




MogDB理论认识
MogDB简介
MogDB是EnMotech openGauss DataBase Enterprise Edition的缩写,是云和恩墨基于openGauss开源数据库进行定制、推出的企业发行版。它将围绕高可用、安全、自动化运维、数据库一体机和SQL审核优化等企业需求,解决企业用户落地。其核心价值是易用性、高性能、高可用等和全天候的企业支持。
MogDB在openGauss开源内核的基础上封装和改善的对于企业应用更加友好的企业级数据库。在openGauss内核的基础上,MogDB增加了MogHA组件,用于进行主备架构下高可用的自动化管理,这对于企业级应用来说是至关重要的。同时也同步研发了MogDB Manager管理软件,其中包括备份恢复,监控,自动化安装等等针对企业级易用性需求的组件。
MogDB和OpenGauss的区别
MogDB是不是一款皮肤产品,MogDB在OpenGausss的基础上做了什么?MogDB与OpenGausss的差异体现在哪里?
无论什么品牌的数据库,它们都存在共性,万变不离其宗,数据库架构可以分为四层 接入层、服务层、计算层、存储层。
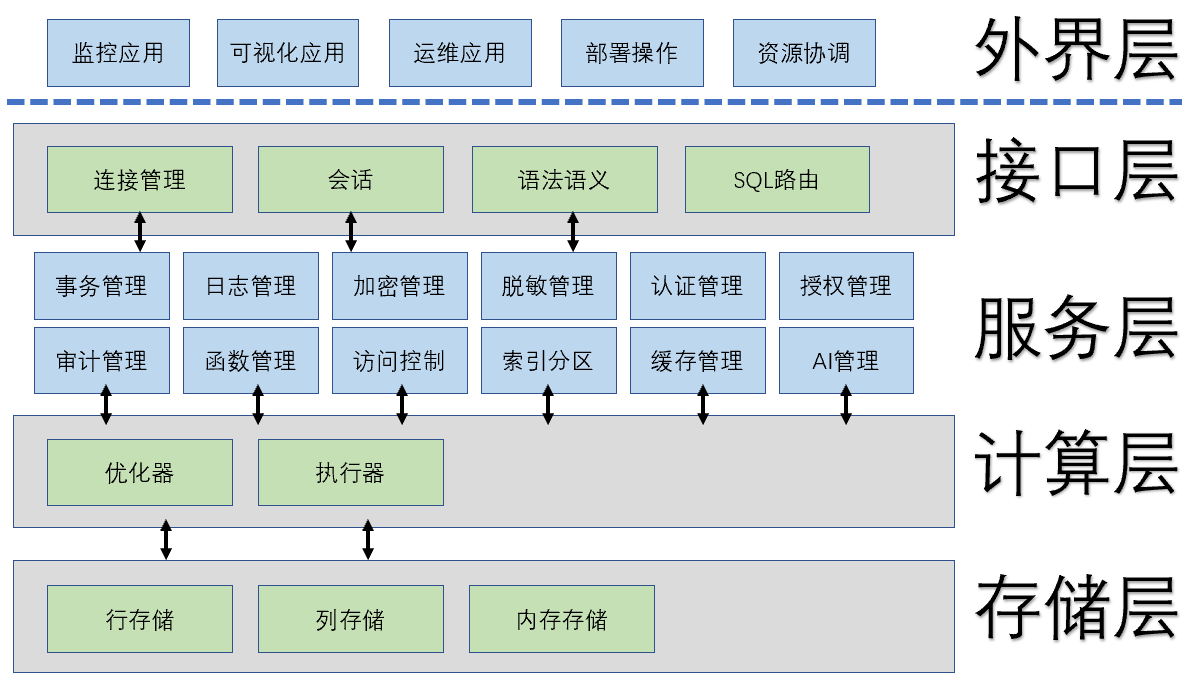
图中可见,数据库的关键核心功能是计算层和存储层,用户处于外界层【应用层】的位置,当发起请求后,请求由接口层接收,经过解析转化后,指令进入数据库内核,通过优化器里面找出最优的路径,配合最佳的算子,正式落实执行任务,按照存储规则流程,计算后或压缩或缓冲或排列,无论哪种种法都要考虑性能和安全的平衡。
市面上基于postgresql内核开发的一些皮肤产品,基本上代码没有任何注入,可能只是前端做了某部分的修改。随着产品软件迭代更新,如果新版本有更好的功能和更强的性能,皮肤产品必须随之迭代更新,没有属于自己的路径发展线。
OpenGausss虽然参照了PostgreSQL9.2.4的框架,但是代码侵入到计算层和存储层,据悉OpenGausss改动的代码超过75%,所以不能说OpenGausss是PostgreSQL的加强版,OpenGausss完全具备自主可控内核管理能力。 举个例子,PostgreSQL最新版本发展到15了,OpenGausss的路径发展并不依赖PostgreSQL,OpenGausss与PostgreSQL是两条路线。
但MogDB却是OpenGausss的加强版!
当应用与数据库交互,数据库通过服务层满足应用需求的各种业务功能,例如基本功能认证、授权。当执行指令下推,计算引擎协同存储引擎一起工作,都需要从服务层读取数据,服务层相当于一个公共服务区域,既可以增强用上层应用能力建设,又可以丰富底层引擎的选择路径。
MogDB基于OpenGausss的基础上做的开发主要集中在服务层和外围层,包括信息输入、输出及中间加工处理与数据应用交互频繁的相关的加密功能、脱敏功能、审计功能、自适应压缩功能等。MogDB 主要思考如何服务应用,让用户更加省心,如何让安装更加简单?如何让监控更加全面精准?如何让运维更加节省成本?如何解决应用最后的一公里问题 ?
目前MogDB 在外围工具上为了一键部署开发了PTK,高可用管理开发了MogHA,图形化管理开发了MogDB Manager,管理开发提供了Mogeaver,并提供了Migrate to MogDB一系列解决方案。
MogDB应用场景
(1) 交易型应用。
大并发、大数据量、以联机事务处理为主的交易型应用,如电商、金融、O2O、电信CRM/计费等,可按需选择不同的主备部署模式。
(2) 物联网数据。
物联网场景如工业监控、远程控制、智慧城市及其延展领域、智能家居和车联网等。物联网场景的特点是传感监控设备的种类和数量多、数据采样频率高、数据存储为追加模型、对数据的操作和分析并重。
openGauss的应用场景即MogDB的应用场景。同类比喻,Mysql有innodb引擎、infobright引擎、memory引擎,MogDB的行式引擎对标innodb引擎,列式引擎对标infobright引擎,内存引擎对标memory引擎。
MogDB的优势
简单一句话概括,openGauss能做的MogDB都能做,而且MogDB面向应用更加友好!
openGauss是单机系统,在这样的系统架构中,业务数据存储在单个物理节点上,数据访问任务被推送到服务节点执行,通过服务器的高并发,实现对数据处理的快速响应。同时通过日志复制可以把数据复制到备机,提供数据的高可靠和读扩展。
openGauss为单一数据库内核,若要在正式的商业项目上使用,还需要构筑数据库监控、主备切换等完整工具链的能力。
在产品层面,MogDB在openGauss原有功能的基础上增加了MogHA企业级高可用组件,以及功能丰富的图形化管理工具MogDB Manager,并在既定路线上持续不断对openGauss内核进行增强。MogDB可最大限度地保障多机房高可用部署能力,4路服务器上可以达到250万tpmC。MogDB Manager包含多种实用组件,如MTK数据库迁移、MIT性能监控、RWT性能压测、PTK自动化部署等,极大程度上完善了openGauss开源数据库的不足之处,丰富了各项企业级功能。
在服务层面,云和恩墨拥有数十年的数据库运维经验,可提供完整的兜底服务,确保数据库更加稳定,应用改造更加平滑,风险更小,弥补openGauss开源数据库人力运维不足的劣势,同时降低维护成本。
最后总结MogDB,它的定位是立足于OpenGauss巨人肩膀之上,同时自力更生有自我特色特长的国产数据库
MogDB安装使用
前置条件环境包
yum install flex.x86_64 -y yum install bison -y yum install numactl -y yum install bzip2 lsof -y yum install python36 -y echo never >/sys/kernel/mm/transparent_hugepage/enabled
本地安装一个单机版的MogDB只需要依照以下三步,但是笔者的经历,必须安装前置条件的环境包。
第一步
$ curl --proto '=https' --tlsv1.2 -sSf https://cdn-mogdb.enmotech.com/ptk/install.sh | sh
第二步
$ /root/.ptk/bin/ptk template --local > config.yaml
第三步
$ /root/.ptk/bin/ptk install -f config.yaml
验证MogDB的版本

MogDB案例实战
项目案例背景
A企业是国家集团旗下的一个单位,A企业数据早年投身电子商务,信息化运营至今已经有5个年头,已经成为集团旗下的标杆企业 。随着国产化大潮不断扩大,数据库是基础软件的重要组成部分,已经上升到芯片、操作系统并驾齐驱的战略高度。集团要求A企业完成国产基础软件试点和业务改造,A企业积极响应号召,集团设定限制标准规范A企业 不允许使用国外相关的产品,包括ETL工具、BI产品、数据库产品、数据分析工具都不允许使用国外产品。
需求调研
A企业调研当前的业务现状,选择消费品经营分析业务作为国产化试点,消费品经营分析业务内含数据包括了有关所售货物的数量、特征和价值及其价格的详细信息。项目立项主题是消费品实时洞察销售分析,目标是实现入库数据的实时觉察和统一看板管理分析,达到数据的实时觉察,从而为销售制造机会。
功能性需求分析
消费品实时洞察销售分析涉及用户消费情况分析、用户购买模式分析、RFM、CLV分析、商品销售分析。
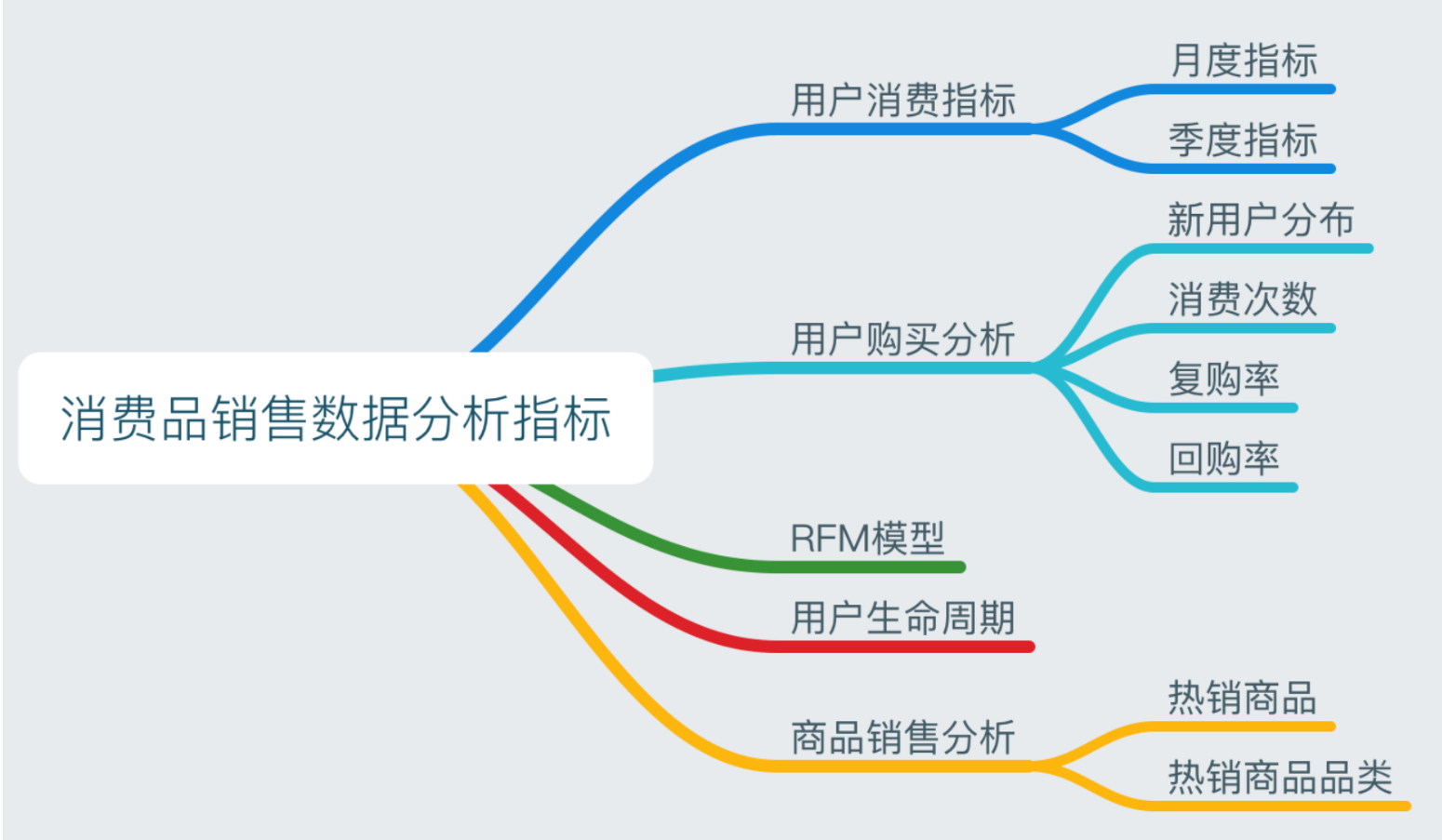
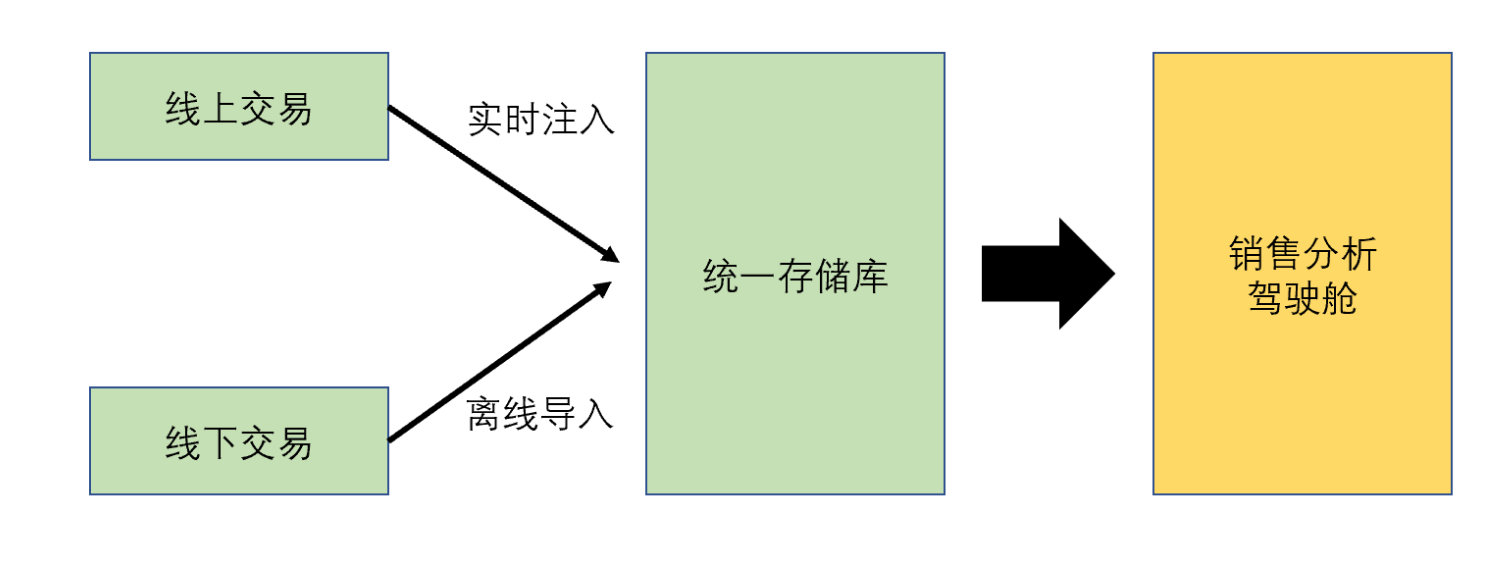
业务流程分析
线下通过零售店的电子交易点单个产品的条形码实现数据入库
线上交易也可以实现数据入库
统一存储库宽表字段含义
| 字段名 | 字段意义 |
|---|---|
| ID | 销售ID |
| Date | 销售日期 |
| Customer_ID | 客户ID |
| Transaction_ID | 交易ID |
| SKU_Category | 商品分类SKU编码 |
| SKU | 商品唯一SKU编码 |
| Quantity | 售出数量 |
| Sales_Amount | 销售额 |
技术方案选型分析
根据集团的战略方向推进国产化战略,不允许用国外ETL \国外BI以及国外数据库,做了国外国内的一个产品调研。
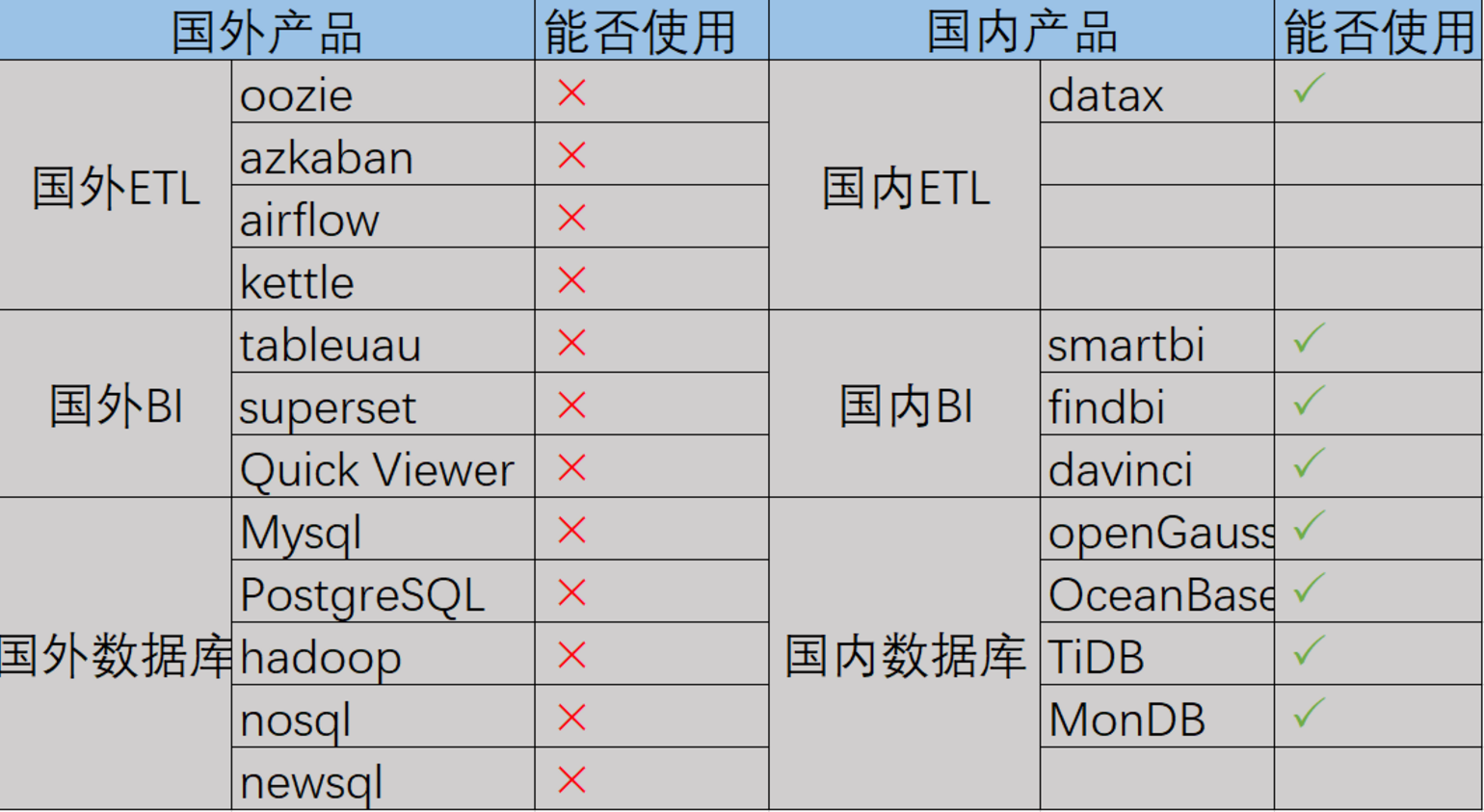
对最关键的数据库产品选型采纳了openGauss、MogDB、OceanBase以及TiDB做了综合对比。
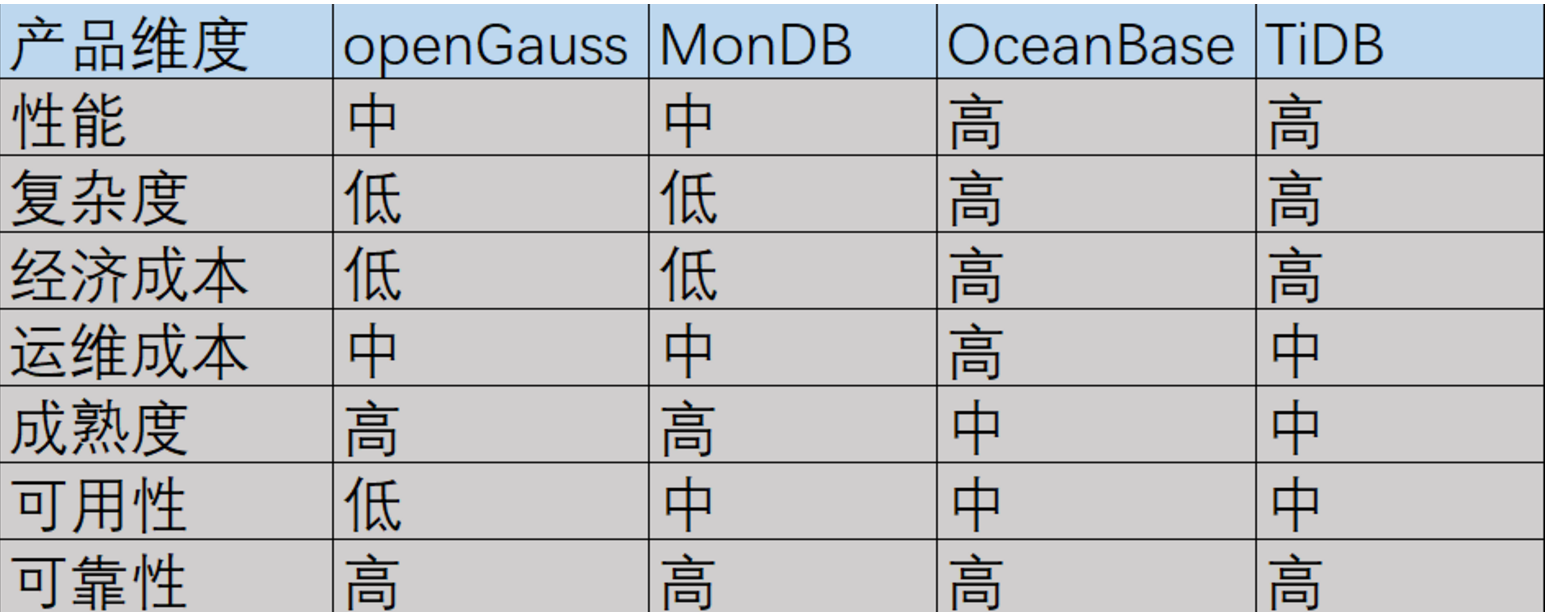
性能:openGauss和MogDB都是单机数据库,始终性能有限,而OceanBase和TiDB通过数据分片提高数据处理的并发性能。
复杂度: openGauss和MogDB属于传统的数据库阵营,支持postgresql原生的操作。而分布式数据库 OceanBase和TiDB有数据分片、合并,从而衍生的数据保存倾斜、数据热点各种可能性问题。
经济成本: openGauss和MogDB安装部署很简单,初始化只需要在一个节点安装即可,OceanBase和TiDB至少3个节点。
运维成本:从产品运行维护的角度上, OceanBase从无到有的全新产品,有传统DBA没有接触过的多租户的使用概念,openGauss和MogDB、TiDB维护管理会好一点
成熟度: 从领导的眼光来看,HTAP还不是很成熟的产品,资深前辈HANA在2019年还给市场清算了,而RDBMS已经在市场碾压多年了,生命力持久。
可用性:能不能开箱即用,能不能一键部署,对工程师的使用习惯有没有入侵
可靠性: 从公司资质来看,openGauss的研发厂商是华为,OceanBase是阿里巴巴独力研发,而 TiDB也有强大的研发实力,都有强大的研发实力为数据库内核保障可靠安全。
结合自身的业务状况分析,从总体数据量和数据增量以及当前的并发规模实况,A企业的业务需求使用postgreSQL就可以满足,数据的规模还算不上大数据,并发量也并不高。
按照理想的业务发展,即使未来业务线性增长,也可以通过ShardingSphere 或者Mycat进行分库分表,因为是一个大宽表,即使使用数据中间件的方式也能解决问题。
目前,分布式数据库方案已经呈现百花齐放的形势,如何选择合适的分布式数据库既满足当前需求又符合未来发展。从技术角度理解来看,分布式数据库方案大致可以分为两大类,即分布式数据库中间件和原生分布式数据库。A公司经过充分调研、考察、交流、技术,从自己的业务状况出发,总结因为数据种类不复杂、数据量不算"大数据"、业务驱动不复杂,对开发人员友好、学习成本不高、社区成熟度高、业务改动少、可以得到充分的技术支持。考虑以上诸多元素所以选择了MogDB。
BI方面有smartbi、findBI、davinci三款国内产品,经过测试综合评估,最终选择davinci。其实smartbi和findBI的商业成熟度更高,davinci的优势是开源,可以做二次开发。
Davinci 是一个 DVAAS(Data Visualization as a Service)平台解决方案的产品,面向业务人员 / 数据工程师 / 数据分析师 / 数据科学家,致力于提供一站式数据可视化解决方案。既可作为公有云 / 私有云独立部署使用,也可作为可视化插件集成到三方系统。用户只需在可视化 UI 上简单配置即可服务多种数据可视化应用,并支持高级交互 / 行业分析 / 模式探索 / 社交智能等可视化功能。
系统功能模块设计
系统整体界面设计
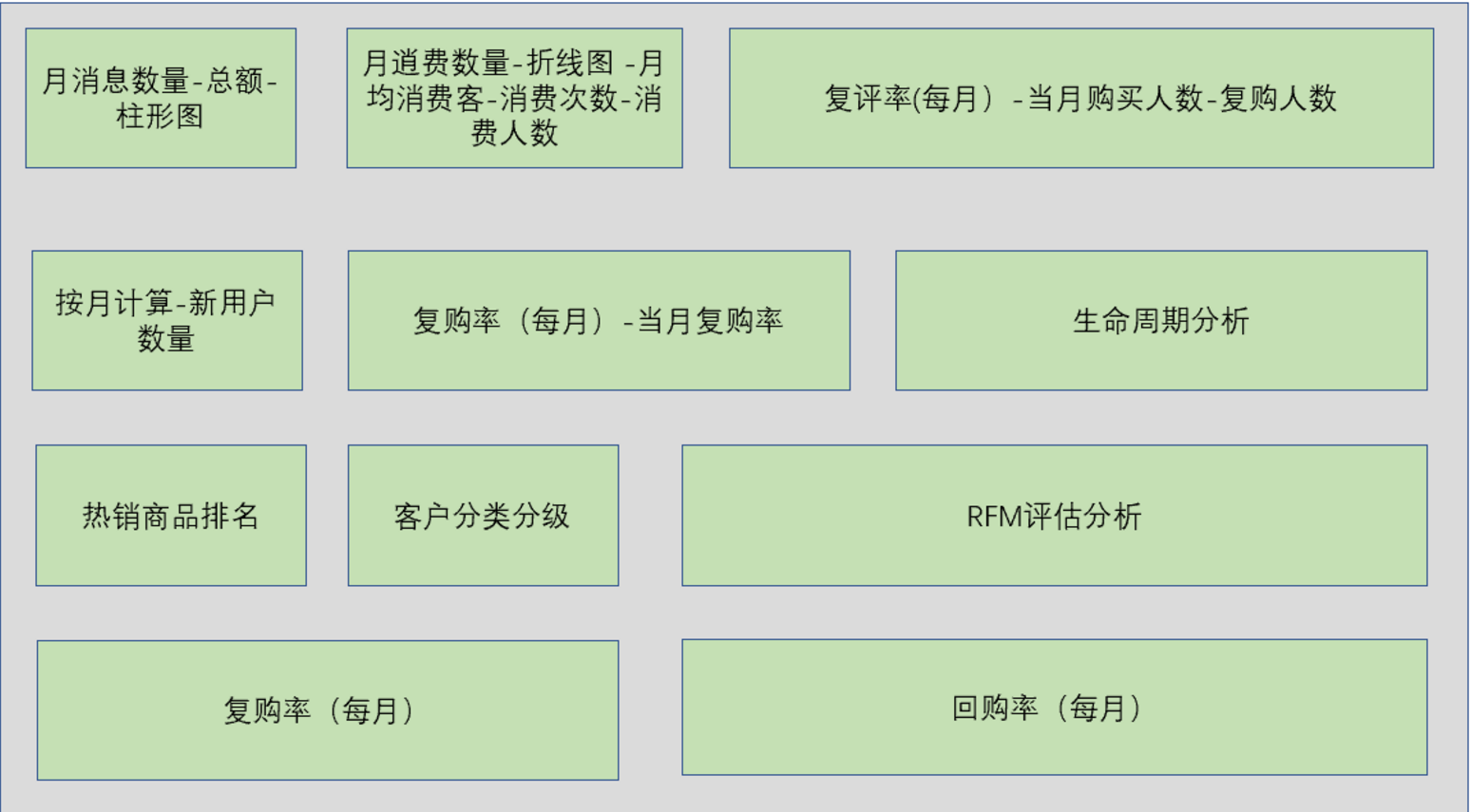
功能模块设计
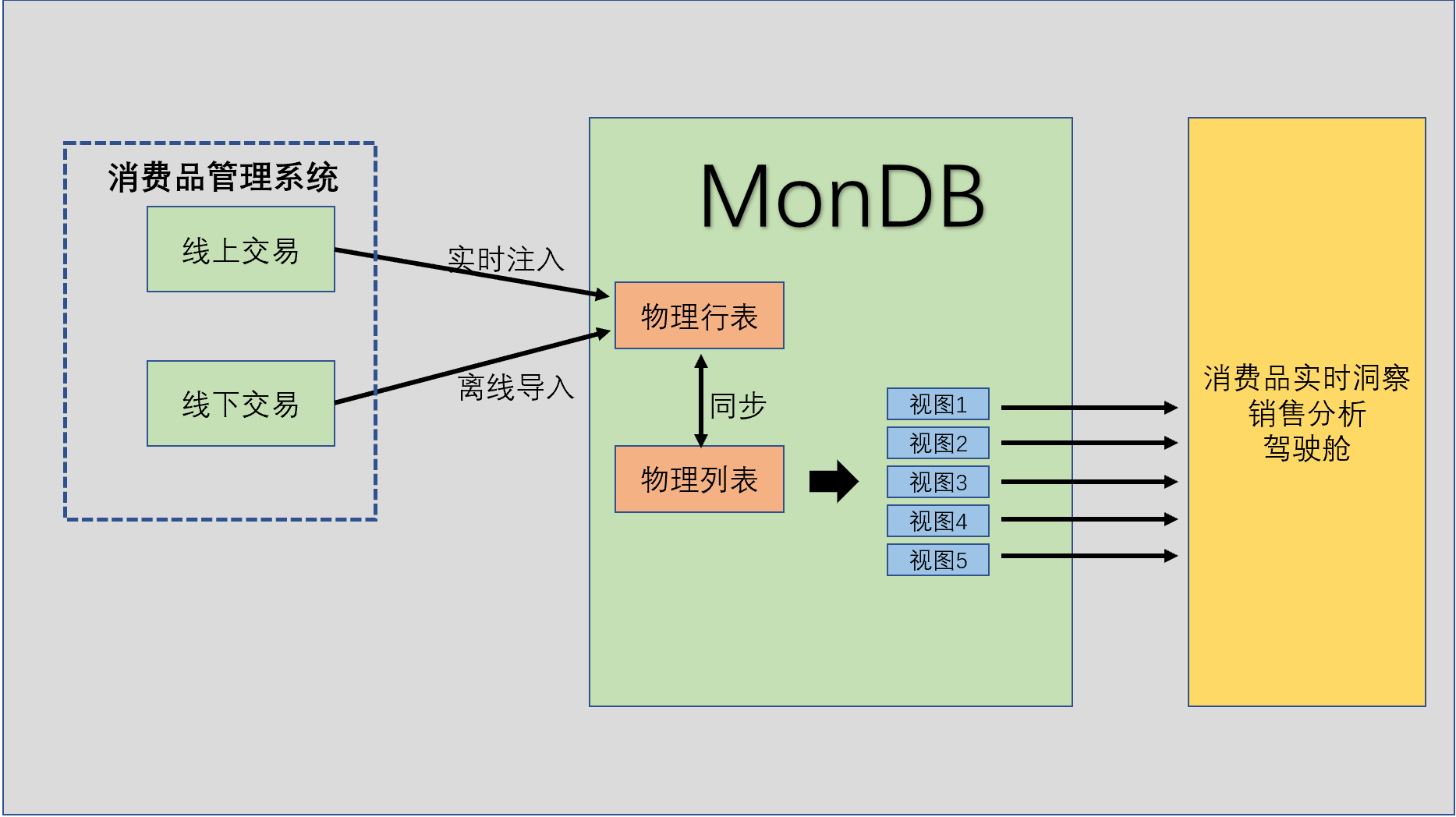
原生业务对应一个消费品管理系统,基于表派生一个列式表,行式表与列式表同步,列式表对接消费品实时洞察销售分析,列式表派生多个视图满足实时洞察的 需求。
数据库设计
经过深思考虑,行式表使用ustore存储方式,并采用索引和分区,列式表则采用cstore存储方式,采用轻度压缩。
create table saletmall2016oltp (
id int,
Date date,
Customer_ID int,
Transaction_ID int,
SKU_Category varchar(50),
SKU varchar(50),
Quantity varchar(50),
Sales_Amount varchar(50)
)with (storage_type=astore)
partition by range(date)
(
partition date201601 values less than ('2016-02-01 00:00:00'),
partition date201602 values less than ('2016-03-01 00:00:00'),
partition date201603 values less than ('2016-04-01 00:00:00'),
partition date201604 values less than ('2016-05-01 00:00:00'),
partition date201605 values less than ('2016-06-01 00:00:00'),
partition date201606 values less than ('2016-07-01 00:00:00'),
partition date201607 values less than ('2016-08-01 00:00:00'),
partition date201608 values less than ('2016-09-01 00:00:00'),
partition date201609 values less than ('2016-10-01 00:00:00'),
partition date201610 values less than ('2016-11-01 00:00:00'),
partition date201611 values less than ('2016-12-01 00:00:00'),
partition date201612 values less than ('2017-01-01 00:00:00')
)
;
create index idx_date_saletmall on saletmall2016oltp(Date);
create table saletmall2016olap (
id int,
Date date,
Customer_ID int,
Transaction_ID int,
SKU_Category varchar(50),
SKU varchar(50),
Quantity varchar(50),
Sales_Amount varchar(50)
)WITH (ORIENTATION = COLUMN,compression=low)
partition by range(date)
(
partition date201601 values less than ('2016-02-01 00:00:00'),
partition date201602 values less than ('2016-03-01 00:00:00'),
partition date201603 values less than ('2016-04-01 00:00:00'),
partition date201604 values less than ('2016-05-01 00:00:00'),
partition date201605 values less than ('2016-06-01 00:00:00'),
partition date201606 values less than ('2016-07-01 00:00:00'),
partition date201607 values less than ('2016-08-01 00:00:00'),
partition date201608 values less than ('2016-09-01 00:00:00'),
partition date201609 values less than ('2016-10-01 00:00:00'),
partition date201610 values less than ('2016-11-01 00:00:00'),
partition date201611 values less than ('2016-12-01 00:00:00'),
partition date201612 values less than ('2017-01-01 00:00:00')
)
;
CREATE OR REPLACE FUNCTION sale_insert_func() RETURNS TRIGGER AS
$$
DECLARE
BEGIN
INSERT INTO saletmall2016olap VALUES(NEW.id, NEW.Date, NEW.Customer_ID,NEW.Transaction_ID,NEW.SKU_Category,NEW.SKU,NEW.Quantity,NEW.Sales_Amount);
RETURN NEW;
END
$$ LANGUAGE PLPGSQL;
CREATE TRIGGER sales_insert_trigger
BEFORE INSERT ON saletmall2016oltp
FOR EACH ROW
EXECUTE PROCEDURE sale_insert_func();
CREATE TABLE
sales=# \dt+ saletmall2016olap
List of relations
Schema | Name | Type | Owner | Size | Storage | Description
--------+-------------------+-------+-------+--------+--------------------------------------+-------------
public | saletmall2016olap | table | omm | 192 kB | {orientation=column,compression=low} |
(1 row)
sales=# \dt+ saletmall2016oltp
List of relations
Schema | Name | Type | Owner | Size | Storage | Description
--------+-------------------+-------+-------+---------+----------------------------------+-------------
public | saletmall2016oltp | table | omm | 0 bytes | {orientation=row,compression=no} |
(1 row)
系统实施
编译安装davinci
因为以后有二次开发davinci的必要,所以在windows下完成编译
1 系统环境
- Windows 10
- Nodejs v10.15.3
- Maven3.5.0
2 前端编译
webapp目录下运行以下命令
- npm install cnpm -g
- cnpm install
- cnpm run build
成功后生成build目录,里面有打包好的前端文件
后端编译
根目录下运行以下命令
- mvn clean package
成功的编译在 assembly\target下面找到
服务器布署
上传解压
[root@server81 ~]# mkdir davinciServer [root@server81 ~]# mv davinci-assembly_0.3.1-0.3.1-SNAPSHOT-dist-rc.zip davinciServer/ [root@server81 ~]# cd davinciServer [root@server81 config]# unzip davinci-assembly_0.3.1-0.3.1-SNAPSHOT-dist-rc.zip [root@server81 davinciServer]# cd config/ [root@server81 config]# ll total 20 -rw-r--r-- 1 root root 5241 May 10 2021 application.yml.example -rw-r--r-- 1 root root 2522 May 10 2021 datasource_driver.yml.example -rw-r--r-- 1 root root 5678 May 10 2021 logback.xml
配置文件
[root@server81 config]# **cp application.yml.example application.yml** [root@server81 config]# **vi application.yml**
server:
protocol: http
address: 0.0.0.0
port: 8080
servlet:
context-path: /
# Used for mail and download services, can be empty, careful configuration
# By default, 'server.address' and 'server.port' is used as the string value.
# access:
# address:
# port:
jwtToken:
secret: secret
timeout: 1800000
algorithm: HS512
source:
initial-size: 1
min-idle: 1
max-wait: 30000
max-active: 10
break-after-acquire-failure: true
connection-error-retry-attempts: 1
time-between-eviction-runs-millis: 2000
min-evictable-idle-time-millis: 600000
max-evictable-idle-time-millis: 900000
test-while-idle: true
test-on-borrow: false
test-on-return: false
validation-query: select 1
validation-query-timeout: 10
keep-alive: false
filters: stat
enable-query-log: false
result-limit: 1000000
spring:
mvc:
async:
request-timeout: 30s
rest:
proxy-host:
proxy-port:
proxy-ignore:
## davinci datasource config
datasource:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://xxxx:3306/davinci?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true
username: bigdata
password: bigdata
driver-class-name: com.mysql.jdbc.Driver
initial-size: 1
min-idle: 1
max-wait: 30000
max-active: 10
break-after-acquire-failure: true
connection-error-retry-attempts: 1
time-between-eviction-runs-millis: 2000
min-evictable-idle-time-millis: 600000
max-evictable-idle-time-millis: 900000
test-while-idle: true
test-on-borrow: false
test-on-return: false
validation-query: select 1
validation-query-timeout: 10
keep-alive: false
filters: stat
## redis config
## please choose either of the two ways
redis:
isEnable: false
## standalone config
host: 127.0.0.1
port: 6379
## cluster config
# cluster:
# nodes:
password:
database: 0
timeout: 1000
jedis:
pool:
max-active: 8
max-wait: 1
max-idle: 8
min-idle: 0
## mail is one of the important configuration of the application
## mail config cannot be null or empty
## some mailboxes need to be set separately password for the SMTP service)
mail:
host: smtp.163.com
port: 25
username: xxxxx@163.com
fromAddress:
password:
nickname:
properties:
smtp:
starttls:
enable: true
required: true
auth: true
mail:
smtp:
ssl:
enable: false
ldap:
urls:
username:
password:
base:
domainName: # domainName 指 企业邮箱后缀,如企业邮箱为:xxx@example.com,这里值为 '@example.com'
security:
oauth2:
enable: false
screenshot:
default_browser: CHROME
timeout_second: 600
chromedriver_path: $your_chromedriver_path$
remote_webdriver_url: $your_remote_webdriver_url$
data-auth-center:
channels:
- name:
base-url:
auth-code:
statistic:
enable: false
# You can use external elasticsearch storage [127.0.0.1:9300]
elastic_urls:
elastic_user:
elastic_index_prefix:
# You can also use external mysql storage
mysql_url:
mysql_username:
mysql_password:
# You can also use external kafka
kafka.bootstrap.servers:
kafka.topic:
java.security.krb5.conf:
java.security.keytab:
java.security.principal:
encryption:
maxEncryptSize: 1024
type: Off # Off is to turn off encryption, to enable encryption, please select AES or RSA
Mysql建表
[root@server81 ~]# mysql -h localhost -u henley davinci -p < /root/davinciServer/bin/davinci.sql Enter password:
启动服务
[root@server81 davinciServer]# **export DAVINCI3_HOME=/root/davinciServer** [root@server81 davinciServer]# **chmod -R +x ./bin/** [root@server81 davinciServer]# **./bin/start-server.sh** ========================================== Starting..., press `CRTL + C` to exit log ========================================== ___ _ _ | \ __ _ __ __(_) _ _ __ (_) | |) |/ _` |\ V /| || ' \ / _|| | |___/ \__,_| \_/ |_||_||_|\__||_| Davinci version: 0.3 Spring Boot version: 2.0.4.RELEASE 2021-03-26 06:34:44.952 INFO 2535 --- [ main] edp.DavinciServerApplication : Starting DavinciServerApplication v0.3.1-SNAPSHOT on server81 with PID 2535 (/root/davinciServer/lib/davinci-server_0.3.1-0.3.1-SNAPSHOT.jar started by root in /root/davinciServer) 2021-03-26 06:34:44.952 INFO 2535 --- [main] edp.DavinciServerApplication : Starting DavinciServerApplication v0.3.1-SNAPSHOT on server81 with PID 2535 (/root/davinciServer/lib/davinci-server_0.3.1-0.3.1-SNAPSHOT.jar started by root in /root/davinciServer) 2021-03-26 06:34:44.967 INFO 2535 --- [main] edp.DavinciServerApplication : No active profile set, falling back to default profiles: default ; root of context hierarchy 2021-03-26 06:34:45.592 INFO 2535 --- [main] ConfigServletWebServerApplicationContext : Refreshing org.springfrhmework.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext@e350b40: startup date [Fri Mar 26 06:34:45 CST 2021]; root of context hierarchy
访问服务
http://xxxxx:8080
使用davinci连接MogDB数据源
建立数据源配置文件:
davinci默认不支持postgresql,需要添加postgresql的驱动连接 [root@cenots7 config]# pwd /root/davinci/davinci03/config [root@cenots7 config]# ll datasource_driver.yml -rw-r--r--. 1 root root 156 Aug 9 00:02 datasource_driver.yml [root@cenots7 config]# cat datasource_driver.yml 加入以下内容 postgresql: name: postgresql desc: postgresql driver: org.postgresql.Driver keyword_prefix: keyword_suffix: alias_prefix: \" alias_suffix: \"
加入postgresql驱动:
[root@cenots7 lib]# pwd /root/davinci/davinci03/lib lib放入postgresql的驱动 [root@cenots7 lib]# wget https://jdbc.postgresql.org/download/postgresql-42.4.1.jar
连接数据源
数据应用开发
davinci是一个好东西 ,数据应用开发为以下五步
1. 登录davinci
2. 连接数据源
3. 定义SQL【定义VIEW】
4. 定义 组件【定义widget】
5. 定义仪表盘【选择合适的widget展示
登录davinci
创建项目
连接数据源

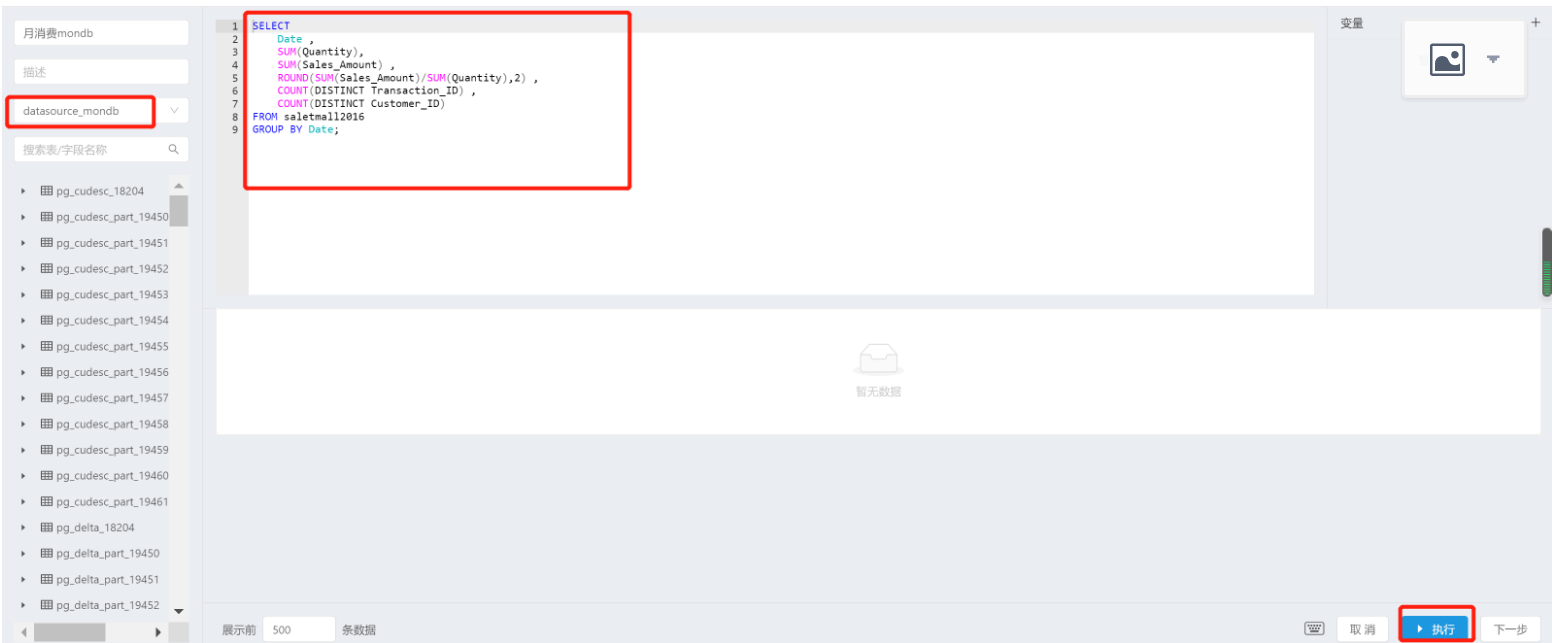
定义SQL

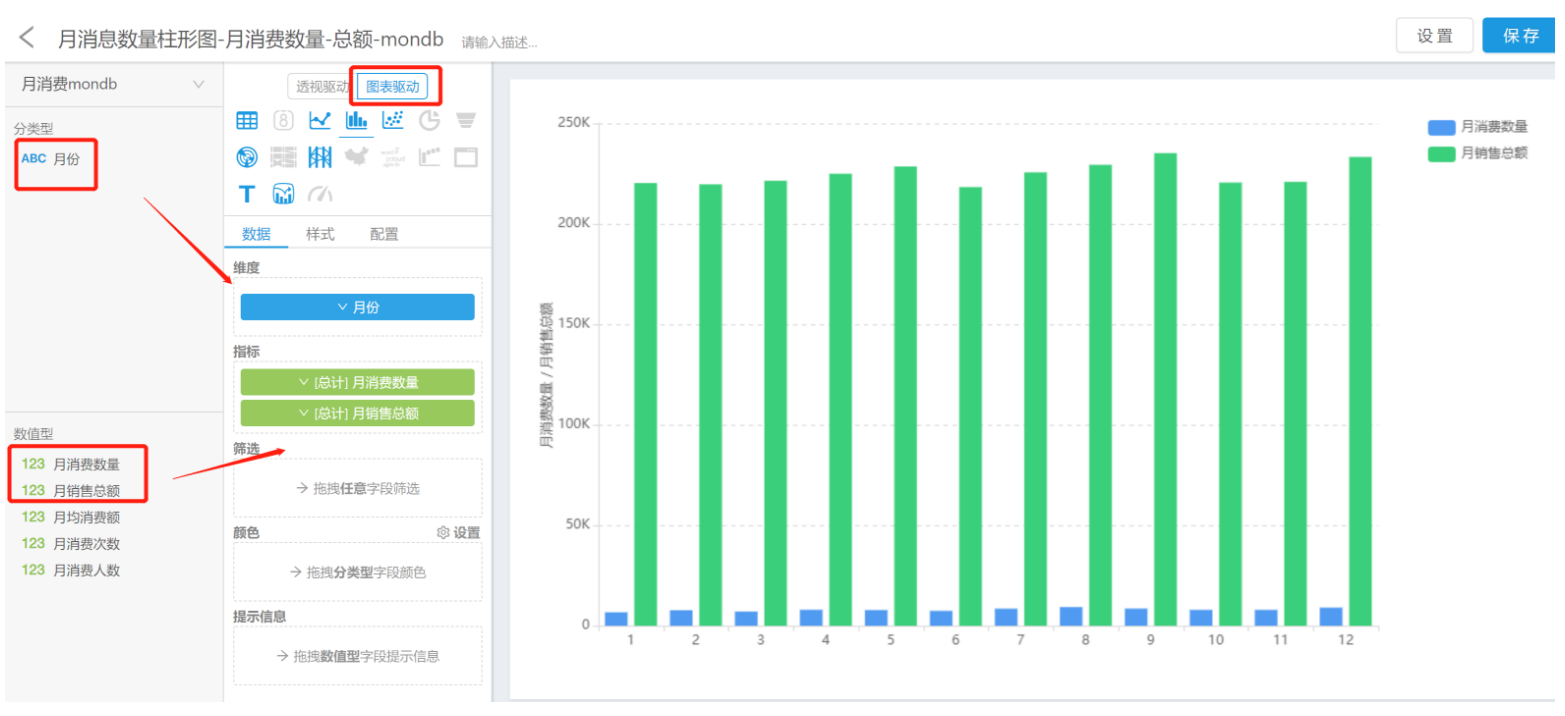
定义组件

定义仪表盘

选择要显示的组件

选择自动更新还是手动更新
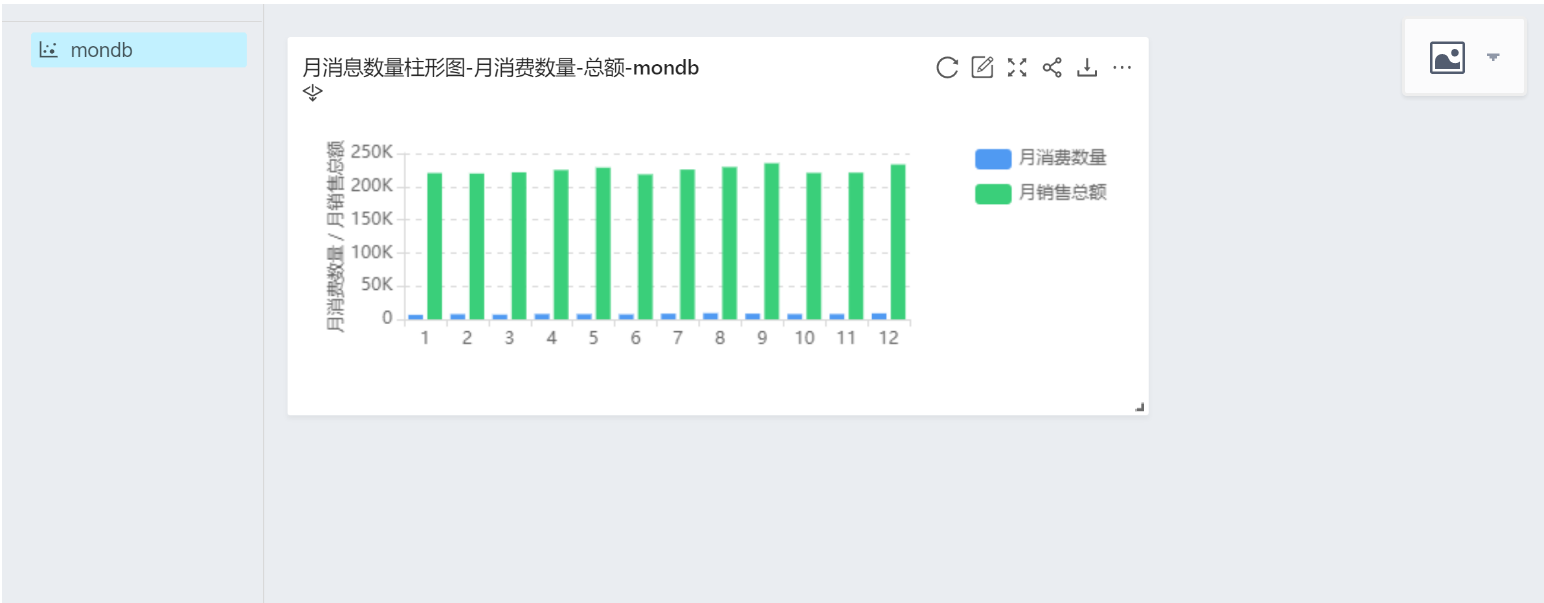
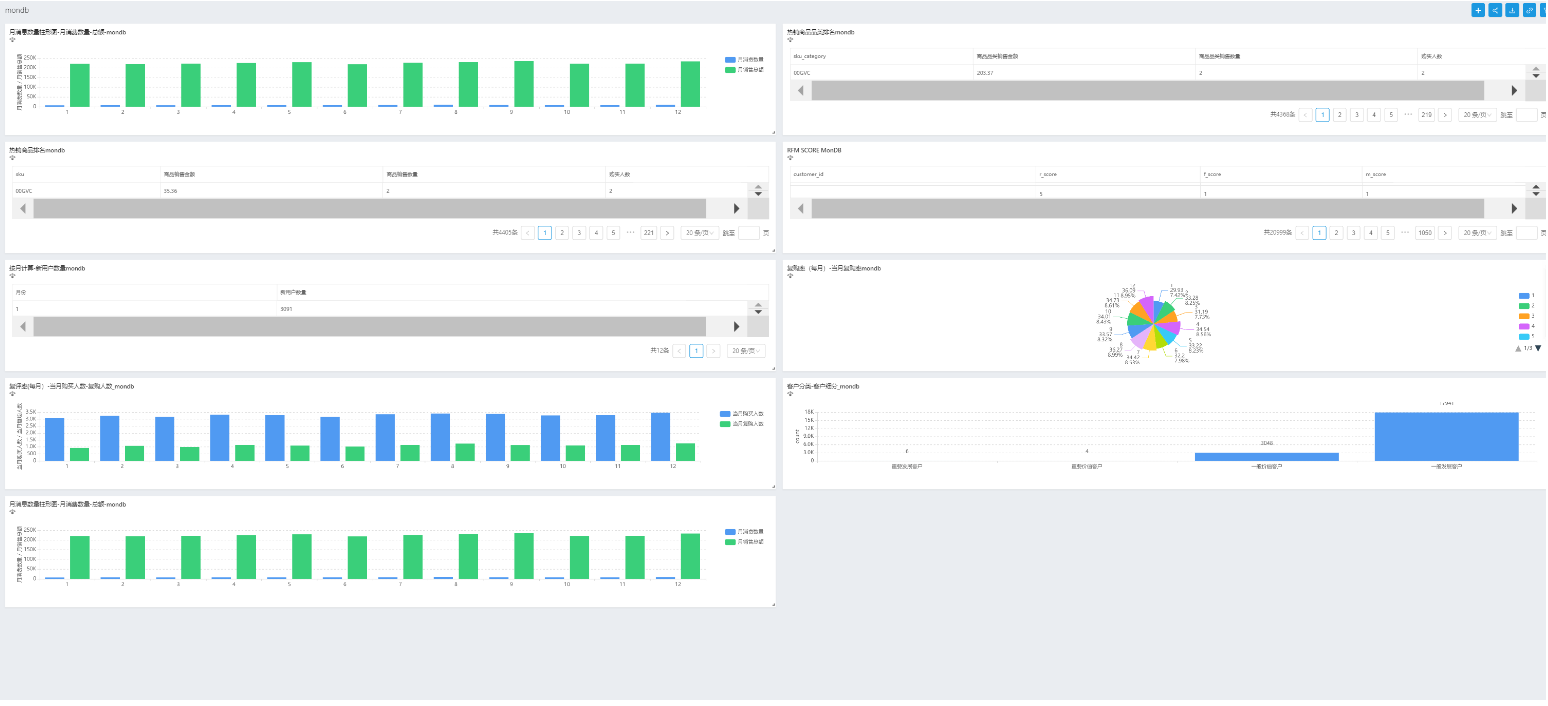
最后添加所有的组件
SQL分析语句
\#月消费数量
CREATE VIEW mth_cnt AS
SELECT
EXTRACT(MONTH FROM Date) AS 月份,
SUM(Quantity) AS 月消费数量,
SUM(Sales_Amount) AS 月销售总额,
ROUND(SUM(Sales_Amount)/SUM(Quantity),2) AS 月均消费额,
COUNT(DISTINCT Transaction_ID) AS 月消费次数,
COUNT(DISTINCT Customer_ID) AS 月消费人数
FROM saletmall2016olap
GROUP BY EXTRACT(MONTH FROM Date);
\#季消费数量
CREATE VIEW quar_cnt AS
SELECT
EXTRACT(QUARTER FROM Date) AS 季度,
SUM(Quantity) AS 季消费数量,
SUM(Sales_Amount) AS 季销售总额,
ROUND(SUM(Sales_Amount)/SUM(Quantity),2) AS 季均消费额,
COUNT(DISTINCT Transaction_ID) AS 季消费次数,
COUNT(DISTINCT Customer_ID) AS 季消费人数
FROM saletmall2016olap
GROUP BY EXTRACT(QUARTER FROM Date);
\#新用户分布
\#按天计算
CREATE VIEW new_customer_by_day AS
SELECT mindate 日期, COUNT(Customer_ID) 新用户数量
FROM (
SELECT MIN(Date) AS mindate, Customer_ID
FROM saletmall2016olap
GROUP BY Customer_ID
) t
GROUP BY mindate
ORDER BY mindate;
\#按月计算
CREATE VIEW new_customer_by_month AS
SELECT minmonth 月份, COUNT(Customer_ID) 新用户数量
FROM (
SELECT MIN(EXTRACT(MONTH FROM Date)) AS minmonth, Customer_ID
FROM saletmall2016olap
GROUP BY Customer_ID
) t
GROUP BY minmonth
ORDER BY minmonth;
\#消费次数分布
WITH tmp AS(
SELECT COUNT(Customer_ID) AS CNT
FROM( SELECT Customer_ID, sum(Transaction_ID) FROM saletmall2016olap GROUP BY Customer_ID HAVING COUNT(2)=1) t1)
SELECT tmp.CNT AS 仅消费一次用户数量, CONCAT(ROUND(100*tmp.CNT/COUNT(DISTINCT saletmall2016olap.Customer_ID),2),'%') 占比
FROM saletmall2016olap,tmp group by CNT;
\#复购率(每月)
CREATE VIEW multibuy_rate AS
SELECT
a.mth,
COUNT(a.Customer_ID) 当月购买人数,
COUNT(CASE WHEN a.cnt>1 THEN 1 ELSE NULL END) 当月复购人数,
CONCAT(ROUND(100*COUNT(CASE WHEN a.cnt>1 THEN 1 ELSE NULL END)/COUNT(a.Customer_ID),2),'%') AS 当月复购率
FROM (
SELECT EXTRACT(MONTH FROM Date) mth, Customer_ID, COUNT(Transaction_ID) AS cnt
FROM saletmall2016olap
GROUP BY mth, Customer_ID
) a
GROUP BY a.mth;
\#回购率(每月)
CREATE VIEW rebuy_rate AS SELECT a.agsdate, COUNT(a.Customer_ID) AS 当月购买人数, COUNT(b.Customer_ID) AS 次月回购人数, concat(round(COUNT(b.Customer_ID) / COUNT(a.Customer_ID) * 100, 2), '%') AS 次月回购率
FROM (
SELECT to_date(Date, 'YYYY-MM-DD HH24:MI:SS') AS agsdate, Customer_ID
FROM saletmall2016olap
GROUP BY agsdate, Customer_ID
ORDER BY Customer_ID
) a
LEFT JOIN (
SELECT to_date(Date, 'YYYY-MM-DD HH24:MI:SS') AS gsdate, Customer_ID
FROM saletmall2016olap
GROUP BY gsdate, Customer_ID
ORDER BY Customer_ID
) b
ON a.Customer_ID = b.Customer_ID
AND a.agsdate = (b.gsdate - INTERVAL '1 MONTH')
GROUP BY agsdate
ORDER BY agsdate;
\#RFM
\#R:最近一次消费时间(以2016-12-31为截止日期)
\#F:消费频率
\#M:消费金额
CREATE VIEW RFM_cnt AS
SELECT
DISTINCT Customer_ID,
DATE_PART('day', '2016-12-31'::date) - DATE_PART('day', date) AS R,
COUNT(DISTINCT Transaction_ID) AS F,
SUM(Sales_Amount) AS M
FROM saletmall2016olap
GROUP BY Customer_ID, R
ORDER BY Customer_ID, R;
SELECT MAX(R), MAX(F), MAX(M)
FROM rfm_cnt;
**创建视图rfm_cnt**
**创建视图RFM_score **
CREATE VIEW RFM_score AS
SELECT Customer_ID,
CASE WHEN R<=30 THEN 5 WHEN R>30 AND R<=90 THEN 4 WHEN R>90 AND R<=180 THEN 3 WHEN R>180 AND R<=270 THEN 2 ELSE 1 END AS R_score,
CASE WHEN F=1 THEN 1 WHEN F=2 THEN 2 WHEN F>2 AND F<=9 THEN 3 WHEN F>9 AND F<=23 THEN 4 ELSE 5 END AS F_score,
CASE WHEN M<=500 THEN 1 WHEN M>500 AND M<=1000 THEN 2 WHEN M>1000 AND M<=2000 THEN 3 WHEN M>2000 AND M<=2500 THEN 4 ELSE 5 END AS M_score
FROM rfm_cnt;
\#计算平均值
SELECT
ROUND(AVG(R_score),1) AS R_avg,
ROUND(AVG(F_score),1) AS F_avg,
ROUND(AVG(M_score),1) AS M_avg
FROM RFM_score;
\#确定RFM值
CREATE VIEW RFM_value AS
SELECT Customer_ID,
CASE WHEN R_score > 2.9 THEN 1 ELSE 0 END AS R_value,
CASE WHEN F_score > 1.8 THEN 1 ELSE 0 END AS F_value,
CASE WHEN M_score > 1.0 THEN 1 ELSE 0 END AS M_value
FROM rfm_score;
\#客户分类
CREATE VIEW Customer_rating AS
select customerType,count(*) from (
SELECT Customer_ID,CASE WHEN R_value=1 AND F_value=1 AND M_value=1 THEN '重要价值客户' WHEN R_value=1 AND F_value=0 AND M_value=1 THEN '重要发展客户' WHEN R_value=0 AND F_value=1 AND M_value=1 THEN '重要保持客户' WHEN R_value=0 AND F_value=0 AND M_value=1 THEN '重要挽留客户' WHEN R_value=1 AND F_value=1 AND M_value=0 THEN '一般价值客户' WHEN R_value=1 AND F_value=0 AND M_value=0 THEN '一般发展客户' WHEN R_value=0 AND F_value=1 AND M_value=0 THEN '一般保持客户' ELSE '一般挽留客户' END AS customerType FROM rfm_value
) as customer_rfm group by customerType;
\#生命周期分析
\#L值
DATE_PART('day', '2016-12-31'::date) - DATE_PART('day', max(date))
CREATE VIEW L_cnt AS
SELECT
DISTINCT Customer_ID,
DATE_PART('day', '2016-12-31'::date) - DATE_PART('day', max(date)) AS R,
DATE_PART('day', '2016-12-31'::date) - DATE_PART('day', min(date)) AS L
FROM saletmall2016olap
GROUP BY Customer_ID
HAVING L>0
ORDER BY Customer_ID;
CREATE VIEW CLV_rating AS
select usertype,count(usertype) from (
SELECT Customer_ID,
CASE
WHEN R<=60 AND L<=180 THEN '新用户'
WHEN R<=60 AND L>180 THEN '忠诚用户'
WHEN R>60 AND L>180 THEN '流失的老用户'
ELSE '一次性用户'
END AS usertype
FROM l_cnt) inner_usertype group by usertype ;
**热销商品排名**
CREATE VIEW topbuy_sku AS
SELECT
SKU,
SUM(Sales_Amount) AS 商品销售金额,
SUM(Quantity) AS 商品销售数量,
COUNT(DISTINCT Customer_ID) AS 购买人数
FROM saletmall2016olap
GROUP BY SKU;
\#热销商品品类排名
CREATE VIEW topbuy_skucate AS
SELECT
SKU_Category,
SUM(Sales_Amount) AS 商品品类销售金额,
SUM(Quantity) AS 商品品类销售数量,
COUNT(DISTINCT Customer_ID) AS 购买人数
FROM saletmall2016olap
GROUP BY SKU_Category;
后面分享一下数据大屏

系统测试
测试目标
- 通过jmeter工具持续不断给MogDB插入数据,并观查以下两个性能指标。
- 观察列式引擎与行式引区的同变状况,是否能实时更新
- 观察数据大屏是否及时察数据的变化【性能取决于数据库的处理能力】
性能测试
BeanShell
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
int max=30,min=1;
int ran1 = (int) (Math.random()*12+1);
int ran2 = (int) (Math.random()*(max-min)+min);
LocalDate date_diy=LocalDate.of(2016, ran1, ran2);
String ymddiy = date_diy.format(DateTimeFormatter.ofPattern("yyyy-MM-dd 00:00:00"));
vars.put("sales2", ymddiy);
String[] sale4 = new String[]{"匹配的字符串"};
Random random = new Random();
int j = random.nextInt(sale4.length);
vars.put("sales4",sale4[j]);
String[] sale5 = new String[]{"匹配的字符串"};
Random random = new Random();
int j = random.nextInt(sale5.length);
vars.put("sales5",sale5[j]);
JDBC Request
INSERT INTO saletmall2016oltp (
Date,
Customer_ID,
Transaction_ID,
SKU_Category,
SKU,
Quantity,
Sales_Amount
)
VALUES (
'${sales2}',
${__Random(3,22625,)},
${__Random(1,61044,)},
'${sales4}',
'${sales5}',
1,
${__javaScript((Math.random() * (10)).toFixed(2) * 1 + 100,)}
);
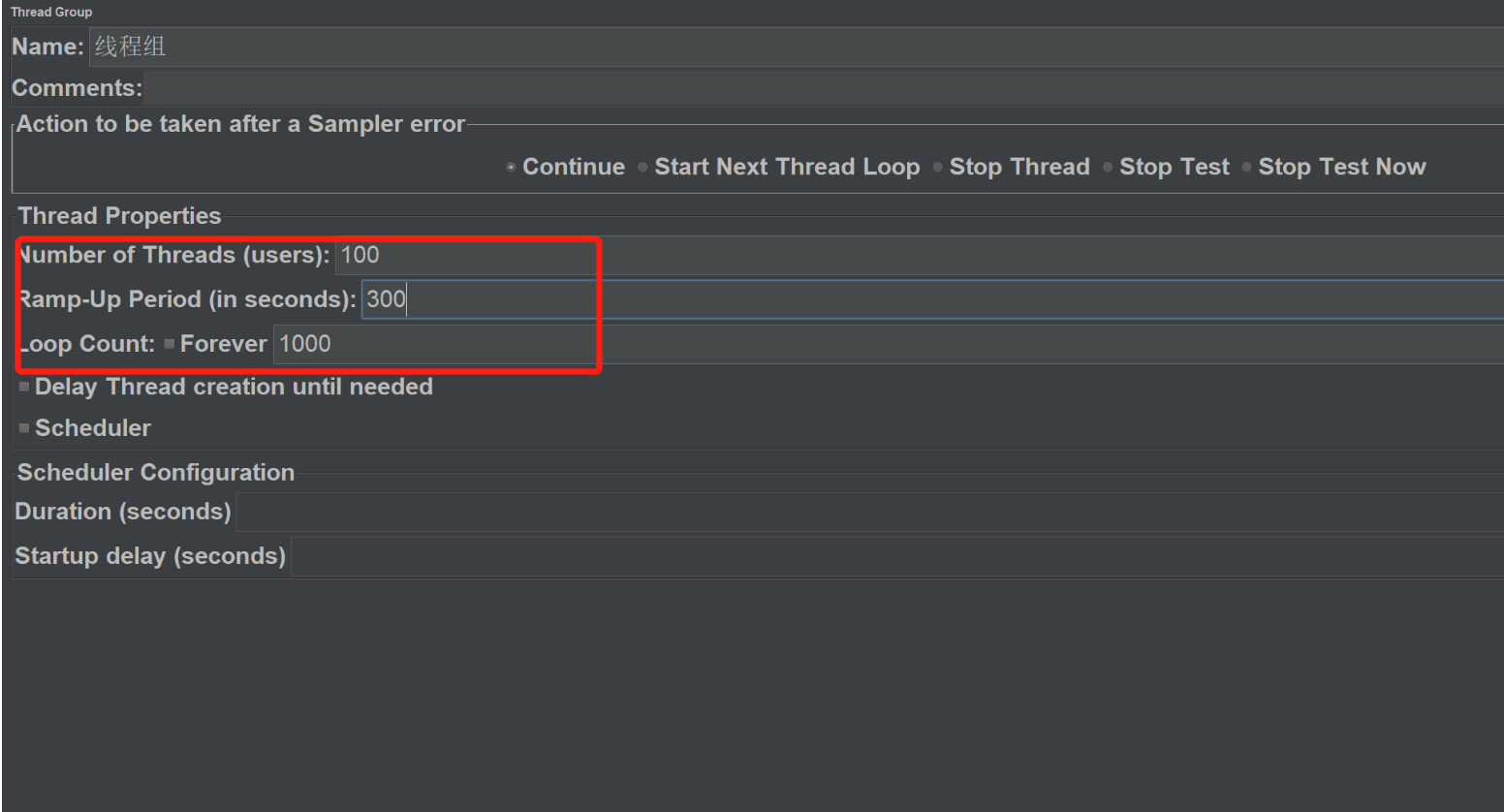
并发插入
模拟100个线程,发起1000个请求,根据情况做调整。。
检验标准
主要看数据大屏的内容有没有实时更新
观察数据库内部活动性能状态,MogDB主要靠系统表、系统视图、DBE_PERF Schema监控性能,DBE_PERF Schema内视图主要用来诊断性能问题,也是WDR Snapshot的数据来源。
系统表一共有71个表,系统视图有87个,DBE_PERF Schema的监控数据库对象包括有OS、Instance、Memory、File、Object、Workload、Session/Thread、Transaction、Query、Cache/IO、Utility、Lock、Wait Events、Configuration、Operator、Workload Manager,更多的信息移步
https://www.bookstack.cn/read/opengauss-1.0-zh/95d4a62a05c58dfe.md
MogDB在这方面的技术服务支持,通过MogDB Manager可以图形界面动态查看我们的数据库工作状态。
MogDB的AI特性
AI与数据库结合是近些年的行业研究热点,MogDB较早地参与了该领域的探索,并取得了阶段性的成果。AI特性子模块名为DBMind,相对数据库其他功能更为独立,大致可分为AI4DB、DB4AI以及AI in DB三个部分。
- AI4DB就是指用人工智能技术优化数据库的性能,从而获得更好地执行表现;也可以通过人工智能的手段实现自治、免运维等。主要包括自调优、自诊断、自安全、自运维、自愈等子领域;
- DB4AI就是指打通数据库到人工智能应用的端到端流程,通过数据库来驱动AI任务,统一人工智能技术栈,达到开箱即用、高性能、节约成本等目的。例如通过SQL-like语句实现推荐系统、图像检索、时序预测等功能,充分发挥数据库的高并行、列存储等优势,既可以避免数据和碎片化存储的代价,又可以避免因信息泄漏造成的安全风险;
- AI in DB 就是对数据库内核进行修改,实现原有数据库架构模式下无法实现的功能,如利用AI算法改进数据库的优化器,实现更精确的代价估计等。
AI4DB:数据库自治运维
如上文所述,AI4DB主要用于对数据库进行自治运维和管理,从而帮助数据库运维人员减少运维工作量。在实现上,DBMind的AI4DB框架具有监控和服务化的性质,同时也提供即时AI工具包,提供开箱即用的AI运维功能(如索引推荐)。AI4DB的监控平台以开源的Prometheus为主,DBMind提供监控数据生产者exporter, 可与Prometheus平台完成对接。
dbmind的技术原理
dbmind的组件如下
- DBMind Service:DBMind后台服务,可用于定期离线计算,包括慢SQL根因分析、时序预测等;
- Prometheus-server:Prometheus 监控指标存储的服务器;
- metadatabase:DBMind在离线计算结束后,将计算结果存储在此处,支持MogDB、SQLite等数据库;
- client:用户读取DBMind离线计算结果的客户端,目前仅实现命令行客户端;若采用MogDB等数据库存储计算DBMind计算结果,则用户可以自行配置Grafana等可视化工具对该结果进行可视化;
- openGauss-exporter:用户从MogDB数据库节点上采集监控指标,供DBMind服务进行计算;
- node-exporter:Prometheus官方提供的exporter, 可用于监控该节点的系统指标,如CPU和内存使用情况;
- reprocessing-exporter:用于对Prometheus采集到的指标进行二次加工处理,例如计算CPU使用率等。
dbmind的工作过程
dbmind涉及三个数据库,分为metadatabase、时序数据库、目标数据库。
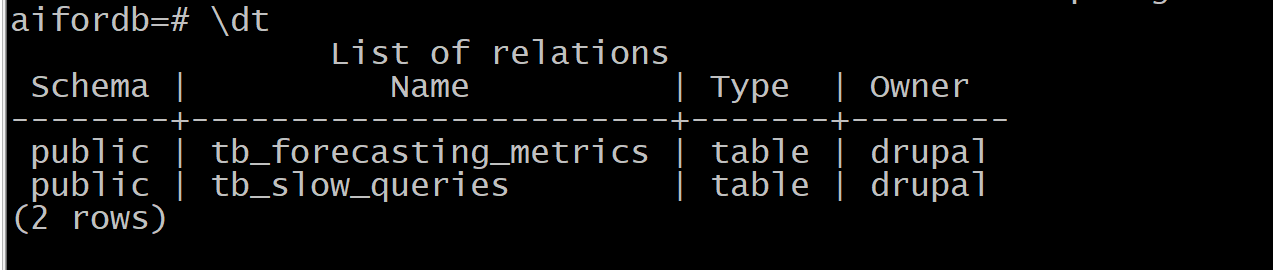
metadatabase是数据库自治运维的功能列表,可以选择sqlite\opengauss\postgresql,dbmind服务初始化安装成功后metadatabase会有两个表tb_forecasting_metrics和tb_slow_queries。
时序数据库默认是promethous,dbmind的业务场景中,需要采集两种数据,一种是系统监控的数据,包括CPU、内存、硬盘的工作指标状态,用node-exporter这个可以技术实现,一种是适配数据库openGauss、MogDB的采集神器openGauss-exporter,以后发展成熟的openGauss-exporter可能会覆盖到71个系统表,87个系统视图。因为node-exporter主要是为系统表、系统视图、DBE_PERF Schema服务的。
目标数据库就是我们的目标监控数据库,可以是MogDB或者openGauss。
安装配置dbmind
yum -y install zlib zlib-devel yum -y install bzip2 bzip2-devel yum -y install ncurses ncurses-devel yum -y install readline readline-devel yum -y install openssl openssl-devel yum -y install openssl-static yum -y install xz lzma xz-devel yum -y install sqlite sqlite-devel yum -y install gdbm gdbm-devel yum -y install tk tk-devel yum -y install libffi libffi-devel
python3.7编译安装
./configure --enable-optimizations --enable-loadable-sqlite-extensions --with-ssl-default-suites=python make make install
安装完python3.7后,通过python3.7的pip安装相关的dbmind的依赖包
/bin/python3.7 -m pip install -r /opt/mogdb/app/bin/dbmind/requirements-x86.txt
初始化dbmind服务安装,dbmind配置参数如下,TSDB要选择目标prometheous的IP,而METADATABASE可以选择sqlite、postgresql、opengauss,笔者本来打算用MogDB做metaBase,但是报错**m dbmind.common.exceptions.SQLExecutionError: Could not determine version from string '(MogDB 3.0.1 build 1a363ea9)*。最后选择postgresql作为metadatabase。
[TSDB]
name = prometheus # The type of time-series database. Options: prometheus.
host = XXXXX # Address of time-series database.
port = 9090 # Port to connect to time-series database.
[METADATABASE]
dbtype = postgresql
host = XXXXX
port = 5432
username = drupal
password = Encrypted->DbKRSO2dX/KTC7YDJxmrqA== # 直接填写原文密码,运行后会进行加密
database = aifordb
dbmind服务初始化安装
[omm@cenots7 ~]$ gs_dbmind service setup --initialize -c /opt/mogdb/app/bin/dbmind/misc
Starting to encrypt the plain-text passwords in the config file...
Starting to initialize and check the essential variables...
Starting to connect to meta-database and create tables...
The setup process finished successfully.
服务初始化安装成功后,postgresql数据库上看到以下两个表
启动dbmind服务时碰到一个错误如下
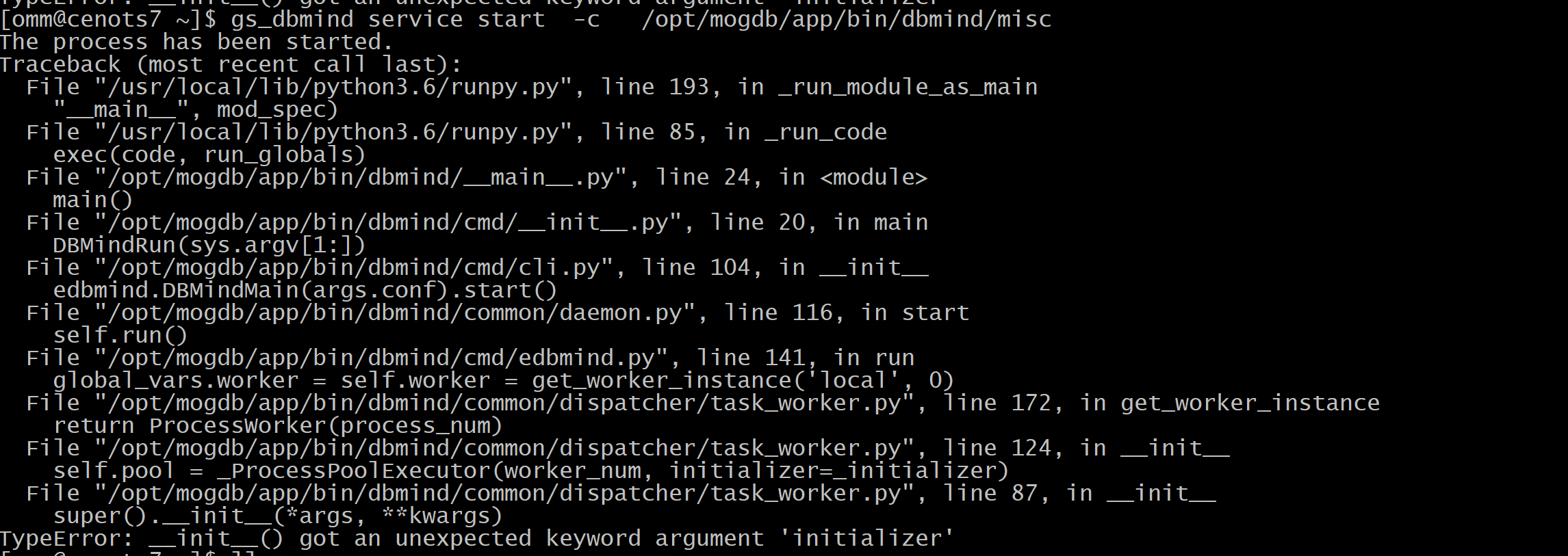
绕了很久找不到答案, 经过社区的朋友解答, an unexpected keyword argument ‘initializer’
与pyhon的版本有关系,发现自己用的是python3.6.1,切换到python3.6.15也不行,于是下载了一个python3.7.0,遵从下面的编译方式
./configure --enable-optimizations --enable-loadable-sqlite-extensions --with-ssl-default-suites=python make make install
确定DBMind服务是启动,拥有以下进程代表服务启动成功。

启动组件服务
启动opengauss_exporter的采集器
[omm@cenots7 ~]$ gs_dbmind component opengauss_exporter
--url postgresql://xxxx:Xxxx@192.xx.xx.xx:26000/sales
--web.listen-address 192.168.30.142 --disable-https 注意此外尾款MogDB的IP、端口、用户名、密码
The process has been started.
启动reprocessing_exporter 的采集器
[omm@cenots7 ~]$ gs_dbmind component reprocessing_exporter 192.168.XX.XXX 9090
--web.listen-address 192.168.30.142
--disable-https
The process has been started.
启动node_exporter 的采集器
[omm@cenots7 node_exporter-1.3.1.linux-amd64]# ./node_exporter
检查9187、8181、9100端口是否打开
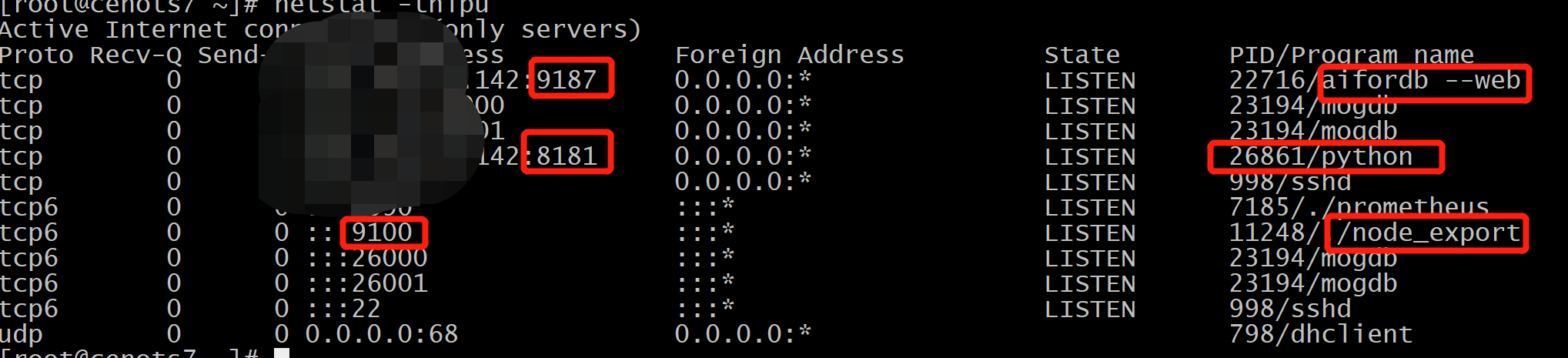
确保9187、8181、9100端口采集的数据传输到prometheus
[root@cenots7 ~]# cd /usr/local/prometheus/prometheus-2.38.0.linux-amd64
[root@cenots7 prometheus-2.38.0.linux-amd64]# vi prometheus.yml
- job_name: 'opengauss_exporter'
static_configs:
- targets: ['XXX.XXX.XXX.XXX:9187']
- job_name: 'reprocessing_exporter'
static_configs:
- targets: ['XXX.XXX.XXX.XXX:8181']
- job_name: 'node_exporter'
static_configs:
- targets: ['XXX.XXX.XXX.XXX:9100']
启动prometheus服务,默认是9090端口
[root@cenots7 prometheus-2.38.0.linux-amd64]# ./prometheus
访问9090,看看9187、8181、9100是不是能得到监控数据
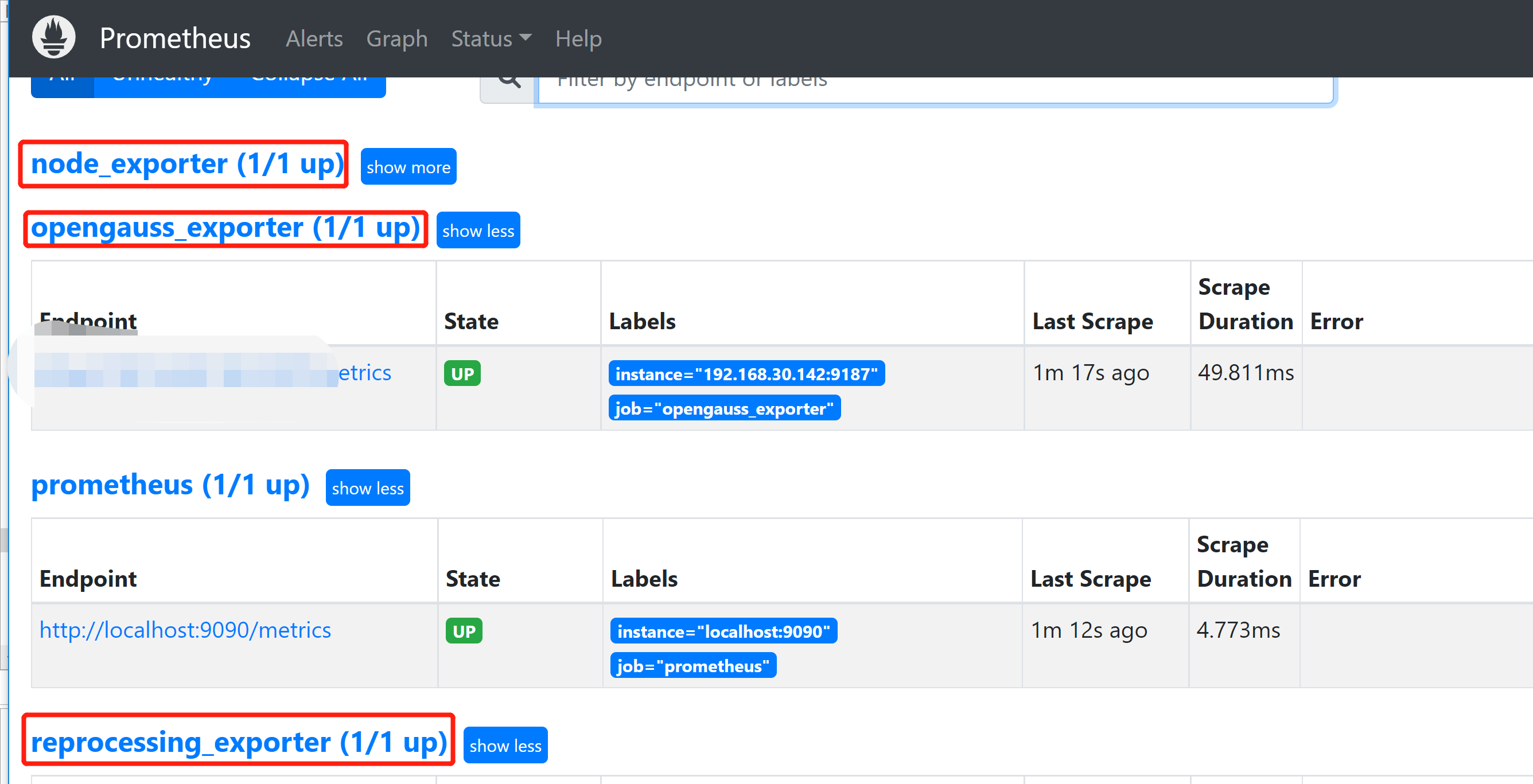
运行AI监测
笔者遇到很神奇的事情,前面需要python3.7才能启动dbmind服务,运行AI检测recommend 报错提示需要3.6版本才能运行程序。只能基于现有的python3.6安装相关依赖包。
/bin/python3.6 -m pip install -r /opt/mogdb/app/bin/dbmind/requirements-optional.txt
connect.json如下
[omm@cenots7 ~]$ cat connect.json
{
"db_name": "sales",
"db_user": "drupal",
"host": "XX.XX.XX.XX",
"host_user": "omm",
"port": 26000,
"ssh_port": 22
}
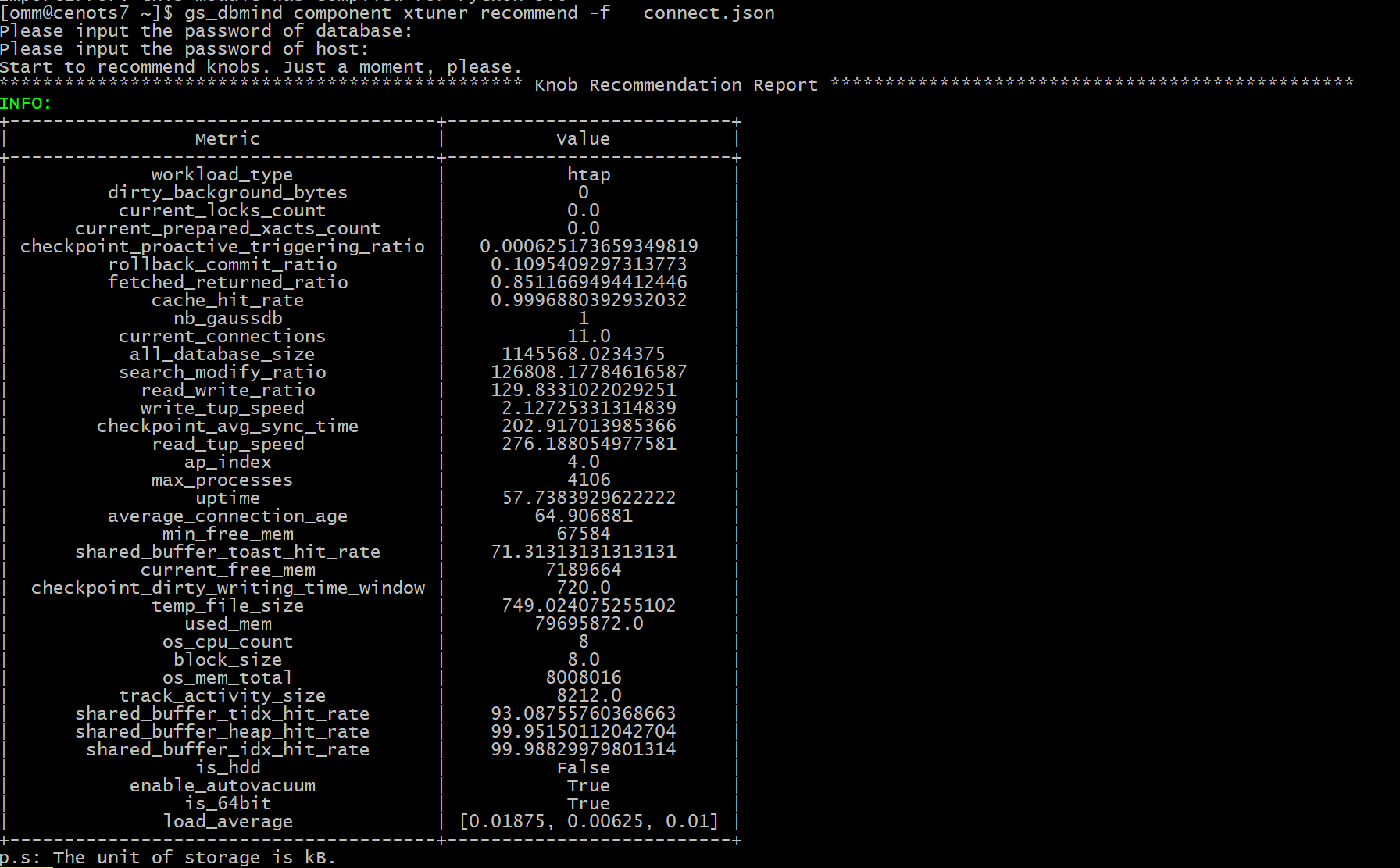
根据当前系统的负荷及当前数据库参数配置,给出一个最优值。运行以下命令
gs_dbmind component xtuner recommend -f connect.json
- temp_file_size:产生的临时文件数量,如果该结果大于0,则表明系统使用了临时文件。使用过多的临时文件会导致性能不佳,如果可能的话,需要提高work_mem参数的配置。
- cache_hit_rate:shared_buffer 的缓存命中率,表明当前workload使用缓存的效率。
- read_write_ratio:数据库作业的读写比例。
- search_modify_ratio:数据库作业的查询与修改数据的比例。
- ap_index:表明当前workload的AP指数,取值范围是0到10,该数值越大,表明越偏向于数据分析与检索。
- workload_type:根据数据库统计信息,推测当前负载类型,分为AP、TP以及HTAP三种类型。
- checkpoint_avg_sync_time:数据库在checkpoint 时,平均每次同步刷新数据到磁盘的时长,单位是毫秒。
- load_average:平均每个CPU核心在1分钟、5分钟以及15分钟内的负载。一般地,该数值在1左右表明当前硬件比较匹配workload、在3左右表明运行当前作业压力比较大,大于5则表示当前硬件环境运行该workload压力过大(此时一般建议减少负载或升级硬件)
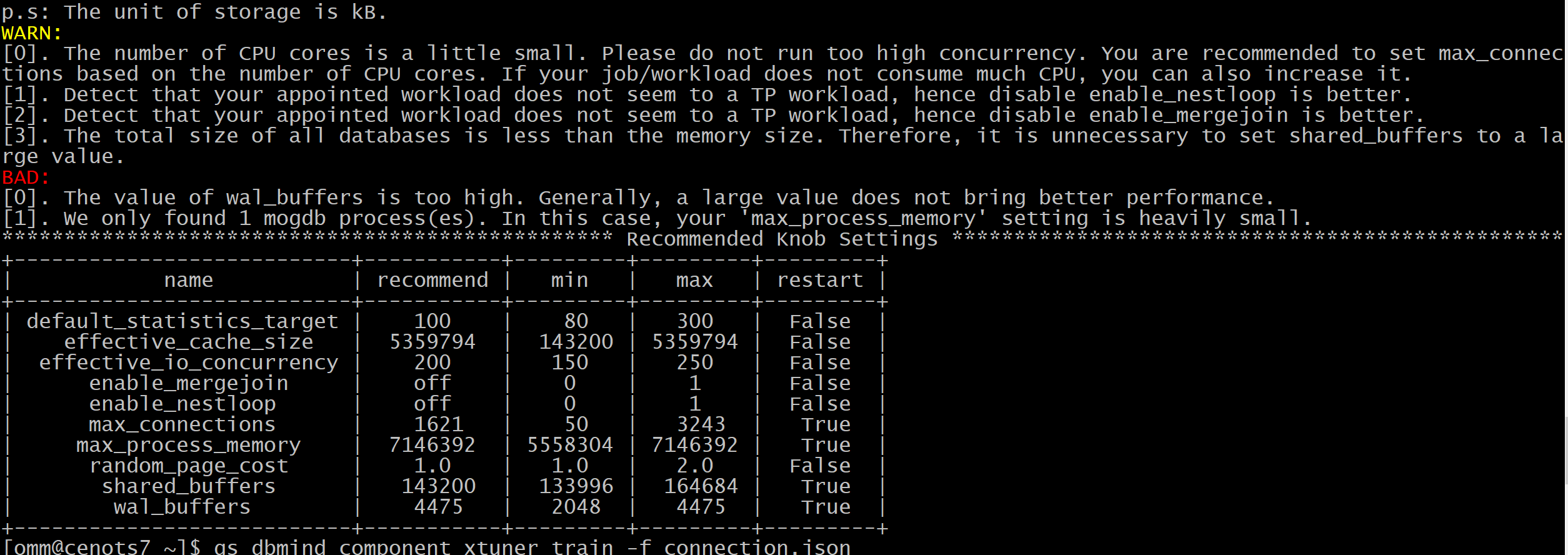
BAD是我们最值的重视的AI智能反馈,这里有两个参数是必须要做调整了。
[0]. The value of wal_buffers is too high. Generally, a large value does not bring better performance.
[1]. We only found 1 mogdb process(es). In this case, your ‘max_process_memory’ setting is heavily small.
************************************************* Recommended Knob Settings *
单query索引推荐
单query索引推荐功能支持用户在数据库中直接进行操作,本功能基于查询语句的语义信息和数据库的统计信息,对用户输入的单条查询语句生成推荐的索引。
- 本功能仅支持单条SELECT类型的语句,不支持其他类型的SQL语句。
- 本功能暂不支持分区表、列存表、段页式表、普通视图、物化视图、全局临时表以及密态数据库。
测试中发现它目前仅支持行式表,所以列式表负荷较大的可以转到行式表上面,使用DEMO示例如下
select "table", "column" from gs_index_advise('SELECT minmonth 月份,
COUNT(Customer_ID) 新用户数量 FROM ( SELECT MIN(EXTRACT(MONTH FROM Date)) AS minmonth,
Customer_ID FROM saletmall2016oltp GROUP BY Customer_ID ) t GROUP BY minmonth ORDER BY minmonth');
总结
davinci和MogDB两者搭配成为简单快捷的即时数据洞察平台,可以实现数据化运营,该平台既要满足图表的丰富性,又要保证信息发布的及时性,而且只需要一个DBA就可以轻易操作。用户可以通过浏览器就可以访问,管理员还可以根据需求指向发布。
业界有一个产品叫做opentsdb,基于hbase基础上做的二次开发,但是opentsdb实现监控业务场景的数据采集、数据传输、数据存储、数据监控、数据管理的一体化解决方案,名气之大在时间序列数据库的产品地位不逊于influxdb。MoGDB以后发展也可以借鉴opentsdb。
MoGDB提供不输MySQL与Postgresql的性能,此处是MoGDB数据库与DVAAS产品适配的一个例子,当然MoGDB在外围配套工具和生态建设方面还有很多进步的空间。笔者尝试了discuz、wordpress、drupal与MoGDB的适配,发现这些知名的CMS开源软件与MoGDB不适配,同样也不支持适配OpenGauss,笔者认为MoGDB以后兼容discuz、wordpress、drupal,这些都是MoGDB很好的发展方向。
