





您可能会在错误日志中看到事件报告集群节点或AlwayOn 之间的瞬时连接失败。您可能会在[sys].[dm_os_wait_stats]中观察到高 Asynch_Network_IO 。你甚至可能已经引起了你的网络人员的注意,只是被告知网络“很好”而让你不知所措。
瞬态网络问题可能来自多种来源。它们严重破坏了 Window Server Failover Clustering (WSFC) 和 SQL Server AlwaysOn 的稳定性。
WSFC、资源主机和 SQL Server 都通过远程过程调用、共享内存和 TSQL 命令相互同步。
虽然 WSFC 可以检测到仲裁丢失,但资源 DLL 可能会检测到 AlwaysOn 问题。
NIC 可能配置错误或根本没有为 SQL Server 配置,导致 NIC 出现拥塞期,并最终丢弃数据包,表现为网络中断。如果“打嗝”持续的时间足够长,则假定节点发生故障并启动不必要的故障转移。
在大多数情况下,服务之间的这种通信芭蕾提供了极其可靠的故障转移检测。但是,不同进程之间的默认 NIC 配置和敏感度级别可能过于激进或不适合您的环境。必须执行进一步的调整以实现所需的稳定性与故障转移检测的比率。
在调整灵敏度相关设置之前解决任何错误配置非常重要。连接问题通常是由于简单的错误配置造成的,而开箱即用的灵敏度值就足够了。
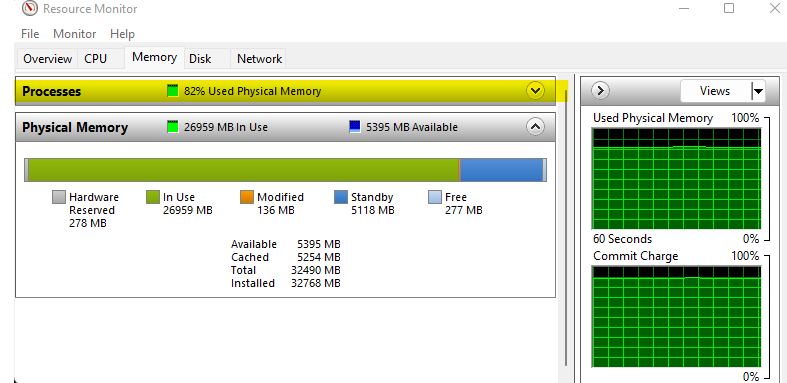
首先,您要确保 SQL Server 没有超出 Windows 内存管理 - 检查任务管理器并确保内存利用率在 77-82% 之间。无论 Windows Server 可用的 GB 数如何,当利用率接近 90% 时,Windows 内存管理就会开始显着影响整个服务器的性能。SQL Server 上的内存利用率不应高于 82%:
现在让我们将注意力转向 NIC/vNIC 配置。SQL Server要求启用接收端缩放 (RSS) 以获得最佳性能和可靠性。RSS 必须在 Windows和NIC/vNIC 上启用。
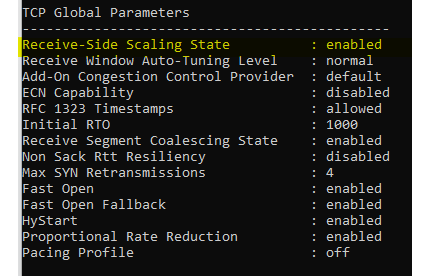
验证是否为 RSS 启用了 Windows:
#验证在 Windows 中启用的 RSS(CMD 作为管理员):
netsh int tcp show global
原文标题:Troubleshooting Transient AlwaysOn and Windows Failover Cluster Service Timeouts
原文作者:Ken Haff
原文地址:https://virtual-dba.com/blog/troubleshooting-transient-alwayson-windows-failover-cluster-service-timeouts/
一旦我们知道 Windows 已准备好使用 RSS,我们就可以查看 NIC/vNIC 配置。
#验证网卡上启用了 RSS(PoSh 作为管理员)
Get-NetAdapter | Where-Object { $_.InterfaceDescription -like '*' } |`
Get-NetAdapterAdvancedProperty |`
Format-Table -AutoSize
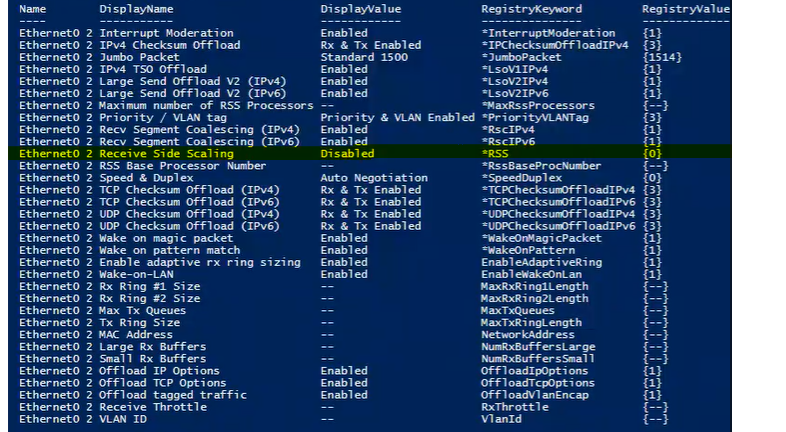
上面的适配器缺少几个设置(用“-”表示)。除了禁用 RSS 之外,您可以从上面看到发送/接收缓冲区和相关的环大小尚未配置。每次更新来宾上的 VMWare 工具后,验证 vNic 设置没有更改非常重要。
#查看RSS CPU矩阵(PoSh作为管理员)
(get-cluster).LeaseTimeout = 40000
#Set HealthCheckTimeout(PoSh 作为管理员):
(get-cluster).HealthCheckTimeout = 60000
#Set SameSubnetDelay(PoSh 为管理员):
(get-cluster).SameSubnetDelay = 2000
#Set CrossSubnetDelay(PoSh 作为管理员):
(get-cluster).CrossSubnetDelay = 4000
#Set RouteHistoryLength 仅在阈值发生更改时(PoSh 作为管理员):
(get-cluster).RouteHistoryLength = 40
#Set SessionTimeout (TSQL as SYSADMIN):
ALTER AVAILABILITY GROUP MODIFY REPLICA ON '' WITH (SESSION_TIMEOUT = 20);
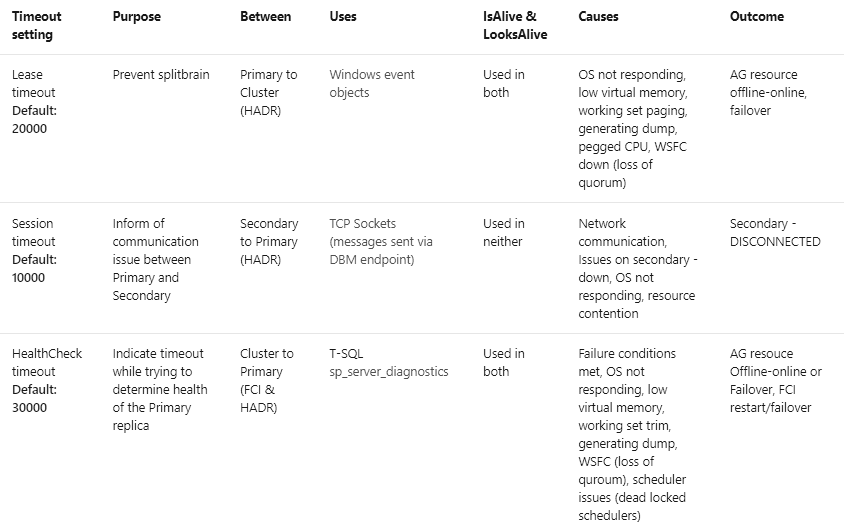
正确配置服务器并调整集群敏感度后,您会发现瞬时连接错误和错误的故障转移事件显着减少。仔细考虑权衡并了解使用不太积极的 SQL Server 群集监控的后果。增加集群超时值将增加对瞬态网络问题的容忍度,但会减慢对硬故障的反应。增加超时以处理资源压力或较大的地理延迟,也会增加从硬故障或不可恢复故障中恢复的时间。虽然这对于许多应用程序来说是可以接受的,但并不是在所有情况下都是理想的。每个部署的正确设置会有所不同,并且可能需要较长时间的微调才能发现。更改任何这些值时,
