




关于telegraf
其实telegraf在几年前我就有看过
这个监控采集插件,其实涉及到了一套监控解决方案--TICK
telegraf作为数据采集,influxdb数据存储,C是Chronograf、k是Kapacitor 两者分别是数据展示及告警,类似grafana与alertmanager。
最近的话夜莺监控系统V5版本也是用到了telegraf作为采集器,下面是这款采集器与其它几款的一个对比。
不同agent整体横向对比
监控agent | telegraf | zabbix_agent | node expoter |
监控方式 | 主动发送 | 主动+被动 | 被动 |
语言 | go | c | go |
监控项 | 上百项监控项 | 侧重基础资源 | 基础资源 |
是否支持自定义指标 | exec模块 | 支持 | 需二次开发 |
数据存储方式 | 支持多种时序库 | mysql | prometheus |
社区活跃度 | 高 | 高 | 高 |
可参考文档 | 较少 | 多、成熟 | 中 |
不同agent性能消耗上对比
主要包括如下三个指标
cpu使用率对比
采集了1小时的数据对比,cpu使用上telegra最高也只有0.7% 使用率三者都比较低

mem使用率对比
telegraf稍微高一些,接近70M

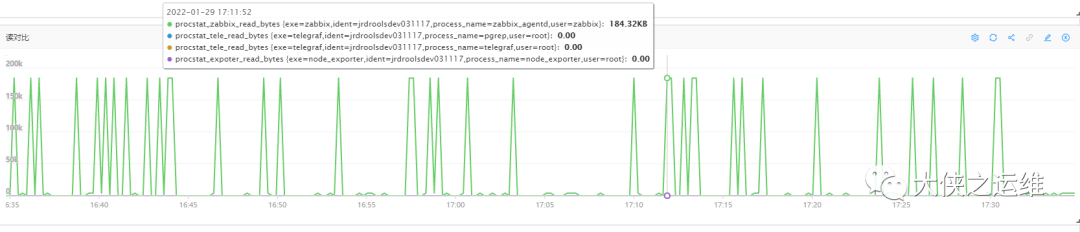
数据包读取大小对比
zabbix根据采集频率会有接近200k的数据
telegraf如果只有主机监控的话,数据有4k
telegraf的一些特点介绍
1.支持监控项多 主机+中间件
interval:所有输入的默认数据收集间隔round_interval:将收集间隔舍入为“interval”例如,如果interval =“10s”则始终收集于:00,:10,:20等。metric_batch_size:Telegraf将指标发送到大多数metric_batch_size指标的批量输出。metric_buffer_limit:Telegraf将缓存metric_buffer_limit每个输出的指标,并在成功写入时刷新此缓冲区。这应该是倍数,metric_batch_size不能少于2倍metric_batch_size。collection_jitter:集合抖动用于随机抖动集合。每个插件在收集之前将在抖动内随机休眠一段时间。这可以用来避免许多插件同时查询sysfs之类的东西,这会对系统产生可测量的影响。flush_interval:所有输出的默认数据刷新间隔。您不应将此设置为以下间隔。最大值flush_interval为flush_interval+flush_jitterflush_jitter:将刷新间隔抖动一个随机量。这主要是为了避免运行大量Telegraf实例的用户出现大量写入峰值。例如,flush_jitter5s和flush_interval10s之一意味着每10-15秒就会发生一次冲洗。precision:默认情况下,precision将设置为与收集时间间隔相同的时间戳顺序,最大值为1s。精度不会用于服务输入,例如logparser和statsd。有效值为 ns,us(或µs)ms,和s。logfile:指定日志文件名。空字符串表示要登录stderr。debug:在调试模式下运行Telegraf。quiet:以安静模式运行Telegraf(仅限错误消息)。hostname:覆盖默认主机名,如果为空使用os.Hostname()。omit_hostname:如果为true,则不host在Telegraf代理中设置标记。
2.配置测试
e.g:telegraf -config etc/telegraf/telegraf.conf -input-filter cpu -test
3.开箱即用
4.telegraf 缺点
附:参考文档
https://github.com/influxdata/telegraf/tree/master/plugins/inputs
文章转载自大侠之运维,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
