




这是Dgraph系列文章的第二篇。在上一篇中,我们学习了Dgraph的基本知识,包括运行Dgraph、添加新的nodes和predicates,以及查询它们。
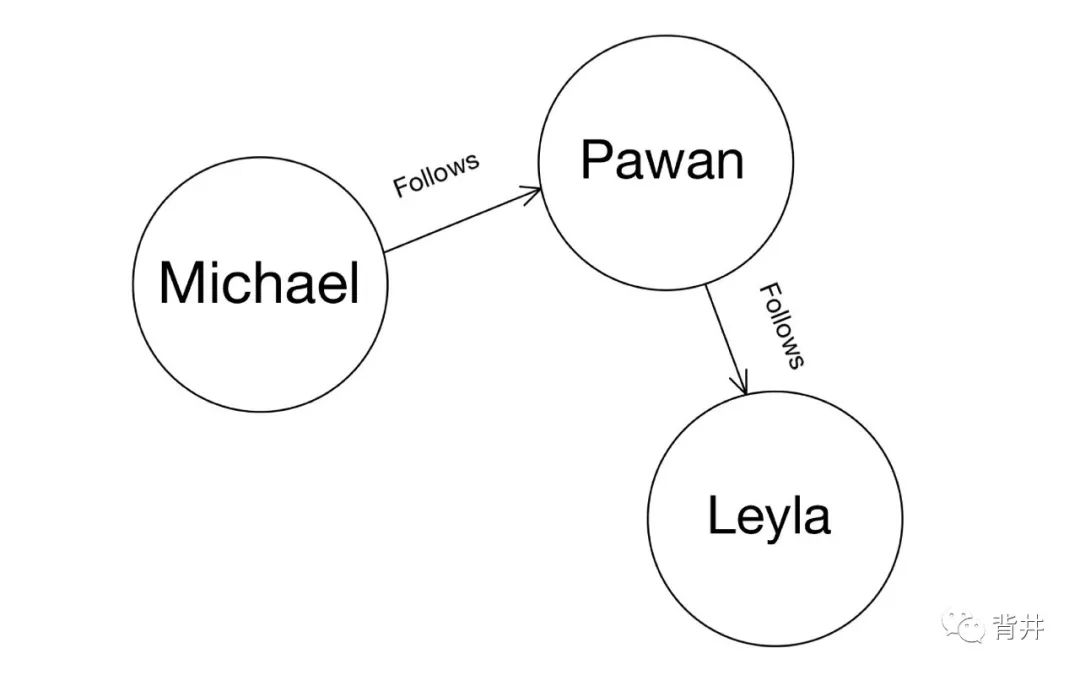
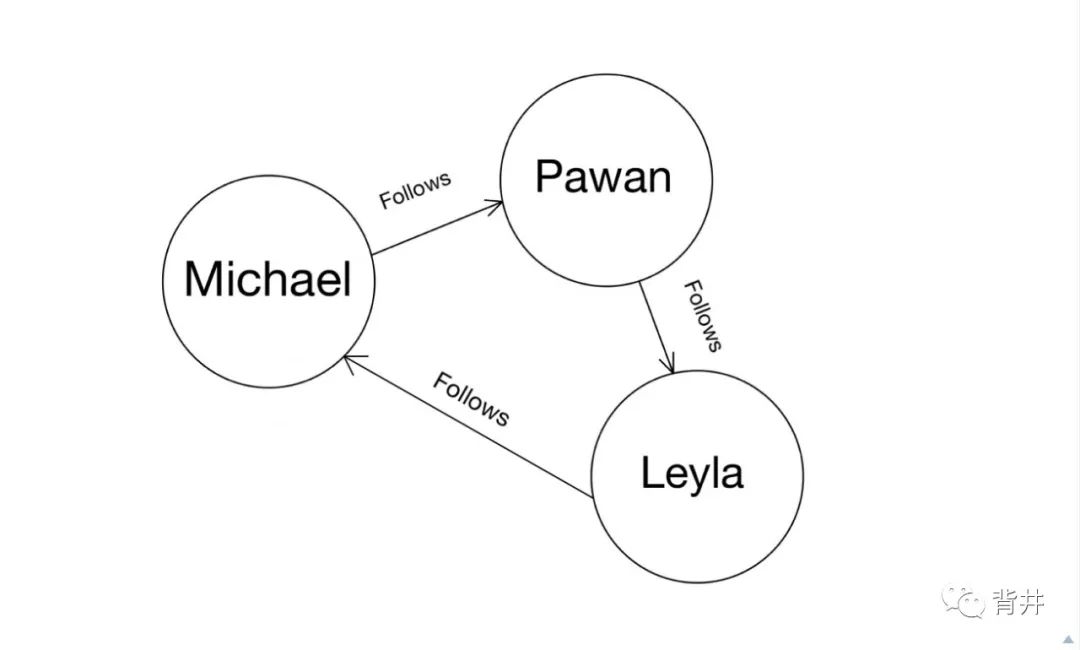
在本篇中,我们将打造上图所示的Graph,并利用 UID 来学习更多的操作。确切地说,我们将学习:
基于UIDs查询、更新nodes或删除predicates
为已有的nodes添加edge
为已有的node添加predicate
遍历这个Graph
首先,让我们创建该Graph。
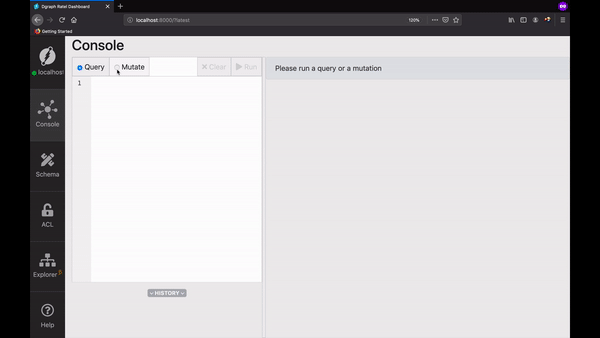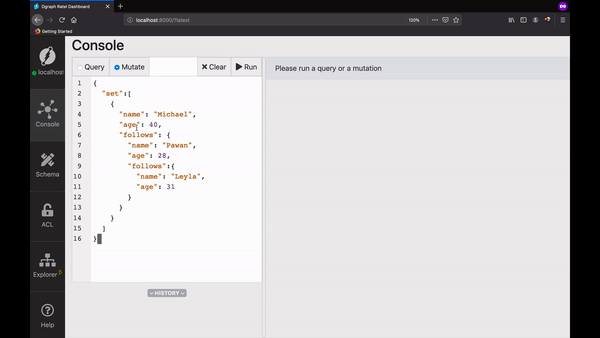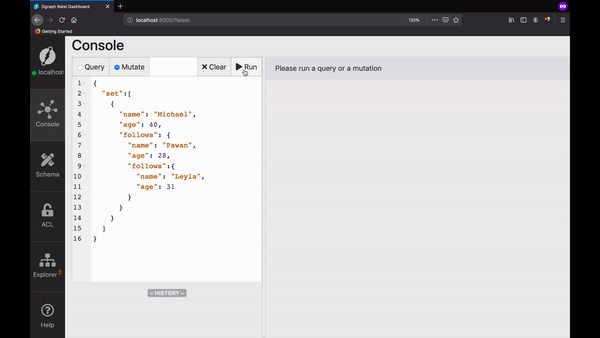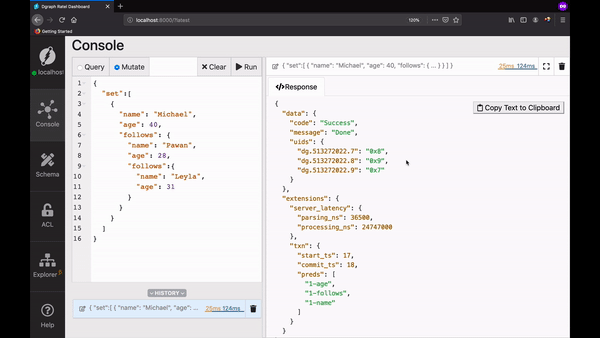
打开Ratel的 mutate tab 面,复制并运行以下内容:
{"set":[{"name": "Michael","age": 40,"follows": {"name": "Pawan","age": 28,"follows":{"name": "Leyla","age": 31}}}]}
基于UIDs的查询
我们可以基于nodes的UID来查询这些nodes。内置的 uid 函数接收一组 UIDs 作为变长参数,这样我们既可以传入一个 UID(如 uid(0x1)) 也可以按需传入多个(如 uid(0x1,0x2))。
uid 函数返回的UID和我们传入的一样,不管UID在数据库中是否存在。但是只有当UID以及它们所关联的predicates存在时,返回值中才会出现所要求的predicates。
uid 函数实战。
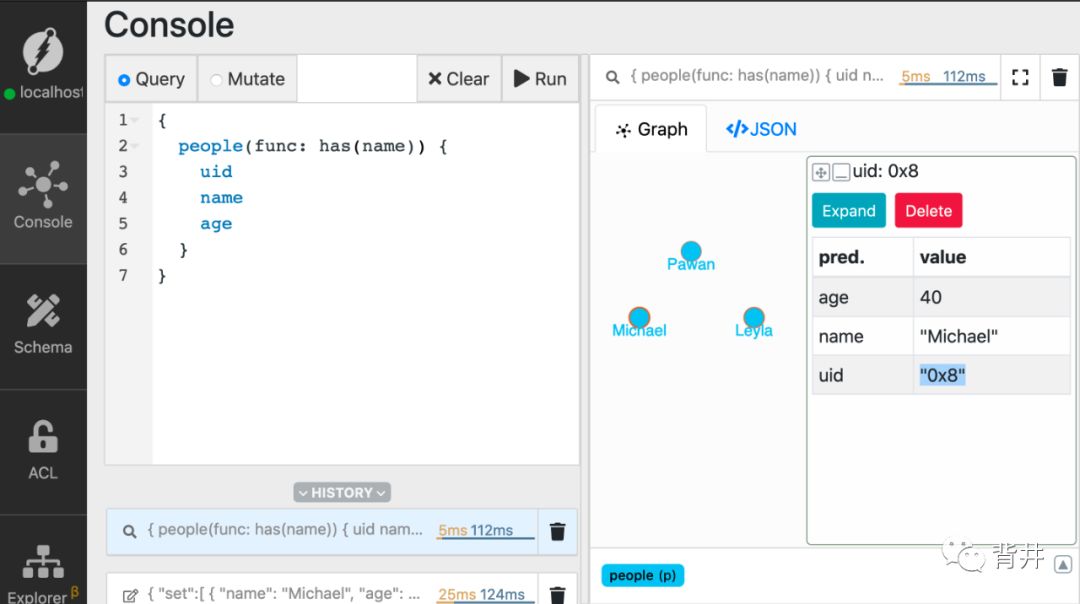
首先,复制 Michael 所在node的 UID。
打开 query tab页,键入以下查询并运行。
{people(func: has(name)) {uidnameage}}
现在,我们可以从结果中复制 Michael所在node的UID了。
在下面的查询中,将 MICHAEL_UID 替换为刚才复制的uid,并运行。
{find_using_uid(func: uid(MICHAELS_UID)){uidnameage}}
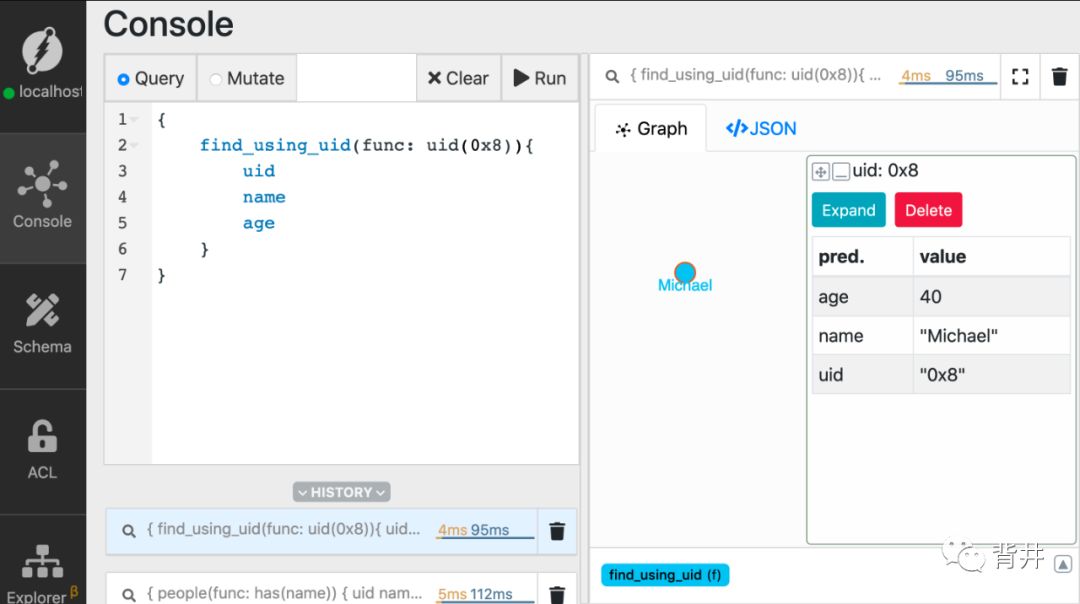
可以看到,uid 函数返回的 node 正好匹配 Michael所在的node。
如果对于上面的查询语法有疑问,可以阅读上篇文章。
更新 predicates
我们也可以基于UID,更新node的一个或多个predicates。
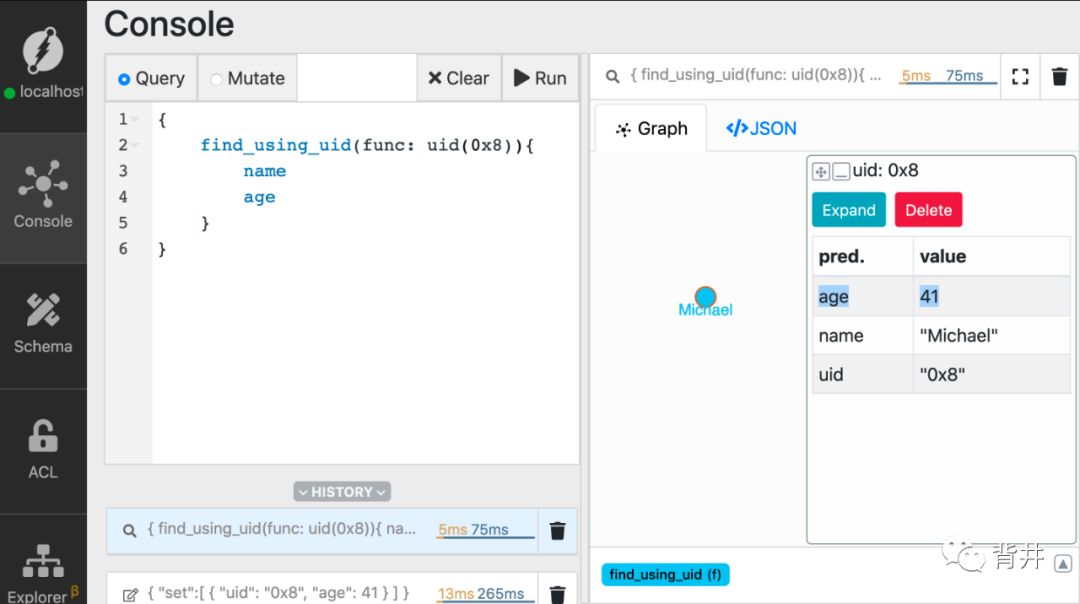
Michael最近庆祝了自己的41岁生日。我们来把他的年龄更新为41。
打开mutate tab页 执行下面的语句。同样,别忘了将 MICHAEL_UID替换为真实的值。
{"set":[{"uid": "MICHAELS_UID","age": 41}]}
我们之前有使用 set 来创建新的nodes。但是当我们使用了已有node的UID时,它将会更新该node的predicates, 而不是创建一个新的node。
可以看到,Michael的年龄变成了41。
{find_using_uid(func: uid(MICHAELS_UID)){nameage}}
类似地,我们也可以给已有的node添加新的predicates。既然 Michael 所在node没有 country predicate,下面语句将为它添加这个predicate。
{"set":[{"uid": "MICHAELS_UID","country": "Australia"}]}
为已有的nodes添加edge
也可以基于UIDs为已有的nodes添加edge。
比方说,Leyla 开始关注 Michael。
我们知道,他俩的这个关系需要一个名为 follows 的edge来指明。
首先,我们复制 Leyla 和 Michael 所在node的UID。
然后,将下面的 LEYLA_UID和MICHAEL_UID替换为刚才复制的值,并执行它。
{"set":[{"uid": "LEYLAS_UID","follows": {"uid": "MICHAELS_UID"}}]}
遍历 edges
Graph 数据库提供了一些特有的能力。Traversals(遍历) 是其一。
Traversals解决的是有关nodes之间关系的问题。因此像这类查询——Michael关注了谁?—— 可以通过遍历 follows 关系查得。
让我们运行一个 traversal 查询,并具体地理解一翻。
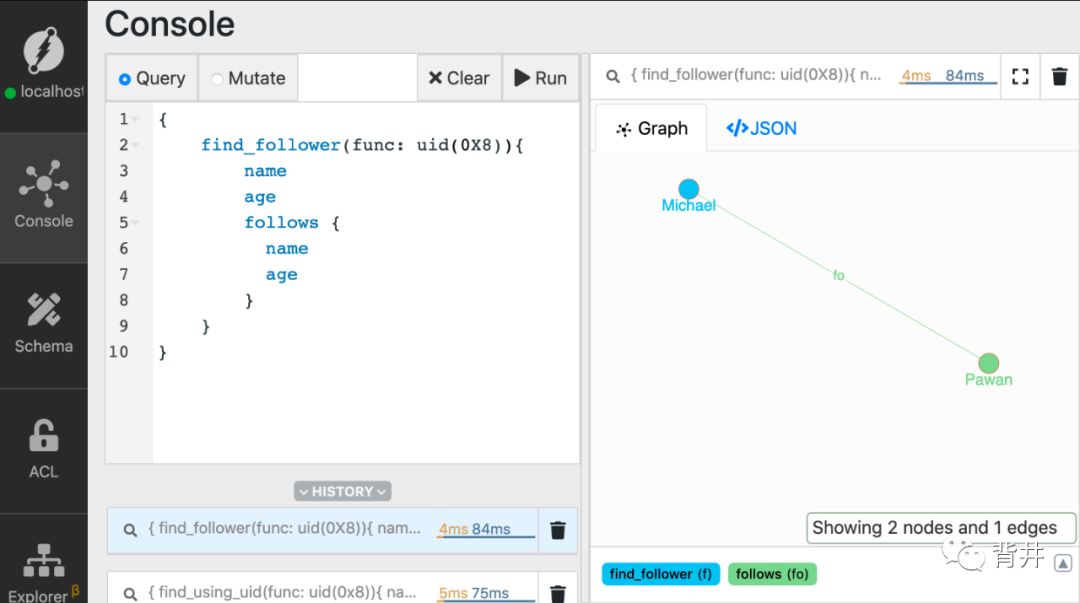
{find_follower(func: uid(MICHAELS_UID)){nameagefollows {nameage}}}
这是结果。
该项查询涉及3个部分:
定位出root nodes
首先,需要选中一个或多个用来遍历的起始nodes。它们被叫作 root nodes。在上面的查询中,我们使用 uid 函数将 Michael所在node 作为 root node。
选出需要遍历的edge
需要指定遍历哪个edge。接着,遍历将会沿着edge往下走,从一个node到它连接的另一个node。
指明需要返回的predicates
既然Michael只关注了一个人,该次遍历只会返回一个node。返回的是一个 2级nodes。root nodes此时是 1级nodes。同样,也需要指明2级nodes要返回哪些predicates。

我们也可以修改这个查询,利用2级nodes进一步遍历更深层次的nodes。下一段将继续探索这个问题。
多层遍历
第一层遍历返回的是Michael关注的人。下一层的遍历进一步返回了这些被Michael关注的人所关注的人。
该模式可以重复多次来实现多层遍历。随着遍历的深入,查询的层级也会一步一步加大。
{find_follower(func: uid(MICHAELS_UID)) {nameagefollows {nameagefollows {nameage}}}}
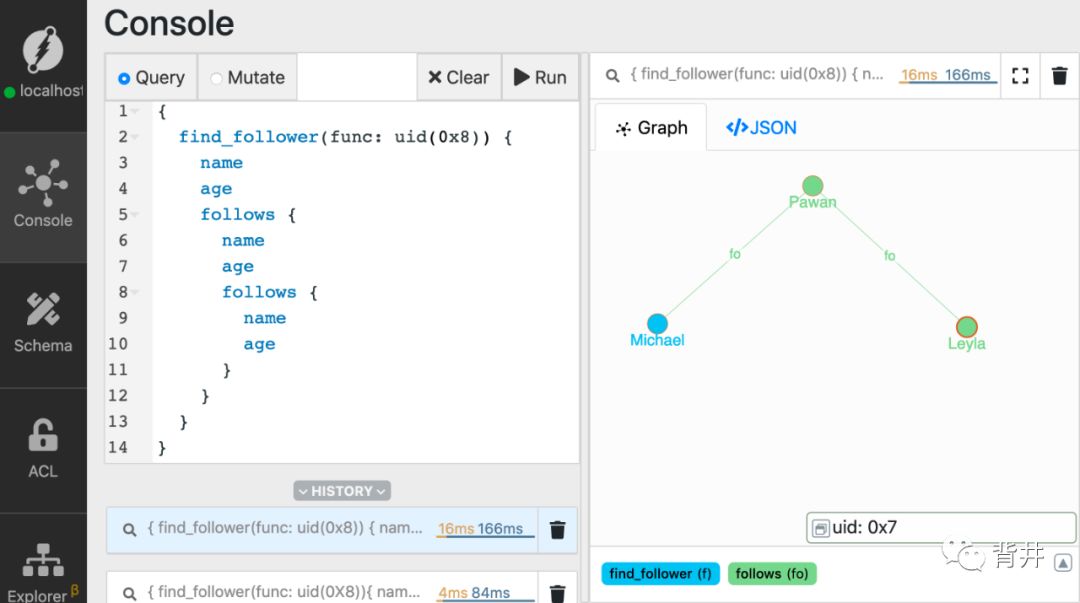
再深入一些:
{find_follower(func: uid(MICHAELS_UID)) {nameagefollows {nameagefollows {nameagefollows {nameage}}}}}
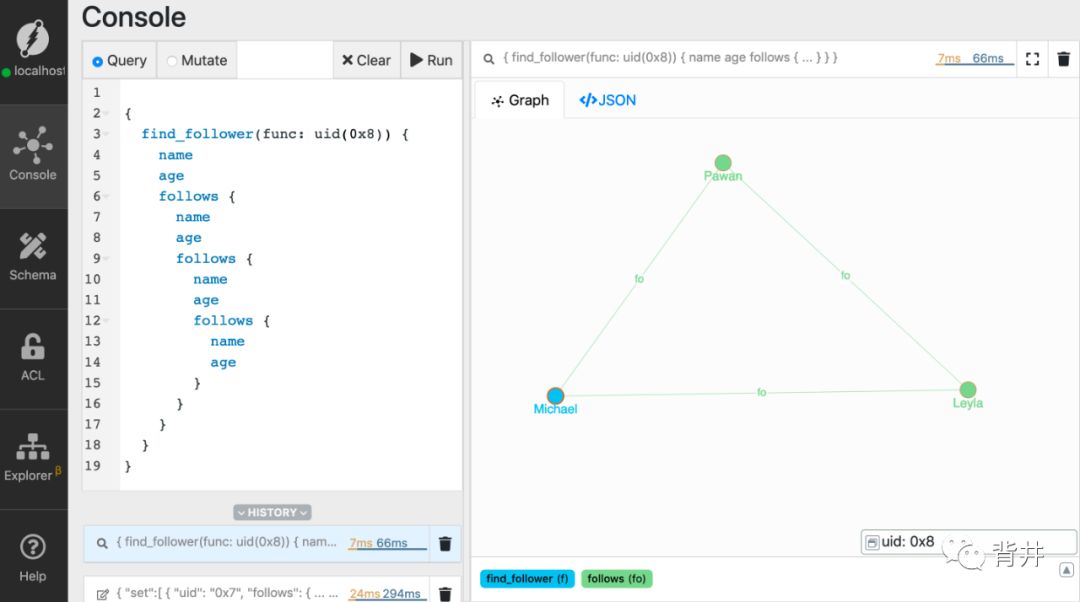
这个查询真是太长了。有4层深。换句话说,查询的深度是4。你可能要问了,有没有什么内置的函数,使得多层遍历简单一些?
答案是 Yes!这正是 recurse() 函数要做的。
递归遍历
递归查询让多层级深度遍历变得简单。它让你可以轻易地遍历一个Graph的一部分。
以下面的递归查询为例,它实现的效果和上面的查询一样。但是体验上更好了。
{find_follower(func: uid(MICHAELS_UID)) @recurse(depth: 4) {nameagefollows}}
在上面的查询中,recurse函数从Michael所在节点开始遍历graph。你也可以选择任何其它的node作为起始node。depth参数指定遍历的深度。
执行的结果如下:
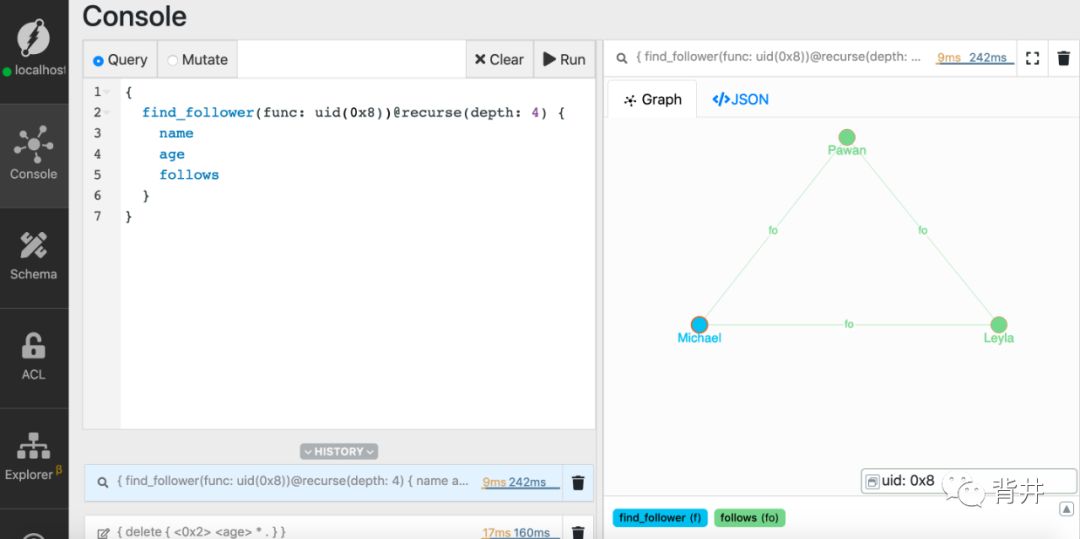
Edges有其方向性
在Dgraph中,edges是有方向的。
例如,follows edge 从Michael开始,然后指向Pawan。它有着方向性。
在Dgraph中沿着edge的方向遍历是再正常不过了。在后续的系列中,我们还将讨论反方向遍历edges。
删除predicate
node 的 predicates 可以使用 delete mutation 进行删除。下面是删除node中predicate的语法:
{delete {<UID> <predicate_name> * .}}
使用上面的语法,删除Michael的 age predicate:
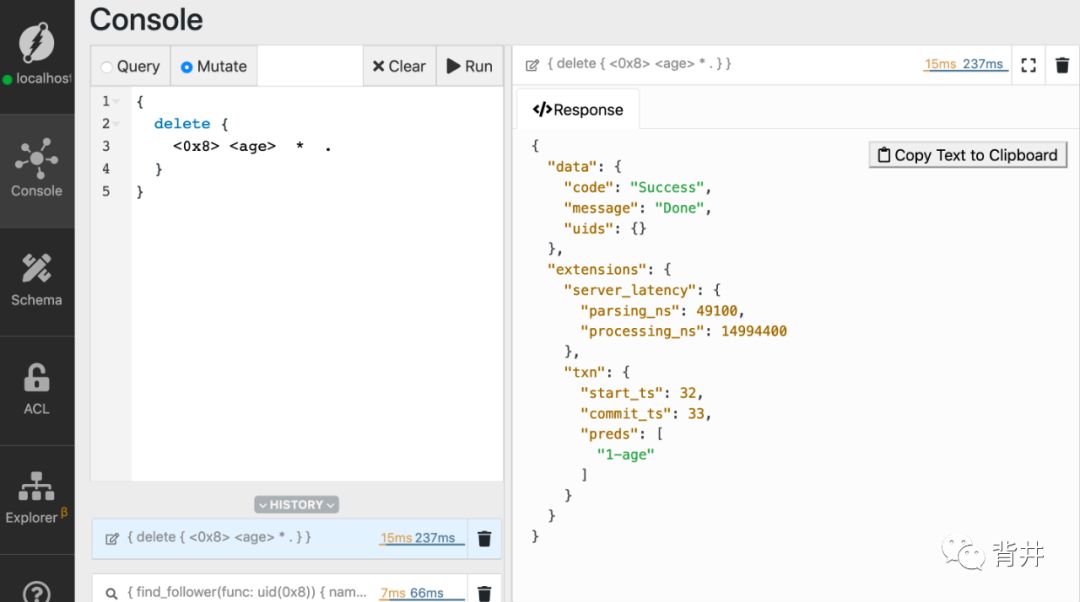
{delete {<MICHAELS_UID> <age> * .}}
总结
本文讲述了Dgraph中基于UIDs的CRUD操作。我们同时也学习了 recurse() 函数。
下一回文章将介绍基于 predicates值的查询。
下次见喽。
