对性能的影响很重要。尽管哈希关联可以帮助两个或多个数据集的关联获得更好的性能,但它对内存资源消耗相当大。对于嵌套循环关联(Nested-Loop)来 说,数据量小的数据集更适合作为驱动数据集。索引可以帮助语句执行时,在访问对象时通过访问条件获取更下的数据集,使优化器可能选择的性能更好的嵌套循环关联方式。此外,索引的存在也可以帮助合并关联(Merge Join)避免排序操作。因此,优化器需要根据语句中的关联谓词来选择备选索引。选择方法遵循以下原则:
• 对于任何两个关联的表,分别在它们的关联字段上产生备选索引;
• 优化器在枚举多张表的关联顺序时,会考虑以及分析过的关联谓词,生成多字段复合备选 索引
GROUP BY 子句和 OREDER BY 子句分析
当语句中存在 GROUP BY 子句和 OREDER BY 子句时,需要按照子句中的字段做排序操作(10g 中,支持以哈希算法做 GROUP BY,但索引可以避免排序或哈希)。而如果子句中的字段都属于同一张表的话,在字段上面建立索引可以避免排序操作。因此,优化器同样要分析 GROUP BY 子句和OREDER BY 子句来生成备选索引。生成备选索引的原则如下:
• 如果 GROUP BY 子句或 OREDER BY 子句中的字段都属于同一张表,则在这些字段上生成一个备选索引;
• 如果两个子句同时存在,并且其中字段属于同一张表,则将 GROUP BY 中的字段按照
ORDER BY 中的字段排序来生成备选索引;
• 如果备选索引接近于查询所需要的全部字段时,将剩余字段也加入备选索引;
合并备选索引
当为一条语句分析得出一组备选索引后,需要将这些索引再次做分析,尽可能合并那些交叠的索引,从而减少索引维护成本和空间开销。要注意的时,在进行索引合并时,不仅要考虑当前语句的备选索引,还要考虑之前分析过的语句所生成的备选索引。这也说明,对于越重要的语句,会越注重物理设计改变对其的影响。在这一过程中,建议器逐个分析当前每一个备选索引,并从其它备选索引中找出几个(_IDXMRGTRIES)与其存在交叠的备选索引,按照一定方法对它们进行合并、生 成新的备选索引。
注意,无论是否生成新的合并索引,原有备选索引都会被保留,用于后续的分析。 合并的方法分为两种:结构合并和综合合并。
• 结构合并:合并后的新索引与原索引在执行计划当中的访问路径方式保持一致,并允许一 定程度的性能下降。例如,索引 IDX1(COL1, COL2)与 IDX2(COL1)可以合并成 IDXM(COL1,
COL2),使得原先访问 IDX1 和 IDX2 的执行计划可以保持访问路径方式不变访问 IDXM,但由于索引空间增加,原先访问 IDX2 的执行计划可能性能会有所下降;
• 综合合并:如果通过结构合并找不到新的合并索引,则会尝试生成会导致原有执行计划的 访问路径方式变化的新的合并索引,即综合合并;
对于生成的合并索引,还要根据其对当前语句执行计划代价的影响,最终决定是否接受。假如当前语句(未访问建议分析之前)访问该表的代价为 Cost(Old);采用了当前所有备选索引后得到的访问该表的代价为 Cost(Best);采用合并索引和的访问代价为 Cost(New)。如果合并索引的代价值与最佳代价值的差值大于一定比例(_IDXMRGCOST)的原先代价时,即:(Cost(New) - Cost(Best)) >
_IDXMRGCOST*Cost(Old)/100,那么这个合并索引则不被接受。
索引维护代价分析
在分析备选索引时,建议器要考虑到新索引对数据修改操作所带来的维护成本。如果维护成本 大于其收益,这样的备选索引则会建议器丢弃掉。由于维护代价主要来自于修改数据的操作,因此, 建议器需要从工作负载当中获得以下必须的数据:
• 对索引所在表的 INSERT、DELETE、UPDATE 和批量数据加载(Bulk Load)的 DML 执行频率, 以及这些操作所影响的数据记录数量;
• 对索引所在表的查询频率;
由这些数据,建议器可以分析出当前系统是属于一个数据仓库(Warehouse,或者决策分析系
统,DSS)类型数据库,还是在线分析处理(OLTP)类型的数据库,或者是一个混合类型的数据库。对于不同的数据库类型,会采用不同的算法计算其维护代价。实际上,大多数数据库系统都会同时 存在两种类型的特点。对于混合类型数据库,需要分别以两种算法计算其维护代价,然后乘以各自 的权重值得出综合。
两个权重值(DSSWEIGHT 和 OLTPWEIGHT)也就决定了这个数据库系统的类型。它们是 0~1 之间的小数,并且总和为 1。要计算它们的值,需要由上述数据计算得到 DSS 操作(Ratio(DSS))和
OLTP 操作(Ratio(OLTP))的比例:
Ratio(OLTP) = MIN(_OLTPTHRESHOLD, TotalDMLs/TotalAccesses) Ratio(DESS) = MIN(_DSSTHRESHOLD, BulkLoadRows/AllProcessedRows)
其中,
• TotalDMLs 为所有对该表进行数据修改(增、删、改)语句的数量,TotalDMLs = TotalDMLs(INS) + TotalDMLs(UPD) + TotalDMLs(DEL);
• TotalAccesses 为所有访问该表的语句数量(数据修改语句数量加上查询语句和数据批量载入语句的数量):TotalAccesses = TotalDMLs + TotalQueries + TotalBulkLoads
• BulkLoadRows 为该表数据批量载入的数据记录数;
• AllProcessedRows 为该表数据修改(增、删、改和数据批量载入)的数据记录数;
• _OLTPTHRESHOLD 为系统设置的 OLTP 操作的最少比例;
• _DSSTHRESHOLD 为系统设置的 DSS 操作的最少比例;
得到两种类型的操作比例后,就可以按照下面公式计算出它们各自的权重。
DSSWEIGHT = 1−(Ratio(OLTP)/_OLTPTHRESHOLD+(_DSSTHRESHOLD- Ratio(DESS))/_DSSTHRESHOLD)/2
OLTPWEIGHT = 1−(Ratio(DESS)/_DSSTHRESHOLD+(_OLTPTHRESHOLD-
Ratio(OLTP))/_OLTPTHRESHOLD)/2
按照上述公式计算出的结果为 0~1 之间(包括 0 和 1)的小数,并且它们的总和为 1: DSSWEIGHT + OLTPWEIGHT = 1−(Ratio(OLTP)/_OLTPTHRESHOLD+(_DSSTHRESHOLD-
Ratio(DESS))/_DSSTHRESHOLD)/2 +
1−(Ratio(DESS)/_DSSTHRESHOLD+(_OLTPTHRESHOLD- Ratio(OLTP))/_OLTPTHRESHOLD)/2
= 2-(Ratio(OLTP)/_OLTPTHRESHOLD+_DSSTHRESHOLD/_DSSTHRESHOLD- Ratio(DESS)/_DSSTHRESHOLD +
Ratio(DESS)/_DSSTHRESHOLD+_OLTPTHRESHOLD/_OLTPTHRESHOLD- Ratio(OLTP)/_OLTPTHRESHOLD)/2
= 2-2/2
= 1
对于混合系统,以两种类型各自的算法计算出在不同类型数据库中的索引维护代价:
MTCost(OLTP)和 MTCost(DSS),乘以权重后的综合即为其索引维护代价:
MTCost = MTCost(OLTP)*OLTPWEIGHT + MTCost(DSS)*DSSWEIGHT
当索引维护代价超过了一定比例(_MAXIDXMAINTOVERHEAD)的性能收益时,那么就认为这个 索引不可取。即,满足以下条件时,不建立索引:
MTCost/Benefit > _MAXIDXMAINTOVERHEAD
其中,
• Benefit 为使用索引的性能收益,Benefit = TotalAccesses*(Cost(Old)-Cost(New));
• Cost(Old)为原先访问表的代价;
• Cost(New)为使用索引后的访问代价;
• TotalAccesses 为需要访问该表的查询数量;
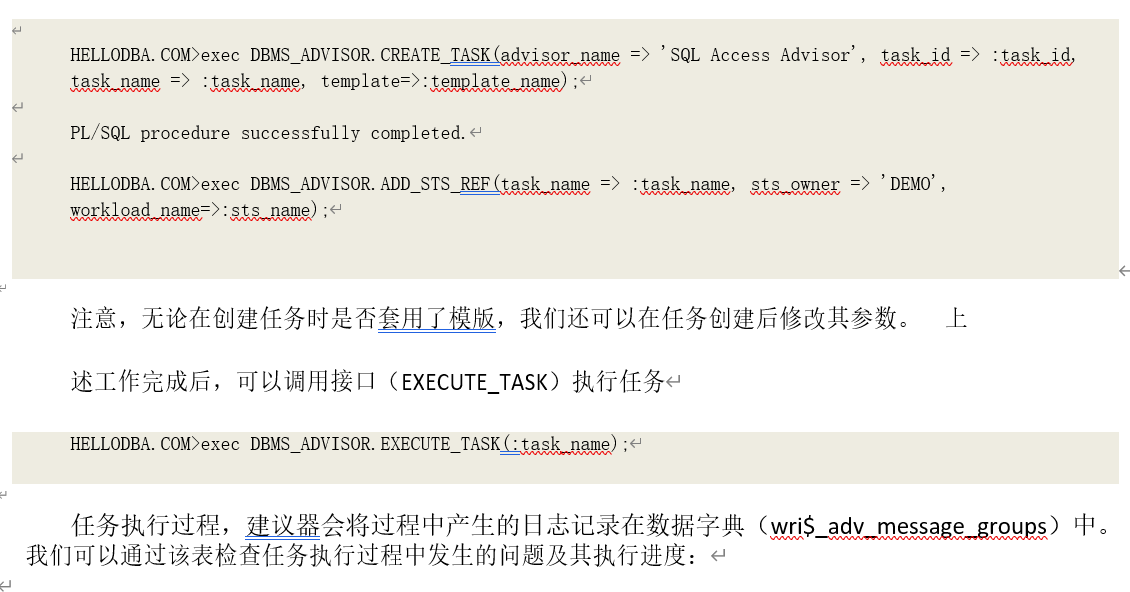
8.5.2 使用 SQL 访问建议器
使用 SQL 访问建议器的过程和方法和其他 SQL 建议器类似:创建建议任务、设置任务参数和执行任务。但是,目前没有专门接口用于 SQL 访问建议器,而是需要通过建议器的通用接口
(DBMS_ADVISOR)来完成上述操作。值得注意的是,SQL 访问建议器的参数非常多,如果系统中有多个模块需要调优,手工为每个任务修改参数的话,会需要许多额外操作。因此,可以通过设置 模版(Template)将所有参数保存下来。
创建和使用模板
创建模版和创建任务的接口是同一个接口:DBMS_ADVISOR.CREATE_TASK,需要指定参数
is_template 为 TRUE。

在 SQL 访问建议器中,系统还设置了几个预设模版,方便用户直接套用:
• SQLACCESS_GENERAL:通用模版,在调用快速调优接口(QUICK_TUNE)时,会套用该模版, 该模版的预设参数包括:
o DML_VOLATILITY:TRUE;
o EXECUTION_TYPE:FULL;
o ANALYSIS_SCOPE:ALL;
o MODE:COMPREHENSIVE;
• SQLACCESS_OLTP:用于 OLTP 系统的模版,其预设参数包括:
o DML_VOLATILITY:TRUE;
o EXECUTION_TYPE:INDEX_ONLY;
o ANALYSIS_SCOPE:INDEX;
o MODE:COMPREHENSIVE;
• SQLACCESS_WAREHOUSE:用于 Warehouse(或 DSS)系统的模版,其预设参数包括:
o DML_VOLATILITY:FALSE;
o EXECUTION_TYPE:FULL;
o ANALYSIS_SCOPE:ALL;
o MODE:COMPREHENSIVE;
• SQLACCESS_WAREHOUSE:用于 Oracle 企业管理器(OEM)任务的模版,其预设参数包括:
o DML_VOLATILITY:TRUE;
o EXECUTION_TYPE:INDEX_ONLY;
o ANALYSIS_SCOPE:INDEX;
o MODE:LIMITED;
SQL 访问建议器参数
SQL 访问建议器的参数数量非常多,在 11gR2 中,其参数(包含隐含参数)总数为 158 个。我们这里列出一些主要参数以及部分隐含参数。以下为在 11g 中有效且给出了描述的参数:
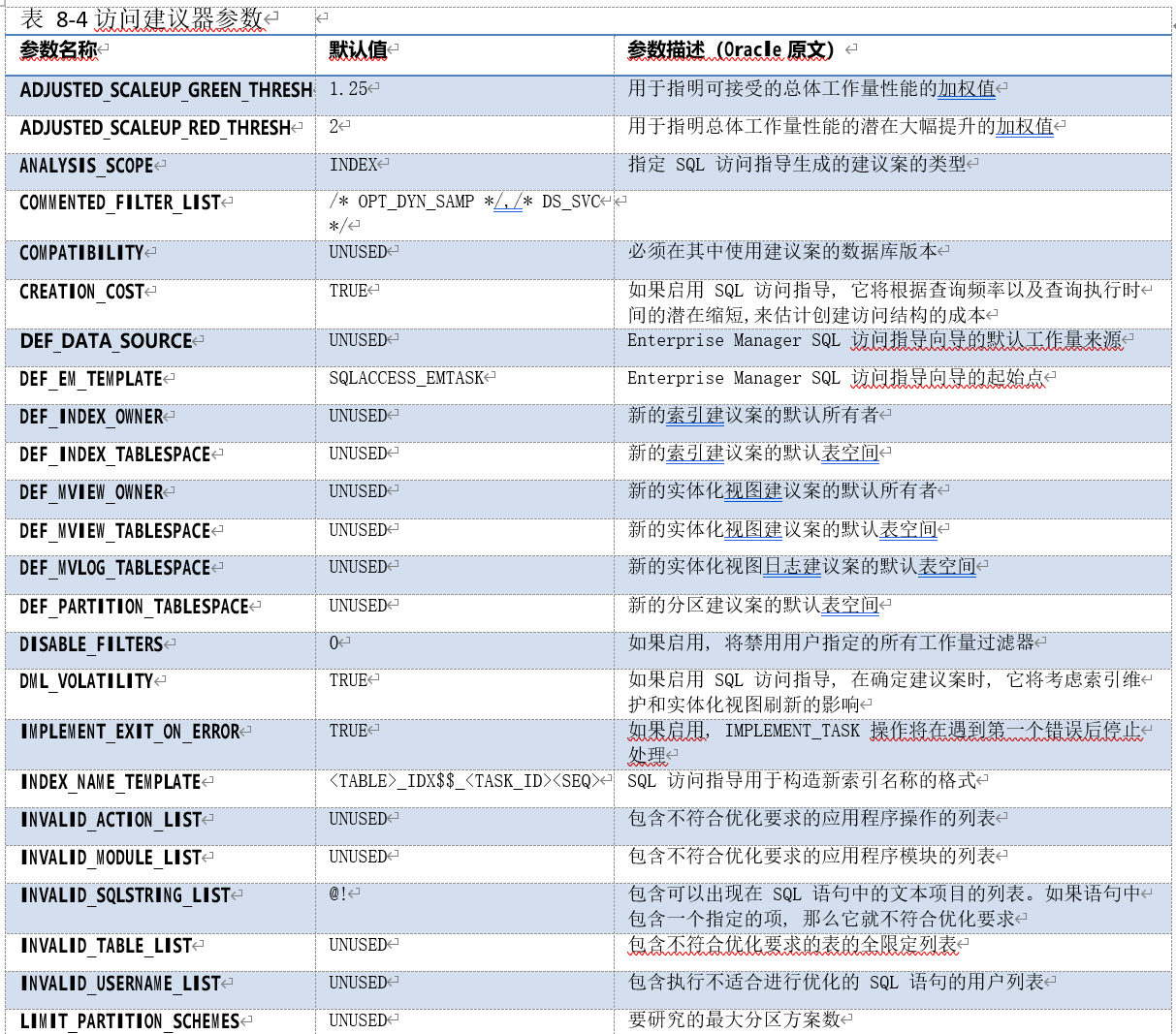

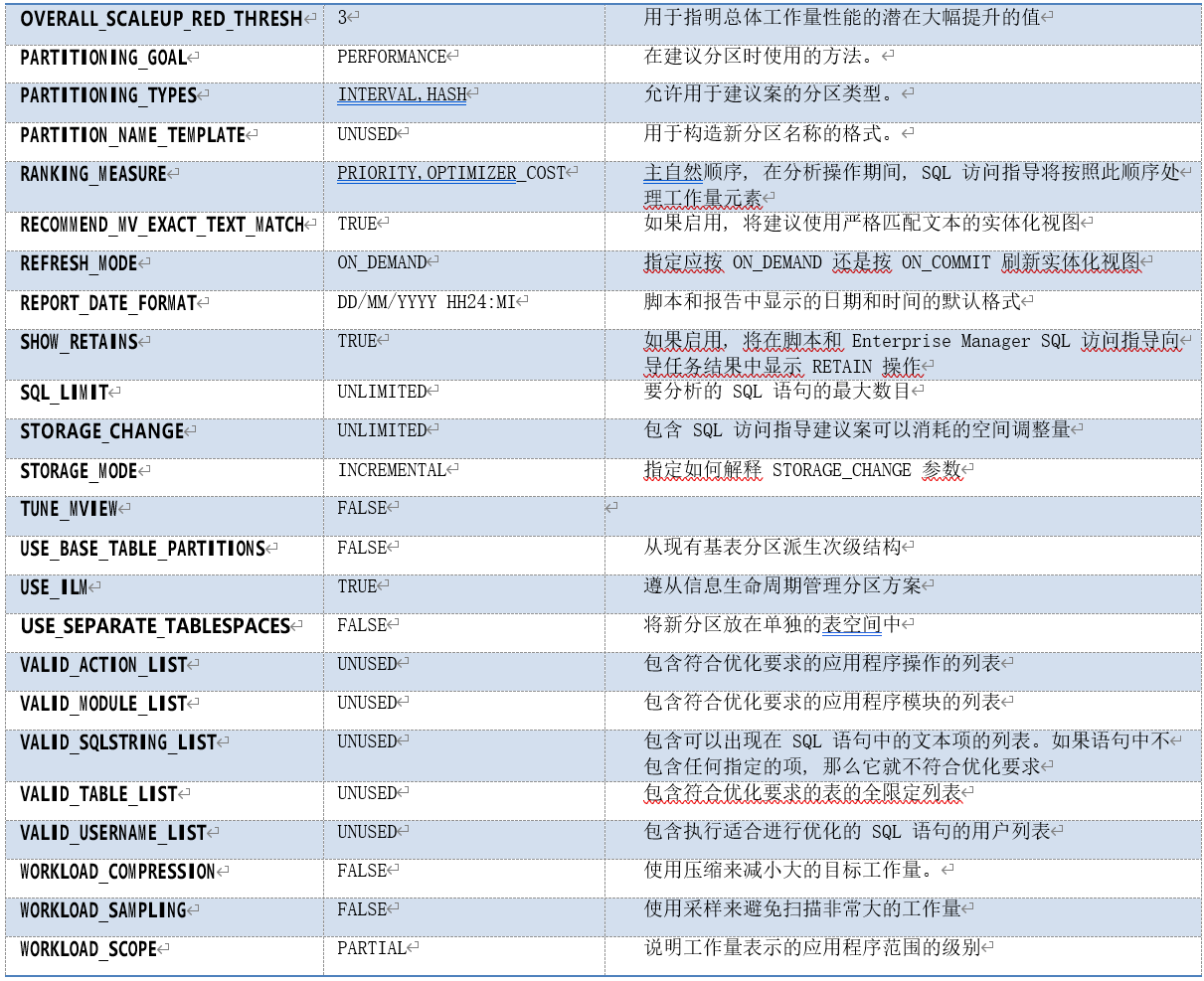
其中,
• ANALYSIS_SCOPE:分析范围,指定优化任务分析的物理对象范围。其值为“,”分割的关键 字组成的字符串,关键字包括:
o INDEX:使建议器分析索引改变对性能的影响,并给出相关优化建议;
o MVIEW:使建议器分析物化视图和日志改变对性能的影响,并给出相关优化建议;
o TABLE:使建议器分析基于表的物理设计(目前版本中,仅对分区建议有效)改变对性 能的影响,并给出相关优化建议;
o PARTITION:使建议器分析优化效果时,考虑到分区因素带来的影响,该关键字需要与 上述 3 个关键字共同使用;
o EVALUATION:使建议器仅对当前工作负载做评估,不会引入任何物理设计改变,且不 能和其它关键字共同使用;
o ALL:使建议器做全面分析,即“INDEX, MVIEW, TABLE, PARTITION”的缩写;
• COMMENTED_FILTER_LIST:注释过滤列表,由“,”分割。即语句中出现了列表中的注释时, 该语句不会被分析。该参数实际上是隐含参数“_INVALID_SQLCOMMENTS_LIST”的同义词;
• DEF_EM_TEMPLATE:由 Oracle 企业管理器(OEM)建议器向导创建的优化任务的默认模版;
• DML_VOLATILITY:建议器是否在分析过程中考虑数据管理语句导致的新索引的维护代价和 物化视图的刷新代价。
• INVALID_ACTION_LIST:指定无效操作列表,由“,”分割。即语句的操作为该列表中的项目 之一的话,该语句不会被分析。例如,如果任务的工作负载内是从 SQL 调优集获得的话, 从视图 dba_sqltune_statistics 查询到的 ACTION 的值与该设置的项目之一匹配的话,该语句不会被加载到任务的目标分析语句集当中。其它多个参数,如 INVALID_MODULE_LIST、
INVALID_SQLSTRING_LIST、INVALID_TABLE_LIST 和 INVALID_USERNAME_LIST 都其中相似的作
用;
• REFRESH_MODE:指定创建物化视图的刷新模式。当 DML_VOLATILITY 设置为’TRUE’时,该参数值会被考虑到物化视图的刷新代价的计算当中;
• ORDER_LIST:决定语句重要性的因素,用于计算重要性的参考数据,也是参数
“RANKING_MEASURE”的同义词。其值为“,”分割的关键字组成的字符串,关键字包括:
o BUFFER_GETS:缓存数据块获取次数;
o CPU_TIME:CPU 占用时间;
o DISK_READS:物理数据块读取次数;
o ELAPSED_TIME:总共消耗时间;
o EXECUTIONS:语句执行次数;
o OPTIMIZER_COST:优化器代价;
o PRIORITY:用户自定义的优先级
• VALID_ACTION_LIST:指定有效操作列表,由“,”分割。即,仅当语句的操作为该列表中的 项目之一的话,该语句才会被分析。其它多个参数,如 VALID_MODULE_LIST、
VALID_SQLSTRING_LIST、VALID_TABLE_LIST 和 VALID_USERNAME_LIST 都其中相似的作用;
以下为部分隐含参数描述,供读者参考,不建议修改:
• _BITMAPCARD:考虑建立位图索引的基数比例;
• _NOBITMAPTHRESHOLD:可以接受的位图索引上的数据维护操作比例;
• _DSSTHRESHOLD:计算 DSS 系统权重时引用的限制值;
• _DMLFREQ_PER_REFRESH:物化视图刷新间隔当中允许执行的数据管理语句数;
• _OLTPTHRESHOLD:计算 OLTP 系统权重时引用的限制值;
• _ENUM_MAX:枚举备选优化建议的最大限制数;
• _FUNCBASEDIDX:是否创建基于函数的备选索引(Function-Based Index);
• _IDXMRGCOST:合并索引时可接受的代价改变比例;
• _IDXMRGLEVEL:用于计算合并索引代价的索引层数;
• _IDXMRGSIZE:合并索引允许的最大索引记录大小;
• _IDXMRGTRIES:用于与当前索引合并的最大备选索引数量;
• _IDXONLYCOLS:将索引改变成仅由索引访问数据的访问方式时,最大允许增加的额外字段 数;
• _INDEXES_PER_TABLE:每张表允许出现的最大备选索引数;
• _MAXIDXCOLSIZE:备选索引允许的最大索引记录大小;
• _MAXIDXMAINTOVERHEAD:可以接受的索引维护代价与其收益的比例;
• _MINPERFIMPROVEMENT:可以接受的最新的性能改进比例;
创建和执行任务
调用建议器通用接口(DBMS_ADVISOR.CREATE_TASK)创建 SQL 访问建议器任务。创建任务时, 可以使用预先创建的模版为其设置参数。任务创建后,需要将现有的工作负载
(ADD_SQLWKLD_REF)或者 SQL 集(ADD_STS_REF,11g 支持)与任务关联起来。