




本文译自 Jérôme Petazzoni 所写的 Kubernetes Deployment: The Ultimate Guide, 原文地址 https://semaphoreci.com/blog/kubernetes-deployment.
准备部署docker化的app? 这里有你所需要的关于Kubernetes deployments的一切,来帮助你把容器化的应用部署到生产。
当学习Kubernetest时,我们用的前几个命令之一就是 kubectl run。有Docker经验的朋友会把它和 docker run 作对比,并且想当然的认为:"哈,运行容器就是这么简单!"
结果却是,当我们使用Kubernetes时:

我们看一下,当运行完一个非常基础的 kubectl run 命令后,发生了什么:
$ kubectl run web --image=nginx
deployment.apps/web created
执行完毕! 然后我们检查集群中创建了什么,额...
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/web-65899c769f-dhtdx 1/1 Running 0 11s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 46s
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/web 1 1 1 1 11s
NAME DESIRED CURRENT READY AGE
replicaset.apps/web-65899c769f 1 1 1 11s
$
没看到什么容器,相反的是,我们得到了一些未知的东西:
一个deployment (在本例中叫做 web )
一个replicaset ( web-65899c769f )
一个pod ( web-65899c769f-dhtdx )
注意: 忽略上例中的名为 kubernetes 的service; 它在我们执行 kubectl run 之前就已经存在了。
我只是想要一个容器!为什么得到的却是3种不同的对象?
简言之,这些Kubernetes对象用以确保 我们能够在不停机的情况下逐步地(progressively)部署、回退以及扩展我们的应用。
看到这,我们可能会问 "(要创建3种对象),需要这么麻烦吗"。等我们了解了全局情况,我们便会理解每个组件的角色和用途。
实际上,许多人最后都会这样想:如果让他们来设计这个系统,他们也会采用类似的思路。
持续集成增加了你对编码的信心。为了让发布也有信心,你的部署过程需要一些安全保证。
Containers 和 Pods
在Kubernetes中,最小的部署单元不是container,而是 pod。一个pod是一组containers(这个组中可以只有一个container),它们运行在同一个机器上,共享了一些资源。
例如,同一pod下的多个containers,可以通过 localhost 来通信。从网络的角度看,这些containers中的进程都是本地的(local)。
我们永远无法创建一个独立的container:最接近的情况,是我们创建一个只有单个container的pod。
所以最上面那个例子所发生的场景是:当我们告诉Kubernetes,"帮我创建NGINX!",我们实际上是说,"我想要一个pod,里边只跑一个用了NGINX镜像的容器。"
# pod-nginx.yml
# Create it with:
# kubectl apply -f pod-nginx.yml
apiVersion: v1
kind: Pod
metadata:
name: web
spec:
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
name: http
好吧,为什么我们不只有pod,还有replica set和deployment?
Declarative vs Imperative (声明式和命令式)
Kubernetes是一个声明式的系统 (对比命令式的系统)。这意味着我们无法对它下命令。我们不能说,"运行这个container。" 我们能做的是,描述我们想要什么,等待Kubernetes采取行动,使得当前有什么和我们想要什么达成一致(reconcile)。
换句话,我们可以说,"我想要一个40英尺长的蓝色的容器,它有黄色的门",然后Kubernetes会为我们找这一个这样的容器。如果这样的容器不存在,Kubernetes会创建一个来;如果已经有一个,但它是绿色、红门,Kubernetes会为我们重新涂色;如果已经有一个和我们要求的一样的容器,Kubernetes什么都不会做,因为我们当前有的和我们想要的一致。
以软件容器的术语来讲,我们可以说,"我想要一个命名为 web 的pod,它里面只运行一个容器,该容器运行的是 nginx 镜像。"
如果该pod还没存在,Kubernetes会创建它。如果该pod已经存在并且匹配我们的要求,Kubernetes什么都不做。
既然如此,我们如何扩展该 web 应用,以便让它在多个容器和多个pods中运行?
Replica sets 让扩展变得简单
如果我们只有pod,而我们想要更多一模一样的pod,我们能做的只能是再次走向Kubernetes,请求它,"我想要一个命名为 web2 的pod,它有如下规格。。。",复用和之前一样的规格。然后不断重复,直到达到我们要求的pod数量。
这样做相当不方便,因为跟踪所有这些pods变成了我们的工作,要保证它们是同步的、使用了相同规格的。
为了让事情简单,Kubernetes提了一个更高级的构造,即 replica set。replica set的规范和pod的非常像,但前者带有一个数量,用来指明需要多少复本(replicas) —— 即,我们想要的具有特定规格的pods的数量。
所以我们告诉Kubernetes,"我想要一个命名为 web 的replica set,它包含3个pods,都符合以下规格:..." 然后 Kubernetes会因此而确保有3个相匹配的pods存在。如果我们是从头操作,3个pods将会被创建;如果3个pods已经存在了,什么都不会发生。因为已经有的匹配了我们想要的。
# pod-replicas.yml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: web-replicas
labels:
app: web
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
app: web
tier: frontend
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
Replica sets 尤其和扩展和高可用相关

对于扩展而言,因为我们可更新已有的replica set,改变想要的复本的数量。如此一来,Kubernetes会相应地创建或移除pods,让最终的数量达到要求。
对于高可用而言,因为Kubernetes会持续监控集群中发生了什么,它会保证无论出现什么情况,我们仍然有想要的复本数量。
如果一个节点宕机了,恰巧该节点运行着 web pods,Kubernetes会创建另一个pod来取代它。或者该节点并未宕机,但是已经有一段时间无法访问或不响应了,当它再次可用时,我们可能会多出一个pod。Kubernetes会终结一个pod,以确保复本数量和所要求的完全一致。
当我们改变pod的定义时,会发生什么?
改变pod的定义并非不常见。例如,当我们需要对容器镜像进行升级时。
记住:replica set的任务是,"确保有N个pods匹配给定的规格。" 那么,如果我们改变了规格会发生什么?突然,不再有pods符合改变后的新的规格了。
到现在我们已经懂得了一个声明式系统应该如何工作:Kubernetes应该立即创建N个符合新规格的pods。老的pods还会呆在那里,直到我们手动地清理它们。
如果这些pods可以在 CI/CD pipeline中自动而干净地被清理掉、如果新的pods的创建能以更细粒度的方式发生——这样会方便很多。
让Deployments来驱动Replica sets
这正是deployments的角色。乍一看,deployment的规范和replica set的很像:它包含对pod的定义以及复本的数量。(还有一些其它的参数,后面会讨论。)
# deployment-nginx.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
但是,Deployments 并不直接创建或删除Pods。它们将这份工作代理给一个或多个replica sets。
当我们创建一个deployment时,它会创建一个replica set,使用我们给的pod定义。
当我们更新一个deployment并且改变了复本的数量,它会将改变传给对应的replica set。
当配置改变时
当我们需要更新pod的定义时,事情变得有趣。例如,我们可能要改变使用的镜像 (因为我们发布了新的版本),或者应用的参数(命令行参数、环境变量或者配置文件)。
当我们更新了pod的定义,deployment会根据新的pod定义创建一个新的replica set。这个新的replica set的初始复本数是0。然后,其复本数会逐步地增加,同时把老的replica set的数量减少。

(Photo by Anthony Roberts)
我们可以想像自己面前有一个混音板,我们打算增大一个新的replica set(调大音量),同时减小另一个老的replica set(调小音量)。
整个过程中,新/旧replica sets中的可用pods仍然能收到请求,用户不会感知到服务停机。
这是大的轮廓,还有许多小的细节来让这个过程更加健壮。
坏掉的deployments以及可用性探针
如果我们推出了一个坏掉的版本,它可能使得整个应用挂掉(一次挂一个pod),因为Kubernetes会稳步地将旧的pods换成新的,一次一个。
除非我们使用了可用性探针(readiness probes)。
一个 readiness probe 是我们加到容器定义中的一个测试。它回答是与否,要么『它工作』,要么『它不能工作』,它每隔一段时间就会探测一次。(默认是每隔10秒。)
Kubernetes支持3种实现探针的方式:
在容器中执行一个命令
针对容器发一个HTTP(S)请求
针对容器打开一个TCP连接
Kubernetes使用探测的结果来判断容器和pod是否能正常接收流量。当我们推出新的版本时,Kubernetes会等待,直到新的pod标记自己为"ready"时,才会去创建另一个pod。
如果因为探针一直失败,导致一个pod无法达到ready状态,Kubernetes永远不会创建下一个。该deployment会终止,应用继续以老的版本运行,直到之前的问题被解决。
如果没有配置readiness probe,只要容器能启动,就会被认为是ready的。所以,如果你想利用探针功能,别忘了定义readiness probe!
从错误的部署中快速回滚

任何时间,在滚动更新期间或以后,都可以告诉Kubernetes:"嗨,我改变主意了。请把部署回滚到之前的版本中。" 它会立即更替新、旧replica set的角色。从那个时间点起,它会增加老的replica set的数量(直到达到该deployment的正常数量),同时减少另一个replica set的数量。
通常而言,这不限于2个新、旧replica sets。在幕后,有一个replica set,我们认为是最新的(up-to-date),是 目标(target) replica set;也是我们将要切换到的replica set,是Kubernetes正常在扩展的replica set。同时,还可能有任意数量的其它replica sets,对应了以前老的版本。
举个例子。我们可能对版本1运行了10个复本。接着我们开始滚动更新到版本2。在某个点上,我们可能有7个pods运行着版本1,3个pods运行着版本2。此时我们可能想直接发布版本3,不再等到版本2完全部署(因为版本3解决一个之前未注意到的问题)。而在版本3正在部署时,我们可能突然想回滚到版本1。Kubernetes只需要调整replica sets的数量(根据版本1、2和3的定义)即可。
MaxSurge 和 MaxUnavailable
Kubernetes在处理deployment时并非完全是一次更新一个pod。之前,我们说过deployments有一些其它参数:这些参数就包括了MaxSurge和MaxUnavailable,它俩指明了更新的步伐(速度)。
在推出新版本时,我们可以想到2个策略。我们可能对应用的可用性非常保守,并决定先创建新的pods再关闭老的。只有在新Pod启动、运行起来并变得可用时,我们才关闭老的pod。
这也意味着集群中要有充分的资源可用。然而,有些情况下,我们可能没法继续运行额外的pods,因为集群资源已经耗尽了,我们此时偏好先关闭老的Pod再创建新的。
MaxSurge指明,在滚动更新时,我们愿意运行多少额外的pods;而 MaxUnavailable则指明,在滚动更新时,我们允许失去多少pods。2个参数都是特定于某个deployment的(即,每个deployment可以用不同的值)。2个参数都支持设定为具体的整数值,或者设置为百分比。2个参数都允许为0(但不能同时为0)。
我们针对2个参数举一些典型的例子并说说它们的含义。
将MaxUnavailable设置为0,意味着"在新的pod未能正常接收流量(ready)之前,不要关闭任何老的pod"。
将MaxSurge设置为100%,意味着"立即启动所有新的pods",暗示集群资源充足,我们想要尽快完成部署。
2个参数的默认值都是25%,意味着当更新一个有100个pods的deployment时,会立即创建25个新的pods并且关闭25个老的pods。每当一个新的pod启动并且标记为ready时,就关闭一个老的pod。每当一个老的pod完成关闭时(它占用的资源被释放),另一个新的pod开始创建。
示例时间!
很容易通过实战观察这2个参数。我们不需要写自定义的YMAL、定义readiness probes或者别的东西。
我们只需要让一个deployment使用一个无效的容器镜像,例如一个不存在的镜像。这样,容器永远不会启动成功,Kubernetes也就不会将它们标记为ready了。
如果你有了Kubernetes集群(一个只有单一节点的集群,像minikube或者Docker Desktop也行),你可以在不同的终端界面中执行下述命令,来观察发生了什么:
kubectl get pods -wkubectl get replicasets -wkubectl get deployments -wkubectl get events -w
然后,用下面的命令创建、扩展并更新该deployment:
kubectl run deployment web --image=nginx
kubectl scale deployment web --replicas=10
kubectl set image deployment web nginx=that-image-does-not-exist
可以看到deployment卡住了,但仍有80%的应用可用。
如果我们运行 kubectl rollout undo deployment web ,Kubernetes会回到最初的版本(运行着 nginx 镜像)。
理解selectors和labels
我们之前说,"replica set的职责是确保恰好存在N个符合定义的pods",这并不准确。实际上,replica set并不关注pods的定义,而关注它们的labels(标签)。
换句话说,pods运行的是 nginx 或 redis 或其它什么东西并不重要。重要的是它们有正确的labels。(在上面的例子中,labels是诸如 run=web 和 pod-template-hash=xxxyyyzzz 的东西)。
一个replica set包含了一个selector,它表达了选择哪些pods(就像SQL中的 SELECT 查询一样)。一个replica set 确保了要有正确数量的pods,并在需要时创建和删除pods;但它并不修改已有的pods。
以免你有疑惑:Kubernetes允许我们手动创建带有labels的pods,且运行着不同的镜像(或不同的设定),来糊弄我们的replica set。
初看,这可能会造成潜在的问题。在实践中,我们几乎不可能用错标签,因为它们涉及了一个针对pod定义的hash函数(这段不太清楚,可能意思是同一label的pod,其pod定义会被强制为一样的?有空了去验证)。
作为负责均衡的services
Services同样使用selectors,来作为Kubernetes中内、外部流量的负载均衡器。可以用下面的命令,针对 web deployment创建一个service:
kubectl expose deployment web --port=80
该service有它自己的内部IP地址(由 ClusterIP 表示),针对该IP地址80端口的连接,将被负载均衡到符合该service selector下的所有pods。在本例中,selector是 run=web 。
当我们编辑该deployment并触发一个滚动更新,一个新的replica set将被创建。这个新的replica set将会创建带着 run=web 标签的pods。这样一来,这些pods会自动接收新的连接。
它意味着在滚动更新期间,deployment并不会重新配置或通知负载均衡器有pods被启动或停止了。这通过service的selector自动地发生。
(如果你好奇在这期间探针如何工作:只有在pod的container通过探针检查后,该pod才会加入到service的负载均衡中去。换句话说,一个pod只有达到ready状态后才会接收流量。)
高级的Kubernetes deployment策略
有时,在推出新的版本时,我们想要更多的控制。
有2个技巧你可能听说过:blue/green deployment和canary deployment。
使用Kubernetes进行blue/green deployment
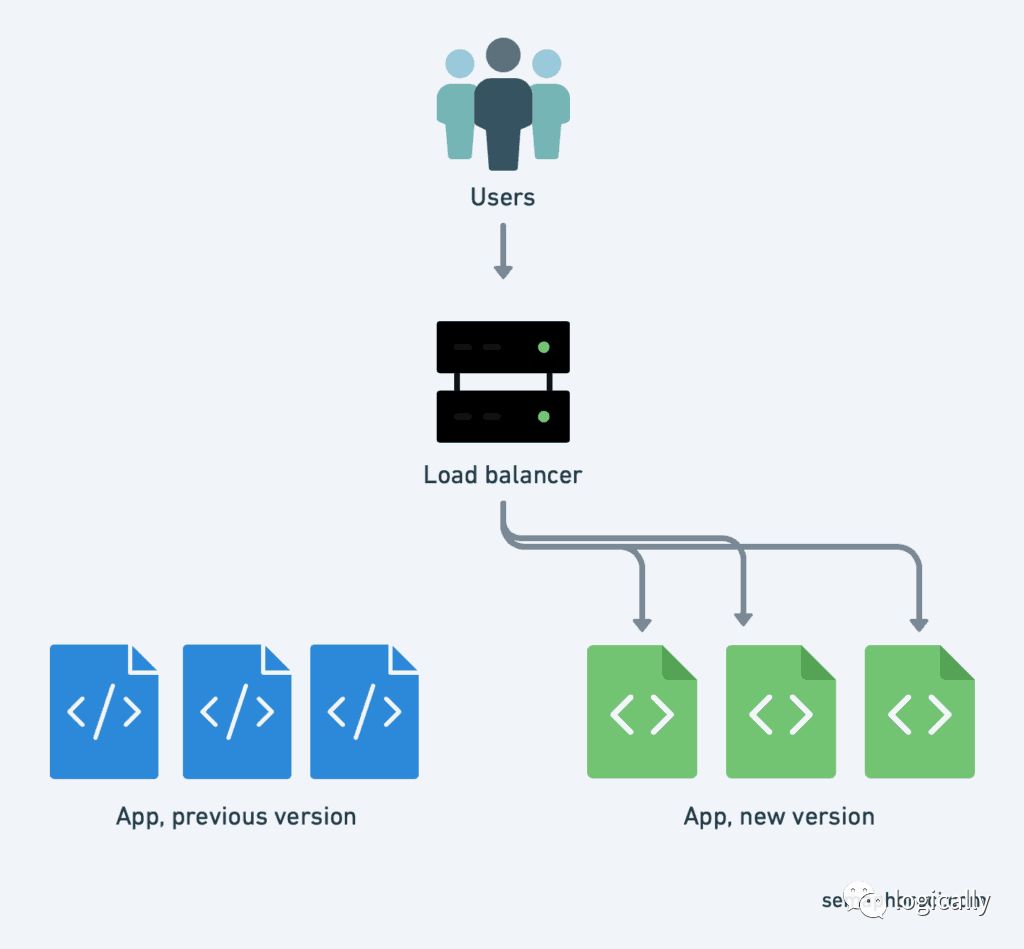
(Blue/Green Deployment)
在 blue/green deployment中,我们想要立即将老版本的流量切换到新版本中,而不是像之前解释过的逐步迁移。这样做的可能理由包括:
我们不想要老、旧请求混合;想要2个版本间的过度尽量的干净
我们同时更新了多个组件(比如,web frontend和api backend),我们不想新版本的web frontend访问到老版本的api backend(或者反过来)
如果期间出错,我们想要能够尽快回滚,不需要等老的版本重启
我们可以通过创建多个deployments来实现blue/green deployment,改变service的selecor就能达到版本切换的目的。
是不是比听起来还容易!
下面的命令会创建2个deployments:blue 和 green ,分别使用了 nginx
和 httpd
容器镜像:
kubectl create deployment blue --image=nginx
kubectl create deployment green --image=httpd
然后,我们创建一个名为 web 的service,初始阶段不会发送任何流量:
kubectl create service clusterip web --tcp=80
现在,我们更新该service,运行 kubectl edit service web 。该命令会通过Kubernetes API获取到service的定义,并用一个文本编辑器打开它。找到含有如下内容的地方:
selector:
app: web
...将 web
替换为 blue
或 green
。保存并退出。kubectl 会把更新后的数据传送给Kubernetes API。好啦! web service将把流量传送给对应的deployment。
(作为验证,通过 kubectl get svc web 获取service的IP地址,然后通过 curl 访问。)
上面使用文本编辑器做的修改,也可以完全通过命令行实现,例如使用下面的命令:
kubectl patch service web -p '{"spec": {"selector": {"app": "green"}}}'
blue/green deployment的优点是,流量切换几乎是瞬间完成的,并且可以以同样快的速度回滚到前一版本,而这只需要修改service的定义。
在Kubernetes中使用Canary deployment
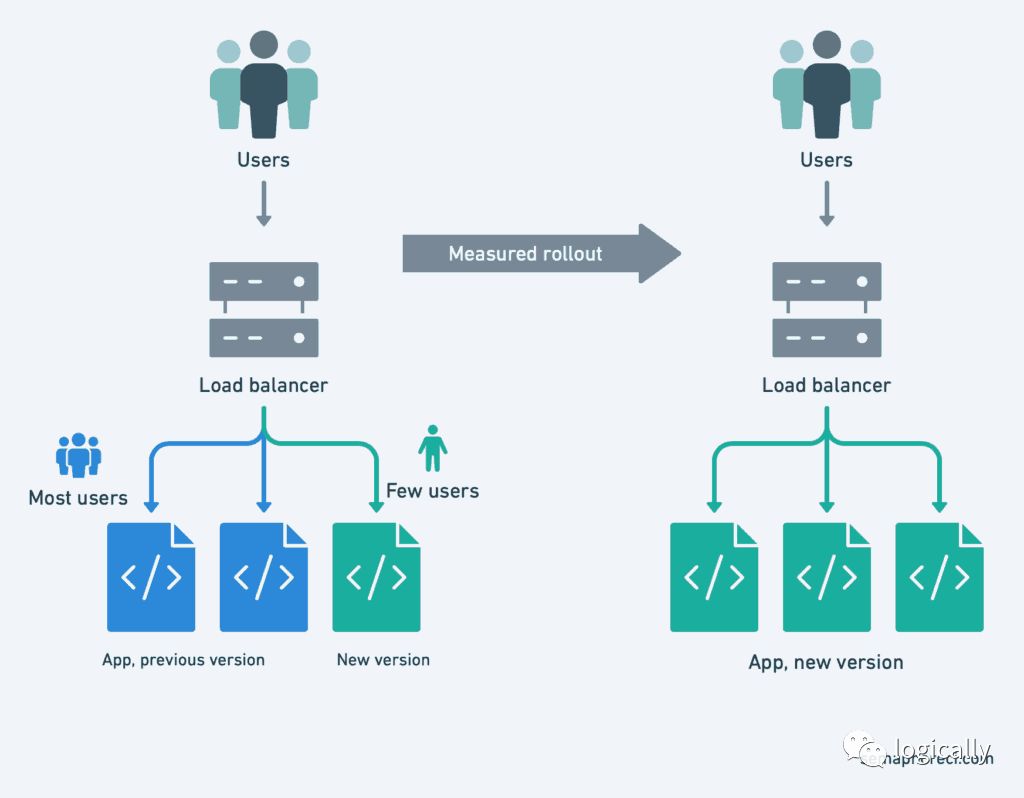
(Canary deployment)
Canary deployment,这里canary是指用于矿井中的金丝雀。它用来检测有毒气体一氧化碳。以前矿井工人通常会携带一只装在笼子里的金丝雀。金丝雀比人对有毒气体更敏感。如果金丝雀出现晕厥,这说明矿井工人进入了一片危险的区域,应该立即返回,不然也会晕倒。
这和软件开发有什么关系呢?
有时,一个有缺陷的版本会影响到客户,而这是不被允许的或无法承担的,即使只影响了一小段时间。所以,我们先是只做一部分更新。例如,我们只让一部分副本运行新的版本;或者只让1%的用户使用新的版本。
然后,我们对比现有版本和金丝雀版本的访问数据。如果数据类似,可以继续更新。如果延迟、错误率或其它方面有问题,就回滚。
这个技巧,看着操作上很复杂,多亏了Kuberntes对lebels和service的原生支持,结果变得很简单。
值得注意的是,在上一个例子中,我们改变的是service的selector,其实改pods的lebels也是可行的。
例如,如果某个service的selector设定是 status=enabled ,我们可以将该label设置给某个特定的pod:
kubectl label pod fronted-aabbccdd-xyz status=enabled
我们也可以批量设置labels:
kubectl label pods -l app=blue,version=v1.5 status=enabled
也可以批量移除labels:
kubectl label pods -l app=blue,version=v1.4 status-
总结
在这里我们看到了一些技巧,让我们的部署变得更加自信。其中的一些技巧减少了部署时的停机时间,意味着我们可以更频繁的部署(迭代)了,不用再担心影响到用户。
一些技巧给了我们安全保证,防止一个有缺陷的版本直接让服务停机。另外一些技巧让我们更放心,知道出问题后,总是能回滚到之前的版本。
Kubernetes 让开发者和运维团队利用以上技巧变成可能,让部署变得更安全。伴随项目部署而来的风险更低了,意味着我们能够经常部署、增量更新,在实现功能时,更容易看到变化带来的结果;不用像以前一样,一周或一个月部署一次了。
最终的结果将是更快的开发速度、更短的面市时间——无论是问题修复还是新功能,应用的可用性也变得更高。这也是使用容器和持续集成的意义。
