




上期推文为简便起见,我们的描述性统计使用的盈余管理数据集已经预处理。然而,现实情况常常是,我们收集的数据存在缺失值、重复值与异常值,数据类型也可能不符合分析需要,等等,这些情况的存在不同程度地影响着数据分析的质量,有时如不消除上述问题的影响,所得分析结论甚至截然相反。因此,从数据分析的目标实现与价值意蕴视角看,数据预处理都是任何一个数据分析人员必须掌握的重要技术。
本期推文专门介绍数据预处理的Python实现。
一、数据集创建
首先,我们基于上期的盈余管理数据集,运用Stata17的do文件创建一个需要预处理的数据集rem.dta,并通过export命令将其输出为Excel同名格式文件rem.xlsx,参见图1。
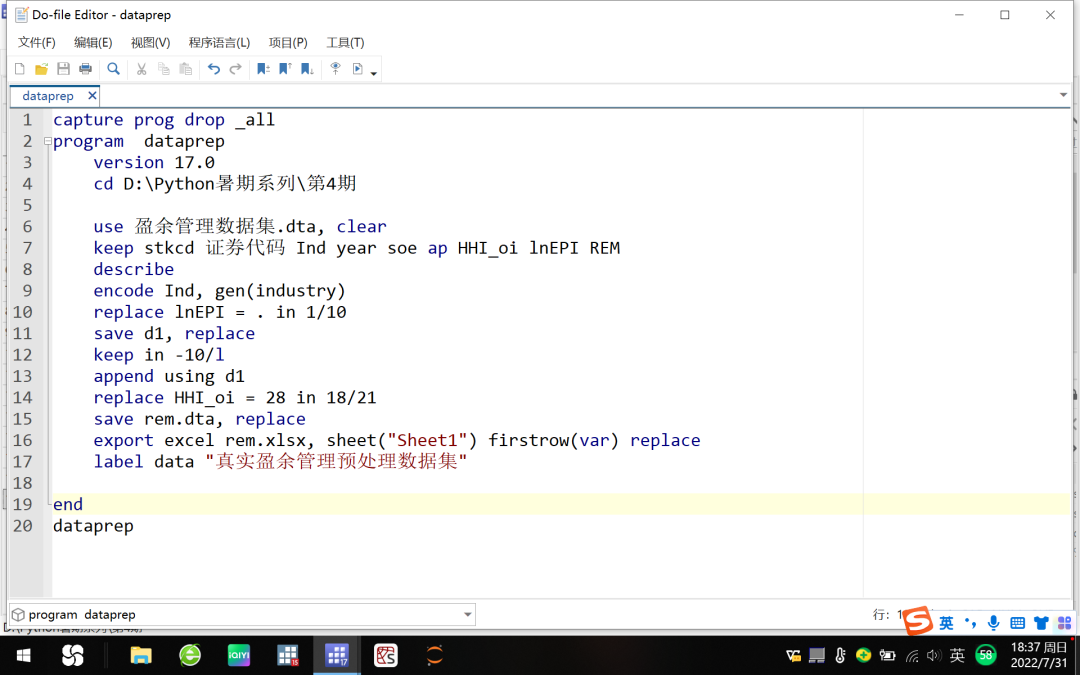
图1 创建预处理数据集的do文件dataprep.do
二、数据导入
打开Jypyter Notebook,输入以下命令导入rem.xlsx文件。
import pandas as pd
df = pd.read_excel(r"D:\Python暑期系列\第4期\rem.xlsx", sheet_name = "Sheet1")
利用describe()方法获取数值型变量的分布情况,即描述性统计,参见图2。
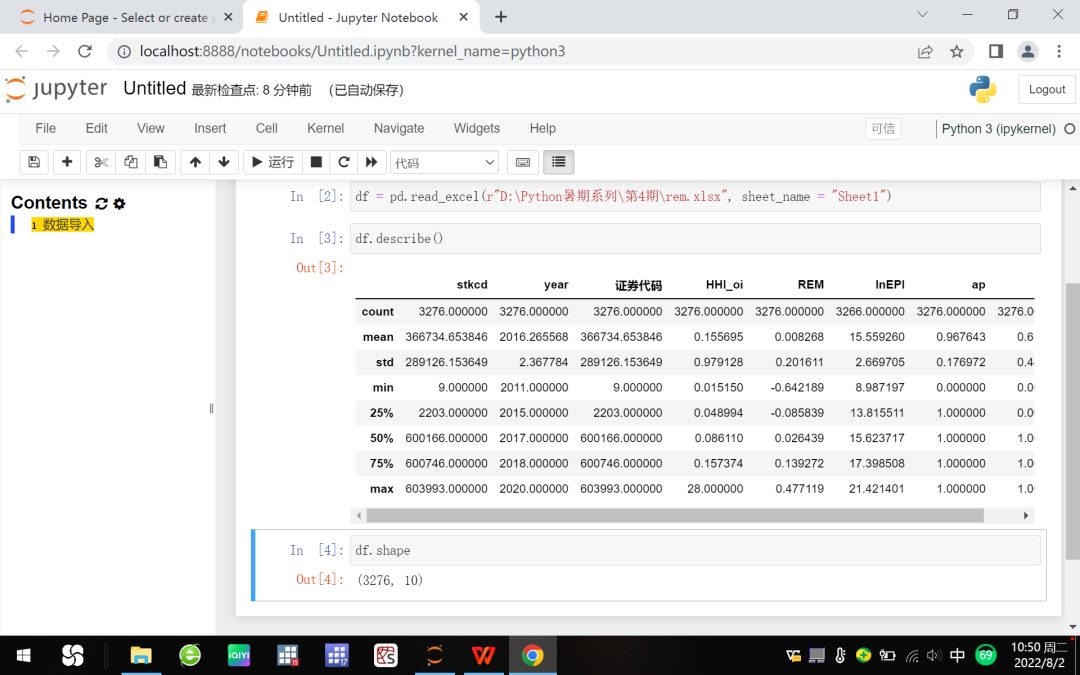
图2 键入describe()生成描述性统计
利用shape方法返回的元组表示df表有3276行10列数据。
三、数据类型转换
利用dtype方法查看证券代码这一列的数据类型;利用astype()方法将证券代码从int类型转换为float类型,具体命令如下,运行结果参见图3。
df["证券代码"].dtype
df["证券代码"].astype("float64")

图3 Python的数据类型转换
四、缺失值处理
(一)判断缺失值。首先我们要判断数据表是否存在缺失值,方法有两种,一种是键入info()查看数据类型等信息,参见图4;另一种是isnull()方法,该方法是基于该命令的两个返回值True和False予以判断,如果是True,则表示对应的行列位置就是缺失值。
具体命令如下:
df.info()
df.isnull()
df.isnull().head(30)
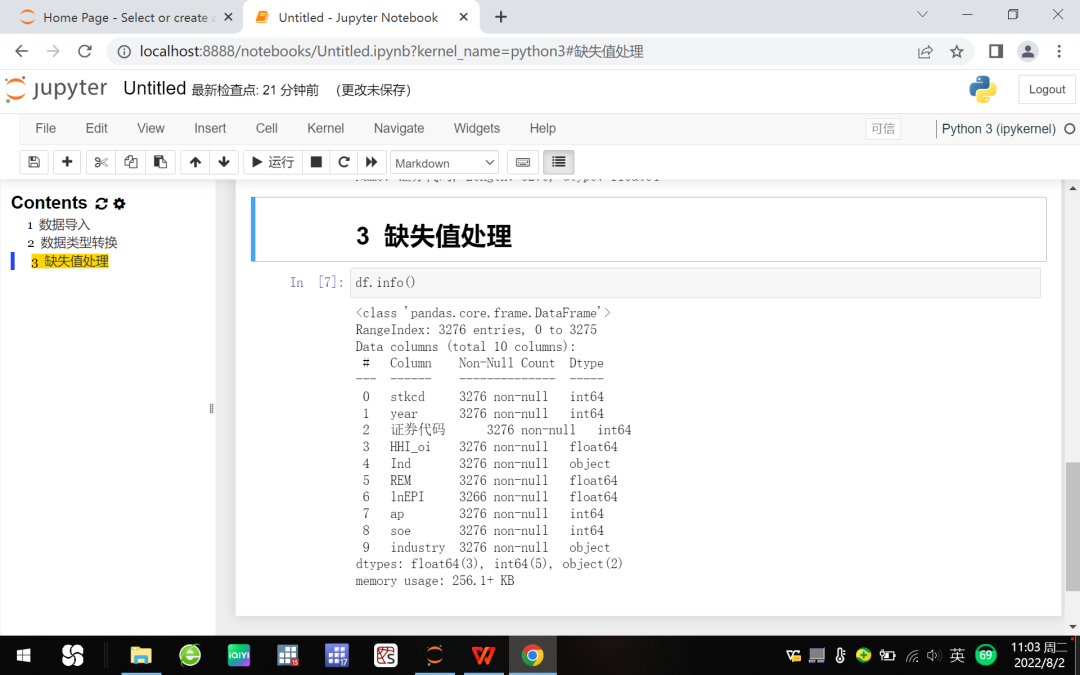
图4 利用info()命令判断缺失值
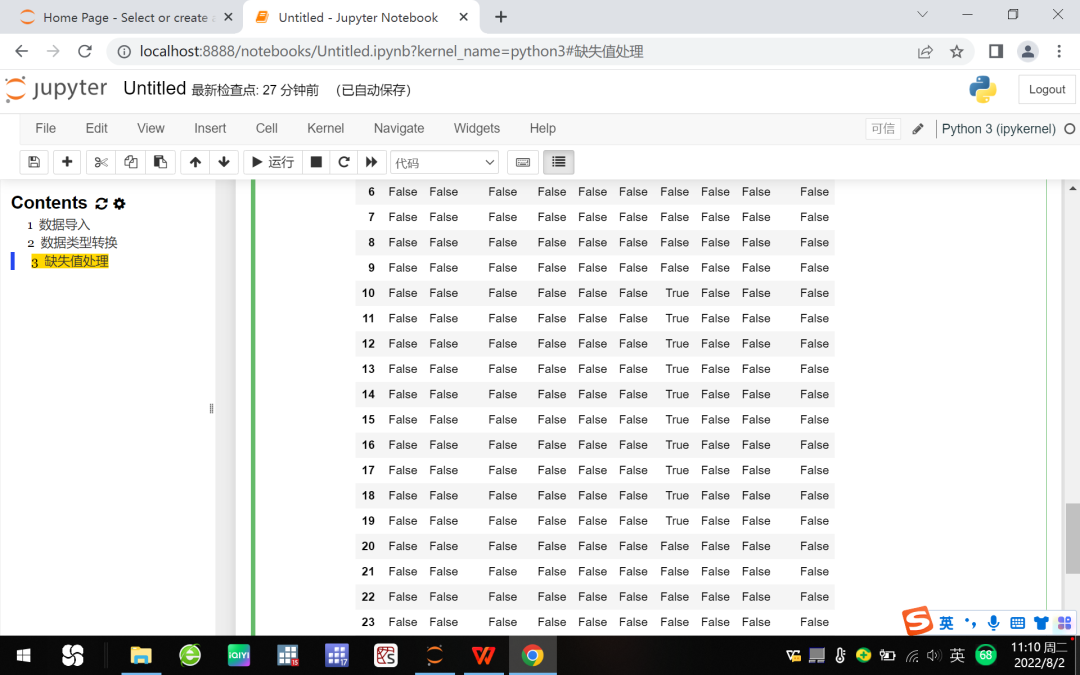
图5 利用isnull()命令判断缺失值
不难发现,lnEPI列存在10个缺失值(3276 - 3266)。
(二)处理缺失值。缺失值的处理方式有两种,一种是删除,即丢弃pandas中任何含有数据缺失值的行;另一种是填充,即把缺失的那部分数据用某个值代替。具体命令如下:
cleaned
df.fillna(0,inplace = True)
我们利用fillna命令将lnEPI的10个缺失值全部替换为0,参见图6。

图6 利用fillna命令填充缺失值
最后,键入info()命令可以验证缺失值已经全部填充完毕,参见图7。

图7 利用info()命令验证缺失值填充
五、重复值处理
(一)检查重复数据。使用df.duplicated().value_counts()统计重复值个数,图8显示,True = 95表示该数据表存在95个重复数据。键入df.duplicated()则直接返回一个布尔值,根据布尔值True判断各行是否为重复行。
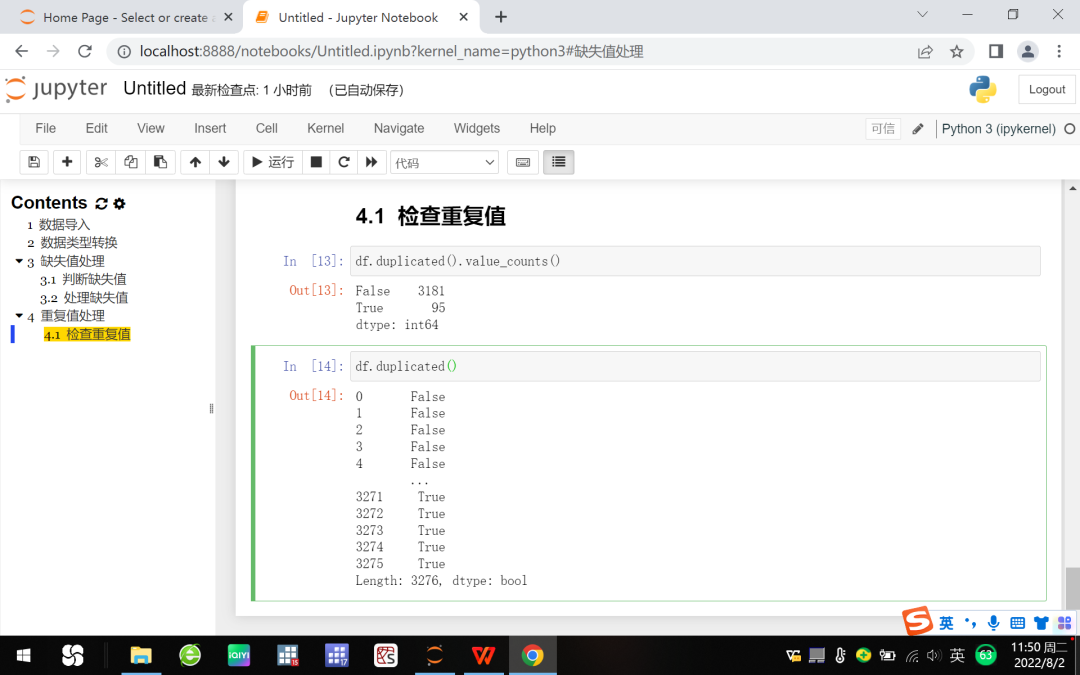
图8 检查数据表的重复值
(二)清洗重复数据。使用df.drop_duplicates()清除重复的最后一行数据,参见图9。
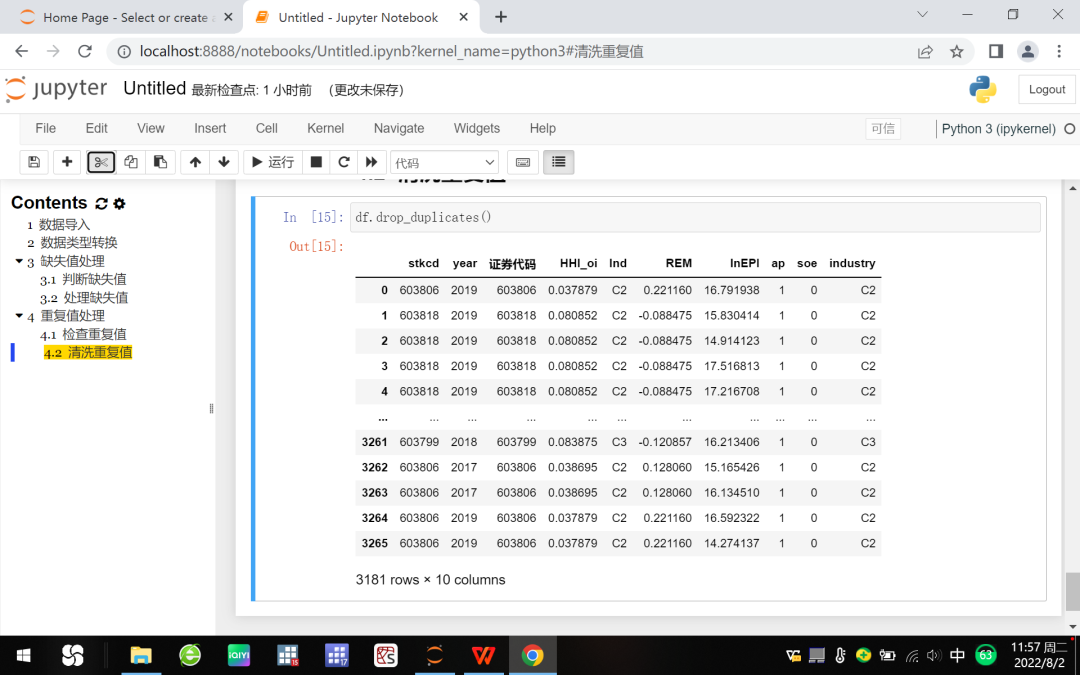
图9 缺失值清除
六、异常值处理
(一)异常值检测。可以依据业务经验划定指标正常范围、依据箱型图上下边缘点值以及偏离正态分布一定标准差(例如3倍)等规则确定异常值。
(二)异常值处理。常见处理方式是删除,也可将异常值当作缺失值予以填充,等等。本例中,衡量产品市场竞争程度的赫芬达尔指数HHi_oi应该小于1,我们使用df[df["HHI_oi"] < 1]命令将数据表中符合这一条件的观测予以保留,参见图10。
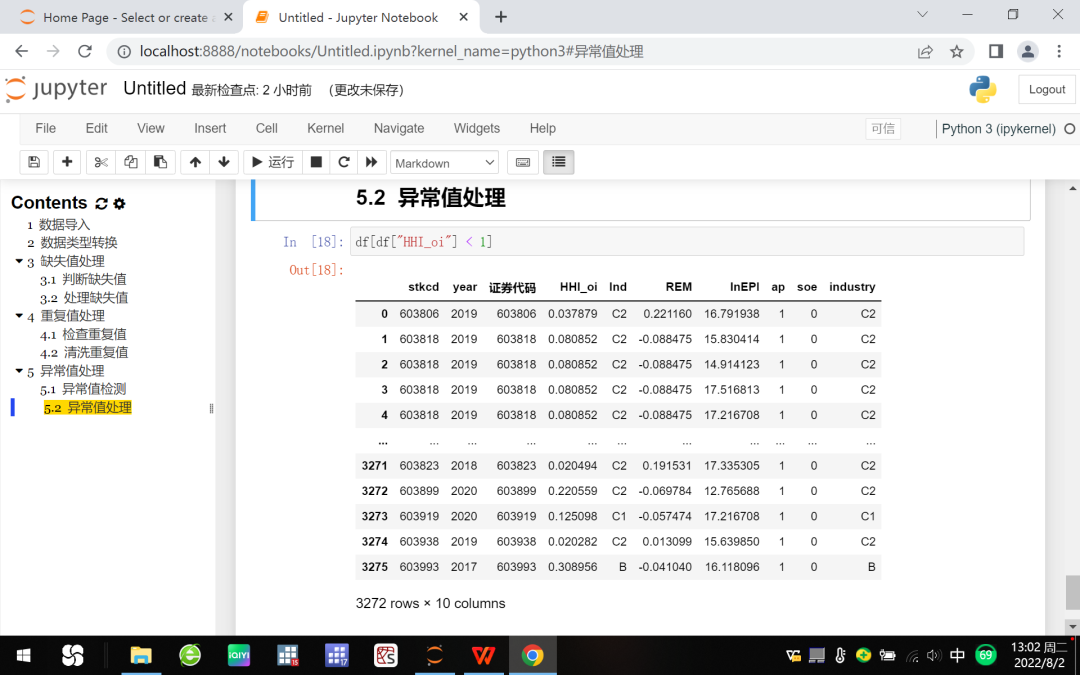
图10 异常值处理
六、数据导出
使用以下命令导出以上预处理数据为.xlsx文件“Python数据预处理.xlsx”,存储在“D:\Python暑期系列\第4期文件夹”中。
df.to_excel(excel_writer = r"D:\Python暑期系列\第4期\Python数据预处理.xlsx",
sheet_name ="rem", index = False, encoding = "utf-8",na_rep = 0, inf_rep = 0)
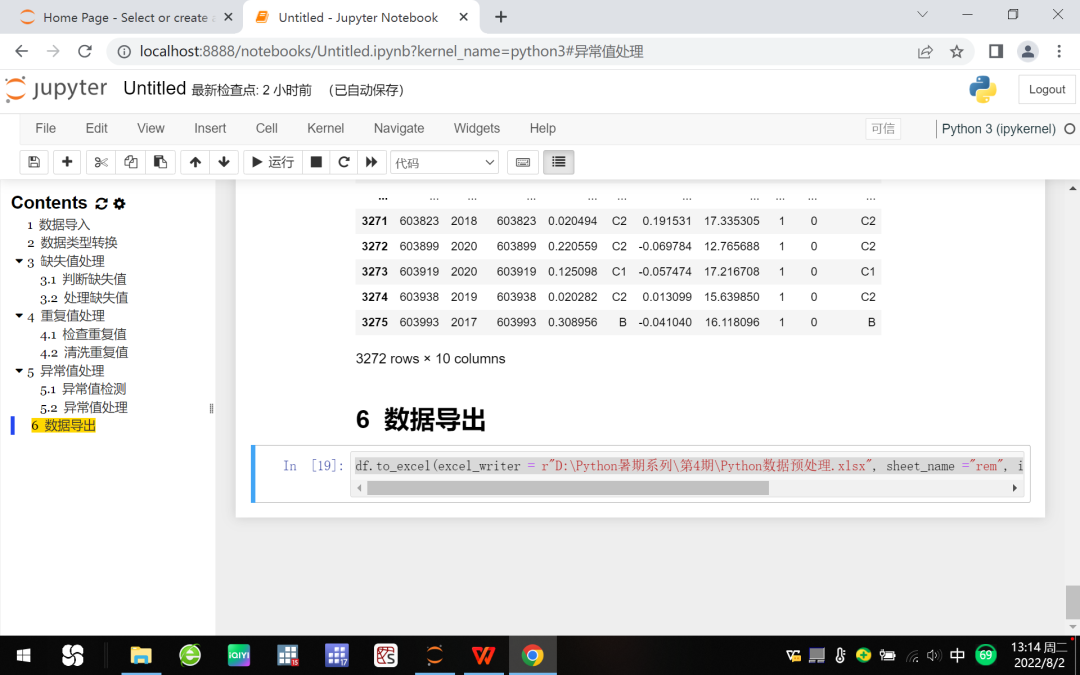
图11 预处理数据集保存
编辑:Sunny
审核:杨 露
往期回顾:
祁祁连山迷万重,分类别裁识流变——真实盈余管理桑基图的Stata实现



实证会计一点通
扫描二维码关注我们

鼎园会计微信群
本群主旨:
交流Stata与Python,
分析结构化数据,
探讨非结构化文本会计,
共同书写鼎园会计人生。
