




一、简介
RocksDB是Facebook开发的嵌入式Key-Value存储系统,借用了来自Google开源项目LevelDB的核心代码以及HBase的重要思想。初始代码fork自LevelDB 1.5版本,它还融入了Facebook团队在开发RocksDB之前的若干代码及想法,增加了许多LevelDB没有的特性并做了许多优化,性能相对LevelDB有较大的提升,并且能够充分利用闪存性能,大大提升应用服务器的速度。
RocksDB已经在业界有了广泛的使用,如:TiDB、CockroachDB、MyRocks、ArangoDB等。
二、RocksDB架构
RocksDB是一个嵌入式KV存储,key 和 value 可以使任意字节。RocksDB按顺序组织所有数据,常用操作是Get(key),Put(key),Delete(key) 和 Scan(key)。

RocksDB的基本结构:Memtable、SSTfile、Logfile。
Memtable:内存数据结构,新写入的数据被存储到Memtable中,并可选地写入Logfile。
SSTfile:数据存储文件,内部按key顺序排序以方便查找。
Logfile:存储顺序写入的文件,相当于WAL。
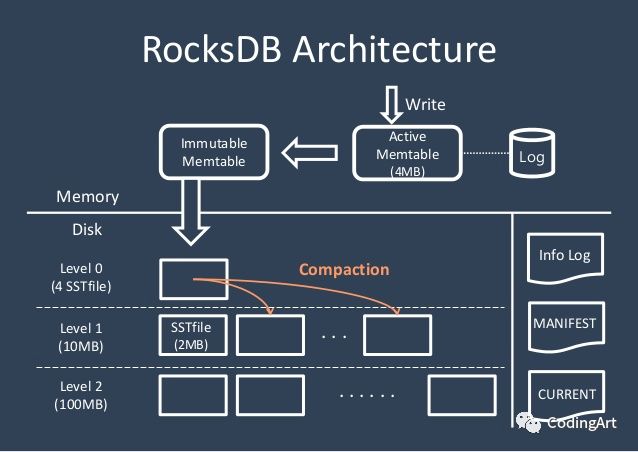
写流程
RocksDB使用日志合并树模型(LSM)。往RocksDB中写数据时先写Logfile,然后写Memtable。Memtable写满了,会生成不可变的Immutable Memtable(避免阻塞新的写入), 后台线程将Immutable Memtable中的数据flush到磁盘,生成Level 0的sst文件。sst文件一旦生成,其内容就不再改变。 同时,对数据库结构的修改,会触发后台任务运行,从上到下(Level从0开始编号),计算每个Level中是否有文件需要合并,如有sst文件满足合并条件,这些文件会被合并,生成新的sst文件,放到合适的层中,可能是当前层也可能是下一层。
RocksDB中数据的持久化和数据文件的合并,只涉及到如下文件操作:生成一个新文件,读取若干文件,删除已存在文件,因此只有追加写,没有随机写,具有非常高的写性能。
读流程
从RocksDB中读取数据,先去Memtable中去读,如果Memtable中没有,就去Level 0中读,如果还未命中,就从后面的Level中逐层找。RocksDB维护了每层中key的范围, 且除了第0层,其他每层中任意两个文件的key范围是不重叠的,且任意一个sst文件中key都是有序的。
由于Memtables和第0层的数据都位于内存,且通常不大; 而每层中每个文件所包含的key是已知的,所以能很快找到key所在的目标文件,如果在上层中找到目标key,就不需要到更下面的层中去找了,因此读操作也能有相当好的性能。
Manifest文件
为了快速从RocksDB中读取某个key的数据,或者快速定位哪些文件需要合并,需要维护一些常驻内存的信息,也就是整个LSM树的结构, 以加速查找和合并;同时LSM的结构在数据库重启时,需要能够快速重建,因此需要把这些信息持久化,Manifest文件就是这些信息的持久化存在。
RocksDB官方文档里,对Manifest文件的描述是: Manifest是一个记录了数据库状态变化的事务性日志。关注两点,一是事务性日志,二是记录了数据库状态的变化,也就是说,Manifest文件的记录着改变数据库状态的操作。Manifest文件中记录了诸如新增sst文件到某一层、当前日志文件名、之前日志文件名、当前Manifest文件名等操作。 每一个操作都将数据库置为一个新的状态,也就是一个新的版本。Manifest文件作为事务性日志文件,只要数据库有变化,其状态就会增长,达到一定大小后会被重写。
SST文件
SST文件是RocksDB中数据的最终存储角色,划分为不同的Level。Level 0的SST文件由Memtable直接dump产生。其他层次的SST文件则由其上一层文件在Compaction过程中产生。
SST其实存储的不只是数据,其中还保存了一些元数据、索引等信息,用于加速读写操作的速度。
SST由几部分组成:Data Block、Meta Block、MetaIndex Block、Index Block以及Footer。

Data Block:顾名思义存储的是数据,也就是KV pair。
Meta Block:比较特殊的Block,用来存储元信息,如布隆过滤器的存储。写入Data Block的数据会同时更新对应Meta Block中的过滤器。读取数据时也会首先经过布隆过滤器过滤,快速判断查找的key是否存在。
MetaIndex Block:记录Meta Block位置信息(offset+size),其中每一条Entry指向一个Meta Block。
Index Block:记录Data Block位置信息的Block,其中的每一条Entry指向一个Data Block,其Key值为所指向的Data Block最后一条数据的Key,Value为指向该Data Block位置的Handle。
Footer:位于文件尾部,记录指向Metaindex Block的Handle和指向Index Block的Handle。需要说明的是Table中所有的Handle是通过偏移量Offset以及Size一同来表示的,用来指明所指向的Block位置。Footer是SST文件解析开始的地方,通过Footer中记录的这两个关键元信息Block的位置,可以方便地开启之后的解析工作。另外Footer种还记录了用于验证文件是否为合法SST文件的常数值Magic Number。
RocksDB Compaction

当L0的文件数量达到阈值时,会触发L0和L1的合并。通常必须将所有L0的文件合并到L1中,因为L0的文件的key是有重叠的。
当L0 compaction完成后,L1的文件总size或者文件数量可能会超过阈值,触发L1向L2的合并。从L1至少选择一个文件,合并到L2中key有交叠的文件中。同样的,合并后可能会触发下一各level的compaction。
当多个Level都满足触发compaction的条件,RocksDB通过计算得分来选择先做哪一个level的compaction。
对于非0 level,score = 该level文件的总长度 阈值。已经正在做compaction的文件不计入总长度中。
对于L0,score = max{文件数量 / level0_file_num_compaction_trigger, L0文件总长度 / max_bytes_for_level_base} 并且 L0文件数量 > level0_file_num_compaction_trigger。
得分最高的level优先做compaction。
