排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
db file sequential read延时的关联性分析
db file sequential read延时的关联性分析
白鳝的洞穴
2021-03-03
1179
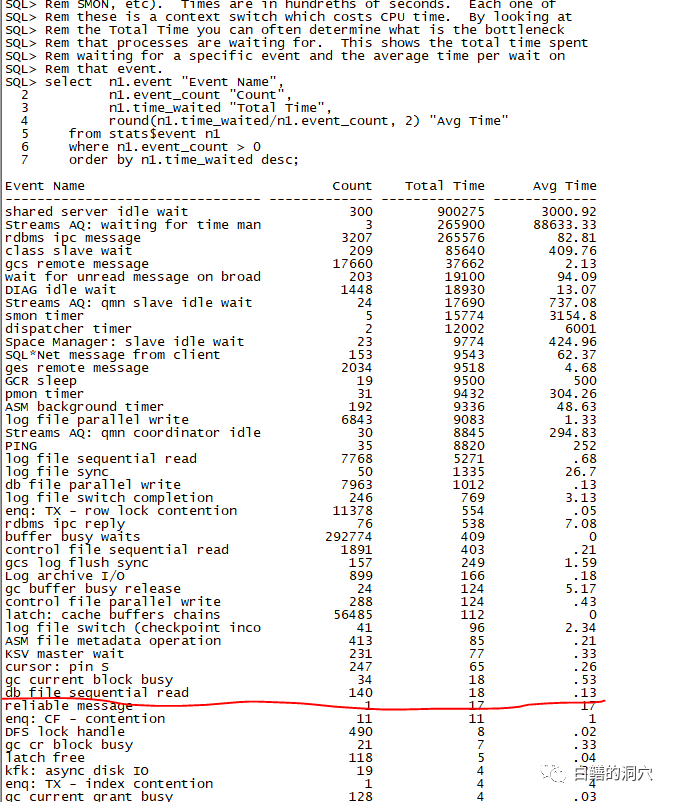
从二十年前开始接触ORACLE 7的时候,我们就认识了一个Oracle的等待事件,db file sequential read。
当时还是使用utlbstat/utlestat工具去分析Oracle的运行状态。这是OWI对外提供的最早的分析工具,让90年代初的DBA感到十分的幸福。这个工具后来就演变为statspack,到了10g时代,就变成了现在绝大多数DBA都熟练使用的awr报告。
记得当时刚刚接触utlbstat工具的时候,就开始研究db file sequential read这个等待事件的含义。老DBA总会告诉新人,这个等待事件是和SQL的索引扫描有关的。当SQL通过索引去访问数据的时候,首先查到索引里的ROWID,然后再通过ROWID进行单块读,读取表里的数据,这个时候就可能会等待db file sequential read了。如果SQL是做全表扫描,那么就会等待db file scattered read了。
这种描述大体上是正确的,不过不够精确。db file scattered read不只是在对数据表做全表扫描的时候产生,在对索引做全索引快速扫描的时候,也是采用多块读的方式进行的,此时的等待事件也是db file scattered read。而在对某张表做全表扫描的时候,也不只是会等待db file scattered read,有时候也会等待db file sequential read。为什么呢会这样呢?原理很简单,现在数据库的db cache都很大,数据库的常用数据大多数都可能在db cache里都存在,在扫描一张表的时候,有可能这张表的一部分数据已经在db cache里了,只有零星的几个数据块需要从文件里读取,于是扫描这张表的时候,很可能会产生db file sequentail read(单块读)。想象一个最坏的情况,一张表的奇数块都在DB CACHE里,而偶数块都需要从数据文件中读取,那么会不会出现采用单块读的效率远低于多块读呢?理论上是可能的,不过oracle的数据文件访问存在预读的机制,通过算法会尽可能地避免出现这种情况。
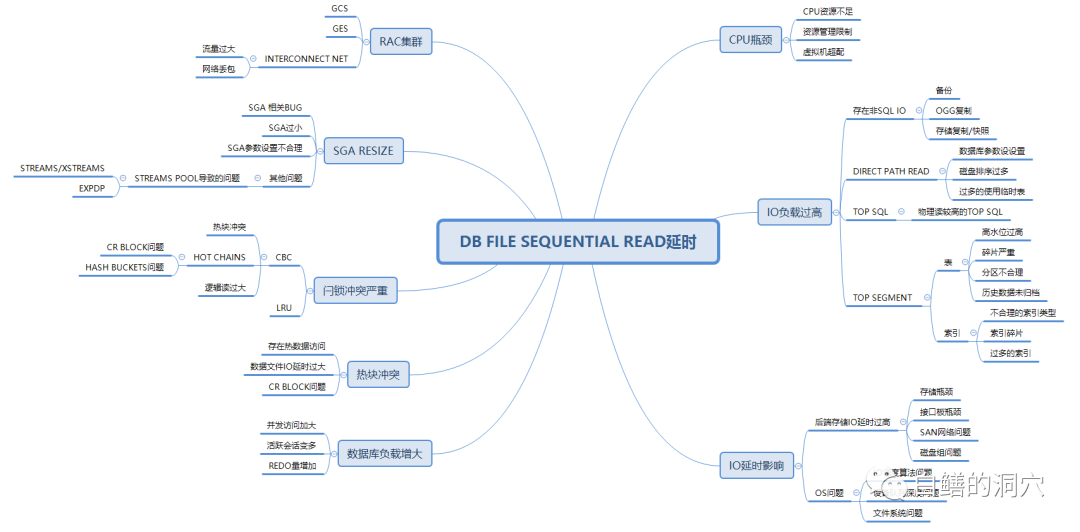
弄懂db file sequential read产生的原因并不复杂,不过想要了解影响这个等待事件的因素就要复杂的多了。当年我咨询过很多前辈,他们对此都不甚了解。顶多告诉我,这个等待事件和IO的总量和IO的延时有关。通过二十多年的学习,现在的DBA对这个等待事件的了解已经十分深刻了,不过能把这个等待事件了解的十分清晰的人还是凤毛麟角。是大家不够努力的学习吗?答案是否定的,大家首先看看老白的下一张图。
这是根据老白二十多年的经验画的一个关于db file sequential read延时影响的思维导图,并不完整,仅仅列出了关系最为紧密的一些因素。即使如此,这张图上的影响路径已经有几十条了。因此说,要让一个普通的DBA弄清楚如此复杂的关系,还是很难的。
把这张图
详细的解释清楚
就更难了,
估计需要用上万的文字才能描述清楚。
今天
我们讨论的篇幅有限,就
挑几个
因素来
简单的分析一下。
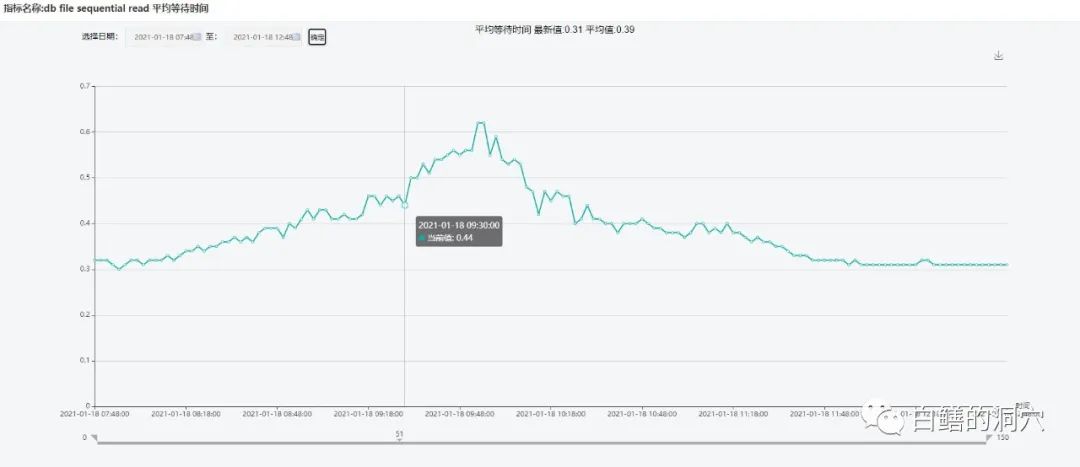
比如说CPU资源,这往往会被人忽略,IO相关的问题怎么会和CPU相关呢?我们先来看一个实际的系统中的数据。首先我们来看一个实际生产环境中的db file sequential平均延时 在早上上班前到业务高峰期到中午业务间歇期的变化情况。
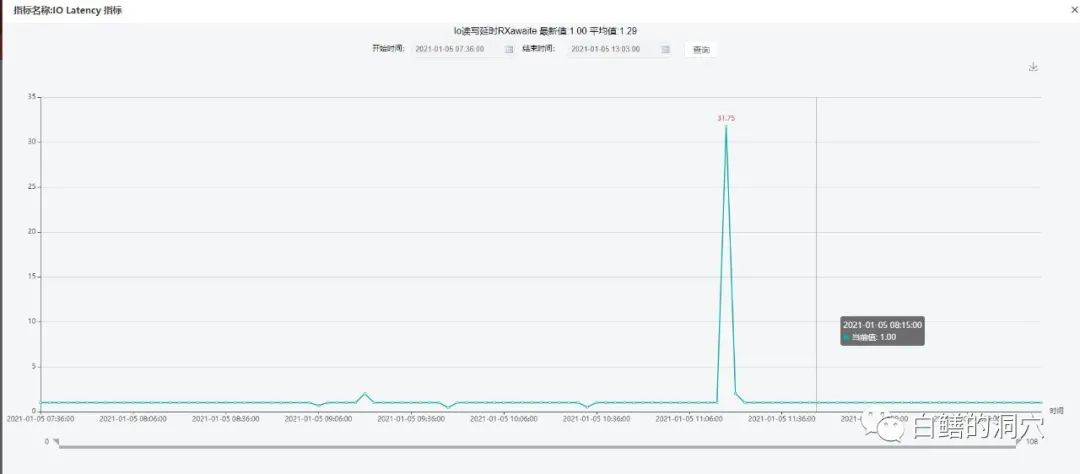
从这张图上可以看出,从9:30开始,延时突然明显变大,到9:50左右达到高峰,然后逐渐回落。出现这种情况是不是意味着操作系统的IO延时也是这样变化的呢?我们来看看这段时间内的IO延时的变化情况。
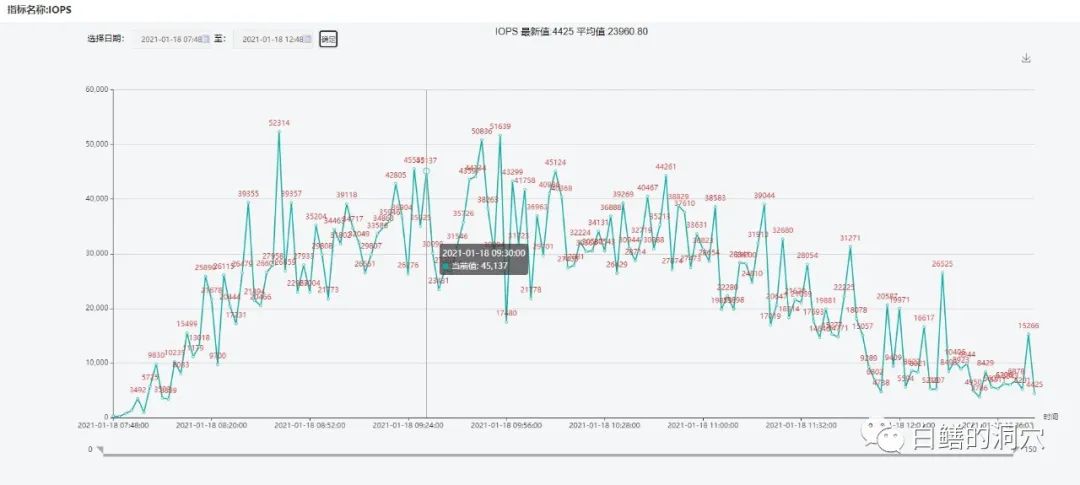
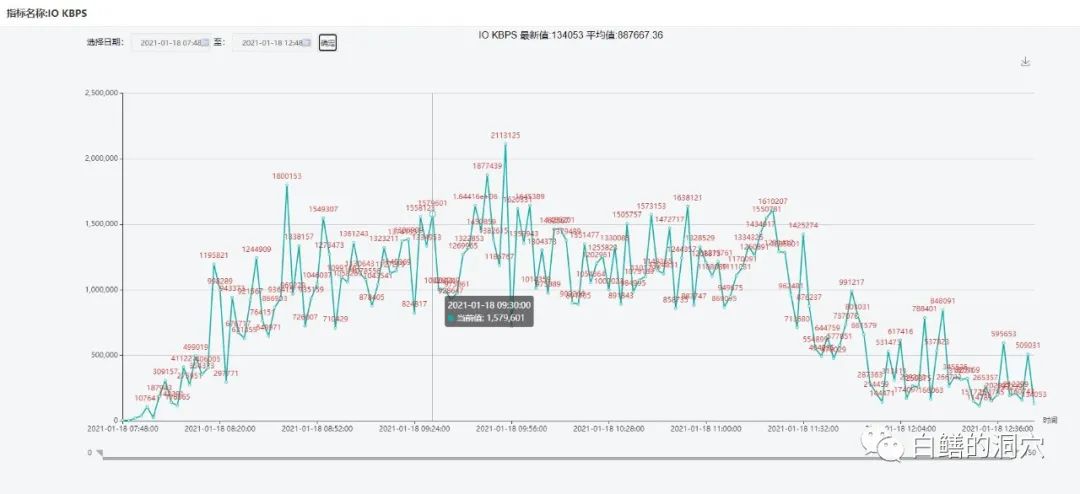
好像IO延时的变化曲线和db file sequential read的延时没有任何相似性性。那么IOPS会不会有关呢?
IOPS和IO吞吐量的变化情况似乎也有点对不上。那到底是什么因素和db file squential read的延时紧密相关呢?
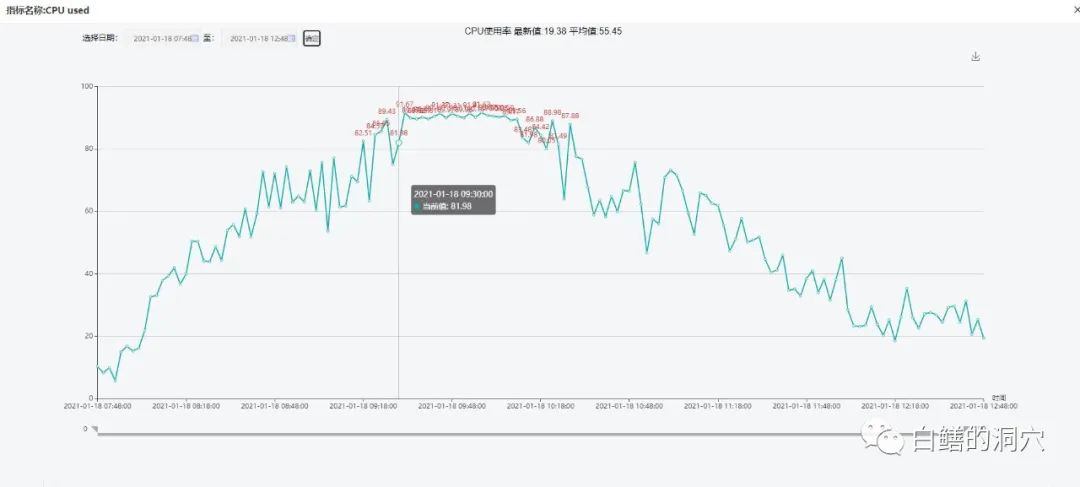
CPU的使用率变化的这张图是不是有点像呢?同样的9:30开始CPU使用率也出现了突然增长。看完这些图之后我们是不是有点迷惑了呢?实际上也很好解释这个问题,因为这个场景中,CPU资源出现了瓶颈,当CPU资源出现瓶颈的时候,db file sequential read的延时是会受到一定的影响的。不过CPU的影响仅限于CPU资源出现瓶颈的时候。如果CPU资源十分充足,那么CPU的使用率变化对单块读延时的影响是微乎其微的。
IO延时对数据库单块读的影响是显而易见的,不过我们从OS层面看到的IO延时包含了多种特征的IO,因此二者之间的关系很可能并不吻合,而且在某些时候还可能出现极大的不匹配的情况。就像我们举的这个案例。在OS层面的IO受到CPU资源的影响是较为均匀的,因为目前服务器处理IO的能力是十分强的,一个比较新的X86服务器的CPU core每秒可以处理400M以上的IO,因此CPU资源调度的因素加载到OS的IO延时上,我们可能很难通过iostat等命令区分出来。所以我们在上面的案例中并没有看到OS IO延时与数据块单块读延时之间的较为紧密的联系。不过实际上数据块单块读的延时受到OS IO延时的影响还是很大的。
我们再来看一个因素,就是IO吞吐量或者IOPS,几年前,老白也曾经想通过机器学习的方法来建立IOPS/IOKB指标与数据库单块读延时之间的模型,不过最后失败了。后来经过对数据库IO原理的仔细研究,才发现当IOPS/IOKB在没有存在瓶颈的时候与存在瓶颈的时候,对数据库单块读延时的影响是截然不同的(这一点与CPU十分类似),当IO瓶颈不存在的时候,这种影响的随机性很大,而当瓶颈出现时,二者的关联性才会较为紧密。
正是这些问题的存在,才使得AIOPS在构建这些关系的时候往往十分困难。理解了这些原理,也可以让我们在构建相关的智能模型的时候,更有针对性。
今天老白写的内容实际上算是一个抛砖引玉,在智能化运维中,关联性分析是故障定位与深度预警的核心技术之一。今天老白分析db file sequential read关联性的方法是比较容易用算法实现的智能分析方法之一,在即将发布的D-SMART V1.9.6中也集成了相关的分析工具,通过关联分析可以为故障定位和溯源提供很直接的分析结果。
数据库
文章转载自
白鳝的洞穴
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨