




PySpark实现了Spark对于Python的API,本文简要介绍了PySpark的配置,以及通过PySpark对RDD进行Transform和Action操作。
1、PySpark介绍
PySpark实现了Spark对于Python的API,通过它,用户可以编写运行在Spark之上的Python程序,从而利用到Spark分布式计算的特点。
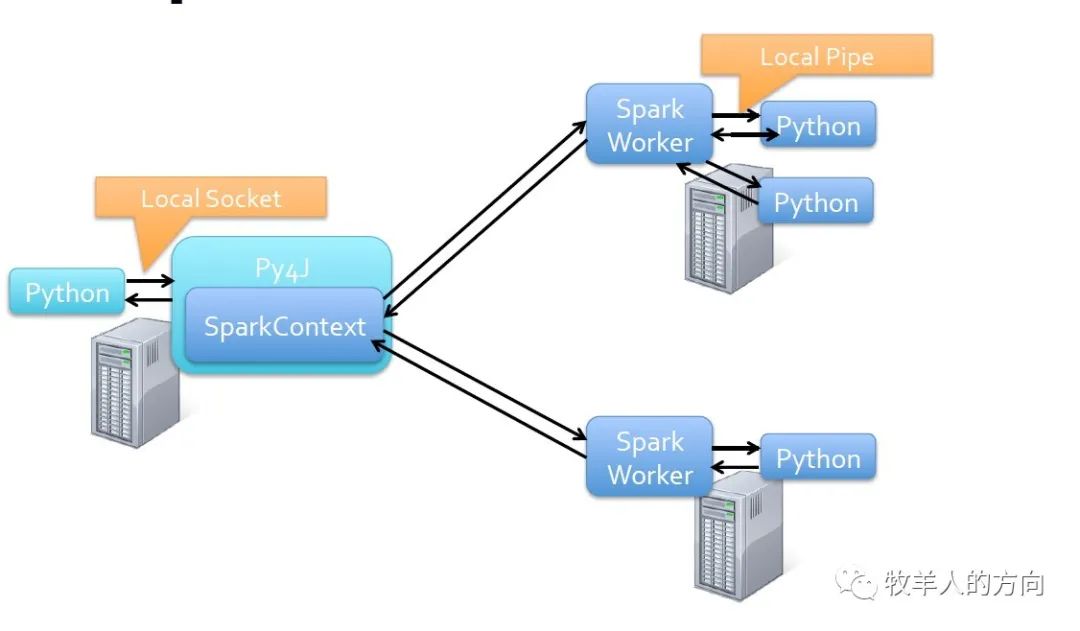
PySpark的整体架构图如下,可以看到Python API的实现依赖于Java的API,Python程序端的SparkContext通过py4j调用JavaSparkContext,后者是对Scala的SparkContext的一个封装。而对RDD进行转换和操作的函数由用户通过Python程序来定义,这些函数会被序列化然后发送到各个worker,然后每一个worker启动一个Python进程来执行反序列化之后的函数,通过管道拿到执行之后的结果。
Python程序的启动
和Scala程序一样,Python程序也是通过SparkSubmit提交得以执行,在SparkSubmit中会判断提交的程序是否为Python,如果是,则设置mainClass为PythonRunner。在PythonRunner中,会根据配置选项,以及用户通过命令行提供的--py-files选项,设置好PYTHONPATH,然后启动一个Java的GatewayServer用来被Python程序调用,然后以用户配置的PYSPARK_PYTHON选项作为Python解释器,执行Python文件,至此用户的Python程序得以启动。
SparkContext
和在Scala中一样,SparkContext是调用Spark进行计算的入口。在Python的context.py中定义了类SparkContext,它封装了一个JavaSparkContext作为它的_jsc属性。在初始化SparkContext时,首先会调用java_gateway.py中定义的launch_gateway方法来初始化JavaGateWay,在launch_gateway中会引入在Spark中定义的类到SparkContext的属性_jvm,比如:java_import(gateway.jvm, "org.apache.spark.SparkConf")。这样在Python中就可以通过SparkContext._jvm.SparkConf引用在Scala中定义的SparkConf这个类,可以实例化这个类的对象,可以调用对象的方法等。在初始化完毕之后,用户就可以调用SparkContext中的方法了,比如textFile和parallelize。
RDD
Python中的RDD对Spark中的RDD进行了一次封装,每一个RDD都对应了一个反序列化的函数。这是因为,尽管在Spark中RDD的元素可以具有任意类型,提供给JavaSparkContext中生成的RDD的只具有Array[Byte]类型,也就是说JavaSparkContext的函数返回值是JavaRDD[Array[Byte]],这样,Python程序需要把对象先序列化成byte数组,然后把它分布到各个节点进行计算。计算完之后再反序列化成Python的对象。(这其中有一个特殊情况,就是JavaSparkContext返回的是JavaRDD[String],可以把它当成是不需要序列化和反序列化的对象。)在Spark中不需要知道Array[Byte]反序列化之后是什么。如何序列化和反序列化、如何对这些Array[Byte]进行转换和操作都由Python程序来控制,Spark只是负责资源的调度,负责如何把这些计算分配到各个节点上去执行。
2、PySpark环境配置
安装好spark后,直接输入pyspark,可调出pyspark工作界面
[root@tango-spark01 spark-2.3.0]# pyspark
Python 2.7.5 (default, Aug 4 2017, 00:39:18)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-16)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
2018-06-01 16:31:52 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
__/__ ___ _____/ __
_\ \/ _ \/ _ `/ __/ '_/
__ .__/\_,_/_/ _/\_\ version 2.3.0
_/
Using Python version 2.7.5 (default, Aug 4 2017 00:39:18)
SparkSession available as 'spark'.
>>>
1)引入Python中pyspark工作模块
import pyspark
from pyspark import SparkContext as sc
from pyspark import SparkConf
conf=SparkConf().setAppName("miniProject").setMaster("local[*]")
sc=SparkContext.getOrCreate(conf)
#任何Spark程序都是SparkContext开始的,SparkContext的初始化需要一个SparkConf对象,SparkConf包含了Spark集群配置的各种参数(比如主节点的URL)。初始化后,就可以使用SparkContext对象所包含的各种方法来创建和操作RDD和共享变量。Spark shell会自动初始化一个SparkContext(在Scala和Python下可以,但不支持Java)。
#getOrCreate表明可以视情况新建session或利用已有的session
2)Python脚本执行 python脚本中需要在开头导入spark相关模块,调用时使用spark-submit提交,如下所示:
spark-submit --master local xxxx.py
spark-submit --master yarn --deploy-mode cluster xxxx.py
3、PySpark使用
3.1 初始化Spark
编写Spark程序的第一件事情就是创建SparkContext对象,SparkContext负责连接到集群。创建SparkContext先要创建SparkConf对象,该对象可以定义我们Spark程序的相关参数。
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
其中appName是程序名称,它会显示在集群状态界面上;master是要提交到的集群的地址
3.2 初始化RDD
RDD(Resilient Distributed Datasets)是Spark中抽象出来的弹性分布式数据集,其本质上是一个只读的分区记录集合。每个RDD可以分成多个分区,每个分区就是一个数据集片段。
创建RDD有两种方式:一种是将驱动程序中的已有集合平行化;另外一种是引用外部存储系统的数据集,例如共享文件系统,HDFS, HBase, 或者其他类似Hadoop的数据源
sc.parallelize初始化RDD
在驱动程序中,对已有的可遍历集合执行SparkContext的parallelize函数,可以创建并行化集合。执行Parallelize函数时,集合元素被复制后用来构成可并行操作的分布式数据集。
a) 利用list创建一个RDD;使用sc.parallelize可以把Python list,NumPy array或者Pandas Series,Pandas DataFrame转成Spark RDD
>>> rdd=sc.parallelize([1,2,3,4,5])
>>> rdd
ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:175
b)getNumPartitions()方法查看list被分成了几部分
>>> rdd.getNumPartitions()
2
c)glom().collect()查看分区状况
>>> rdd.glom().collect()
[[1, 2], [3, 4, 5]]
外部数据集初始化RDD
PySpark可以从需要hadoop支持的存储系统创建分布式数据集,包括本地文件系统、HDFS、 Cassandra、HBase以及Amazon S3等等。Spark支持文本文件、sequenceFile以及其他的Hadoop输入格式。注:sequenceFile是Hadoop中一个由二进制序列化过的key/value的字节流组成的文本存储文件。文本RDD可以通过SparkContext的textFile函数创建。该方法以文件地址(URI)作为输入并按行读取。
a) 记录当前pyspark工作环境位置
>>> import os
>>> cwd=os.getcwd()
>>> cwd
'/usr/local/spark/spark-2.3.0'
b) 要读入的文件的全路径
>>> rdd=sc.textFile("file:"+cwd+"/test-rdd/test-rdd.txt")
>>> rdd
file:/usr/local/spark/spark-2.3.0/test-rdd/test-rdd.txt MapPartitionsRDD[7] at textFile at NativeMethodAccessorImpl.java:0
c) first()方法取读入的rdd数据第一个item
>>> rdd.first()
u'Mary,F,7065'
3.3 RDD操作
RDDs支持两种类型的操作:一种是转换(transformations), 该操作从已有数据集创建新的数据集;另外一种是动作(actions),该操作在数据集上执行计算之后返回一个值给驱动程序。例如, map就是一个转换,这个操作在数据集的每个元素上执行一个函数并返回一个处理之后新的RDD结果。另一方面,reduce是一个动作,这个操作按照某个函数规则聚集RDD中的所有元素并且把最终结果返回给驱动程序。
Spark中的所有转换操作都是lazy模式的,也就是说,不是立马做转换计算结果,而是将这些转换操作记录在相应的数据集上,当需要通过动作(action)把结果返回给驱动程序时才真正执行。这个设计使Spark运行起来更加高效。例如,如果通过map创建的数据集后续会被reduce用到,那么只有reduce的结果会返回给驱动程序,而不是更大的map结果。默认情况下,RDD上的转换操作在每次做动作时,都会重新执行计算一次。然而,我们可以使用persist(或者cache)函数将RDD存放在内存中,方便后续的快速访问。另外,Spark也支持将RDD存放在磁盘上,或者在多个节点冗余存储。
常见Transformations操作
| Transformation | 含义 |
|---|---|
| map(func) | 对每个RDD元素应用func之后,构造成新的RDD |
| filter(func) | 对每个RDD元素应用func, 将func为true的元素构造成新的RDD |
| flatMap(func) | 和map类似,但是flatMap可以将一个输出元素映射成0个或多个元素。(也就是说func返回的是元素序列而不是单个元素). |
| mapPartitions(func) | 和map类似,但是在RDD的不同分区上独立执行。所以函数func的参数是一个Python迭代器,输出结果也应该是迭代器【即func作用为Iterator<T> => Iterator】 |
| mapPartitionsWithIndex(func) | 和mapPartitions类似, but also provides func with an integer value representing the index of the partition, 但是还为函数func提供了一个正式参数,用来表示分区的编号。【此时func作用为(Int, Iterator<T>) => Iterator 】 |
| sample(withReplacement, fraction, seed) | 抽样: fraction是抽样的比例0~1之间的浮点数; withRepacement表示是否有放回抽样, True是有放回, False是无放回;seed是随机种子。 |
| union(otherDataset) | 并集操作,重复元素会保留(可以通过distinct操作去重) |
| intersection(otherDataset) | 交集操作,结果不会包含重复元素 |
| distinct([numTasks])) | 去重操作 |
| groupByKey([numTasks]) | 把Key相同的数据放到一起【(K, V) => (K, Iterable<V>)】,需要注意的问题:1. 如果分组(grouping)操作是为了后续的聚集(aggregation)操作(例如sum/average), 使用reduceByKey或者aggregateByKey更高效。2.默认情况下,并发度取决于分区数量。我们可以传入参数numTasks来调整并发任务数。 |
| reduceByKey(func, [numTasks]) | 首先按Key分组,然后将相同Key对应的所有Value都执行func操作得到一个值。func必须是(V, V) => V'的计算操作。numTasks作用跟上面提到的groupByKey一样。 |
| sortByKey([ascending], [numTasks]) | 按Key排序。通过第一个参数True/False指定是升序还是降序。 |
| join(otherDataset, [numTasks]) | 类似SQL中的连接(内连接),即(K, V) and (K, W) => (K, (V, W)),返回所有连接对。外连接通过:leftOUterJoin(左出现右无匹配为空)、rightOuterJoin(右全出现左无匹配为空)、fullOuterJoin实现(左右全出现无匹配为空)。 |
| cogroup(otherDataset, [numTasks]) | 对两个RDD做groupBy。即(K, V) and (K, W) => (K, Iterable<V>, Iterable(W))。别名groupWith。 |
| pipe(command, [envVars]) | 将驱动程序中的RDD交给shell处理(外部进程),例如Perl或bash脚本。RDD元素作为标准输入传给脚本,脚本处理之后的标准输出会作为新的RDD返回给驱动程序。 |
| coalesce(numPartitions) | 将RDD的分区数减小到numPartitions。当数据集通过过滤减小规模时,使用这个操作可以提升性能。 |
| repartition(numPartitions) | 将数据重新随机分区为numPartitions个。这会导致整个RDD的数据在集群网络中洗牌。 |
| repartitionAndSortWithinPartitions(partitioner) | 使用partitioner函数充分去,并在分区内排序。这比先repartition然后在分区内sort高效,原因是这样迫使排序操作被移到了shuffle阶段。 |
常见Actions操作
| Action | 含义 |
|---|---|
| reduce(func) | 使用func函数聚集RDD中的元素(func接收两个参数返回一个值)。这个函数应该满足结合律和交换律以便能够正确并行计算。 |
| collect() | 将RDD转为数组返回给驱动程序。这个在执行filter等操作之后返回足够小的数据集是比较有用。 |
| count() | 返回RDD中的元素数量。 |
| first() | 返回RDD中的第一个元素。(通take(1)) |
| take(n) | 返回由RDD的前N个元素组成的数组。 |
| takeSample(withReplacement, num, [seed]) | 返回num个元素的数组,这些元素抽样自RDD,withReplacement表示是否有放回,seed是随机数生成器的种子)。 |
| takeOrdered(n, [ordering]) | 返回RDD的前N个元素,使用自然顺序或者通过ordering函数对将个元素转换为新的Key. |
| saveAsTextFile(path) | 将RDD元素写入文本文件。Spark自动调用元素的toString方法做字符串转换。 |
| saveAsSequenceFile(path)(Java and Scala) | 将RDD保存为Hadoop SequenceFile.这个过程机制如下:1. Pyrolite用来将序列化的Python RDD转为Java对象RDD;2. Java RDD中的Key/Value被转为Writable然后写到文件。 |
| countByKey() | 统计每个Key出现的次数,只对(K, V)类型的RDD有效,返回(K, int)词典。 |
| foreach(func) | 在所有RDD元素上执行函数func。 |
以下是个基本的例子:
首先从外部文件中定义一个基本的RDD
lineLengths为map转换的结果,由于使用惰性算法,lineLengths不会立刻计算出来
最后运行reduce action,这个时候spark会把计算分成不同的任务运行在单独的机器上,每台机器会运行自己部分并返回结果到driver program
>>> lines=sc.textFile("file:"+cwd+"/test-rdd/test-rdd.txt")
>>> lineLengths=lines.map(lambda s:len(s))
>>> lineLengths
PythonRDD[15] at RDD at PythonRDD.scala:48
>>> totalLength = lineLengths.reduce(lambda a, b: a + b)
>>> totalLength
43
如果想下次继续使用lineLengths,可以使用RDD持久化,在reduce()前执行该操作,可以将lineLengths保存在内存中:
>>> lineLengths.persist()
PythonRDD[12] at RDD at PythonRDD.scala:48
3.4 RDD持久化
Spark中最重要的能力之一是将数据持久化到内存中方便后续操作。当持久化一个RDD的时候,一旦该RDD在内存中计算出来,每个节点保存RDD的部分分区,在其他动作中就可以重用内存中的这个RDD(以及源于它的新RDD)。这种机制使得后续的动作(actions)快很多(通常在10倍以上)。可以通过persist() 或者cache()两个方法将RDD标记为持久化的。该RDD第一次在动作中计算出来之后,就会被保存在各节点的内存中。
3.5 Sample API
以下是一些sample API可练习使用:
Map、Reduce API:最基本入门的API
from pyspark import SparkContext
sc = SparkContext('local')
#第二个参数2代表的是分区数,默认为1
old=sc.parallelize([1,2,3,4,5],2)
newMap = old.map(lambda x:(x,x**2))
newReduce = old.reduce(lambda a,b : a+b)
print(newMap.glom().collect())
print(newReduce)
结果如下:
>>> old=sc.parallelize([1,2,3,4,5],2)
>>> newMap = old.map(lambda x:(x,x**2))
>>> newReduce = old.reduce(lambda a,b : a+b)
>>> print(newMap.glom().collect())
[[(1, 1), (2, 4)], [(3, 9), (4, 16), (5, 25)]]
>>> print(newReduce)
15
flatMap、filter、distinc API:数据的拆分、过滤和去重
sc = SparkContext('local')
old=sc.parallelize([1,2,3,4,5])
#新的map里将原来的每个元素拆成了3个
newFlatPartitions = old.flatMap(lambda x : (x, x+1, x*2))
#过滤,只保留小于6的元素
newFilterPartitions = newFlatPartitions.filter(lambda x: x<6)
#去重
newDiscinctPartitions = newFilterPartitions.distinct()
print(newFlatPartitions.collect())
print(newFilterPartitions.collect())
print(newDiscinctPartitions.collect())
结果如下:
>>> old=sc.parallelize([1,2,3,4,5])
>>> newFlatPartitions = old.flatMap(lambda x : (x, x+1, x*2))
>>> newFlatPartitions
PythonRDD[22] at RDD at PythonRDD.scala:48
>>> newFilterPartitions = newFlatPartitions.filter(lambda x: x<6)
>>> newFilterPartitions
PythonRDD[23] at RDD at PythonRDD.scala:48
>>> newDiscinctPartitions = newFilterPartitions.distinct()
>>> newDiscinctPartitions
PythonRDD[28] at RDD at PythonRDD.scala:48
>>> print(newFlatPartitions.collect())
[1, 2, 2, 2, 3, 4, 3, 4, 6, 4, 5, 8, 5, 6, 10]
>>> print(newFilterPartitions.collect())
[1, 2, 2, 2, 3, 4, 3, 4, 4, 5, 5]
>>> print(newDiscinctPartitions.collect())
[2, 4, 1, 3, 5]
Sample、taskSample、sampleByKey API:数据的抽样
sc = SparkContext('local')
old=sc.parallelize(range(8))
samplePartition = [old.sample(withReplacement=True, fraction=0.5) for i in range(5)]
for num, element in zip(range(len(samplePartition)), samplePartition):
print('sample: %s y=%s' %(str(num),str(element.collect())))
taskSamplePartition = [old.takeSample(withReplacement=False, num=4) for i in range(5)]
for num, element in zip(range(len(taskSamplePartition)), taskSamplePartition) :
#注意因为是action,所以element是集合对象,而不是rdd的分区
print('taskSample: %s y=%s' %(str(num),str(element)))
mapRdd = sc.parallelize([('B',1),('A',2),('C',3),('D',4),('E',5)])
y = [mapRdd.sampleByKey(withReplacement=False, fractions={'A':0.5, 'B':1, 'C':0.2, 'D':0.6, 'E':0.8}) for i in range(5)]
for num, element in zip(range(len(y)), y) :
#注意因为是action,所以element是集合对象,而不是rdd的分区
print('y: %s y=%s' %(str(num),str(element.collect())))
结果如下:
>>> old=sc.parallelize(range(8))
>>> samplePartition = [old.sample(withReplacement=True, fraction=0.5) for i in range(5)]
>>> for num, element in zip(range(len(samplePartition)), samplePartition):
... print('sample: %s y=%s' %(str(num),str(element.collect())))
...
sample: 0 y=[6, 7]
sample: 1 y=[0, 2, 3, 3, 5]
sample: 2 y=[0, 0, 2, 6, 6]
sample: 3 y=[]
sample: 4 y=[1, 5, 6]
>>> taskSamplePartition = [old.takeSample(withReplacement=False, num=4) for i in range(5)]
>>> for num, element in zip(range(len(taskSamplePartition)), taskSamplePartition) :
... print('taskSample: %s y=%s' %(str(num),str(element)))
...
taskSample: 0 y=[4, 2, 7, 1]
taskSample: 1 y=[1, 7, 6, 2]
taskSample: 2 y=[0, 1, 6, 5]
taskSample: 3 y=[7, 5, 3, 6]
taskSample: 4 y=[3, 5, 7, 2]
>>> mapRdd = sc.parallelize([('B',1),('A',2),('C',3),('D',4),('E',5)])
>>> y = [mapRdd.sampleByKey(withReplacement=False, fractions={'A':0.5, 'B':1, 'C':0.2, 'D':0.6, 'E':0.8}) for i in range(5)]
>>> for num, element in zip(range(len(y)), y):
... print('y: %s y=%s' %(str(num),str(element.collect())))
...
y: 0 y=[('B', 1), ('A', 2), ('C', 3), ('D', 4), ('E', 5)]
y: 1 y=[('B', 1), ('A', 2), ('E', 5)]
y: 2 y=[('B', 1), ('A', 2), ('E', 5)]
y: 3 y=[('B', 1), ('A', 2), ('D', 4), ('E', 5)]
y: 4 y=[('B', 1), ('A', 2), ('E', 5)]
>>>
交集intersection、并集union、排序sortBy API
sc = SparkContext('local')
rdd1 = sc.parallelize(['C','A','B','B'])
rdd2 = sc.parallelize(['A','A','D','E','B'])
rdd3 = rdd1.union(rdd2)
rdd4 = rdd1.intersection(rdd2)
print(rdd3.collect())
print(rdd4.collect())
print(rdd3.sortBy(lambda x : x[0]).collect())
结果如下:
>>> rdd1 = sc.parallelize(['C','A','B','B'])
>>> rdd2 = sc.parallelize(['A','A','D','E','B'])
>>> rdd3 = rdd1.union(rdd2)
>>> rdd4 = rdd1.intersection(rdd2)
>>> print(rdd3.collect())
['C', 'A', 'B', 'B', 'A', 'A', 'D', 'E', 'B']
>>> print(rdd4.collect())
['A', 'B']
>>> print(rdd3.sortBy(lambda x : x[0]).collect())
['A', 'A', 'A', 'B', 'B', 'B', 'C', 'D', 'E']
reduceByKey、 reduceByKeyLocal API 这两个要计算的效果是一样的,但是前者是传输,后者是动作,使用时候需要注意
sc = SparkContext('local')
oldRdd=sc.parallelize([('Key1',1),('Key3',2),('Key1',3),('Key2',4),('Key2',5)])
newRdd = oldRdd.reduceByKey(lambda accumulate,ele : accumulate+ele)
newActionResult = oldRdd.reduceByKeyLocally(lambda accumulate,ele : accumulate+ele)
print(newRdd.collect())
print(newActionResult)
结果如下:
>>> oldRdd=sc.parallelize([('Key1',1),('Key3',2),('Key1',3),('Key2',4),('Key2',5)])
>>> newRdd = oldRdd.reduceByKey(lambda accumulate,ele : accumulate+ele)
>>> newActionResult = oldRdd.reduceByKeyLocally(lambda accumulate,ele : accumulate+ele)
>>> print(newRdd.collect())
[('Key3', 2), ('Key1', 4), ('Key2', 9)]
>>> print(newActionResult)
{'Key3': 2, 'Key2': 9, 'Key1': 4}
参考资料
Spark官网:http://spark.apache.org/docs/latest/rdd-programming-guide.html
PySpark官方文档:https://spark.apache.org/docs/latest/api/python/index.html
