我们面对的大部分系统都或多或少的存在一些健康问题,系统也不至于宕机,业务也能跑,只是用户会觉得用的不够爽,经常出现一些性能问题。这种系统在很多客户那边是当成正常系统来运维的,IT部门不会去多加关注,业务部门久而久之也就习惯了。不过如果某个处于这样状态的系统是对外提供公共服务的,那么就需要重点关注了。今天老白分享的这个案例就是这样一个Oracle数据库。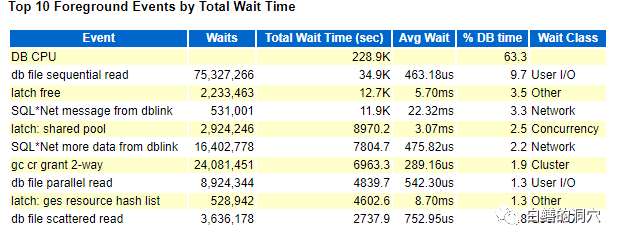
当我们看到这样一个数据库的时候,我们该如何去分析系统可能存在的问题呢?我们可能会看到db file sequential read排在前列,是不是该怀疑IO的问题呢?实际上看到平均等待时间为0.463毫秒的时候,我们就应该放弃这个想法了,这是一个使用SSD盘的系统,IO性能很强劲。后面我们还看到了latch free和shared pool的等待,是不是把问题的重点分析方向往共享池或者CURSOR方面倾斜呢?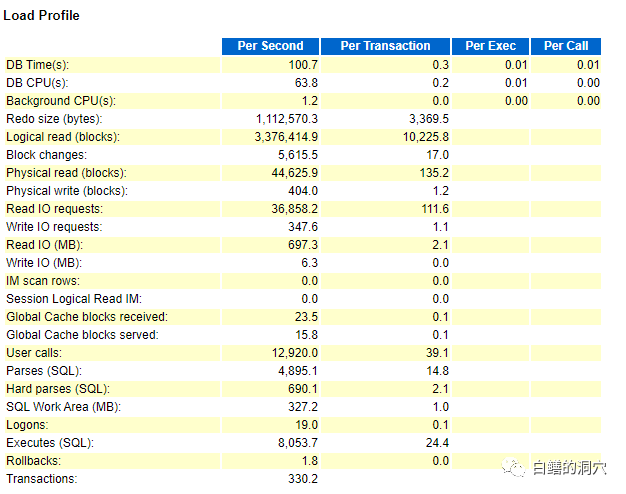
从LOAD PROFILE上看,确实硬解析比较多。可能这方面会存在问题。
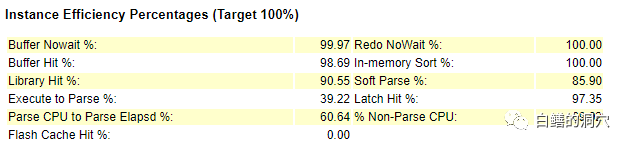
从命中率上看,我们似乎更有理由相信硬解析带来的问题是巨大的。为什么会有这样的初步判断呢?这是我们从静态的AWR数据异常上十分容易捕捉到的异常点。“人总是更多的看到他们所希望看到的东西”,于是我们会在这份AWR报告中看到更多的作证上面问题的疑点,于是分析会一步步的被带入歧途。今天老白和大家分享一种以动态发展的健康状态入手分析的方法,通过动态的趋势分析来定位对系统影响最大的因素,从而更准确的定位问题的根因。下面我们首先来看看这套系统的健康状态变化的动态趋势图。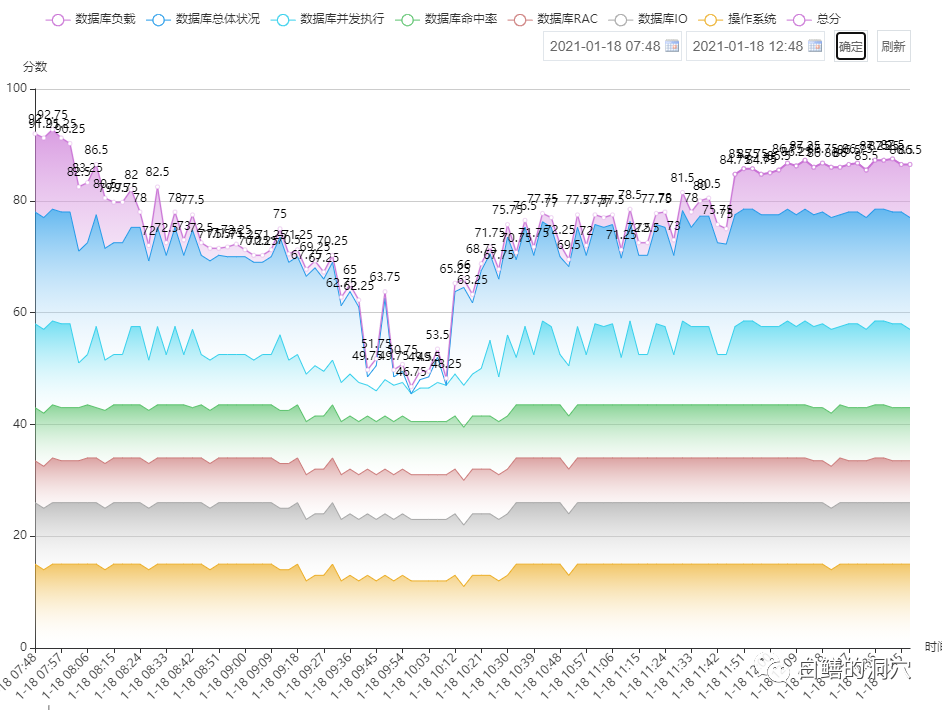
上面是一个7:48-12:48的某个数据库的健康状态图,从这张图上可以看到一个巨大的V字型。当早上用户开始多的时候,系统随着系统负载的增加,系统的健康状态就出现了一些问题,直到11点之后负载降低到一定程度,健康状态才有所好转。
对照上面的系统负载趋势我们可以看到负载与健康之间的关系,负载的增加导致了系统健康的明显下降。不过大家需要注意的是,当9:30系统负载达到最高峰之后,负载并未继续上升,但是数据库的健康状态还在持续下降。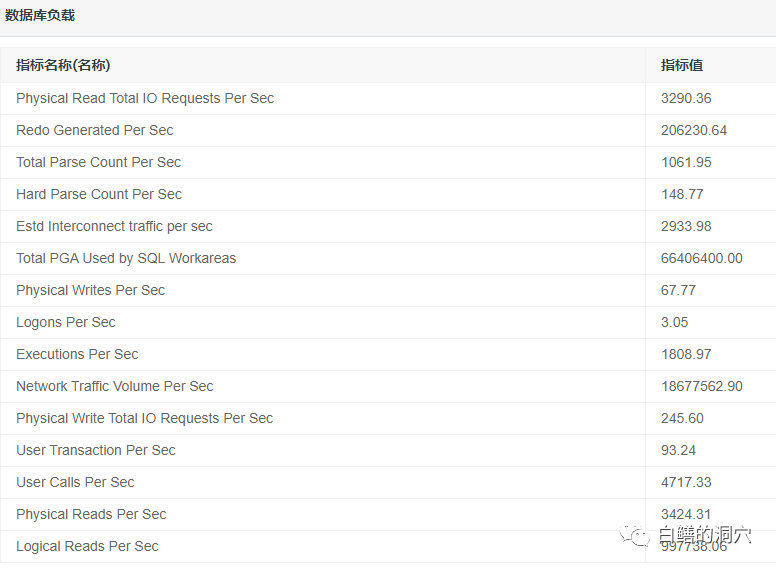
从上图可以看出,8:03的时候,系统负载已经比7:48的时候大了不少,每秒物理读3290,REDO量还不算太高,大约200K,执行数量1808,事务数93/秒,逻辑读99万+/秒。此时系统从冷状态突然变热,部分SQL的解析出现了性能问题。体现在部分和SQL解析相关的等待事件的延时增加。
不过几分钟后,负载继续在增加,但是CURSOR并发相关的指标比刚才要好一些了。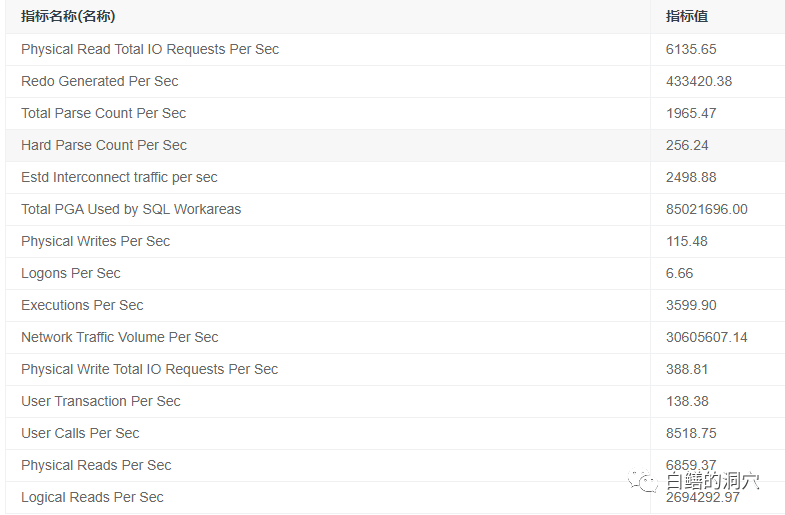
从负载数据上看,上的负载比刚才要大不少,而共享池相关的指标似乎比刚才要好一些: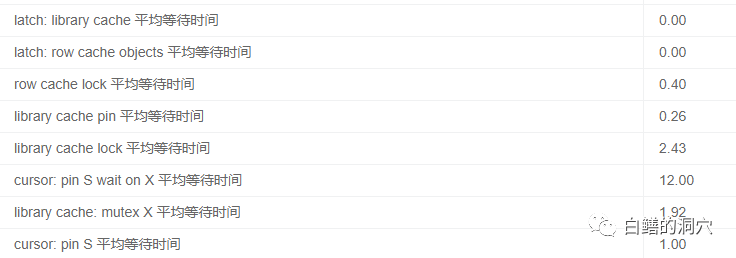
这是因为这些数据字典相关的ROW CACHE都已经加载到共享池中了。而此时系统的负载还在服务器能够承受的范围内,因此从健康总分上看,此时的健康状态还比刚才要好一些。
到9:39分的时候,系统负载已经超出了服务器最佳运行的资源负载了。每秒的逻辑读达到406万,物理读达到4万多,也就是320M每秒,因为短连接应用的存在,每秒的Logons达到了24+,这让数据库的总体健康状态雪上加霜。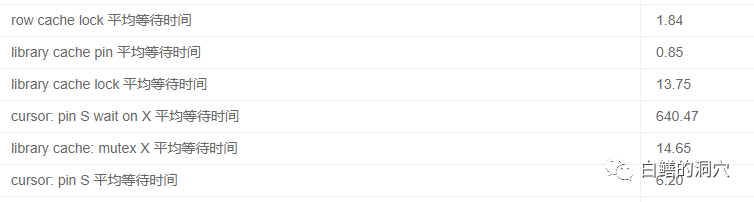
这时候平均CPU的使用率已经超过90%,但是还没有达到100%。活跃会话数量也超过了200。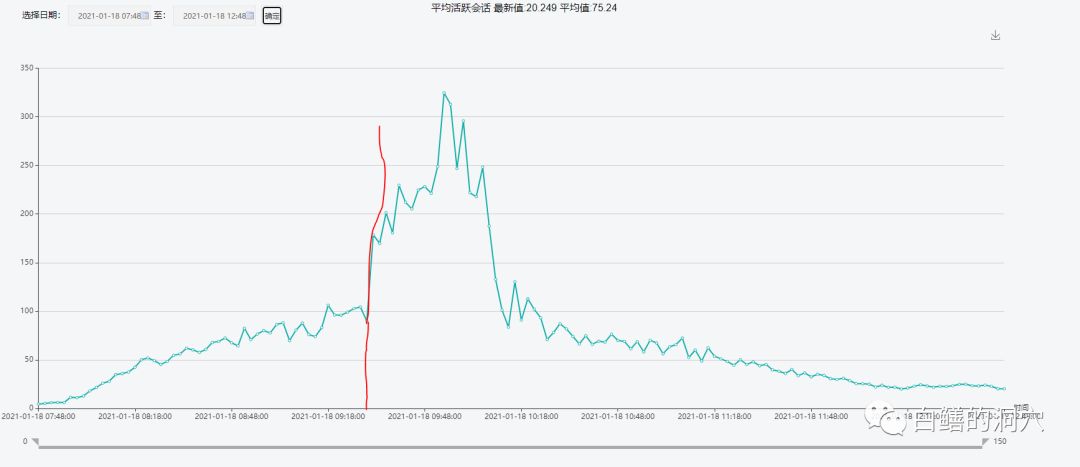
从活跃会话数的变化曲线来看,从7:48开始活跃会话数逐渐增高,刚刚开始的时候是较为平稳的增加,从9:30开始出现了剧烈增加,从不到100很快上升到200以上。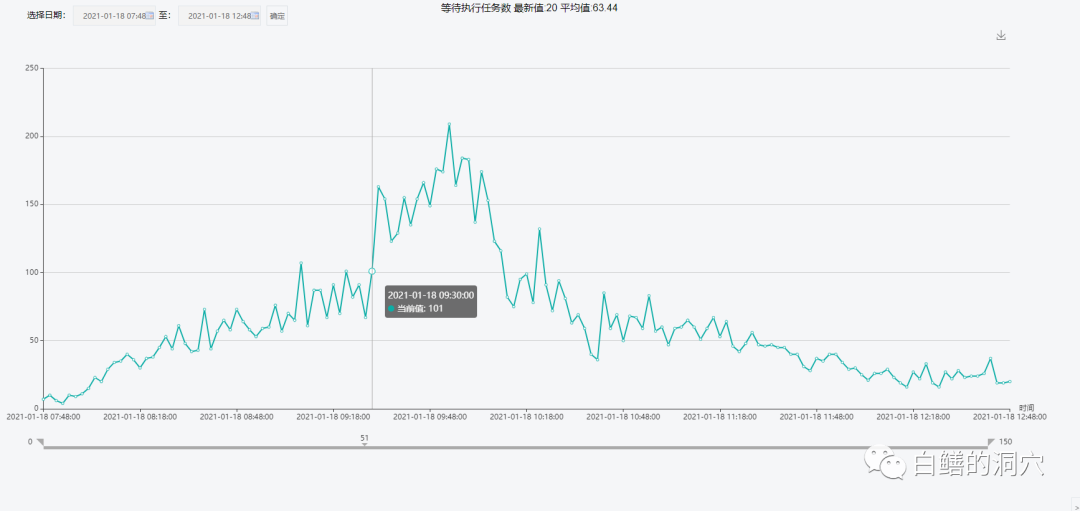
这一点和CPU的R队列的指标的曲线是基本吻合的。这个系统的服务器是一台2路18核的服务器,总共CPU线程数是72。如果R队列不超过72,则CPU资源不存在很大的瓶颈,R队列如果超过CPU线程数,则CPU调度会增大数据库各种等待的长度。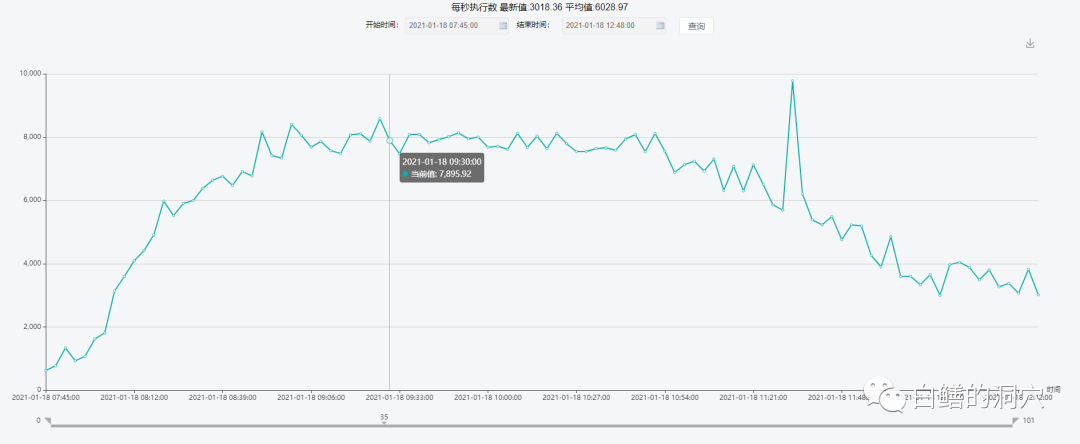
从并发执行量来看,9:30的时候的并发执行量与之间并无太大的不同。不过从前面的那个健康指标上看,9:30之后系统的总体健康出现了明显的下降。从上述情况来看,这是一个十分典型的因为资源开销过大导致系统健康与性能下降的典型案例。从下图可以看出,当系统健康状态最差的时候,正好是CPU使用率最高的时候,此时的系统总体负载反而降低了。
此时的逻辑读大小是330万+/秒,每秒执行7824。此时的CPU消耗有很大一部分消耗在LATCH SPIN上而并没有消耗在执行SQL上。针对此类问题,我们的优化策略就十分明确了,首先要降低CPU的使用,如果CPU资源降下来了,那么系统的性能,健康度都可以得到很大的提升。因此首先我们需要分析一下TOP SQL,并进行一些SQL方面的优化。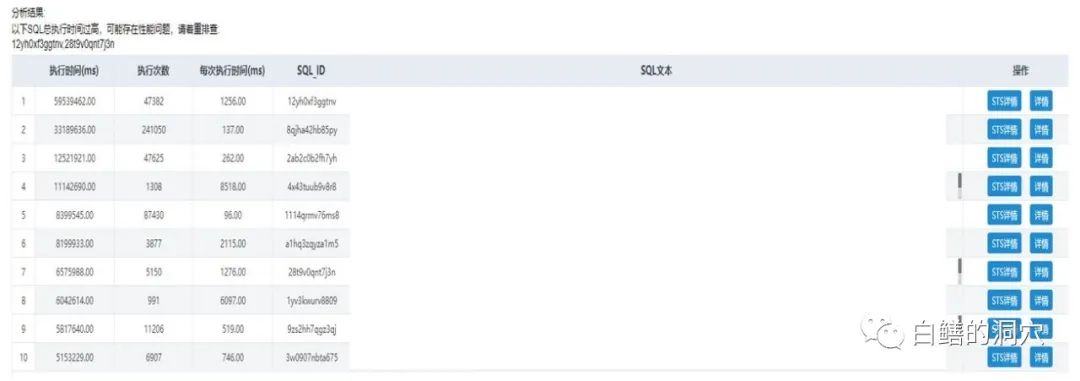
通过D-SMART的诊断工具,我们找到了一些需要优化的SQL ,后续就可以通过STS进一步的查找优化方案。除了TOP SQL之外,所有和CPU相关的问题都需要去做分析。我们在数据库的CIB上看到了一些奇怪的现象:
数据库的CPU_COUNT看到是76,不过从CPU分析上我们看到这个系统有88线程,不过这个数据库并没有设置CPU_COUNT,为什么数据库看到的CPU线程和实际的CPU线程数对不上呢?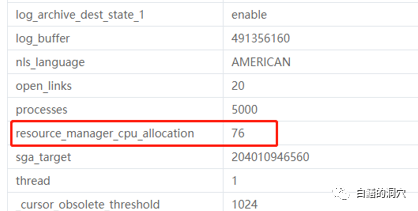
原来这个数据库设置了一个已经废弃的资源管理器参数,通过这个参数限制了CPU资源的使用。我们咨询了客户为什么要设置这个参数,原来客户也发现了只要CPU使用率比较高,系统就会慢,在设置这个参数之前,CPU使用率经常高达100%,CPU 100%后,系统的性能就十分差了,于是运维厂商建议通过这个参数来控制CPU使用率。设置了这个参数后,CPU使用率基本上被控制在90%以内,不过系统的性能没有好转。实际上当CPU资源超载的情况下,通过限制CPU资源使用时无法解决问题的,设置了这个参数之后,系统的性能不会有所改善,反而会更差,因为CPU资源的上限更低了。正确的方法是优化相关的SQL,使高峰期的CPU使用率处于正常的范围内。
最后修改时间:2021-03-08 17:18:26
文章转载自
白鳝的洞穴,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





