




原文标题:Working with Node.js Stream API
原文作者:Darko Milosevic
原文链接:https://medium.com/florence-development/working-with-node-js-stream-api-60c12437a1be
注: 本文中 Stream 和 流 是一个意思,可互换。
介绍
Stream一词在计算机科学中用于描述分块数据集,这种数据集不是一次性可得的,而是跨时间获取的。一个Stream仅仅是一组值,类似于一个数组,但从空间向反转到了时间向(即Stream的值是随着时间不断产生的)。
在Node.js中,Stream 是实现用于处理流数据的API模块的名称。
自2009年首次引入Node.js Stream API 以来,它已经有了很大的发展。由于存在不同的实现方式,接口也混合了不同的风格,这个不断发展的API给用户造成了很大的困惑。
本文将关注最新的“Stream 3”实现,以及Node v10+附带的新的有用的api。
Stream Basics
所有的streams都是EventEmitter的实例,这意味着它们会发出用于读写数据的事件(events)。
Stream Types 流的类型
Node.js中有四种基本流类型。
Readable (可读流):
对可读取和可消费的数据源的抽象
示例:客户端上的HTTP响应、服务器上的HTTP请求、fs read streams、process.stdin等。
Writable (可写流):
对可以写入数据的目标的抽象
示例:服务器上的HTTP响应、客户端上的HTTP请求、fs write streams、process.stout、process.stderr等。
Duplex (双向流):
同时实现可读(Readable)和可写(Writable)接口的流
示例:TCP套接字(net.Socket)。
Transform (转换流):
类似于双向流的流,具有在读写数据时修改或转换数据的能力
示例:压缩流(zlib.createGzip)。
Stream Modes 流的模式
Node.js中的Stream有两种操作模式:
Standard mode (标准模式):
默认设置的模式
操作的数据类型是“STRING”和“BUFFER”(或“UInt8Array”)
Node.js的内部stream实现中使用的类型
Object mode(对象模式):
创建流对象时要设定“objectMode”标识参数
内部缓冲算法计算的是对象(objects)而不是字节(bytes)
Buffering(缓冲)
每个流都有一个用于存储数据的内部缓冲区。可读流和可写流各有一个,可以使用 Readable.readableBuffer 和 writeable.writeablebuffer 访问。
双向流 和 转换流 有两个独立的缓冲区,允许每侧独立操作。
缓冲区的大小由 highWatermarkOption 参数决定。对于在标准模式下运行的流,它指定缓冲区大小;对于在对象模式下运行的流,它指定对象数。
Backpressure(背压)
背压这个概念对于刚开始使用Stream API的人来说很难理解,这也使得它成为一个常见的引发bug的源头。没有背压,流就不会这么有效率,背压是Stream最重要的特性之一。
背压是 writable stream 回传给 readable stream 的信号。当 readable stream 读取数据过快并且 writable 的内部缓冲区(由 highWatermarkOption 设置)的填充速度快于它可以被处理的速度时,信号就会发送出去。
该信号提醒 readable stream 先暂停发送更多的数据。Backpressure允许在 readable stream 和 writable stream 之间进行可靠的、基于pull的数据传输。
如果在传输数据时不考虑背压系统,可能会发生一些情况:
系统内存耗尽
当前进程减缓
垃圾收集器压力过大
Backpressure支持可靠、无损和内存高效的数据传输,这是Node.js提供流API的首要目的。
API for Stream Consumers 可用的Stream API
许多Node.js应用程序会使用到流。熟悉 Stream API 可以让你正确地使用和消费「流」。
Consuming Writable Streams 消费可写流
每个 writable stream 的实例都有如下几个方法:
writable.write(chunk[, encoding][, callback])
向流中写入一些数据
如果内部缓冲区满了,方法返回false;否则返回true
writable.end([chunk][, encoding][, callback])
指示写入流不再写入额外的数据。一个可选的「chunk」参数用于在关闭流之前写入最后一块数据。
writable.cork()
强制让所有写入的数据缓冲在内存中。
writable.uncork()
将自上次调用cork()之后的缓冲区的所有数据flush到目标源中。
writable.destroy()
销毁这个stream。
下面的一段代码展示了可写入流实例的简单使用。它没有处理backpressure,这很可能不是你想要的:
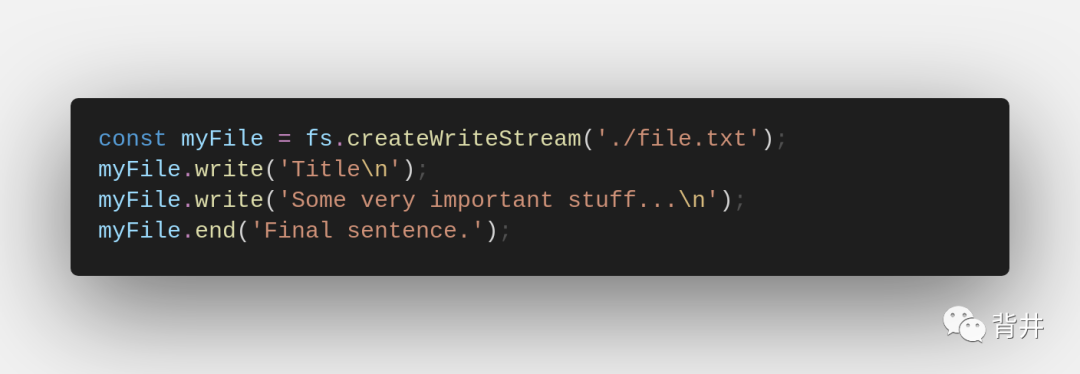
writable stream 可以发出下面这些事件:
drain
在“writeable.write()”由于背压而返回“false”且该压力已被释放后,如果适合继续向流中写入数据,则会生成此事件。
error
如果在写入或通过管道(pipe)传输数据时发生错误,则生成此事件(发出此事件时流还未关闭)。
finish
在调用了“writable.end()”方法并刷新(flush)了所有数据后发出。
close
当流及其任何底层资源关闭时发出。
pipe
在可读流上调用“.pipe()”方法时发出。
unpipe
在可读流上调用“.unpipe()”方法时发出。
下面这个简单的例子,使用了手工的方法将数据适当地写入到 writable stream (没使用 readable.pipe() ),并将背压考虑在内:
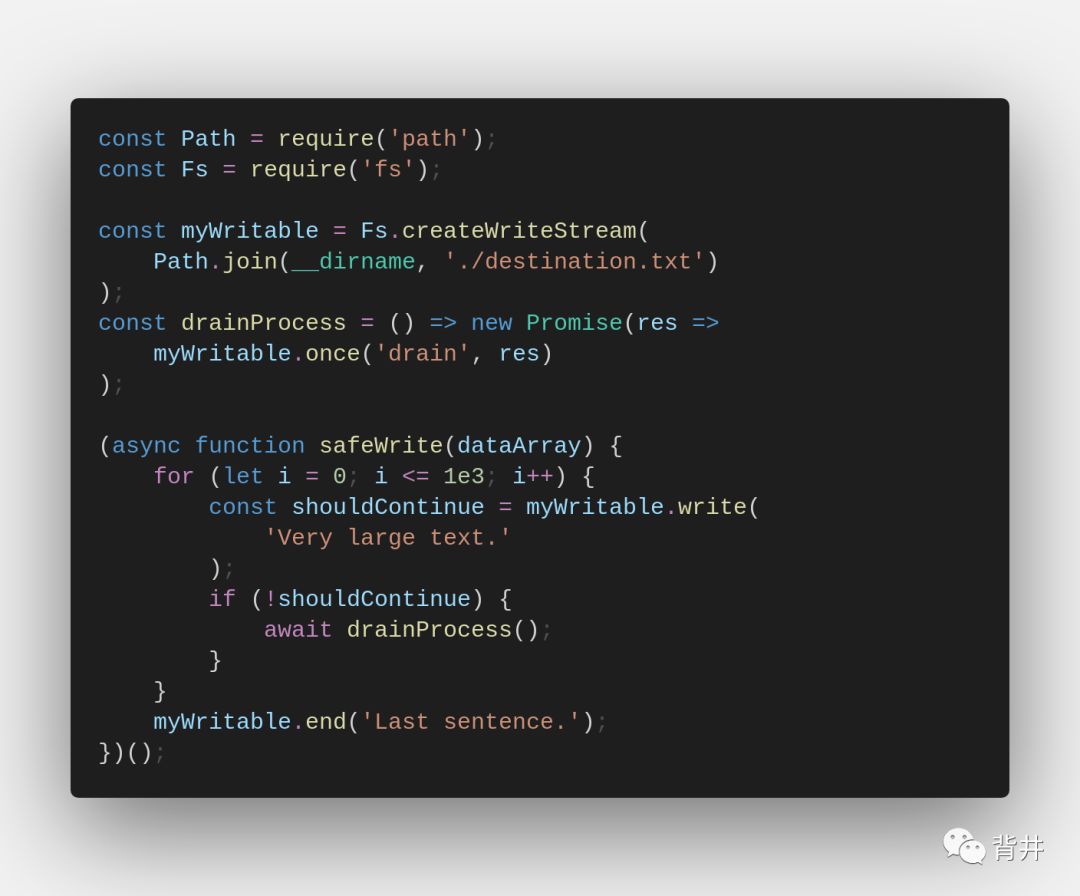
上面是一个简单的例子,因为它只在一个循环中写同一个句子。最重要的是管理背压。
Backpressure,以及其它的一些事项,可以通过“readable.pipe()”方法方便地处理,该方法如下所示:
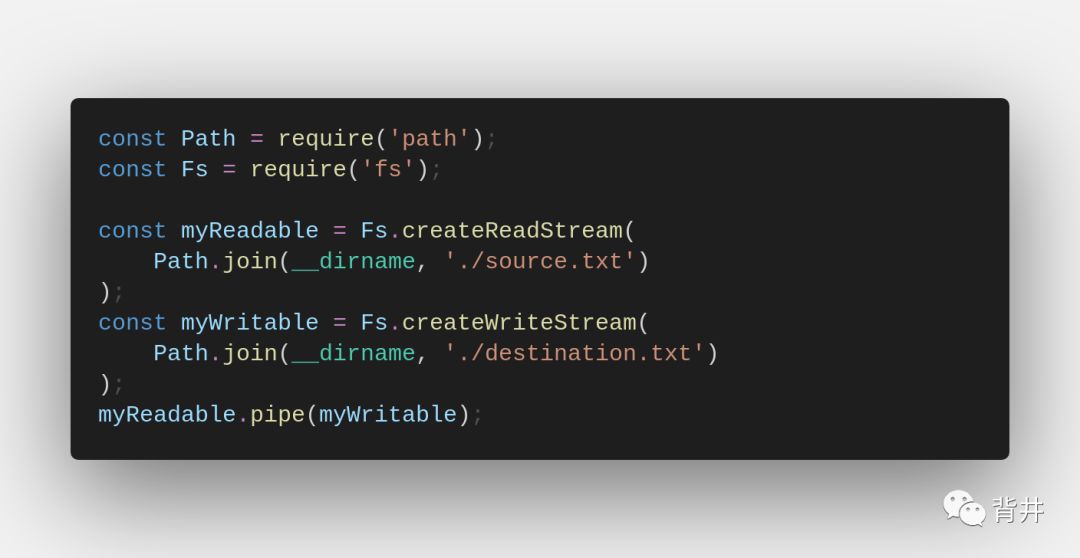
我们将在下文中进一步详细介绍 readable.pipe() 方法。
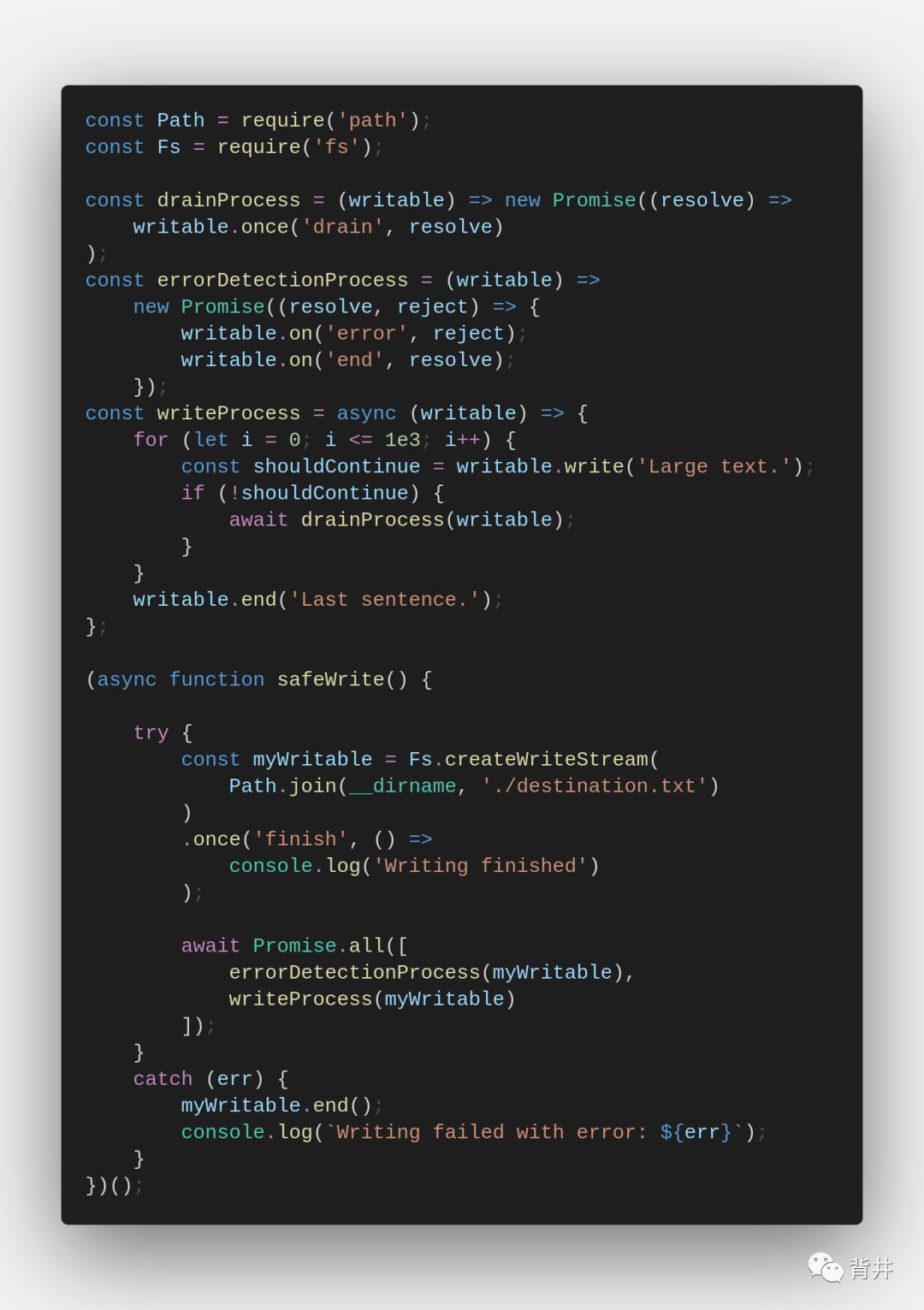
在手工写数据到writable stream时,不仅要关注背压,监听错误也很重要。
下面是一个完整的手动写数据到到 writable stream 的示例,其中考虑了背压、正确的错误处理和写入后操作(我们给的例子中是记录日志):
Consuming Readable Streams 使用可读流
可读流可以在两种模式下工作:
flowing:从底层系统自动读取数据并尽快提供给应用程序
paused:必须显式调用“readable.read()”方法才能读取数据块
(文档中也提到了对象模式 object mode,但它是一个单独的特性,flowing 和 paused 可读流都可以处于或不处于对象模式)
所有可读流都以 paused 模式启动。要从 paused模式 切换到 flowing模式,必须执行以下操作之一,这将在下一节中详细介绍:
添加 data 事件侦听器
调用 readable.resume() 方法
使用 readable.pipe() 将可读流定向到可写流
要切换回paused模式,必须执行以下操作之一:
如果没有 pipe() 目标,则调用 readable.pause()
如果存在 pipe() 目标,则删除这些目标(readable.unpipe()可以帮上忙)
有四种使用可读流的方法。开发人员应该选择其中一种。对于单个可读流,混合使用这些API会导致意想不到的行为。
1. 使用 readable.pause() 、 readable.resume() 和 data 事件:
`data` 事件
当该stream传送数据块时发出(添加监听器后自动切换到flowing模式)
`readable.pause()`
暂停当前流,将其切换到paused模式
`readable.resume()`
将当前流切换为flowing模式
下面一个可读流的例子,它被消耗,数据被写入标准输出。不是特别有用,但它可以作为示范:
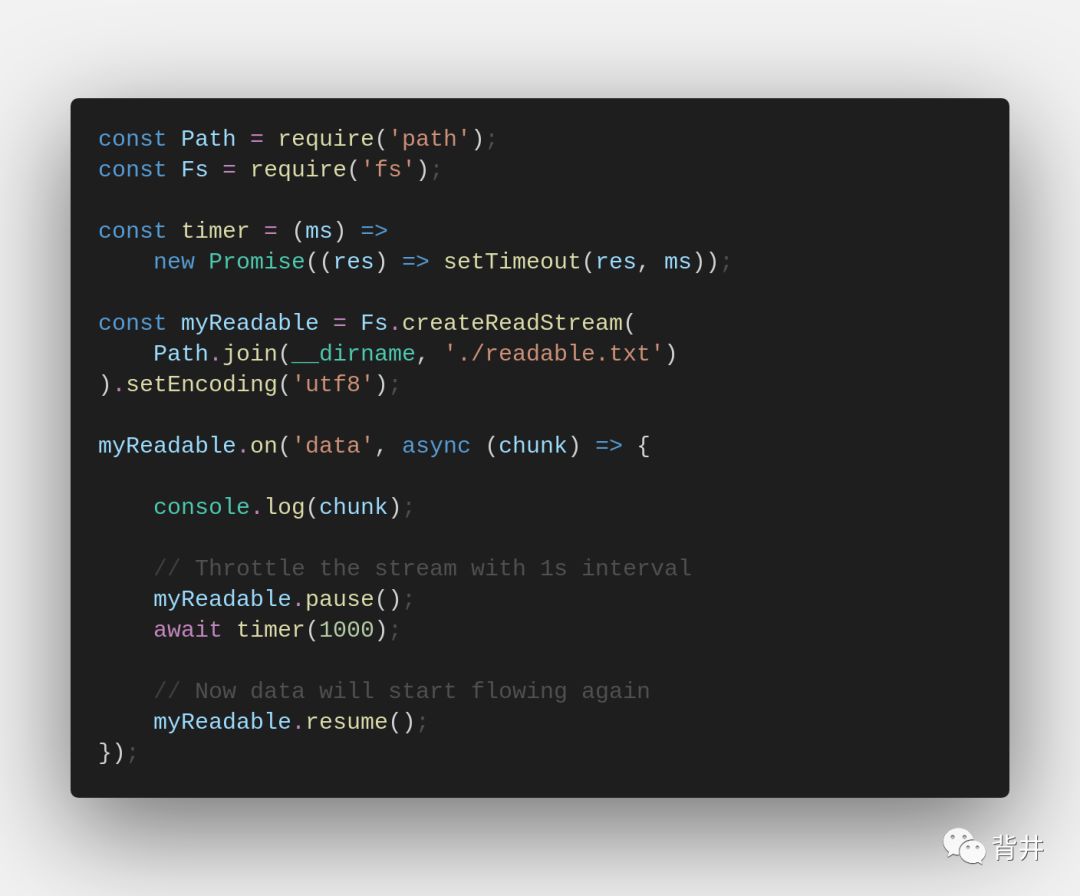
2. 使用 readable.read() 和 readable 事件
`readable` event
在有某些底层数据需要被读取时触发(当添加“readable”监听器后,流切换到paused模式)
`readable.read([size])`
从内部缓冲区中提取一些数据并返回。如果没有要读取的数据,则返回“null”。默认情况下,如果未指定编码,则数据将作为 “Buffer” 返回。
这是一个类似于上面的例子,但是使用了第二种方式来使用可读流:
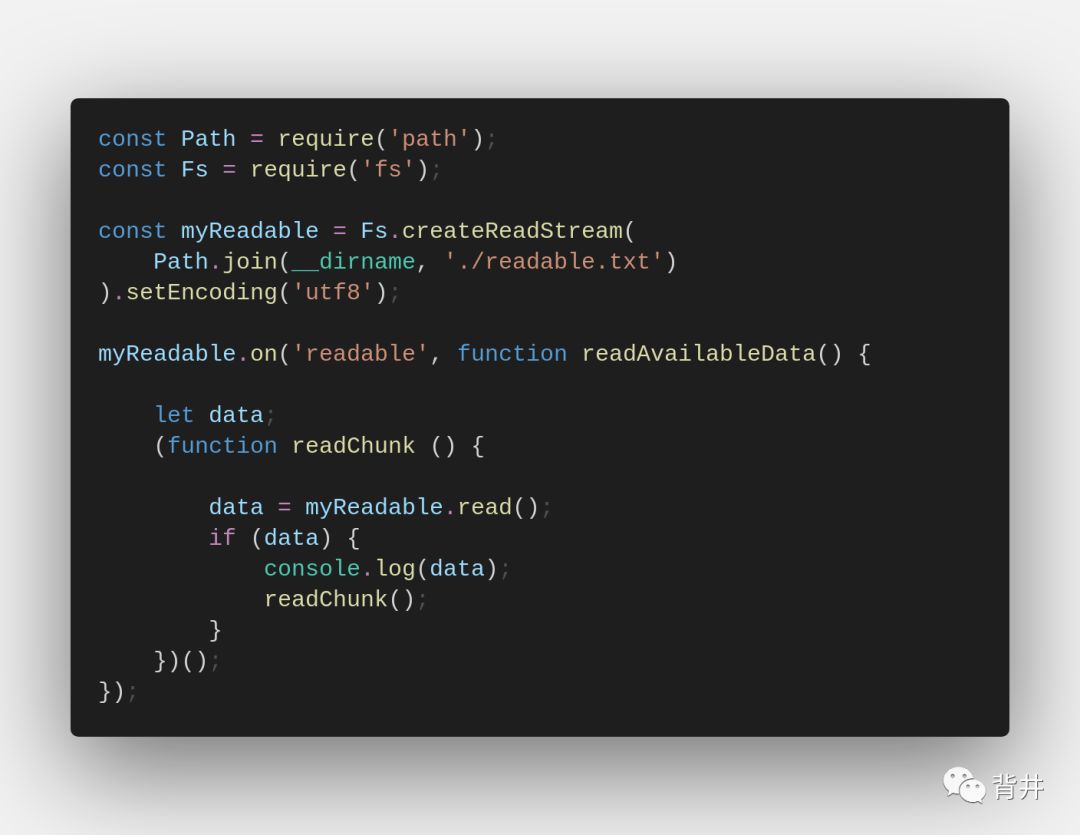
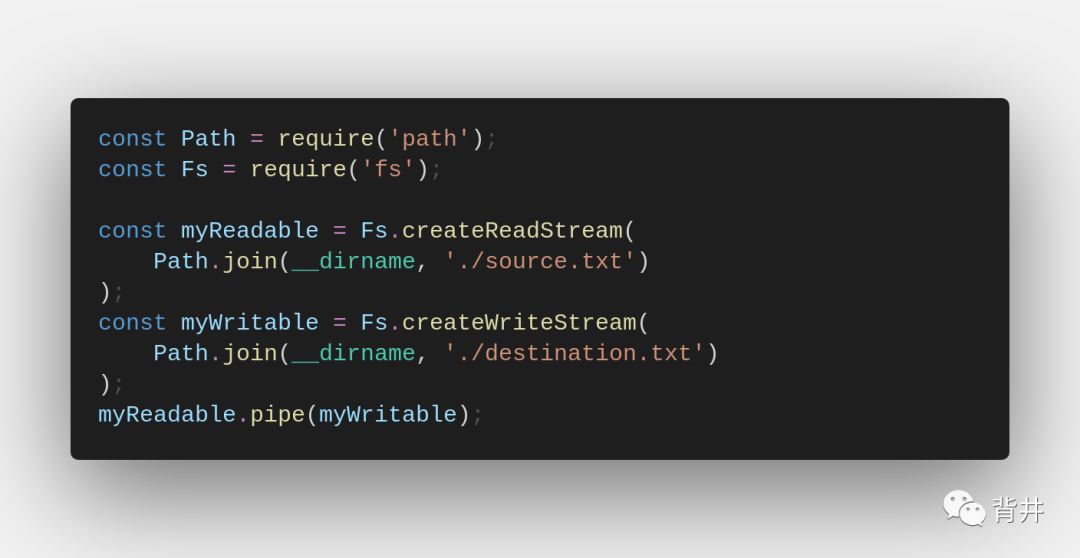
3. 使用 readable.pipe() :
`readable.pipe(writable[, options])`
将可写流附加到可读流,可读流自动切换到flowing模式并使可读流将其所有数据传递到附加的可写流。数据流(即背压)将自动处理。
这是使用可读流的几种方式中最方便的一种,因为它并不冗长,会自动处理背压以及在结束后自动关闭流。
从之前的代码片段中复制的一个简单示例:
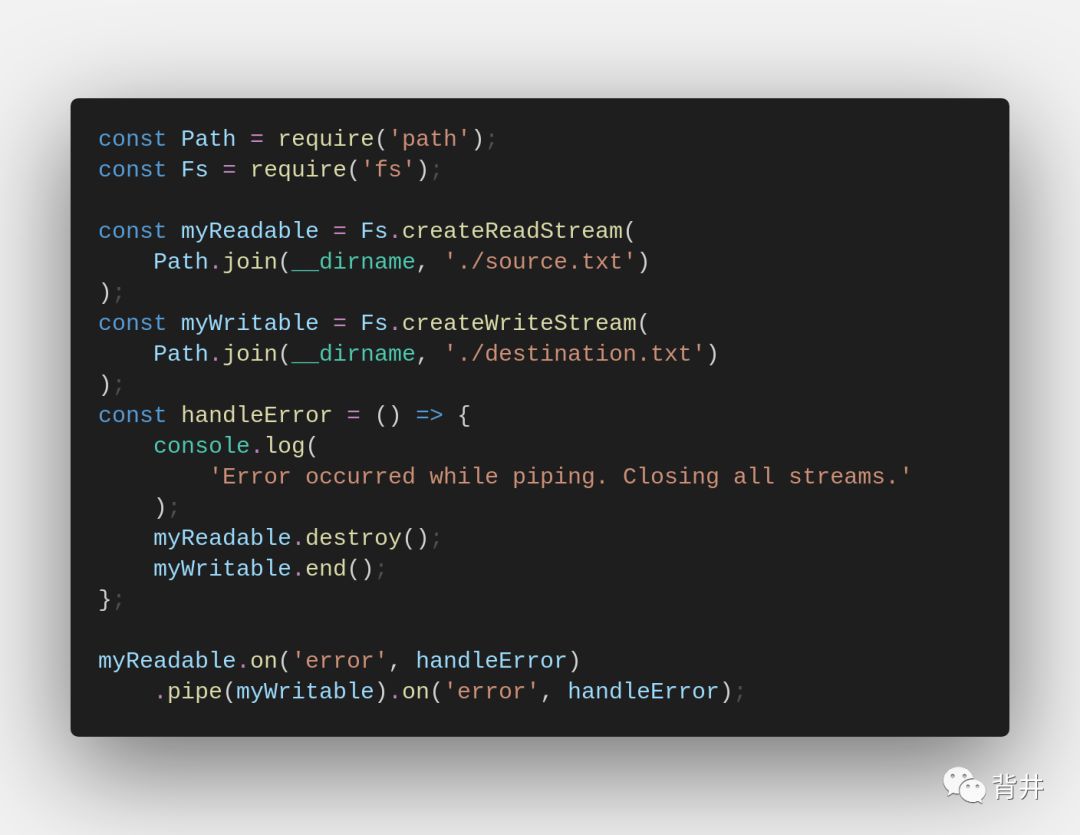
有一样东西不是自动管理的,那就是错误处理和传播。例如,如果要在发生错误时关闭每个流,则必须监听「error」事件。
带有error事件处理的pipe示例:
4. 使用 Async Iteration Async Generator
可读流实现了「Symbol.asyncIterator」方法,因此可以使用'for await of'对它们进行迭代`。
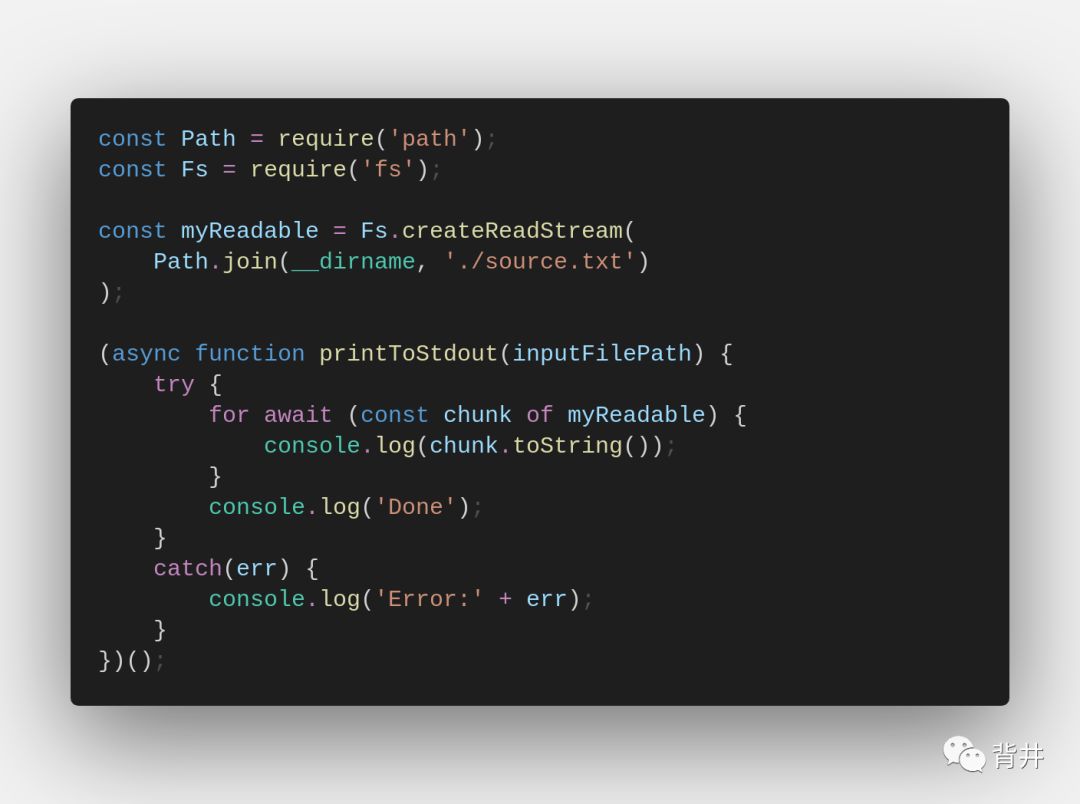
异步生成器(Async Generator)在Node v10+中正式可用。异步生成器是异步函数和生成器函数的混合体。它们实现了「Symbol.asyncIterator」方法,并可用于异步迭代。通常,流是跨时间的数据块集合,因此异步生成器非常适合。下面是一个例子:
Consuming Duplex and Transform Streams 使用双向流和转换流
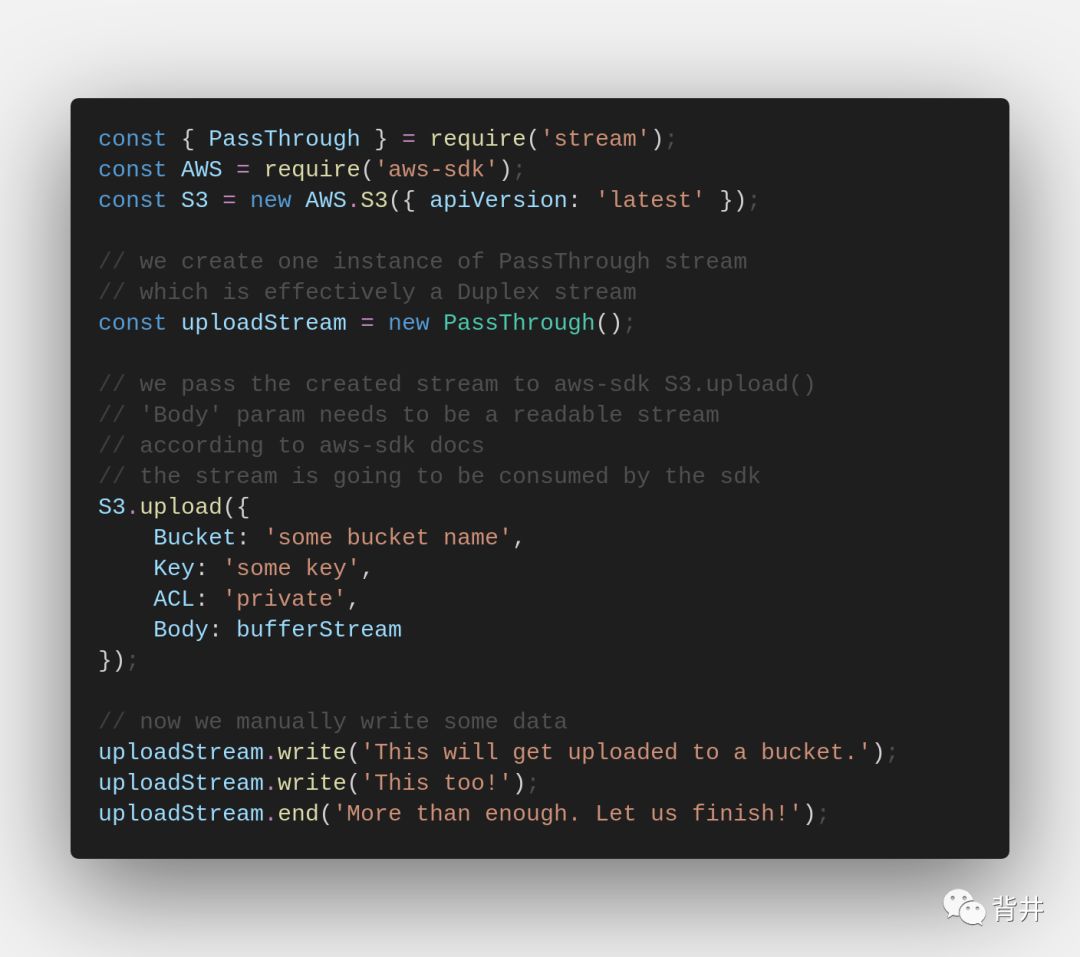
双向流同时实现了 Readable 和 Writable 接口。PassThrough流 就是一种双向流。当某些API期望可读流作为参数,并且你还希望手动写入一些数据时,就使用这种类型的流。
要同时满足两种需要:
创建 PassThrough流 的实例
将流传给API(API将使用这个流的 Readable 接口)
向流中添加一些数据(使用流的 Writable 接口)
过程如下所示(误: 示例中的body应该是uploadStream):
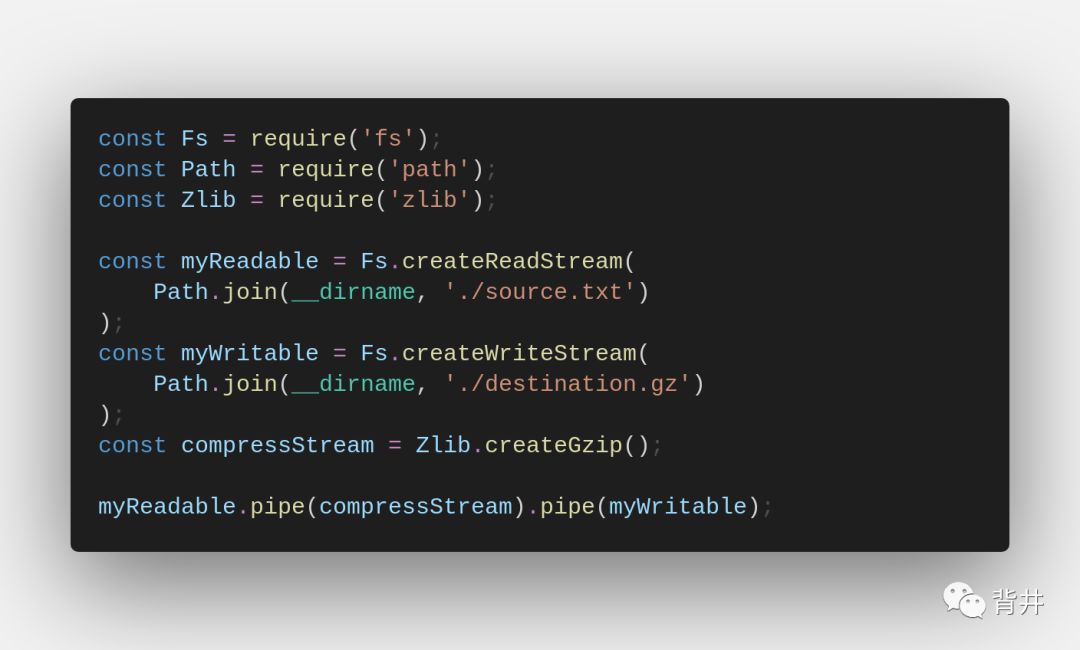
转换流也是双向流。这些流具有可读和可写接口,但它们的主要目的是转换传递的数据。
最常见的示例是使用来自“zlib”模块的 内置转换流 压缩数据:
Useful class methods 有用的类方法(Node v10+)
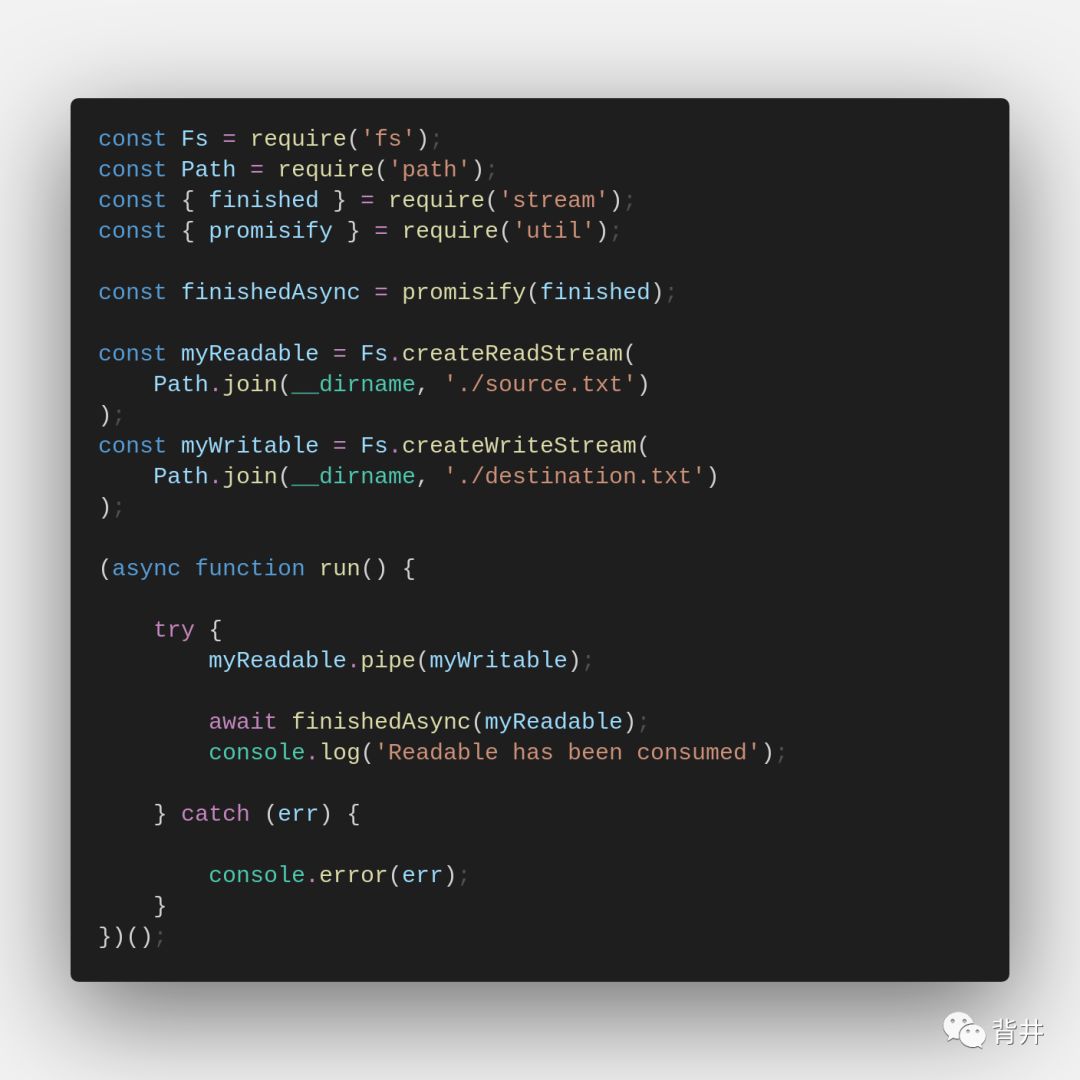
Stream.finished(stream, callback)
允许我们在流不再可读、不可写或遇到错误或过早关闭时收到通知。
此方法对于错误处理或在流被使用后执行进一步操作时非常有用。例如:
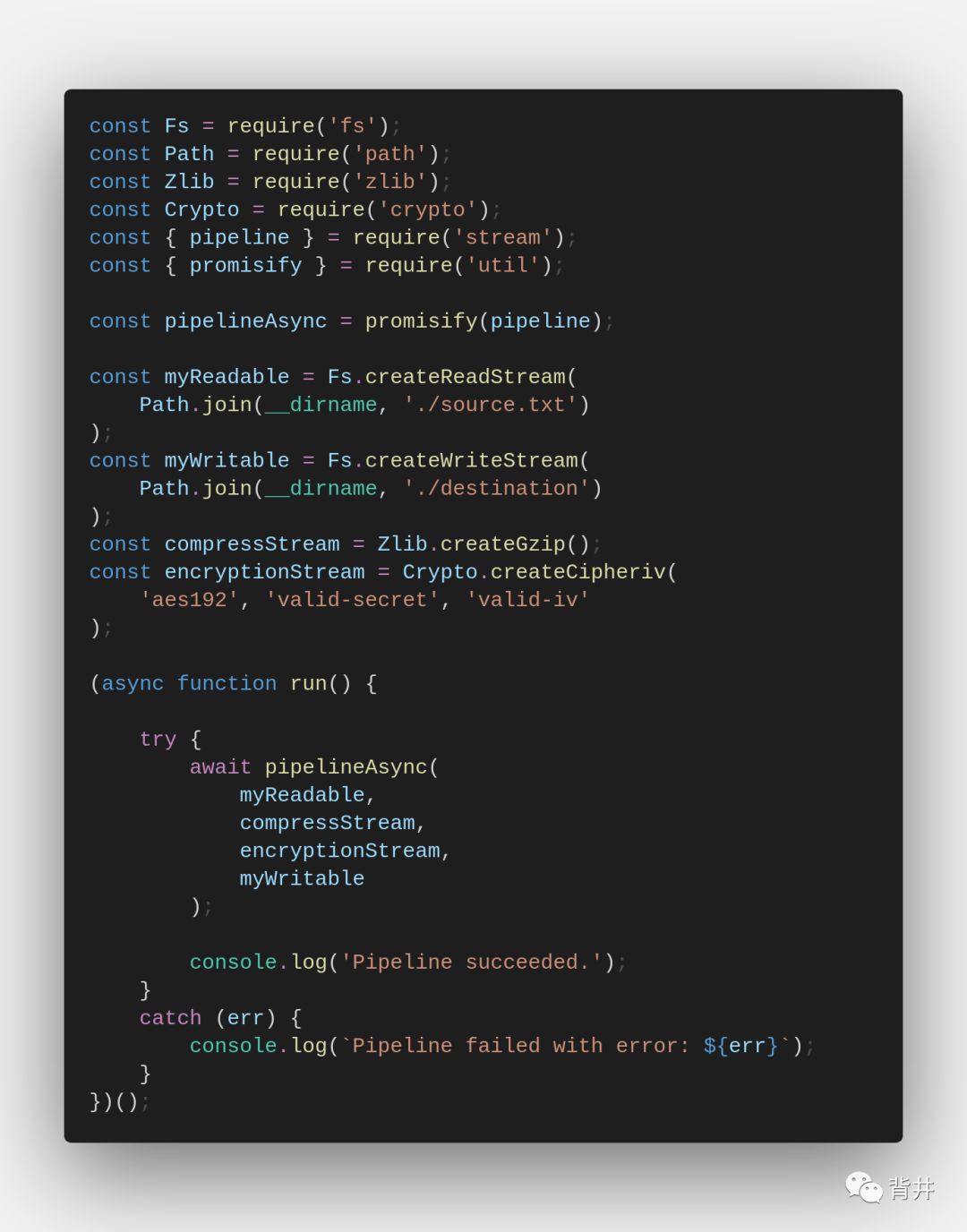
Stream.pipeline(…streams[, callback])
该方法允许在多个流之间进行pipe操作,并提供了完整的错误处理、资源清理和结束时回调。
该方法是建造pipeline最干净和最简洁的方式。与 readable.pipe() 不同,所有内容都是自动处理的,包括错误传播和进程结束后资源的清理。例如:
API for Stream Implementers 给Stream实现者的API
Stream API是可扩展的,它为开发人员提供了一个接口来创建他们自己的扩展。有两种方法可以实现你自己的Stream。
1. 扩展适当的父类
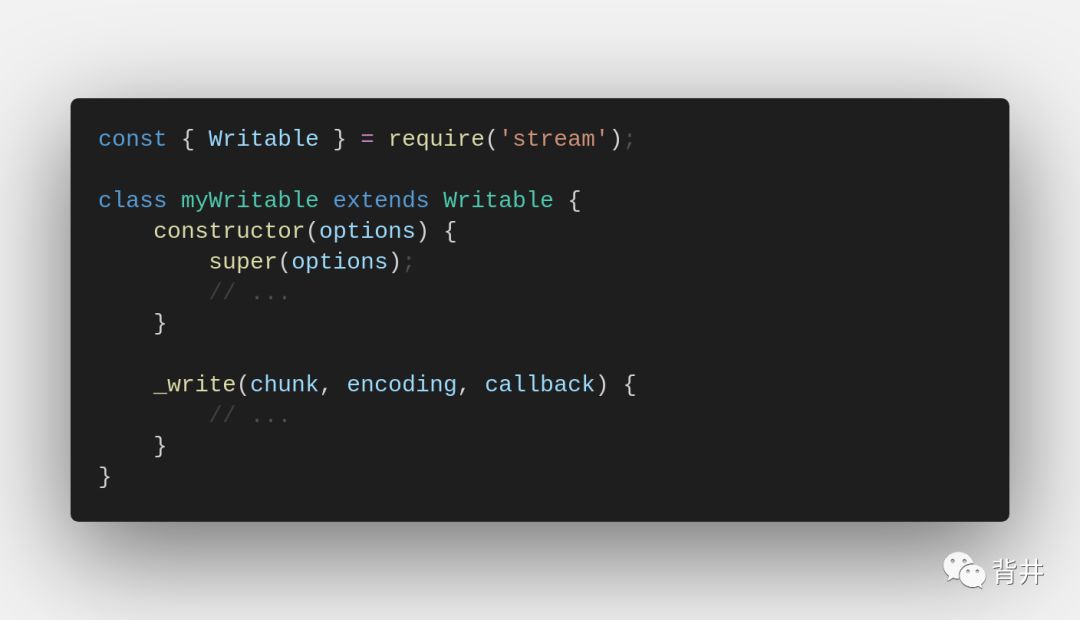
新的stream类必须实现一个或多个特定的方法,具体取决于所创建的流的类型(我们在对每种类型的流进行实现时,会列出这些方法)。
这些方法都以下划线作为前缀,它们只在实现新流时使用。如果用户在使用时调用它们,将导致意外行为(即,这些方法是给实现者用的,不是给用户端用的)。
2. 通过直接创建实例并提供适当的方法作为构造函数的参数,以简化的方式扩展流:
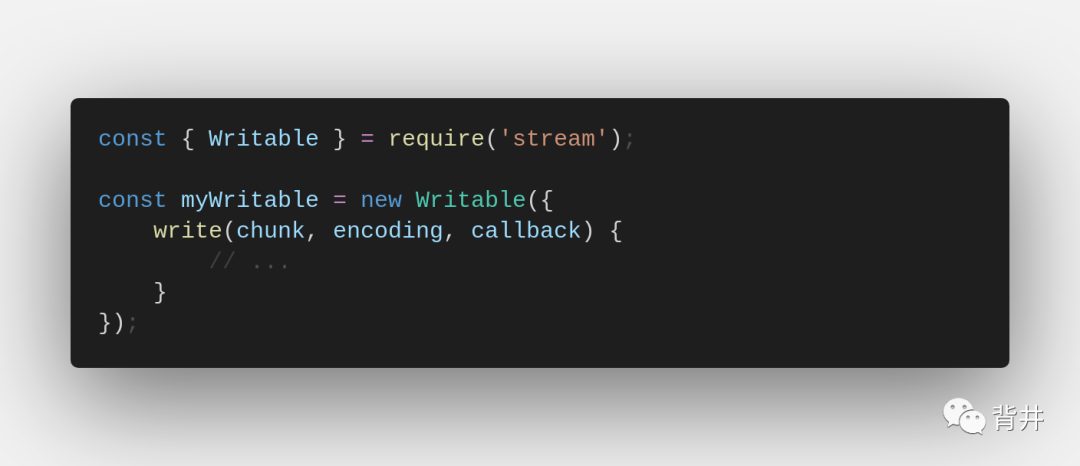
要特别记住的是,在这种情况下,所需方法不需要下划线前缀。
实现 Writable Stream
为了实现可写流,我们需要提供一个 writable._write() 方法来向底层资源发送数据:
`writable._write(chunk, encoding, callback)`
chunk:要写入的chunk 数据块
encoding:如果块是 String 类型,则需要指定
callback:在写入已完成或失败时必须调用此方法
一个简单的writable stream的实现:
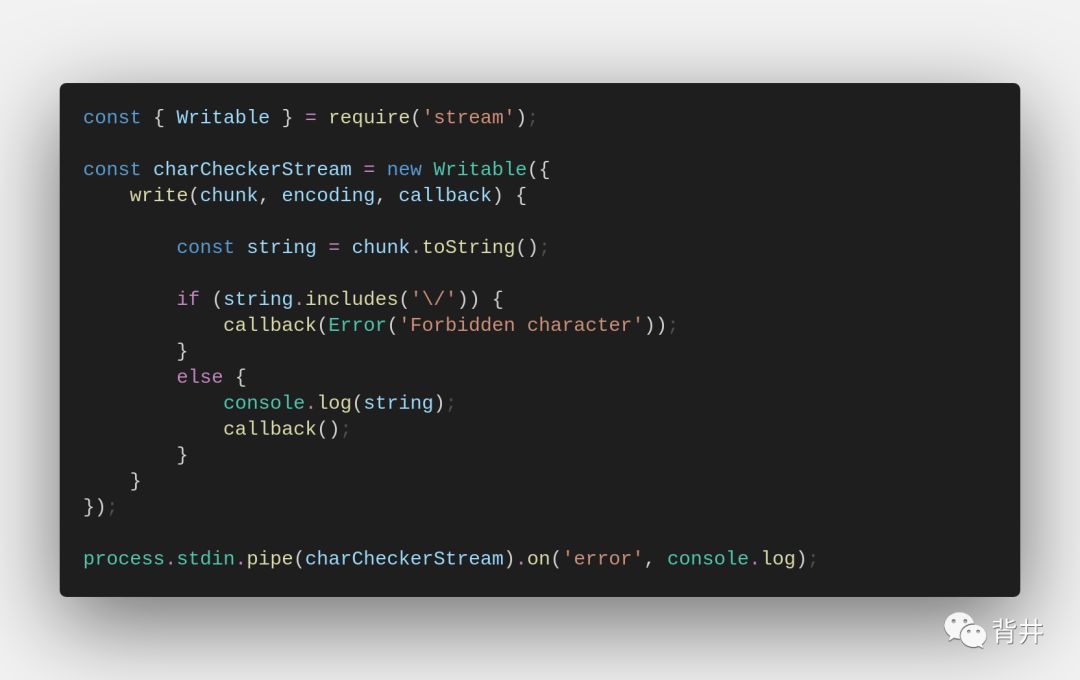
此流将标准输入打印到标准输出,当输入「/」时,流抛出异常。这个例子是出于演示的目的而写。
实现一个Readable Stream
要实现自定义的可读流,我们必须调用其构造函数并实现 readable._read() 方法(其他方法是可选的),且read方法内部必须调用 readable.push() :
`readable._read(size)`
调用此方法时,如果源中有数据可用,则实现者应调用 this.push(dataChunk) 方法将该数据推入读取队列
size:要异步读取的字节数
`readable.push()`
仅由实现者调用,并且只能从 readable._read() 方法中调用。调用时,数据块将添加到内部队列中,供流的用户使用(“null”是一个终止字符)。
下面这个可读流的实现,是在一分钟内每秒生成1到10的随机整数,然后结束数据生成并关闭自身。
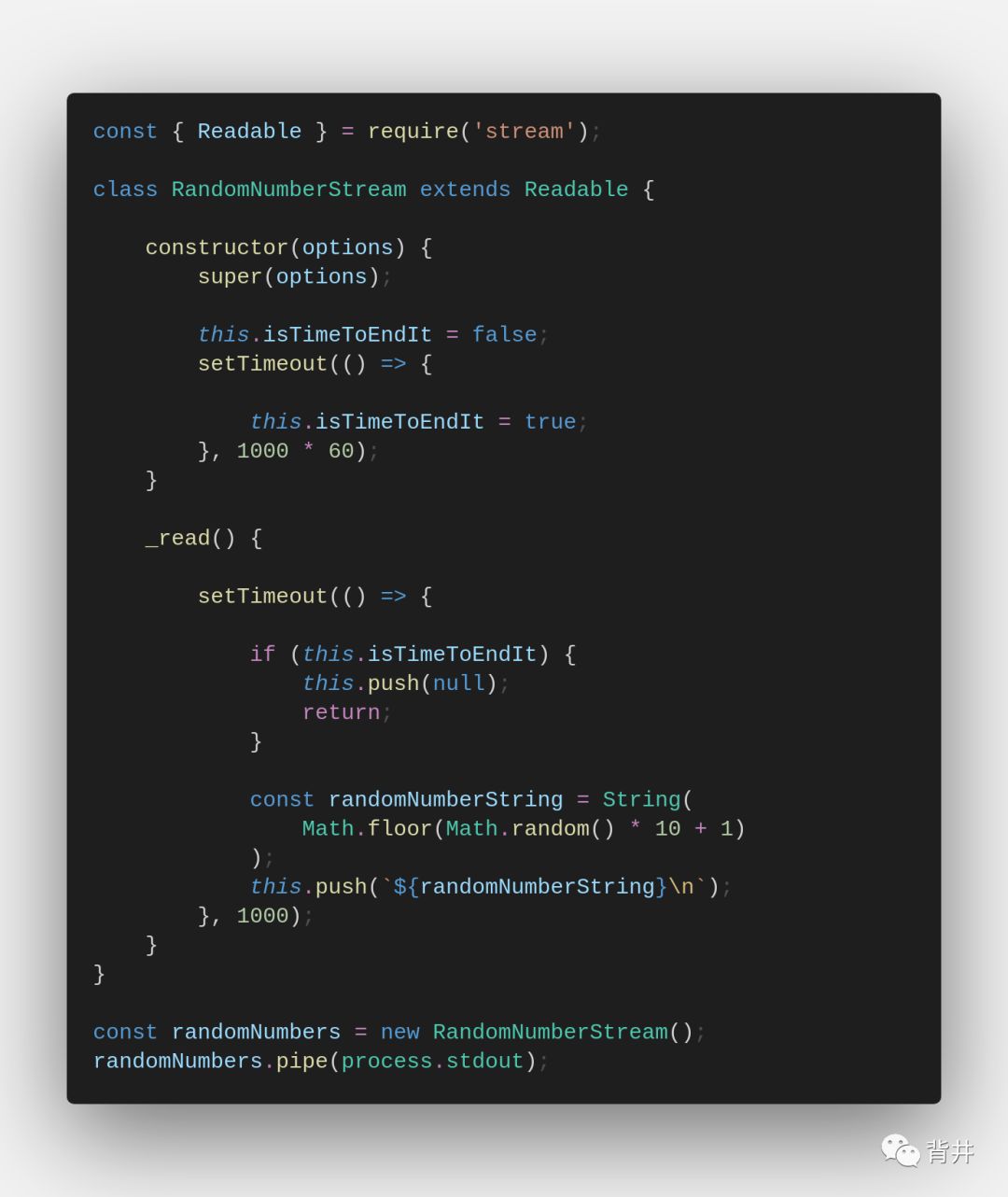
实现一个Duplex Stream
双向流实现了可读和可写接口,它们彼此独立。Duplex类的prototype继承自stream.Readable,寄生于stream.Writable(JavaScript不支持多重继承)。
要创建双向流的自定义实现,必须实现可写和可读流的每个必需方法,即 readable._read() 和 writeable._write() 。
下面的流将 stdin(可写端)的内容打印出来,并将一些随机表情写出到stdout(可读端),直到sad smiley(:()出现,随即终止可读流。

实现一个Transform Stream
转换流类似于双向流(其实它是双向流的一种),但具有更简单的接口。输出是根据输入计算出来的。不要求输出与输入的长度相同,不要求数据块的数量相同,也不要求数据同时到达。
实现转换流只需要一个方法,即 transform._transform() 方法(“transform._flush()”是可选的)。
`transform._transform(chunk, encoding, callback)`
处理正在写入的字节,计算输出,然后使用“readable.push()”方法将输出传递给可读部分。可以为一个接收的块多次调用来生成输出,或者根本不生成输出
chunk:要写入的数据块
encoding:String类型的块需要指定此值
callback:(err,transformedChunk)
`transform._flush(callback)` — 可选.
在某些情况下,当一些计算完成时,转换操作可能需要在流的末尾发出额外的数据。在流结束之前,此方法刷新数据。
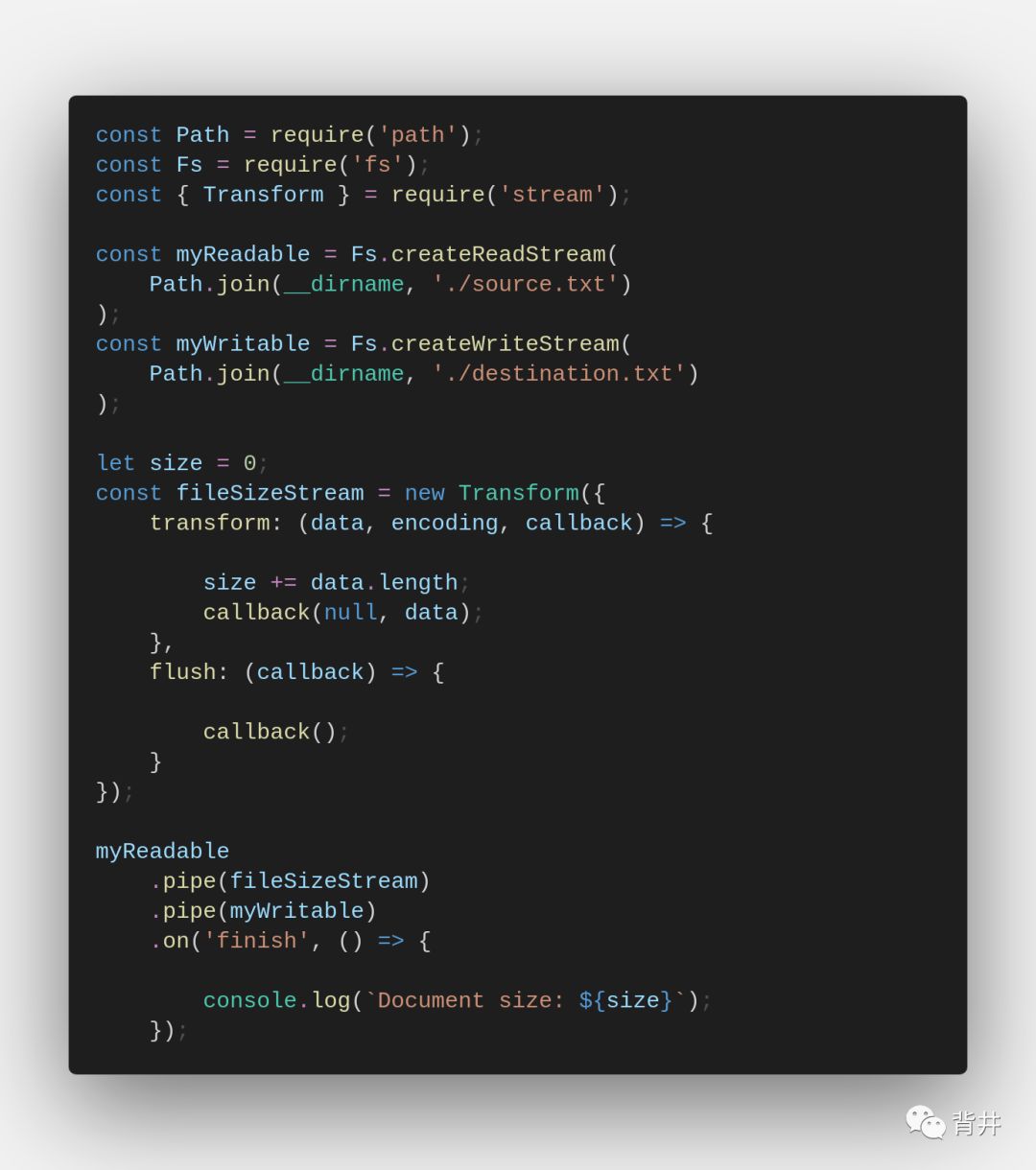
总结
通过本文,我们学习了如何使用Node.js的所有Stream类型。我们还学习了如何实现自己的Stream并利用好它们强大的功能。
Node.js的Stream以难以使用而闻名,但是伴随对它们独特的API的理解,它们也会成为开发者非常宝贵的工具。
