




背景
在AI应用领域,图像是业界公认最内卷的方向之一,以至于出现很多硕博同学花了几年时光,刚基于当时的SOTA(State Of The Art,业内用于表示“效果最好的方法”),取得了一丢丢微弱的提升,论文都还没写完,某个大佬就提出了一种"颠覆性"的新方法,吊打旧SOTA(自然也吊打他们改进的方法)。
Diffusion Model就是图像生成领域近年出现的"颠覆性"方法,将图像生成效果和稳定性拔高到了一个新的高度。本文接下来就会从效果及原理两个部分介绍Diffusion Model,具体章节如下:
2022最卷的领域-文本生成图像:这个部分会展示这两年文本生成图像领域成果,非从业者可以看看这个部分权当八卦 Diffusion Model 演进:这个部分会具体介绍推动Diffusion Model发展的几篇论文,从业者们可以看看。毕竟再不学习就卷不过应届生了 :-)
2022最卷的领域-文本生成图像
2021年1月,国际知名AI公司OpenAI公布了其首个文本生成图像模型DALL·E 。人如其名,这个模型可以根据输入的文字生成对应内容的图像,并且生成的图像还挺靠谱,引得网友们纷纷转发。这里展示几个DALL·E的效果。



可以看出虽然DALL·E 已经能够理解简单的文本语义并绘制图像,但还限于比较简单的场景。一般来说,在未来的几年内,会逐步有新的技术被提出,逐步改进DALL·E 并最终趋向成熟。但“未来”比大家预料的要来得快得多。
约1年左右,2021年12月底,OpenAI再次提出GLIDE模型,此模型能够生成比DALL·E更复杂、更丰富的图像,其效果如下



不到半年,2022年4月,OpenAI又又又提出DALL·E 2,这次他们已经自信地表示“能够生成真实或者艺术图像”。让我们来看看它的效果



仅一个月后,2022年5月,Google不甘落后发表其新模型Imagen,在写实性上击败DALL·E 2。其效果如下



由于存在法律和伦理上的风险,上文所介绍的模型虽然都公开了论文,但是具体模型并没有开放出来。当然,留着未来用于商业化变现也是一个很重要的原因。
不过幸好,在程序员界没什么是没有开源方案的。这里我就以开源项目Disco Diffusion为例,展示一些它的结果。当然由于数据量不够,效果跟上面的工业界作品肯定是不能比拟的,仅供娱乐:



展示完各个模型的效果,可以发现从2022年初开始,各种新模型如雨后春笋般冒出来,但其实它们背后都是一个模型范式:Diffusion Model 。下文我们就介绍下这个图像界的新贵,它在图像领域已经是比肩GAN的存在,或许其作用会进一步延伸到NLP,最终成为又一个通用模型范式。
Diffusion Model 演进
事实上Diffusion Model 并不是新概念,在2015年“Deep Unsupervised Learning using Nonequilibrium Thermodynamics”就已经提出了DPM(Diffusion Probabilistic Models)的概念。随后在2020年“Denoising Diffusion Probabilistic Models”中提出DDPM模型用于图像生成,两者继承关系从命名上一目了然。DDPM发布后,其优异的图像生成效果,同时引起了各位刷分大佬和水文大佬们的注意,再次点燃了被GAN统治了若干年的图像生成领域,不少优质文章就此诞生:
Denoising Diffusion Implicit Models,2020:在牺牲少量图像生成多样性,可以对DDPM的采样效率提升10-50倍 Diffusion Models Beat GANs on Image Synthesis,2021:成功利用Diffusion Models 生成比GAN效果更好的图像,更重要的是提出了一种Classifier Guidance的带条件图像生成方法,大大拓展了Diffusion Models的使用场景 More Control for Free! Image Synthesis with Semantic Diffusion Guidance,2021:进一步拓展了Classifier Guidance的方法,除了利用Classifier ,也可以利用文本或者图像进行带语义条件引导图像生成 Classifier-Free Diffusion Guidance,2021:如标题所述,提出了一种无需提前训练任何分类器,仅通过对Diffusion Models增加约束即可实现带条件图像生成的方法 GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models,2021:在以上这些技术能力基础已经夯实后,OpenAI利用他们的“钞能力”(数据、机器等各种意义上)训练了一个超大规模Diffusion Models模型,成功超过自己上一代“基于文本的图像生成模型”DALL·E 取得新的SOTA 再之后的2022年,OpenAI的DALL·E 2、Google的Imagen 等等各种SOTA你方唱罢我登场,也就出现了文章开头那一幕
本文仅关注DDPM及其后Diffusion Model演进,涉及的文章大致如上。同时由于DDIM对于DDPM采样效率的优化,并不影响对DDPM模型整体发展脉络的理解,因此下文关于DDIM也不再单独介绍(实在是肝不动了T.T )。
温馨提示,DDPM和VAE(Variational AutoEncoder)在技术和流程上有着一定相似性,因此强烈建议先阅读“当我们在谈论 Deep Learning:AutoEncoder 及其相关模型”中Variational AutoEncoder部分,将有助于理解下文。
另外,下文参考了上述每篇原始论文,以及What are Diffusion Models?,有兴趣的同学可以自行研究。
DDPM(Denoising Diffusion Probabilistic Models)
DDPM的核心思路非常朴素,跟VAE相似:将海量的图像信息,通过某种统一的方式encode成一个高斯分布,这个过程称为扩散;然后就可以从高斯分布中随机采样一份数据,并执行decode过程(上述encode的逆过程),预期即可生成一个有现实含义的图像,这个过程称为逆扩散。整个流程的示意图如下,其中 就是真实图像, 就是高斯分布图像。
由于DDPM中存在大量的公式推导,本文不再复述,有疑问的可以参考B站视频“Diffusion Model扩散模型理论与完整PyTorch代码详细解读”,UP主带着大家推公式。
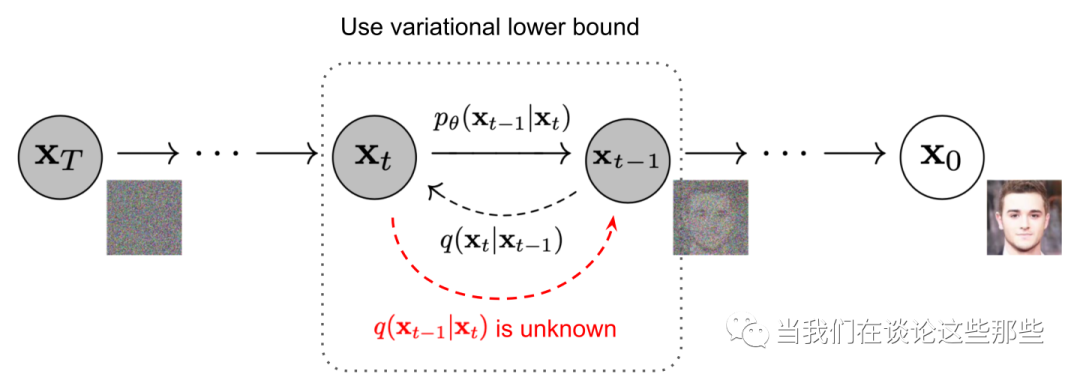
扩散阶段
扩散阶段的设计很有意思:原始图像 通过 次转换,分别生成 ,其中每一次转换都是在上一次生成的图像基础上添加一些噪声。因此,这个过程可以视为一个马尔科夫过程。具体公式如下:
其中 是用于控制随机程度的参数, ,且建议 ,从而确保 。 表示给定 时, 的联合概率分布。
令 且 ,易得:
即,当给定原始图像 , 不需要真的执行 次操作,而是可以直接根据上述公式采样得出。
逆扩散阶段
虽然扩散阶段的 在 给定的情况下可以确定,但其逆扩散过程 却无法直接获得。因此,我们需要用一个参数为 的模型去拟合逆扩散过程,这个拟合的分布可以记作 。且由于 ,于是有
对于均值,这里省略各种推导,“易得”公式如下。其中, ,为扩散阶段的随机噪声。
对于方差,为了方便优化,文中将 ,其中 是一个与时间 有关,但不需要训练的参数。按照作者实验, 就有不错的效果。
训练与采样
给定数据集 ,我们期望经过 扩散+逆扩散 完美还原原图,因此Loss 可以定义为
上述公式的意思是,由于原始Loss 不好优化,因此我们退而求其次优化其上界 。当 最小化时,预期 也得到了最小化。
其中, ,为扩散阶段的随机噪声。 表示在任意时刻 ,神经网络 都能够根据 预测出真实 。
因此,整体训练和采样(即用已训练的模型生成图像)的步骤如下

Diffusion Models Beat GANs on Image Synthesis
这篇文章来自OpenAI,其最主要的贡献就是提出了如何在给定条件下进行图像生成,且效果比GAN更好,大大拓展了Diffusion Models的实用性。这种来自工业界的文章普遍思路比较朴素,但是足够好用。
当给定训练好的Diffusion Models,如上文所述其逆扩散过程可以描述为 。假如此时我们要求逆扩散的图像必须属于某种类型 ,那么逆扩散过程就应该被重新定义为
为了获取类型 ,我们需要一个训练好的分类器 ,这个分类器跟普通分类器的区别是,必须要见过加噪图像 ,因此重新训练是不可避免的。此时逆扩散过程就变成了 。其可以化简为
其中, 是一个概率密度归一化的常数, 。因此,Classifier Guided Sampling 的过程可以总结如下图

More Control for Free! Image Synthesis with Semantic Diffusion Guidance
既然能够使用分类器引导(Classifier Guided)Diffusion Models采样图像,那很自觉地,是否可以利用更soft的方式引导呢。本文就将 Classifier Guided 的方法推广,提出了语义引导(Semantic Guided)的方式,更具体点,就是通过文本引导(Language Guidance)——生成满足文本语义的图像、图像引导(Image Guidance)——生成相似语义的图像,这再一次大大拓宽了Diffusion Models的使用场景。
具体做法基本是顺延“Diffusion Models Beat GANs on Image Synthesis”的公式,定义 ,则采样过程可修改为如下,不同的引导方式只需要调整 的定义即可。

在分别介绍Language Guidance和Image Guidance之前,由于它们都使用了 CLIP 这个预训练模型,我们先对其做个简单介绍。
CLIP
CLIP(Contrastive Language-Image Pre-training)来自于OpenAI的论文“Learning Transferable Visual Models From Natural Language Supervision”。在NLP领域中,通过自监督训练大规模预训练模型已经是基本操作了,BERT、GPT等层出不穷,席卷学术和工业界。利用预训练模型,在很多任务上,few-shot甚至zero-shot就能比肩各种曾经的SOTA。
图像领域也有pre-train的先例如ImageNet,但是这种task-specified都是需要标记的,因此训练样本有限。为了真正用上海量数据,OpenAI爬取了互联网4亿条 图像-文本描述 映射数据,基于此训练了CLIP模型,当然其效果也确实很惊人,在很多计算机视觉任务中zero-shot就能取得不错的成绩。
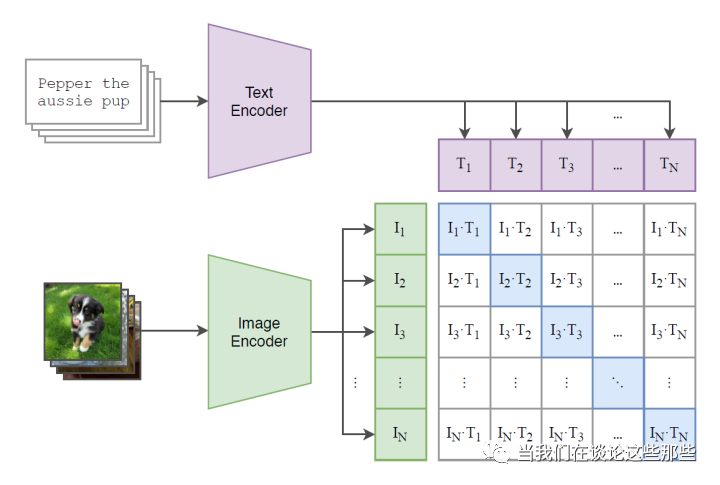
CLIP的具体模型结构如上图,也算充分说明了所谓“大道至简”:只要数据足够多,模型就可以非常简洁。大概思路是:
图像和文本分别使用encoder编码为embedding,图像可使用 ResNet,文本可使用 Transformer 假如每个Batch中样本量为N,图像embedding和文本embedding两两做内积则可以得到一个(N,N)维度的矩阵,其中第i行第j列表示对应图像和文本的相似度 模型的目标就是使对角线的相似度最大,而非对角线相似度为0,也是借鉴了对比学习的思路
文字描述其实隐晦,远不如代码直观,因此这里贴出代码如下。

Language Guidance
了解了CLIP如何定义图像-文本的相似度,那么定义Language Guidance的 也就比较容易明白了,具体如下:
其中, 为用于引导的文本, 表示文本encoder。 为图像, 表示图像encoder。因此,CLIP中图像encoder必须要使用噪声图像finetune。其效果如下

Image Guidance
Image Guidance的 定义如下:
其中,定义 为用于引导的无噪声图像, 为 生成的加噪图像。同样的,CLIP中图像encoder必须要使用噪声图像finetune。其效果如下

Classifier-Free Diffusion Guidance
上文的Classifier-Guide采样方式,需要在采样阶段准备好额外的分类器,因此DDPM的原作者又提出一种Classifier-Free-Guide 的方式。假如无引导的Diffusion Model为 ,那么带分类信息引导的可以写为
由于
其中, 表示真实分布。因此,采样时的 可以被写作
接下来就是如何训练出 。这两者在Diffusion Model会共用模型,并将带标记的样本与无标记的样本混合一起训练,对于无标记样本则将 用于区分即可。
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
至此,Diffusion Models主要的技术都已经储备完毕,OpenAI则借助上述各种技术,带着自己的“钞能力”和丰富的样本及算力,训练出GLIDE模型成为当时的SOTA。由于其自身没有太多创新,这里不再赘述,只是贴出几张效果图作为欣赏。

尾巴
曾经AlphaGo横空出世之时,各种关于AI取代人类真真假假新闻大肆传播。为了安抚群众的情绪,有一种论调是:AI善于做确定性的或推理相关的工作,而人类则善于创造,且创造类工作无法被AI所取代。随着图像生成技术的日渐成熟,AI创作,甚至“AI艺术品”的时代也迟早会到来,上述的观点现在看起来已经有失偏颇。接下来,人类的精英们,可能还要再想想如何在未来社会,让人类与AI协同工作,同时划江而治。
