




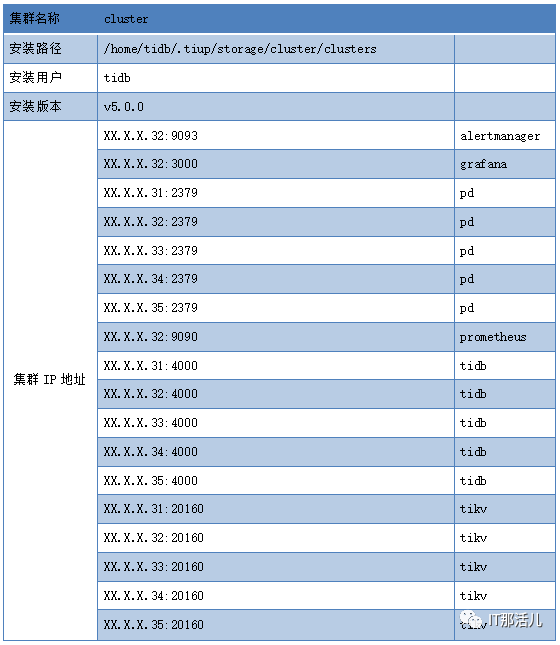
点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!


由于TiDB-server层是无状态服务,并且有Haproxy进行流量负载均衡,TiKV和PD层有Raft协议的高可用保障,停止单台服务器进行维护对整个集群运行没有太大影响,但是集群会存在有某些SQL访问、在线DDL延迟抖动的情况,总体影响不是太大。延迟抖动主要有以下原因:
存在TiKV层Leader region正好在停机维护的服务器上,从而出现Raft重新选择Leader region,业务已经在运行期间部分SQL在访问中由于找不到原Leader信息会出现Backoff的情况,从而SQL访问伴随有延迟的情况。 PD层Leader的转移类似TiKV,TiDB-server层中owner转移需重新选择新owner会对正在执行中DDL有影响。
在停单台服务器进行维护操作之前梳理DM同步到TiDB的任务,确保同步不失败。 调整max-store-down-time参数(默认30分钟,如果停机时间超过30分钟,建议调大此参数)。 Tiup正常停止该节点的TiKV、PD、TiDB实例。 服务器停机。 服务器维护。 服务器启动。 启动该节点的TiKV、PD、TiDB实例。 观察Grafana PD相关的metric信息以及Dashboard访问情况。 应用检查业务使用情况。
停TiKV组件
通常情况下,线上集群对 TiKV 的部署是单机单实例或者单机多实例,在对服务器做临时维护时,需要根据部署情况来进行相应的处理,由于现网为单机单实例只做对应的描述;在实际维护中TiKV节点下线过程中Leader region调度对集群的服务影响很小,并且Leader region调度速度也较快。
单机单实例临时关机维护步骤:
修改 max-store-down-time 超过服务器维护时间,默认 30 min,保证在服务器维护期间不发生补副本行为(需要注意维护完成后将参数恢复。)
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 config set max-store-down-time 60m //
修改为60分钟,根据实际情况而定
检查是否有 label,确保没有标签(如果存在标签需要单独分析是否为单机多实例的情况。)
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 label
检查所有服务器上store的情况,找到该服务器的对应的store id。
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 store
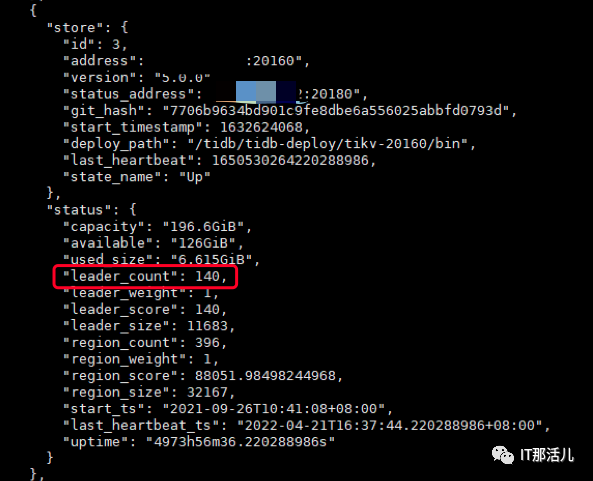
迁移该服务器上所有 store 的 leader到其他节点。
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 scheduler add evict-leader-scheduler 2 //
把 store 2 上的所有 region 的 leader 从 store 2 调度出去
检查 leader 情况:
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 store 2 //
检查该服务器所有 tikv 节点上的 leader count,leader count数量为 0 进行下一步,否则等待为0
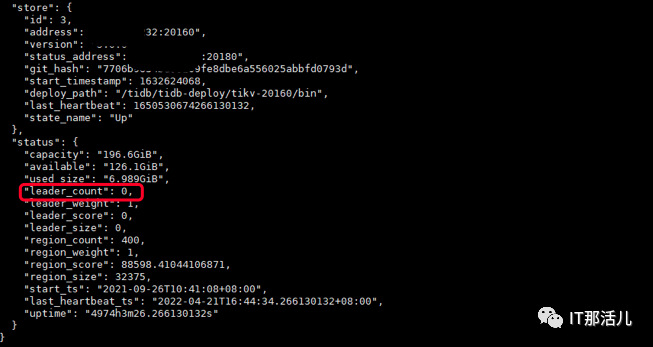
停止Tikv组件:
tiup cluster stop tidb-test -N {TiKVIP}:20160
停PD组件
通常大多数的线上集群有3 或5个PD节点,如果维护的服务器上有PD 组件,需要具体考虑节点是 leader 还是 follower(以下1 和 2 两部分),关闭 follower 对集群运行没有任何影响,关闭 leader 需要先切换,并在切换时可能存在短暂性能抖动。
1. 当前服务器包括一个 PD follower 节点且集群 PD 总数 >= 3
检查当前待操作 PD 集群节点信息:
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 member 显示当前所有成员
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 member leader show //显示当前Leader成员
停止当前待操作 PD follower 节点:
tiup cluster stop tidb-test -N {PDIP}:2379
2. 当前服务器包括一个 PD leader 节点且集群 PD 总数 >= 3
检查当前待操作 PD 集群节点信息:
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 member //显示当前所有成员
检查当前待操作 PD 节点角色:
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 member leader show //显示当前leader 的信息
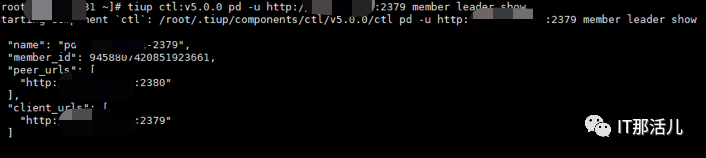
迁移 leader 节点:
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 member leader transfer pd-id // 将 leader 迁移到指定成员pd-id
检查迁移结果:
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 member leader show
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 member //显示当前所有成员,迁移成功进行下一步,否则等待
在待维护服务器上执行停PD节点:
tiup cluster stop tidb-test -N {PDIP}:2379
leader 迁回(可选):
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 member leader transfer pd-id // 将 leader 迁移到指定成员
停TiDB-server组件
1. TiDB-server实例维护
tiup cluster stop tidb-test -N {TiDBIP}:4000
在实际生产环境中,TiDB集群经常会和DM(数据同步工具)配合使用,在停单台服务器进行维护操作之前需认真梳理DM同步到TiDB的任务,如果DM工具的目标端是直接连接的TiDB-server,在停服务器维护之前需要对DM工具的Task任务进行调整,停掉DM任务连接的TiDB-server节点会导致同步任务失败。
停grafana、alertmanager、prometheus
停grafana:
tiup cluster stop tidb-test -N {grafanaIP}:3000
停alertmanager:
tiup cluster stop tidb-test -N {alertmanagerIP}:9093
停止prometheus:
tiup cluster stop tidb-test -N {prometheusIP}:9090
关停服务器前检查
检查集群状态,对应的服务器的组件是否都完全停掉。
tiup cluster display tidb-test
停服务器升级CPU和内存并重新启动。
启动服务器后检查集群状态
检查集群状态,是否都正常。
tiup cluster display tidb-test
所有节点都完成后调整参数
修改 max-store-down-time 超过服务器维护时间,默认 30 min,保证在服务器维护期间不发生补副本行为(需要注意维护完成后将参数恢复。)
tiup ctl:v5.0.0 pd -u http://{PDIP}:2379 config set max-store-down-time 30m // 默认30分钟

本文作者:陈 聪(上海新炬王翦团队)
本文来源:“IT那活儿”公众号

