




引言
Multi-Task Learning(MTL)即多任务学习,在一些领域也被称为多目标学习。MTL与常规单任务模型的区别在于,MTL仅使用一个模型就可以处理多个任务。比如在手机助手唤醒这个高频场景,一般需要两个模型,A模型用于检测是否是手机用户的语音,避免环境音或者自身回声干扰;B模型用于检测用户语音是否包含唤醒词(如:Hey Siri、小爱同学 等)。借助MTL,则可以在一个M模型中同时完成上述两个任务,而事实上Iphone中Siri也正是这么做的,详见Apple论文“Multi-Task Learning for Voice Trigger Detection”。
MTL作为一种建模方式,既包含模型架构设计方面,也包含模型训练过程方面。模型架构设计容易理解,即模型需要支持多种任务的输入输出,需要使多任务之间信息更有效率地共享等;而在模型训练过程方面,需要包含多任务的数据集划分,损失函数的定义,训练流程等方面。从这个角度看,目前中文社区中大部分MTL介绍的文章是“有偏”的,对于部分论文或者技巧的解析深度有余,而对MTL的系统介绍远远不足。以至于在推荐系统领域,部分同学会误解MTL就是MMoE、ESMM。
因此,本文旨在较为系统的介绍MTL的基础,使读者能相对“无偏”了解这个领域,以便正确地借鉴其他论文中的知识和技巧。限于本人知识和时间有限,文章如果有疏漏或者错误,欢迎指正 :)
Multi-Task Learning简介
很难想象,MTL的神经网络是早在1993年已经提出的概念,来自于Caruana的“Multitask Learning: A Knowledge-Based Source of Inductive Bias”。其单任务模型(Fig1)和MTL模型结构(Fig2)如下,对于MTL模型,神经网络有多个输出的节点,每个节点对应一个任务,可以说是非常符合直觉的。
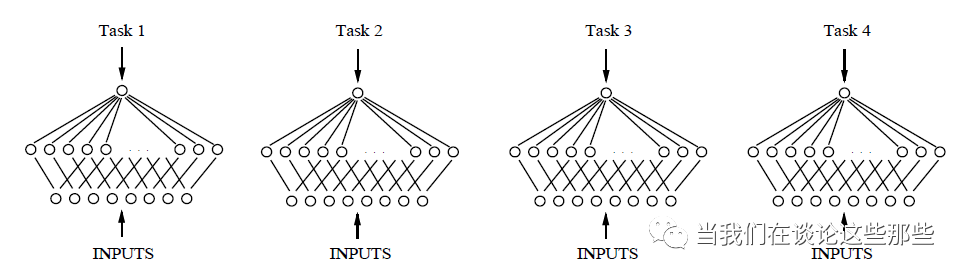
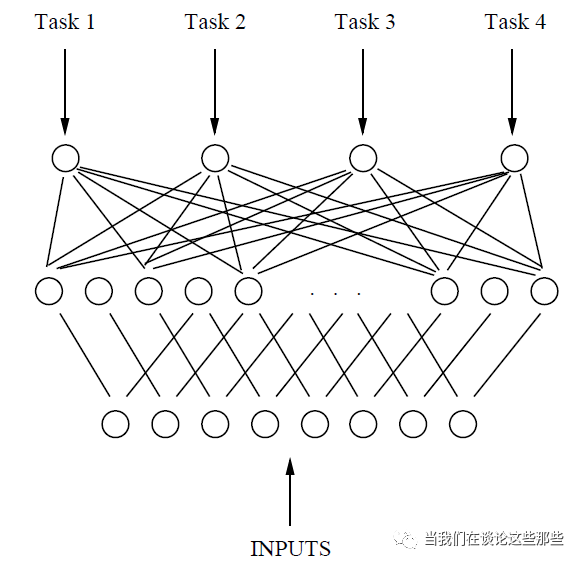
那么就先以这个最简单的MTL模型,谈谈除了模型比较Fancy之外,出于哪些更实际的理由促使大家使用MTL而多个非单任务模型呢?从实用角度来说,有以下几点:
第一,MTL可以在模型效果不下降的情况下提升多任务预测效率。由于可以共享一部分网络结构,MTL的总网络参数量相较于N个单任务网络参数量总和显著降低,这意味着在实时多任务预测场景下MTL模型效率会更高;同时对某个任务而言,MTL模型参数(共享参数+任务独立参数)与单任务模型参数量一样,所以其模型理论表达能力并没有降低。
第二,MTL对于相关的多任务,可以提升小样本任务训练效果。得益于MTL的参数共享机制,共享参数可以通过样本充足的任务得到充分训练,减少小样本任务单独训练不充分,容易过拟合的问题。
第三,MTL通过引入Inductive Bias,可以提升所有相关任务的鲁棒性。在机器学习中,无时无刻都在对问题做一些假设(或者叫先验、约束),这些就被称为 Inductive Bias,如 L1正则是模型稀疏性的假设、CNN 是特征局部性的假设、RNN是样本时序性的假设……对于MTL,Inductive Bias则是不同任务之间效果的约束,如果这些约束合理,那么显然会让所有任务都更不容易受噪声样本影响,从而提升模型的鲁棒性。
上面几点优势本质上都是因为“共享参数”带来的。因此,如果不同任务之间差异巨大,根本没什么需要共享的,“共享参数”机制就会使Inductive Bias从约束变成噪声,拉低每一个任务的效果。
有时候即使没有同时训练多个任务的需求,但是出于对上述优势的考虑,会额外引入一些辅助任务构造成MTL的模型,辅助将主任务训练的更加鲁棒。
Multi-Task Learning与其他学习方式
上面对MTL进行了简单介绍,其中关于“参数共享”部分很容易让人想起迁移学习,而多输出节点部分则很像多分类。关于他们之间的关系,Wasi Ahmad的《Multi-Task Machine Learning》中比较合理地归纳,如下图。
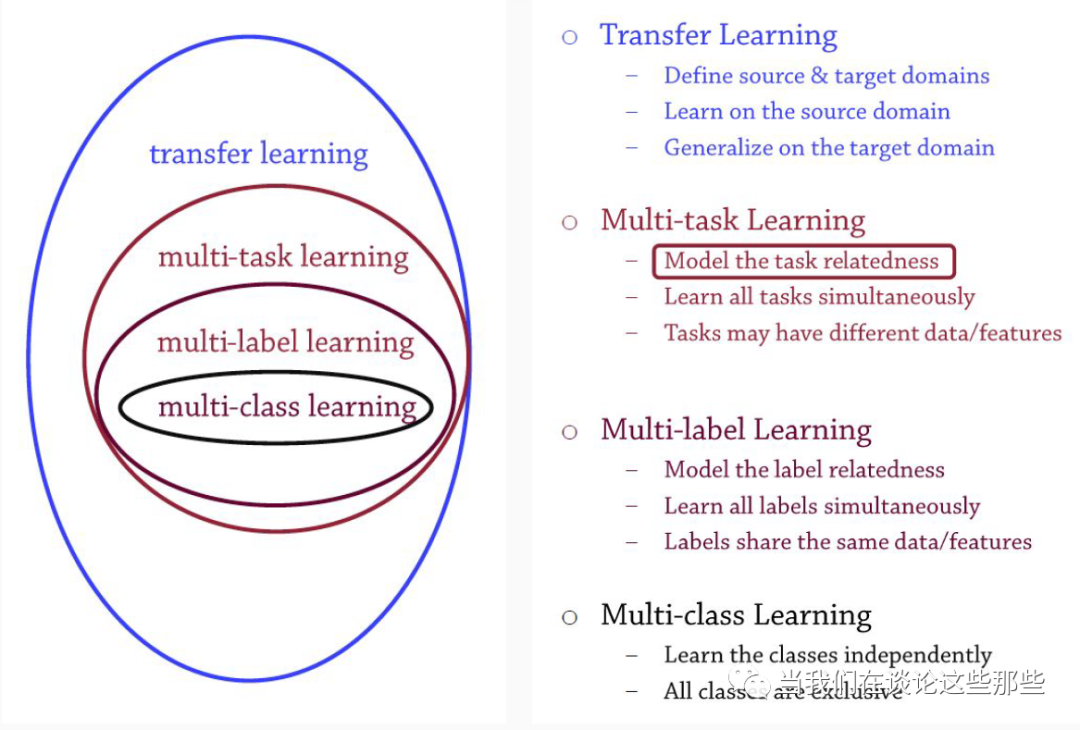
Fig3. MTL与其他学习的关系
迁移学习(Transfer Learning):将A领域的知识应用到B领域中,从而缓解B领域样本不足的问题。在图像领域,最常见的迁移学习之一就是复用Pretrain的模型用于图像特征提取,曾经红极一时的VGG16、Inception-v3等都是论文常客。在NLP领域,当红的Bert模型+Finetune的训练形式也已经是标配。
多任务学习(Multi-Task Learning):同时对多个任务建模,通过对多个任务之间的参数相关性添加约束(如“参数共享”)将所有任务联系起来。在推荐系统领域,Google的MMoE和阿里巴巴的ESMM是较为人熟知的MTL模型。
多标签学习(Multi-Label Learning):即多标签多分类学习,对一个样本同时预测多个标签。如对每个人兴趣爱好的预测,总兴趣标签空间可以包含动漫、音乐、摄影、交友等等,某个人的兴趣为总空间的子集,训练和预测的目标即为这个子集所表示成的Multi Hot向量。
多类别学习(Multi-Class Learning):即单标签多分类学习,对一个样本同时预测多个分类的概率。如语言分类任务中,需要预测某个文本是汉语、英语、阿拉伯语等等,训练和预测目标为这种语言所表示成的One Hot 向量。
接下来,我们开始具体介绍MTL。
Multi-Task Learning定义
首先,需要对“任务”这个概念有个明确的定义(这里参考亚利桑那大学博士论文《MULTI-TASK AND TRANSFER LEARNING IN LOW-RESOURCE SPEECH RECOGNITION》),一个任务定义如下:
源数据:X 表示某领域的样本集合
目标数据:Y 表示某领域的目标集合
映射:f: X → Y,表示从源到目标的转换关系
对于一个MTL模型,能够同时对多个上述任务进行建模。模型中部分参数是所有任务共享的,下面称为“共享参数”;另外一部分参数是每个任务独享的,下面称为“独立参数”。那么理想情况下,我们希望“共享参数”在所有样本计算Loss后更新,而“独立参数”只在对应任务样本计算Loss后才更新,这就达到了一起训练的目的。
有了上面的定义,就可以对MTL的主要形式做出预判,大概会有以下三种形式。
第一,给定一个源数据集(X),以及多个目标数据集(Y1,Y2,...Yn),MTL将X分别映射到每个目标数据集中,如图Fig4(a)。这也是最普遍的MTL形式,下面把这种形式称为Single Input Multi Output(SIMO)。
第二,给定多个源数据集(X1,X2...Xn),以及多个目标数据集(Y1,Y2,...Yn),MTL分别将Xi映射到Yi,如图Fig4(c)。这种形式不如第一种常见,却是大部分场景下,最容易将单任务快速迁移到MTL进行尝试的方式。下面把这种形式称为Multi Input Multi Output(MIMO)。
第三,给定多个源数据集(X1,X2...Xn),以及一个目标数据集(Y),MTL分别将Xi映射到目标Y,如图Fig4(b)。如果这里Y被定义为所有源数据集的目标的超集,这个MTL任务就退化成上面提到的Multi-Label Learning任务。这种形式一般不被当成是MTL,所以谈论MTL时最不常见。下面把这种形式称为Multi Input Single Output(MISO)。
需要强调的是,这里所说的“MTL的形式”,指的是如何组合不同任务的数据,而不是仅仅指网络结构。举个例子,对于Multi Input Multi Output形式的MTL模型,每个任务的源数据集不同,但如果Multi Input的特征完全一致,大可以共享特征解析部分的网络参数。
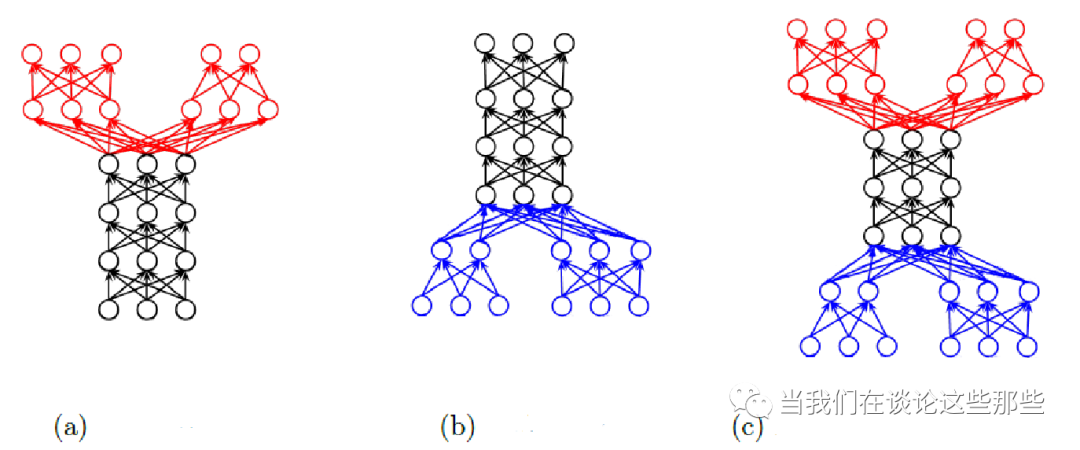
Fig4. MTL的主要形式
下面,针对Single Input Multi Output、Multi Input Multi Output 两种常见的MTL形式进行具体介绍。其中主要包含两点:模型结构,模型训练(Loss定义,训练步骤等)。这里仅会以部分领域较为知名的基础模型为例,意在直观的理解上述两点,对更深入细节有兴趣的同学可以阅读给出的参考文献。
Single Input Multi Output 模型
SIMO形式的MTL模型比较常见,这里举计算机视觉、推荐系统中的两个例子。
计算机视觉
在计算机视觉领域,2014年香港中文大学的“Facial Landmark Detection by Deep Multi-task Learning”是一篇将多任务用于人脸关键点检测的文章,提出了TCDCN模型。人脸关键点包括人脸轮廓、眼睛、眉毛、嘴唇以及鼻子等等。
其模型结构如Fig6所示,可以看出有多个输出:一个主任务Landmark Detection,和其他辅助任务。辅助任务用于帮助主任务学习CNN的网络参数,文中的辅助任务包括:性别、是否带眼镜、是否微笑、脸部的姿势等。为了直观的说明每个任务,Fig5展示了训练样本,包含图像即每个任务的Label信息。
TCDCN模型的损失函数也非常符合直觉,如Fig7所示。其中第一项就是Landmark Detection的损失函数;而第二项就是辅助任务的损失函数,第二项λ是辅助任务Loss的权重,用于调节辅助任务的重要性。
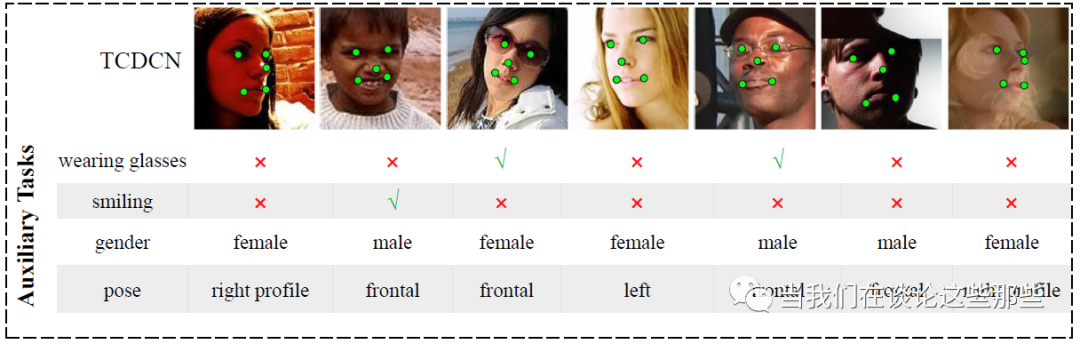
Fig5. TCDCN训练样本
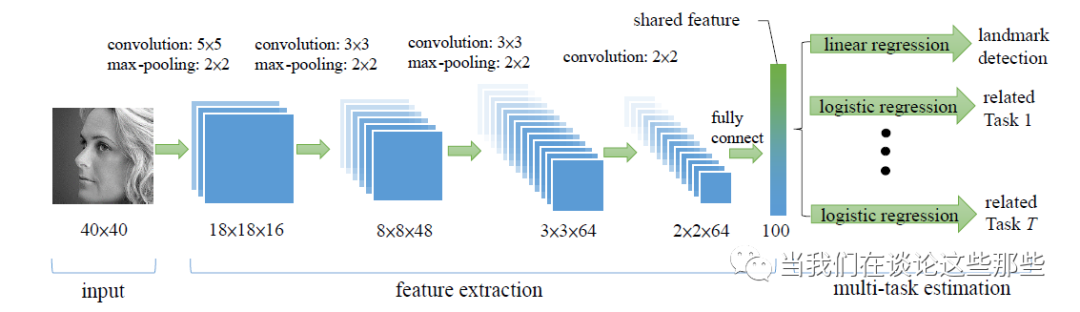
Fig6. TCDCN模型
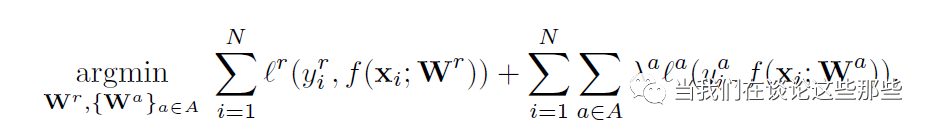
Fig7. TCDCN模型损失函数
推荐系统
在推荐系统领域,2018年来自阿里巴巴的“Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate”是一篇将多任务用于点击率、转化率预估的文章,提出的模型称为ESMM。这里稍微解释下各个指标的含义:
商品点击率(CTR,pCTR)= 点击数/曝光数,衡量用户看到一个链接后点击的概率。
商品转化率(CVR,pCVR)= 转化数/点击数,衡量用户点击商品详情后,下单购买的概率。
商品点击转化率(CTCVR,pCTCVR)= 点击率*转化率。
ESMM模型结构如Fig8所示,包含一个主任务CVR预估,以及辅助任务CTCVR预估。CTCVR任务同样是用于帮助CVR把Eembedding Lookup Table学习的更好,避免CVR预估由于样本偏少导致容易过拟合泛化性差等问题。
ESMM的损失函数如Fig9所示,这里主任务CVR预估并没有单独计算Loss。可以看出最终损失是CTR、CTCVR的损失之和,主任务CVR体现在CTCVR这一项中,这避免了部分用户没有点击导致无法计算CVR的问题,是非常优秀的转换。
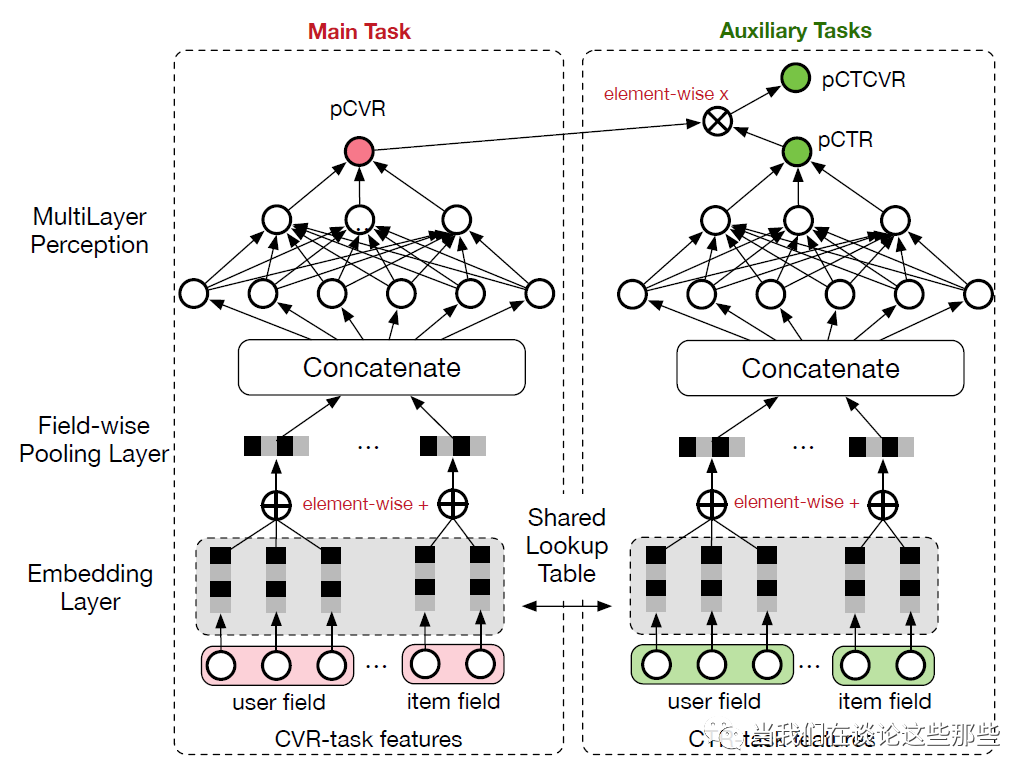
Fig8. ESMM模型结构
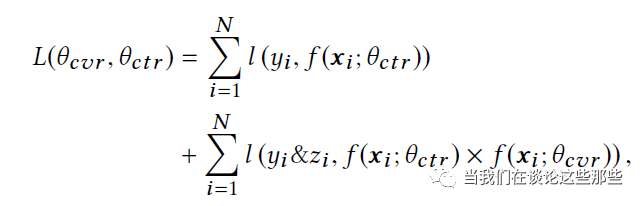
Fig9. ESMM损失函数
模型训练
从上面可以看出,Single Input Multi Output 模型的Loss一般都会有多项,每一项对应一个任务(或者该任务的某种转换任务)。所以每个batch训练比较简单,直接更新整个网络的参数即可。
但是Loss相加也会带来一个问题,不同任务的目标不同,可能是回归也可能是分类,那Loss的尺度就不一样。如Fig7中的λ,就是用于调节不同任务的Loss大小,避免某个任务Loss太大,其他任务无法参与训练。这就引入一个很麻烦的问题,λ要怎么调节才能平衡每个任务呢?
最简单当然是根据专家知识调参,也有一些工作提供了自动调节Loss尺度的方案,如“Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics”,这里就不再展开。
Multi Input Multi Output 模型
MIMO形式的MTL模型不那么常见(可能是因为看起来没啥技术含量不好灌水?),这里仅举一个相对知名的自然语言处理的例子。(如果有同学知道更多MIMO的例子,欢迎留言区补充,最好有文章标题,方便其他同学学习)
自然语言处理
在自然语言处理领域,2019年来自微软的“Multi-Task Deep Neural Networks for Natural Language Understanding”是一篇将MTL用于学习Text Representation的文章,提出的模型称为MTDNN。MTDNN在10个NLP任务中刷新了记录,并在文章中多次强调其取得了比BERT更好的Representation结果(这种高强度的CUE总让人有一种相爱相杀的感觉哈哈)。
MTDNN的模型结构如Fig10所示。虽然涉及较多领域知识,但其实图中Shared Layers的具体含义不明白细节,也能看出整体结构就类似于Fig2中最原始的MTL模型。MTDNN不是单一的主任务,而是所有任务一样重要,其任务包括:句子情感分类、文本相似性回归、文本相似性分类、文本相似性排序等等。
MTDNN的训练方式也很直观,如Fig11所示。其中包含两个步骤:
第一步,Pretrain Encoder Layers。这一步类似BERT,利用无监督任务将Encoder Layers的海量参数学好,这里的无监督任务包含Masked Language Modeling 和Next Sentence Prediction。这一步可以理解成学习模型的“共享参数”。
第二步,MTL学习每个任务。这一步就是利用多任务的标签来精调模型(“共享参数”和“独立参数”都会参与训练),做法也很简单,就是每个batch抽取一个任务的样本,然后根据该任务的损失函数进行模型参数更新。由于不同任务的损失函数不耦合,就不需要考虑Loss尺度的问题。
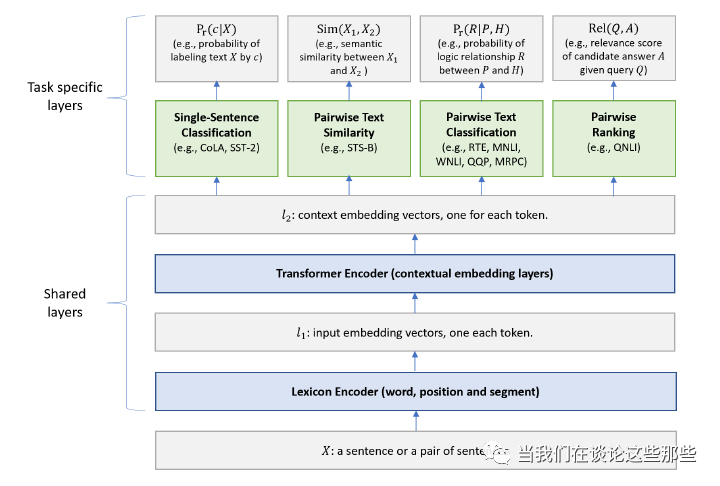
Fig10. MTDNN模型结构

Fig11. MTDNN模型训练
Multi-Task Learning 参数共享形式
Hard Soft Parameter Sharing
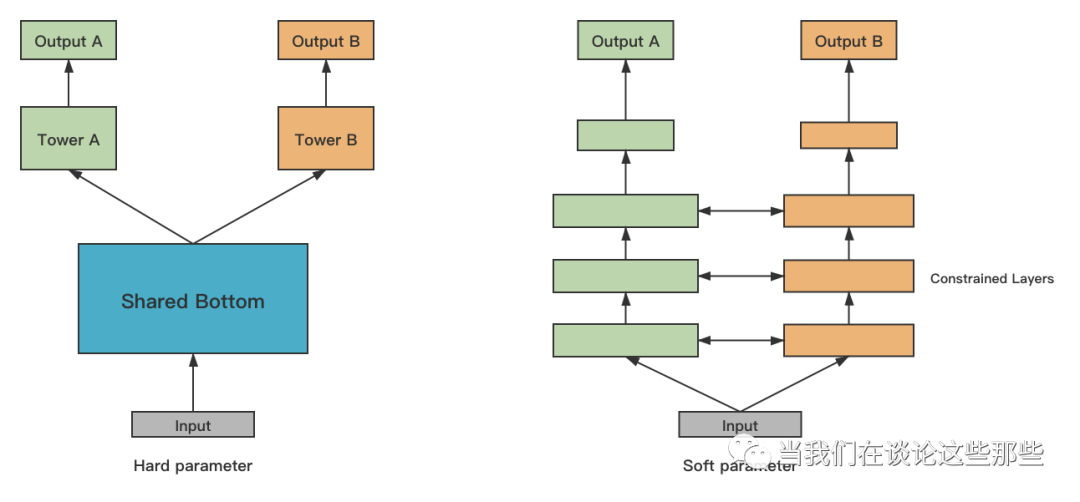
Fig12. MTL参数共享形式
MTL模型中参数共享的方式一般说来有两种,分别是Hard Parameter Sharing和Soft Parameter Sharing。
Hard Parameter Sharing即Fig12(左),表示对多任务直接共享部分神经网络参数,是最主流的参数共享形式。上面提到的例子也基本都是这种形式,适用于多任务之间相关性比较强的场景。
Soft Parameter Sharing即Fig12(右),表示每个任务分别有自己的神经网络参数,但是会对多任务的网络参数之间加约束,使参数彼此相似。这种方式实际中不太常见,可用于多任务之间相关性比较弱的场景。约束指标如L2 Norm(见“Low Resource Dependency Parsing: Cross-lingual Parameter Sharing in a Neural Network Parser”)、Trace Norm(见“Trace Norm Regularised Deep Multi-Task Learning”)。
Mixture of Experts
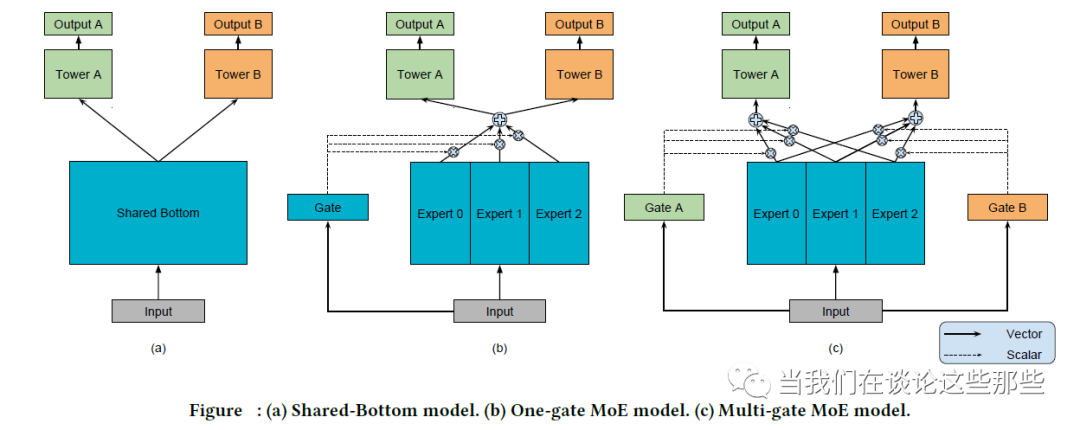
Fig13. MTL Mixture of Experts 形式
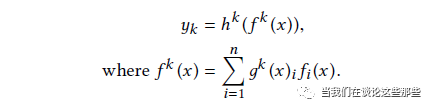
Fig14. MMoE模型公式
上面提到Soft Parameter Sharing可用于多任务之间相关性较较弱的场景,但是如果多任务之间相关性非常低,一般也不会考虑使用MTL。更常见的是,多任务之前有较为相关的部分,也有相互独立的部分,直接Hard Parameter Sharing也不太合适,Mixture of Experts模型就适合这种场景。
Google在2018年“Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts”文章提出Multi-Mixture-of-Experts(MMoE)模型,是对Geoffrey Hinton 提出的Mixture-of-Experts(MoE、One-gate MoE)的一种改进,而它们都是一种特殊的Hard Parameter Sharing模型。这三种模型结构如Fig13,其中(a)Hard Parameter Sharing模型,(b)MoE模型,(c)MMoE模型。
MoE模型将“共享参数”划分为N个Expert子网络,而Gate网络负责输出N个Expert子网络的权重,最终结果是Expert子网络与Gate的加权和。思想上其实类似于后来的Attenton。
MMoE则是在MoE的基础上,对每一个任务有独自的Gate网络负责输出权重,使不同的任务能更多样化地使用Expert网络。其具体公式如Fig14,也比较好理解,就不再赘述。
尾巴
本文旨在较为全面的介绍MTL的基础知识,包括MTL与其他机器学习算法的关系,MTL的主要建模形式、训练方式,以及关于参数共享的扩展形式。虽然对每个话题都只进行了基本介绍,文章也已经快超6000字,所以文中对每一项更深入的话题没有进一步扩展,只留了一些参考文献供有兴趣的同学自行学习。
有其他疑问的同学欢迎关注公众号“”私信交流,或者评论区留言交流,我会在精力范围内尽量回复。
最后祝大家Happy牛Year!
Reference
https://ruder.io/multi-task/index.html#hardparametersharing
其他参考文献已经在文中对应部分给出。

欢迎关注公众号~
