




需求背景
技术方案
垂直分表——大表拆小表,基于字段进行,将一些不常使用或长度较大字段拆分成扩展表; 垂直分库——基于业务边界进行数据库层面的拆分,解决单库的性能瓶颈; 水平分表——横向分表,将表中的数据行按照一定规律分布到不同的表中,降低单表数据量,优化查询性能,但是库级别还存在瓶颈; 水平分库分表——在水平分表基础上,将数据进一步分布到不同的库中,缓解单机和单库的性能瓶颈和压力,突破 IO、连接数、硬件资源的瓶颈;
技术选型
Sharding-JDBC (ShardingSphere)
优点:
成功应用案例多,京东、当当等大公司广泛应用;
使用简单,Sharding-JDBC 快速集成项目,不需要部署额外服务;
性能优异,损耗低,官网有测试结果。
缺点:
MyCat
优点:
支持 JDBC 连接 ORACLE、DB2、SQL Server、MYSQL 等数据库;
支持多语言、跨平台,部署和实施简单高可用,故障自动切换。
缺点:
需要单独部署一个服务,增加了系统风险;
方案制定(Sharding-JDBC 4.x)
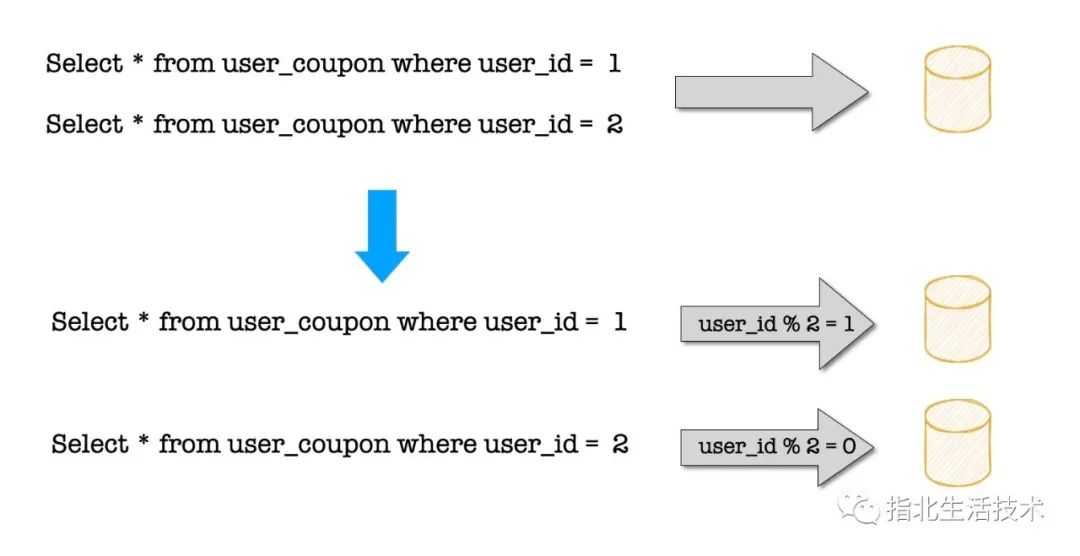
用户券分表配置
添加依赖包
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>$4.0.0-RC1</version>
</dependency>
分表个数选择
配置数据源及策略
spring.shardingsphere.props.sql.show = true
#datasource
spring.shardingsphere.datasource.names = ds
spring.shardingsphere.datasource.ds.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds.url = jdbc:mysql://{ip}:{port}/{db}?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.ds.username = {username}
spring.shardingsphere.datasource.ds.password = {password}
#table
spring.shardingsphere.sharding.binding-tables = user_coupon
spring.shardingsphere.sharding.tables.user_coupon.actual-data-nodes = ds.user_coupon_$->{0..1}
spring.shardingsphere.sharding.tables.user_coupon.table-strategy.inline.sharding-column = userId
spring.shardingsphere.sharding.tables.user_coupon.table-strategy.inline.algorithm-expression = user_coupon_$->{userId % 2}
历史数据迁移(datax)
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能。
关键配置
{
"job":{
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"*"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://{ip}:{port}/{db}?useUnicode=true&characterEncoding=utf8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true"
],
"table": [
"user_coupon"
]
}
],
"username": "xxx",
"password": "xxx",
"where": "userId%2=0"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"*"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://{ip}:{port}/{db}?useUnicode=true&characterEncoding=utf8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true",
"table": [
"user_coupon_0"
]
}
],
"username": "xxx",
"password": "xxx",
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [],
"writeMode": "replace"
}
}
}
],
"setting": {
"speed": {
"channel": "10"
}
}
}
}
增量数据同步(canal)
canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。canal 工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
canal 解析 binary log 对象(原始为 byte 流)
注意事项
主键ID问题
用其他主键,比如 snowflake;
自己实现步长(数据库、redis);
hibernate 自增序列。
MySql保留字问题
解决方案:
升级Sharding-JDBC版本为最新版;
去保留字,字段重命名。
主键查询
参考
datax:https://github.com/alibaba/DataX
文章转载自指北生活技术,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
