




在今天的文章中,我们将寻找关于什么是Oracle大数据的答案?
什么是大数据?—作为概念
“这是一个以经济和可扩展的方式使随时间收集的大量数据可用和有意义的概念,而关系数据库技术还不够”。
数据的重要性和价值与日俱增。数据重要性和价值增加的原因是数据数量和种类的增加。
当我们审视它时,大数据概念的根源可以追溯到2004年。换句话说,自2004年以来,世界最大的科技巨头一直在投资和使用这个概念。
大数据是一个概念,包括开源软件。这些软件的核心包括一系列我们称之为Hadoop的软件组。我们可以列出以下一些软件:
Hadoop Core
HDFS (Hadoop Distributed File System)
Hive (Data Warehouse)
HBase
ZooKeeper
Oozie
Mahout
Sqoop
Cloudera Manager
大数据的概念不限于上述软件组件。就你所能想象的,大数据的概念实际上是有限的。我称之为“大数据=想象”,我将在本文的其余部分尝试解释为什么是“想象”。
大数据概念与4V
让我们谈谈如何暂时离开非关系环境,将4V和非关系环境与关系环境(RDBMS)结合起来,这样我们就可以清楚地记住大数据的概念。
体积:
也许形成大数据概念的最重要原因是我们拥有的数据量每天都在以对数增长。随着数据量的大幅增加,公司的IT成本自然会增加。
有必要降低不断上升的It成本,并调整存储和管理所有这些数据的环境。
速度:
考虑到除了数据量不断增加之外,这些数据流入系统的速度非常快,必须得到满足。将此类数据快速加载到关系数据库中既繁琐又昂贵。
因此,除了数据量之外,数据流向系统的速度非常快,这是解释大数据概念和用途的另一个V。
品种:
社交媒体、传感器数据、CRM文件、文档、图像、视频等。想象一下你能想到的所有数据、来源和数据类型。
将它们全部存储在关系数据库中是不可能的,而且成本也不高,即使是在我们知道的文件系统上。
如果数据的多样性增加了,我们想要处理、分析和存储所有这些数据,那么大数据的概念就是完美的选择。
值:
当其他3个V组合在一起时,形成另一个V。这就是价值。进入系统的大量、各种且流动非常快的数据也必须具有价值。否则,产生的成本就变成了获得的价值。
为了避免这种情况发生,我们需要理解我们拥有的数据,增加价值并进行分析。因此,大数据概念的第四个V变成了价值。
Oracle开发了一个工程化系统,用于存储、存储、分析、增值和报告数据和数据类型,涵盖了我上面提到的4个Vs。我们将其命名为“Oracle大数据设备”。
在进入大数据设备之前,让我们先谈谈Hadoop和集群结构以及当前的方法。
Hadoop集群与传统架构
如你所知,Oracle开发工程系统,我们称之为工程系统,与传统架构不同。
这些系统是由Oracle Exadata数据库机器开发的。
其目的是将软件和硬件结合在一起,并消除我们已知的传统体系结构中的一些问题,不幸的是,这些问题现在已经习惯了。
例如,如果在无法从单个制造商获得支持的情况下出现问题;硬件团队将问题分配给软件,软件分配给网络团队,网络团队再次分配给硬件。
因此,从硬件制造商A、软件制造商B、集群制造商C、网络组件制造商D等等。当经常出现问题时,很难获得解决方案和支持。
大数据机
Oracle大数据设备是一个完整的、集成的、经过测试和验证的Oracle解决方案,包括我们提到的所有软件和您需要的所有其他硬件。
大数据设备附带安装了Hadoop群集和Oracle Enterprise Linux。此产品上没有运行关系数据库。
Oracle数据库组件(如RAC、ASM)也不可用。相反,有一个Oracle NoSQL数据库可以存储和查询“键值”。
因此,在Oracle大数据设备上安装和运行的所有软件都是免费的。Oracle为您提供了使用Hadoop的环境,以及它可以立即执行的操作。
其设置基于天,而不是周。因此,使用Oracle Big Data Appliance,您将落后于我上面提到的过程,这一过程花费了数月时间,为您付出了艰辛的努力。您将获得Oracle的全面支持。

Oracle大数据设备的集成软件组件如下;
Oracle大数据设备的硬件组成如下;
Oracle大数据设备通过其自己的Infiniband(40 Gb/s)网络进行通信,通信速度至少是任何传统架构的4倍。它还可以与其他Oracle工程系统完全集成。
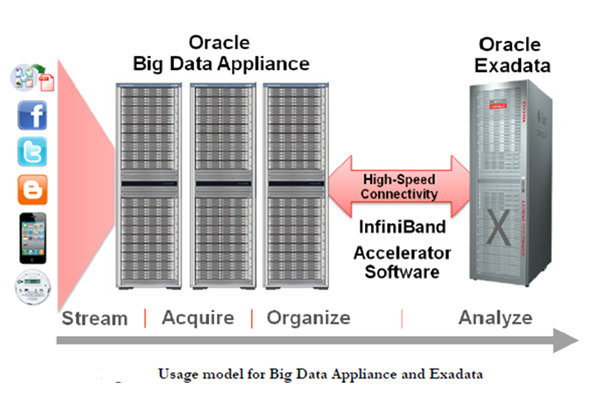
分别从左到右总结上述图像;
步骤1––数据流:这是来自多个源的不同类型数据流入系统的阶段。
在此阶段,系统的数据流已准备好并配置为上传到Oracle大数据设备。
步骤2––收集和组织:在Oracle Big Data Appliance中以高容量、多样性和速度记录和存储数据,从而实现HDFS。
默认情况下,HDFS执行“三重镜像”(将传入数据存储在3个副本中),并将其分发到已安装的Hadoop集群(总共18个节点)。
步骤3––分析和报告:在通过Java代码将数据传递到Oracle Big data Appliance上后,我们称之为“Map/Reduce”,并将其转换为可以上传到关系数据库的格式,
我们将数据传输到Oracle Exadata,我们通过Infiniband连接该数据,并将其包含在关系世界中。
在我文章的开头,我指出大数据受到你想象力的限制。
当您评估所有这些可能性时,您可以看到有许多领域可以使用大数据及其范围。
此外,您可以通过infiniband将八个大数据设备相互连接,而无需额外的交换机。
Oracle开发并准备使用的另一个软件是“Oracle大数据连接器”。
Oracle大数据连接器
这些软件组件的目的是方便地将数据从大数据设备提取到Oracle数据库。
为了从HDF中提取数据,从而从Hadoop集群提取到关系环境,您需要花费精力和时间。
同时,您需要在您的机构中拥有合格的人员或获得咨询服务。让我们谈谈这些连接器软件,它将充当大数据和Oracle数据库之间的桥梁,减少安装工作量和成本;
用于Hadoop的Oracle加载程序
用于Hadoop分布式文件系统(HDFS)的Oracle直接连接器
用于Hadoop的Oracle Data Integrator应用程序适配器
用于Hadoop的Oracle R连接器
用于Hadoop的Oracle加载程序
该软件是一种Map/Reduce工具,其目的是优化从Hadoop到Oracle数据库的数据传输。
Oracle Loader for Hadoop优化和修改数据,以便将其加载到可以加载到数据库中的格式。
这样做也有助于减少可能的CPU和I/O量。
用于Hadoop分布式文件系统(HDFS)的Oracle直接连接器
该软件的目的是提供从Oracle数据库快速访问HDFS介质的功能。
得益于直接连接器,我们可以随时从关系型环境查询到非关系型大数据环境。
我在这里谈论的是直接SQL访问,一种“外部表”。HDF上的数据可以查询或加载到关系数据库中。
用于Hadoop的Oracle Data Integrator应用程序适配器
它是将ODI工具与大数据相结合的软件。其目的是通过HDFS将数据传输到Oracle数据库。Hadoop实现需要对Java和Map/Reduce代码有深入的了解。
通过ODI连接器,可以编写映射/减少函数,并与图形界面一起使用。然后,开发的代码在Hadoop上运行,可以执行Map/Reduce操作。
用于Hadoop的Oracle R连接器
R连接器允许我们进行统计分析。
原文标题:What Is Oracle Big Data?
原文作者:Buğra PARLAYAN
原文链接:https://dbtut.com/index.php/2022/05/24/what-is-oracle-big-data
