




点击蓝字
关注我们
背景
随着移动互联网的发展(web3.0),数据通讯成本低,各种传感技术和智能设备(物联网)的产生,除了传统的手机计算机产生数据,手环、共享单车等新兴设备都在源源不断的产生海量的实时数据并发往云端。(提炼:实时数据源越来越多)
数据作为企业重要的资产,对于海量时序数据的存储和分析,能够帮助企业实现实时监控业务或者设备的运行情况,生成多维度的报表。通过大数据分析和机器学习,可以对业务进行预测和报警,帮助企业进行科学决策、节约成本、创造价值。
(实时数据属于企业重要资产,数据产生价值)
实时数据越来越多,传统的数据存储方式存在不足,比如数据记录量大(一天可以产生上亿条),对数据的实时写入成为瓶颈,查询分析要求高,传统的关系型数据库或NOSQL数据库应对实时数据,性能提升有限,只能是单纯依靠集群技术,投入更多的计算和存储资源,企业的存储和运营维护成本急剧上升。
时序数据的写入:如何支持每秒钟上千万上亿数据点的写入。
时序数据的读取:又如何支持在秒级对上亿数据的分组聚合运算。
成本敏感:由海量数据存储带来的是成本问题。如何更低成本的存储这些数据,将成为时序数据库需要解决的重中之重。
时序数据库概念
时序数据库全称为时间序列数据库。时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。时序数据库则记录了所有的历史数据。同时时序数据的查询也总是会带上时间作为过滤条件。相对于关系型数据库它的存储空间减半,查询速度极大的提高。时间序列函数优越的查询性能远超过关系型数据库,Informix TimeSeries非常适合在物联网分析应用。
时序数据库特点
1.数据是时序的,一定是有时间戳的
2.数据是结构化,单条数据不大,数据量很大
3.数据是写多读少,极少有更新或删除操作
4.无需传统数据库的事务处理
5.用户关注的是一段时间的数据,而不是某个时间点的数据
6.数据有保留期限
7.数据的查询分析一定是基于时间段和地理区域的
8.除存储查询外,往往还需要各种统计和实时计算操作
9.数据量巨大,一天的采集量就可以达到100亿条
时序数据库分类
[时序]TimescaleDB, 基于 PostgreSQL, 支持 SQL.
[时序]KairosDB, 基于 Cassandra, 不支持 SQL.
[通用]CrateDB, 基于 Elastic Search, 但支持ANSI SQL
[时序]InfluxDB, 是 db-engines 上排名第一的时序数据库, 最新版中集群功能不开源了, 商业版支持, 另外并发查询性能较差.
[通用]Kudu, 列式存储(类parquet), 支持 java API 更新数据, 比较赞的是支持 upsert. 可以通过 impala 或 spark 来支持SQL 查询.
时序数据库优缺点
· 数据写入 时序数据会按照指定的时间粒度持续写入,支持实时、高并发写入,无须更新或删除操作。
· 数据读取 写多读少,多时间粒度、指定维度读取,实时聚合。
· 数据存储 按列存储,通过查询特征发现时序数据更适合将一个指标放在一起存储,任何列都能作为存储,读取数据时只会读取所需要的维度所在的列;以不同时间粒度存储,将最近时间以一个比较细的粒度存储,可以将历史数据聚合成一个比较粗的粒度。
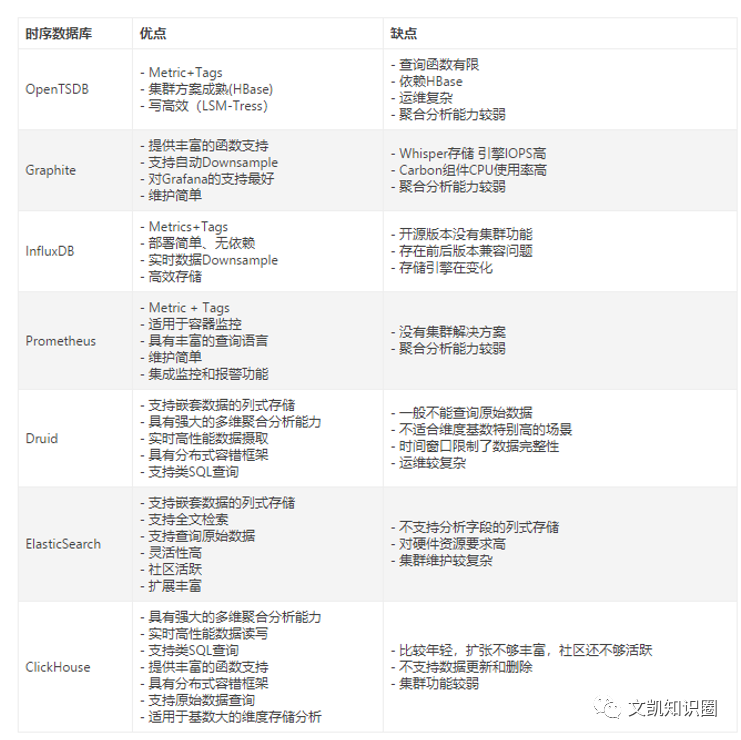
各大厂商的时序数据库

文凯知识圈
扫码关注我们
