




背景
在效果广告场景,oCPX(智能调价)是业界目前最主流的出价方式。oCPX出价基础公式如下
其中,表示广告主的转化出价(比如为一次“新下单”愿意付多少钱),表示广告被点击后的预估转化概率,是调价因子。可以看到,的准确值在出价阶段扮演中非常重要的角色,因此所有从业者都铆着劲儿要把做准。但是预估准很困难,从数据的量和质两个方面来说的话:
量少:转化一般都是指注册、下单、付费等等行为,这种用户成本较高的行为天然就是稀疏的。为了提升样本量,一般就只好拉长样本时间窗口;但是对于新广告,只有近期的数据,甚至只有不到1天的转化数据 质低:这里主要指的就是延迟转化(Delayed Feedback)引发的label有偏。举例来说,某用户点击广告下载了XX手游,自律的他准备周末才注册游玩;或者,某用户点击广告把商品加入购物车,但是准备N天以后统一下单等等。这会导致,如果你用昨天的点击转化数据来训练模型,很可能其中有一些label=0样本,再过几天label=1了,让你原地爆炸
可以看出,1和2对较近期数据的要求是截然相反的:
从量少的角度,尤其是新广告这种无历史数据的情况,当然是用越实时的数据越好 从质低的角度,尤其是链路较深的转化行为,实时数据的label大概率是不准确的,必须要等待一段时间直到label可信
这就引出了本文介绍的主题:如何通过模型来缓解样本延迟转化(Delayed Feedback)带来的影响。需要提醒的是,以下介绍的方案都在基于Online Learning流程来表述的,别跟Batch Learning流程混淆否则容易疑惑。
方案概述
从模型层面缓解 Delayed Feedback 问题基本可以归为两类手段:
将Delayed Feedback看做FN(False Negative)问题,通过缩小可观测样本(包含FN样本)与真实样本(上帝全知视角)分布差异,从而预测真实,这类手段有如下一些方法: PU(Positive-Unlabeled) Learning:与常见的通过正负样本来学习分类器不同,PU Learning通过正样本(Positive)与无标记样本(Unlabeled)来学习分类器,一般用于获取label代价较高的场景。在 Delayed Feedback 场景,label=0的样本中包含正样本与负样本,因此统一视为无标记样本 Importance Sampling:Importance Sampling是一种通过在A分布样本(可观测样本)进行采样,预估B分布样本(真实样本)上统计量的手段 延迟转化问题顾名思义,本质蕴含着两个问题:是否延迟、是否转化,因此天然可以作为一个多目标问题建模。而具体如何拆解这两个目标,下文列举两个有代表性的方案: 将延迟转化问题拆解为“是否转化,第几天转化”两个目标建模,代表论文为Criteo的“Modeling Delayed Feedback in Display Advertising” 将延迟转化问题拆解为“第1天是否转化,...,第N天是否转化”这样几个问题多目标建模,代表论文为Google的“Handling many conversions per click in modeling delayed feedback”
False Negative类解决方案
这里的两种方案都来自Twitter的文章“Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction”。为了方便下文论述,这里先给出无延迟转化场景的标准LogLoss公式如下
其中表示每次请求相关的样本特征,表示label,表示拟合函数。
PU Learning
假如一个样本可以被描述为,其中表示样本特征,表示可观察到的label(即目前是否转化),表示无法观察到的真实label(即最终是否转化)。如上文所说,PU Learning依赖正样本与无标记样本。在延迟转化场景,即正样本,即无标记样本
使用PU Learning有一个假设,即的样本是否被观察到的概率是完全随机的,即
事实上这个假设在 延迟转化 场景是不合理的,以玩游戏为例,素来有周中屯游戏周末玩,白天屯游戏晚上玩的现象。因为这里只贴出比较有意思的结论,具体推导过程则不再赘述,读者可参考原文。基于 PU Learning,Loss应该被修改为
由于采用的是Online Learning的方式,一条会被拆分成两条记录:(点击记录)和(转化记录),当我们把这两条记录带入会发现,,非常有意思。
Importance Sampling
Importance Sampling 是一种Monte Carlo采样策略,详解介绍可以参考知乎博文,比如这篇文章。在机器学习中,比较耳熟能详的是在Reinforcement Learning中部分Off-Policy场景,通过Importance Sampling来缓解Behavior Policy和 Target Policy分布的差异。
在延迟转化场景,假如样本的真实分布为,那么Cross Entropy如下
在Online Learning场景,一次转化行为由两条样本构成:首先是点击未转化样本,随后是一次转化样本,我们将这个能观察到的样本分布记为,于是延迟转化问题就可以转化为:如何通过可观察分布来近似不可观察分布。
又由于有如下假设(假设都还算比较合理):
所有样本都有一条label=0(点击未转化)的样本,即 观察到的转化样本分布能够代表真实转化样本分布,
方案1:Fake Negative Calibration
根据上面假设和公式(推导省略),可以得到
因此,就可以直接根据观测样本预估,并通过此公式进行校准,进而得到。
方案2:Fake Negative Weighted
根据上面假设和公式(推导省略),带入原始LogLoss则有
其中,未知,直接用替代即可。
多目标类解决方案
如上文所说,延迟转化本质蕴含着两个问题:是否延迟、是否转化,因此可以作为一个多目标问题建模。得益于DNN对多目标建模的便利,且多目标理解成本比上面“False Negative类解决方案”更低,因此也涌现不少这类解决方案,主要区别只是在于拆解方式。下面仅以两种较典型方案为例说明。
Delayed Feedback Models(DFM)
DFM是Criteo在“Modeling Delayed Feedback in Display Advertising”所提出,是延迟转化认知最普遍的方案之一。DFM其实是改良版本的 PU Learning 模型,PU Learning 最大的问题在于假设“对于转化样本,是否能够被正确观察到是完全随机的”是很不合理的,除了上文提到的反例,还有一种反例:刚发生完点击的样本可观察的转化概率,比发生一段时间后的可观察到的转化概率,是更低的,因为用户从点击到转化行为链路本身就需要时间。
为了解决这个问题,DFM除了对Positive-Unlabeled 样本进行建模外,还有另一个模型负责对“点击转化间隔时长”建模。为了方便描述,我们做如下定义:
,表示用户目前是否转化 ,表示用户最终是否发生转化 表示点击与转化之间的间隔(如果,则无意义) 表示目前具体点击行为,已经过去的时间
于是有
本文也有假设,当给定,的联合分布与离点击过去时间无关。这个假设是非常合理的,其具体表达式如下
接下来,本文就要学习两个模型:转化率模型,点击与转化间隔时长模型。在预测阶段,则仅使用即可。
对于转化率模型,文中使用的是逻辑回归(当然此处使用任何模型都是可以的),转化率模型设置如下
对于点击与转化间隔时长模型,文中用指数分布来拟合,即
接下来又是推导过程,这里继续省略,最终我们基于原始LogLoss可以推导出
在此文章思路的基础上,后续还有一些作者进行了一些优化,这里列出部分文章供参考:
《A Nonparametric Delayed Feedback Model for Conversion Rate Prediction 》 《Capturing Delayed Feedback in Conversion Rate Prediction via Elapsed-Time Sampling》
Handling many conversions per click in modeling delayed feedback
本文来源于Google文章“Handling many conversions per click in modeling delayed feedback”,其不止能够对延迟转化建模,同时也能解决单次点击带来多次转化的问题。
我们先初步描述问题:模型是基于时间内的样本顺序训练的,样本特征为,样本label为。比较特殊的是,是一个序列,表示在时间上的label序列。其中,归因的时间窗口为,为请求发生的时间,表示最大归因窗口(如30天,即超过此时间则不再将行为归因到该样本)。模型的目的是预估,使与的分布一致,其中为模型参数。
如果简单按照上面所说的对每个时间段 联合建模,因为每个时间段的样本量有限,且随着时间段划分越细,数据也越稀疏,不利于模型训练。因此文中实际上,是对的时间段进行联合建模。需要注意的是,在的时刻,的label是可以用于训练的,而计算loss时应当使用的label数据,如下图所示:
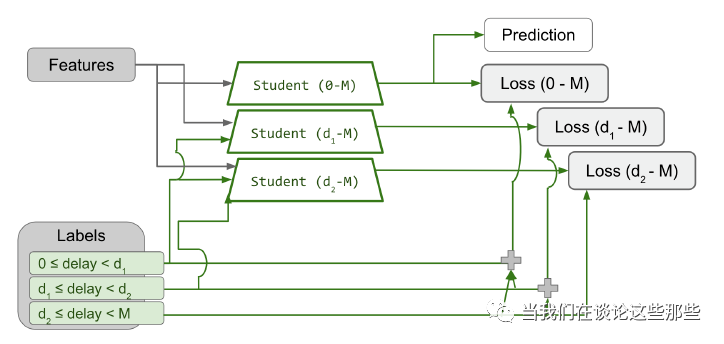
尾巴
延迟转化问题,是效果广告场景典型的样本缺陷之一(站在建模的角度),本文列举了常见的一些缓解延迟转化对模型转化率预估偏差影响的方案。这些方案虽然都不算高大上,甚至很多偏统计学而非机器学习,但是比目前很多“没问题,就创造问题解决”都来得踏实和接地气。看着业界建模“花式内卷”,希望多再多些这种卷出水平、卷出价值的工作:)
