




有很多不错的无锁哈希表实现。通常,这些数据结构不是使用传统的锁,而是使用基于CAS的操作来实现无锁化(Lock Free)。有了这段叙述,你可能以为我这篇文章是来讨论无锁数据结构的。然而并不是,请不要惊讶。相反,这里我们要讨论的是传统的锁(Plain Old Locks)。
关于线程、锁和Lock Free操作,我之前也译过几篇,它们是:
既然大家已经就绪,我们现在要实现一个满足以下约定的并发版本的 Map:
public interface ConcurrentMap<K, V> {
boolean put(K key, V value);
V get(K key);
boolean remove(K key);
}
因为它将是一个线程安全的数据结构,在 put、get 或 remove 元素时,我们应当先获取锁并在随后释放:
public abstract class AbstractConcurrentMap<K, V>
implements ConcurrentMap<K, V> {
// constructor, fields and other methods
protected abstract void acquire(Entry<K, V> entry);
protected abstract void release(Entry<K, V> entry);
}
同样,在该实现中,我们应该初始化预定数量的桶(buckets):
public abstract class AbstractConcurrentMap<K, V>
implements ConcurrentMap<K, V> {
protected static final int INITIAL_CAPACITY = 100;
protected List<Entry<K, V>>[] table;
protected int size = 0;
public AbstractConcurrentMap() {
table = (List<Entry<K, V>>[]) new List[INITIAL_CAPACITY];
for (var i = 0; i < INITIAL_CAPACITY; i++) {
table[i] = new ArrayList<>();
}
}
// omitted
}
One Size Fits All? (固定数量的桶能适应所有场景吗?)
当存储元素的数量远远超过桶的数量时会发生什么?即使存在最通用的哈希函数,哈希表的性能也会显著降低。为了防止这种情况,我们需要在必要时增加更多的桶:
protected abstract boolean shouldResize();
protected abstract void resize();
有了这些抽象模板方法,我们可以将新的键值对放入Map中了:
@Override
public boolean put(K key, V value) {
if (key == null) return false;
var entry = new Entry<>(key, value);
acquire(entry);
try {
var bucketNumber = findBucket(entry);
var currentPosition = table[bucketNumber].indexOf(entry);
if (currentPosition == -1) {
table[bucketNumber].add(entry);
size++;
} else {
table[bucketNumber].add(currentPosition, entry);
}
} finally {
release(entry);
}
if (shouldResize()) resize();
return true;
}
protected int findBucket(Entry<K, V> entry) {
return abs(entry.hashCode()) % table.length;
}
为了找到放置新元素的桶,我们依赖了元素的key的 hashcode 值。而且,我们用此值对桶的数量取模,以免发生数组越界。
剩下的部分非常简单:我们为新的entry获取一个锁,entry不存在时,则插入到桶中,否则就更新桶。操作的最后,如果我们得出需要增加更多桶的结论,我们便增加桶的数量以维护哈希表的平衡。get 和 remove 方法也可以同样简单地实现。
让我们像做填空题一样实现所有这些抽象方法。
One Lock to Rule Them All (一个锁解决所有问题)
实现这个线程安全的数据结构的最简单方法,是对其所有操作共用一个锁:
public final class CoarseGrainedConcurrentMap<K, V>
extends AbstractConcurrentMap<K, V> {
private final ReentrantLock lock;
public CoarseGrainedConcurrentMap() {
super();
lock = new ReentrantLock();
}
@Override
protected void acquire(Entry<K, V> entry) {
lock.lock();
}
@Override
protected void release(Entry<K, V> entry) {
lock.unlock();
}
// omitted
}
当前的实现中,获取和释放锁是完全独立于 map entry 的。像上面承诺的一样,我们只用了一个 ReentrantLock 来实现同步(synchronization)。这种方式被称作 粗粒度同步(Coarse-Grained Synchronization),因为我们只用了一个锁来保证整个哈希表的互斥访问。
此外,我们应该调整哈希表的大小,以保持其恒定的访问和修改时间。为了做到这一点,我们可以结合不同的试探性方法。例如,当平均bucket大小超过特定数量时:
@Override
protected boolean shouldResize() {
return size table.length >= 5;
}
为了增加更多的桶,我们应该复制当前的哈希表并创建一个新的表,比如说,两倍大小的新表。然后将旧表中的所有条目添加到新表中:
@Override
protected void resize() {
lock.lock();
try {
var oldTable = table;
var doubledCapacity = oldTable.length * 2;
table = (List<Entry<K, V>>[]) new List[doubledCapacity];
for (var i = 0; i < doubledCapacity; i++) {
table[i] = new ArrayList<>();
}
for (var entries : oldTable) {
for (var entry : entries) {
var newBucketNumber = abs(entry.hashCode()) % doubledCapacity;
table[newBucketNumber].add(entry);
}
}
} finally {
lock.unlock();
}
}
请注意,在进行大小调整操作时,我们也应该获取和释放同一个锁。
Sequential Bottleneck (顺序瓶颈)
假设有三个并发请求,分别是:将新元素放入第一个桶、从第三个桶获取元素以及从第六个桶移除元素:
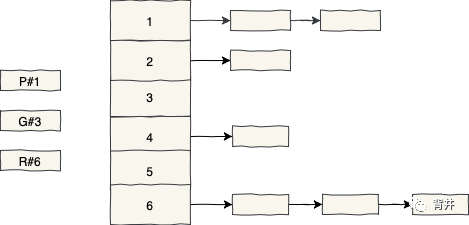
理想情况下,我们期望从一个高度可伸缩的并发数据结构中以尽可能少的协调来服务这些请求。然而,这是在现实世界中发生的事情:
由于我们只使用一个锁进行同步,因此并发请求将被阻塞在获取锁的第一个操作之后。当第一个操作释放锁时,第二个操作才能获得锁,一段时间后,它再释放锁。
这种现象被称为顺序瓶颈(Sequential Bottleneck,类似于Head of Line Blocking),我们应该在并发环境中消弱它的影响。
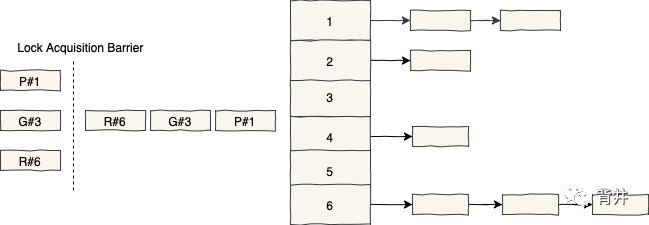
The United Stripes of Locks (不太好翻译,叫 「统一的分离锁」?)
改进当前粗粒度实现的一种方法是使用一组锁,而不是仅使用一个锁。这样,每个锁将负责同步一个或多个桶。与我们当前的方法相比,这是更细粒度的同步(Finer-Grained Synchronization):
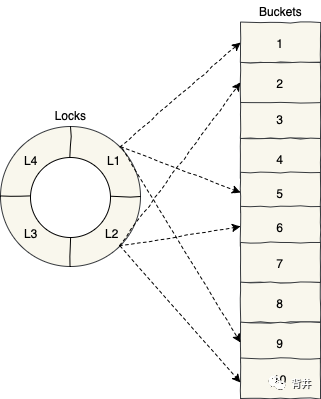
在这里,我们将哈希表分成几个部分,并独立地同步每个部分。这样我们就减少了每个锁的竞争,从而提高了吞吐量。这个想法也被称为锁分离(Lock Striping),因为我们独立地同步不同的部分(即 stripes,条纹。可以和美国星条旗联系起来,每个星条代表一个州;而在锁分离中,每个stripe代表某些桶的一个锁):
public final class LockStripedConcurrentMap<K, V>
extends AbstractConcurrentMap<K, V> {
private final ReentrantLock[] locks;
public LockStripedConcurrentMap() {
super();
locks = new ReentrantLock[INITIAL_CAPACITY];
for (int i = 0; i < INITIAL_CAPACITY; i++) {
locks[i] = new ReentrantLock();
}
}
// omitted
}
我们需要一个找到某个entry(也即,桶)所对应的锁的方法:
private ReentrantLock lockFor(Entry<K, V> entry) {
return locks[abs(entry.hashCode()) % locks.length];
}
然后,我们可以获取并释放对特定条目的操作的锁,如下所示:
@Override
protected void acquire(Entry<K, V> entry) {
lockFor(entry).lock();
}
@Override
protected void release(Entry<K, V> entry) {
lockFor(entry).unlock();
}
resize 过程与之前几乎相同。唯一的区别是,我们应该在调整大小之前获取所有锁,并在调整大小之后释放所有锁。
我们预期细粒度方法的性能优于粗粒度方法,接下来我们衡量一下。
Moment of Truth (真相时刻)
为了对这两种方法做性能对比,我们将使用以下工作负载:
final int NUMBER_OF_ITERATIONS = 100;
final List<String> KEYS = IntStream.rangeClosed(1, 100)
.mapToObj(i -> "key" + i).collect(toList());
void workload(ConcurrentMap<String, String> map) {
var requests = new CompletableFuture<?>[NUMBER_OF_ITERATIONS * 3];
for (var i = 0; i < NUMBER_OF_ITERATIONS; i++) {
requests[3 * i] = CompletableFuture.supplyAsync(
() -> map.put(randomKey(), "value")
);
requests[3 * i + 1] = CompletableFuture.supplyAsync(
() -> map.get(randomKey())
);
requests[3 * i + 2] = CompletableFuture.supplyAsync(
() -> map.remove(randomKey())
);
}
CompletableFuture.allOf(requests).join();
}
String randomKey() {
return KEYS.get(ThreadLocalRandom.current().nextInt(100));
}
每次运行,我们都添加一个key、获取一个key并移除一个key。每个工作负载将运行这三个操作100次。利用JMH,每个工作负载将执行数千次:
@Benchmark
@BenchmarkMode(Throughput)
public void forCoarseGrainedLocking() {
workload(new CoarseGrainedConcurrentMap<>());
}
@Benchmark
@BenchmarkMode(Throughput)
public void forStripedLocking() {
workload(new LockStripedConcurrentMap<>());
}
粗粒度实现平均每秒可以处理8547个操作:
8547.430 ±(99.9%) 58.803 ops/s [Average]
(min, avg, max) = (8350.369, 8547.430, 8676.476), stdev = 104.523
CI (99.9%): [8488.627, 8606.234] (assumes normal distribution)
另一方面,细粒度实现平均每秒可以处理多达13855个操作。
13855.946 ±(99.9%) 119.109 ops/s [Average]
(min, avg, max) = (13524.367, 13855.946, 14319.174), stdev = 211.716
CI (99.9%): [13736.837, 13975.055] (assumes normal distribution)
本文源码已放在github上:https://github.com/alimate/lock-striping
 关注作者
关注作者

