




NULL基础知识
IS NULL或
IS NOT NULL判断,可以用函数转换为普通值。如 NVL 、NVL2 函数。
构造测试数据(MYSQL)
date && ./sysbench ./oltp_read_only.lua --mysql-db=sysbenchdb --mysql-host=172.23.152.229 --mysql-port=2883 --mysql-user=user01@obmysql01#obdemo --mysql-password=123456 --tables=1 --table_size=10000000 --report-interval=10 --threads=100 --db-driver=mysql --time=3600 --skip_trx=on --db-ps-mode=disable --create-secondary=off --mysql-ignore-errors=6002,6004,4012,2013,4016,1062 prepare && date
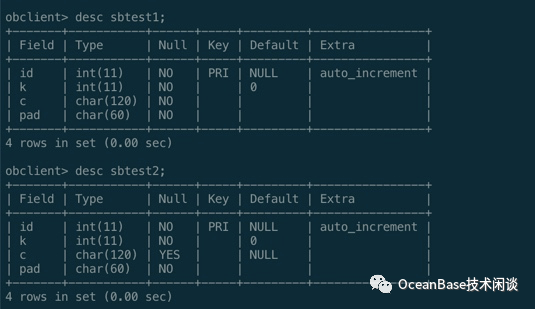
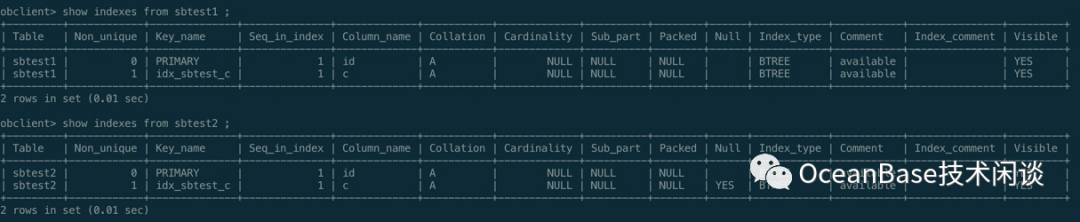
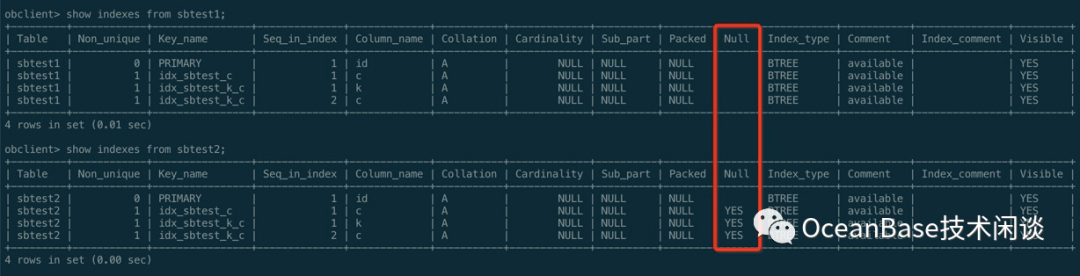
obclient -h127.1 -uuser01@obmysql01#obdemo -P2883 -p123456 -c -A sysbenchdbshow create table sbtest1;show indexes from sbtest1;
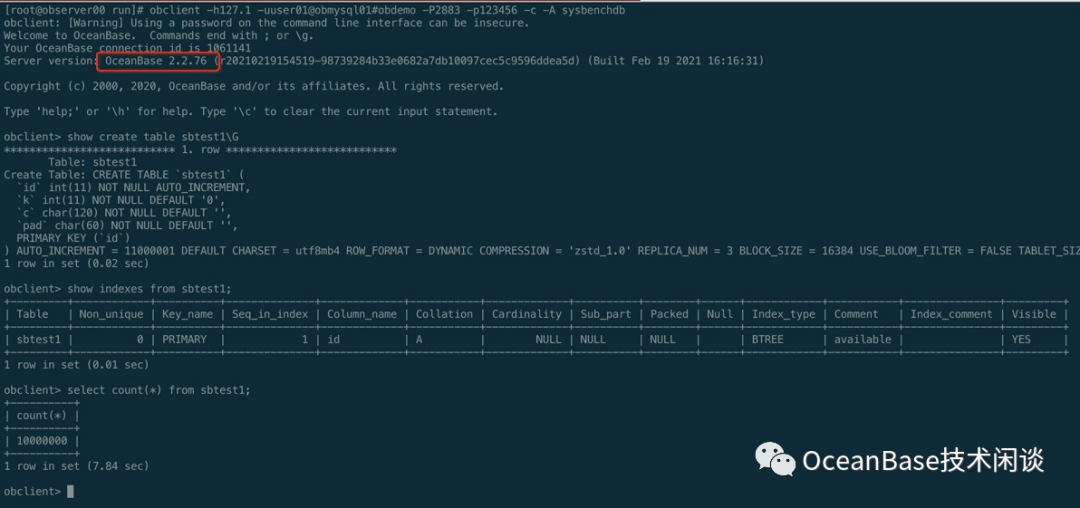
obclient -h127.1 -uuser01@obmysql01#obdemo -P2883 -p123456 -c -A sysbenchdbalter table sbtest2 modify column c char(120) null;update /*+ query_timeout(100000000) trx_idle_timeout(1000000000) trx_idle_timeout(1200000000) */ sbtest2 set c = null where mod(id, 10000) = 0; commit;show create table sbtest2\Gselect count(*) from sbtest2 where c is null;
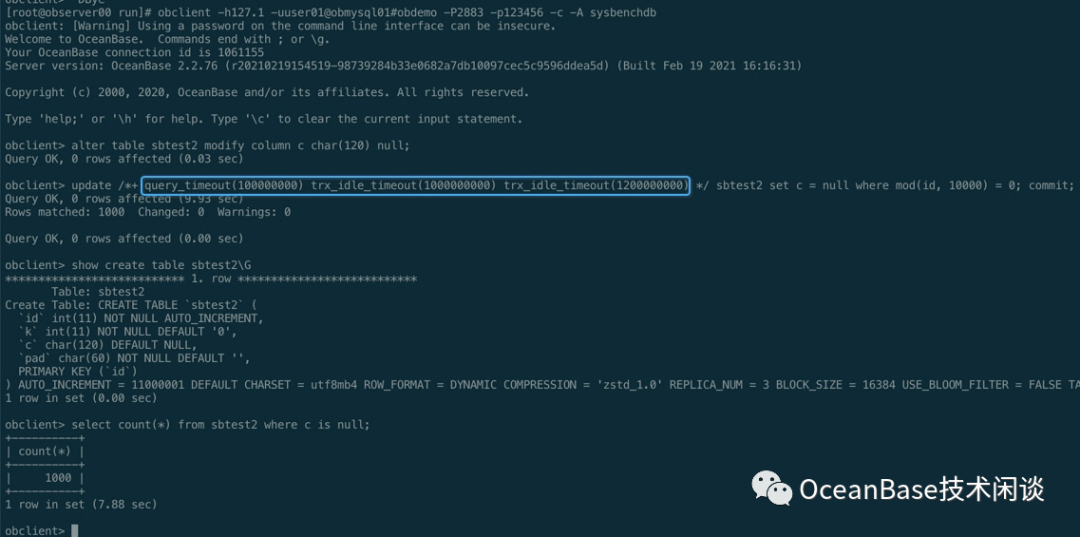
// 发起合并alter system major freeze;// 查看合并进度SELECT ZONE,svr_ip,major_version,ss_store_count,merged_ss_store_count,modified_ss_store_count,merge_start_time,merge_finish_time,merge_processFROM __all_virtual_partition_sstable_image_info;// 查看合并事件SELECT DATE_FORMAT(gmt_create, '%b%d %H:%i:%s') gmt_create_ , module, event, name1, value1, name2, value2, rs_svr_ipFROM __all_rootservice_event_historyWHERE 1 = 1 -- AND module IN ('server')-- AND module NOT IN ('leader_coordinator')ORDER BY gmt_create DESCLIMIT 10;
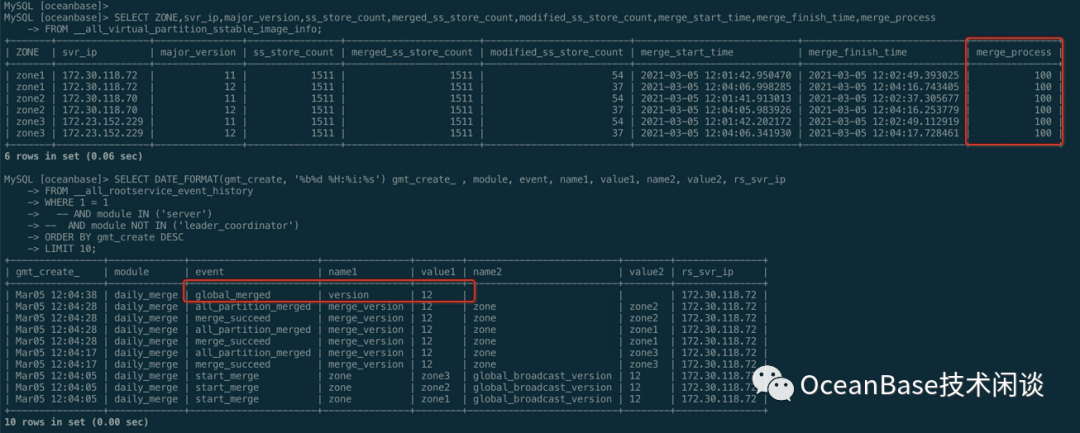

查看表的统计信息
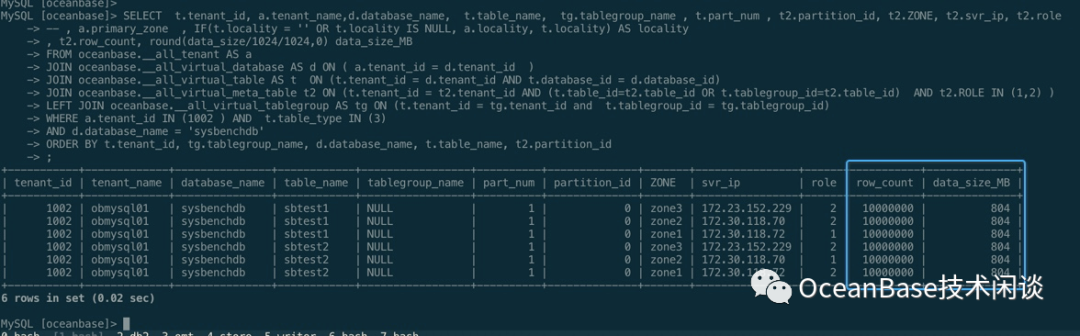
SELECT t.tenant_id, a.tenant_name,d.database_name, t.table_name, tg.tablegroup_name , t.part_num , t2.partition_id, t2.ZONE, t2.svr_ip, t2.role -- , a.primary_zone , IF(t.locality = '' OR t.locality IS NULL, a.locality, t.locality) AS locality , t2.row_count, round(data_size/1024/1024,0) data_size_MBFROM oceanbase.__all_tenant AS a JOIN oceanbase.__all_virtual_database AS d ON ( a.tenant_id = d.tenant_id ) JOIN oceanbase.__all_virtual_table AS t ON (t.tenant_id = d.tenant_id AND t.database_id = d.database_id) JOIN oceanbase.__all_virtual_meta_table t2 ON (t.tenant_id = t2.tenant_id AND (t.table_id=t2.table_id OR t.tablegroup_id=t2.table_id) AND t2.ROLE IN (1,2) ) LEFT JOIN oceanbase.__all_virtual_tablegroup AS tg ON (t.tenant_id = tg.tenant_id and t.tablegroup_id = tg.tablegroup_id) WHERE a.tenant_id IN (1002 ) AND t.table_type IN (3) AND d.database_name = 'sysbenchdb'ORDER BY t.tenant_id, tg.tablegroup_name, d.database_name, t.table_name, t2.partition_id;
测试单列索引跟NULL关系
idx_sbtest_c(c)create index idx_sbtest_c on sbtest1(c);create index idx_sbtest_c on sbtest2(c);

备注:
执行计划查看
gv$plan_cache_plan_stat和
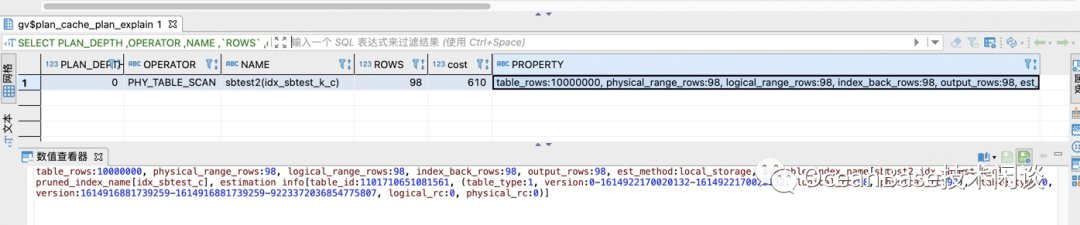
gv$plan_cache_plan_explain。以前文章也介绍过。后面这个视图比较特殊,是一个类似KV的结构,必须提供完整4个等值条件才会返回结果。
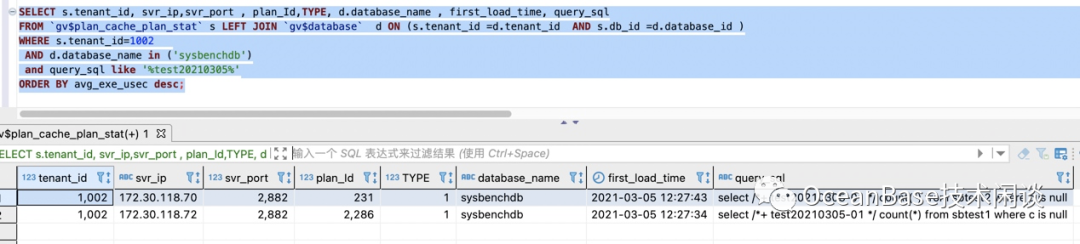
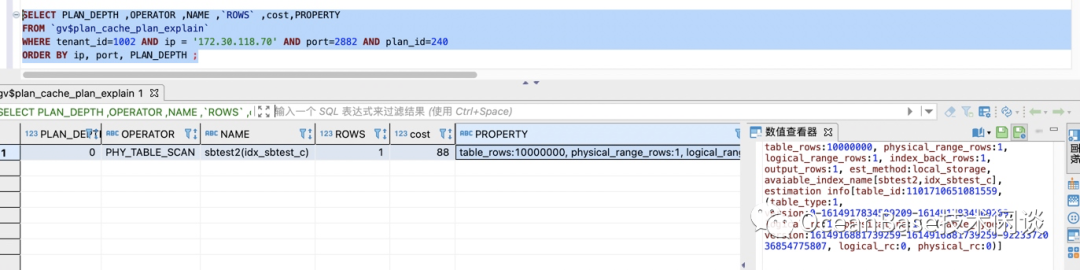
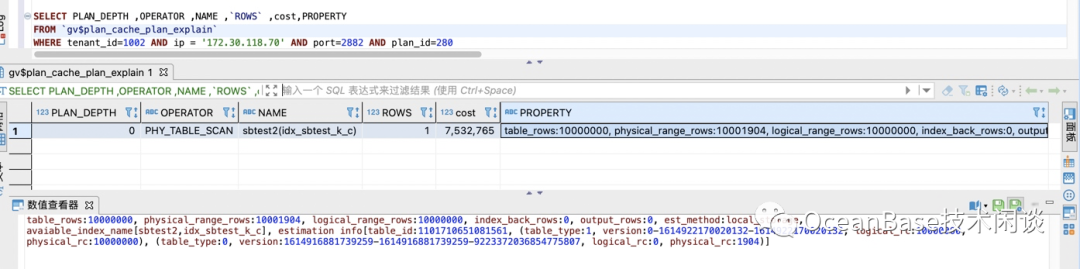
// 查看缓存的SQL执行统计信息SELECT s.tenant_id, svr_ip, svr_port , plan_Id,sql_id,TYPE, d.database_name , query_sql, first_load_time, avg_exe_usec, slow_count,executions, slowest_exe_usecFROM `gv$plan_cache_plan_stat` s LEFT JOIN `gv$database` d ON (s.tenant_id =d.tenant_id AND s.db_id =d.database_id )WHERE s.tenant_id=1002 -- 改成具体的 tenant_id AND d.database_name in ('sysbenchdb') and query_sql like '%test20210305%'ORDER BY avg_exe_usec desc;// 查看具体SQL的执行计划缓存SELECT PLAN_DEPTH ,OPERATOR ,NAME ,`ROWS` ,cost,PROPERTYFROM `gv$plan_cache_plan_explain` WHERE tenant_id=1002 AND ip = '172.30.118.70' AND port=2882 AND plan_id=231 ;
IS NULL 测试
test202103-05,主要是方便从SQL缓存里定位到这条SQL, 不影响实际执行计划和结果正确性。
select /*+ test20210305-01 */ count(*) from sbtest1 where c is null ;select /*+ test20210305-01 */ count(*) from sbtest2 where c is null ;
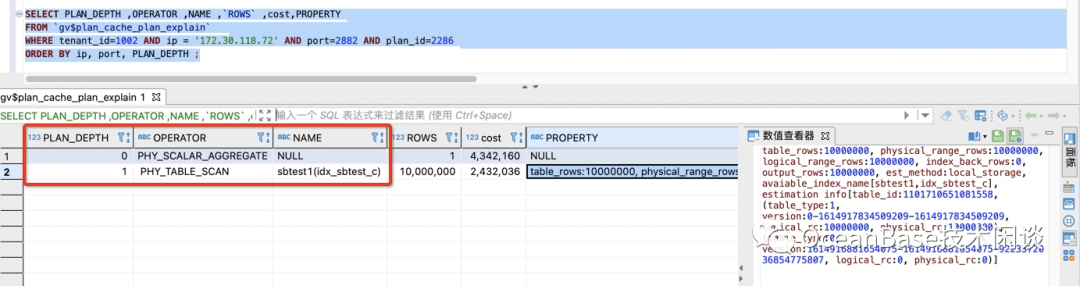
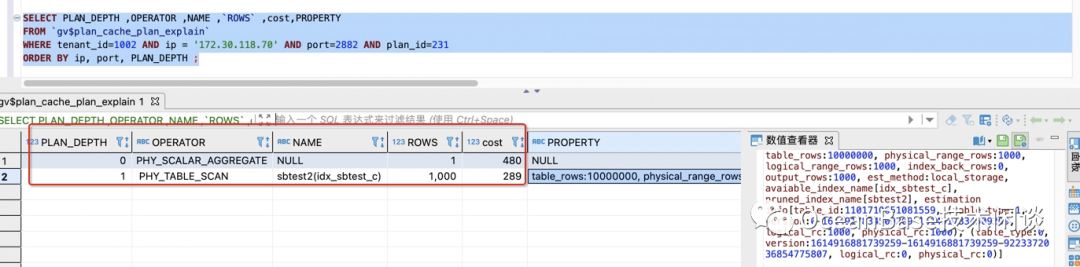
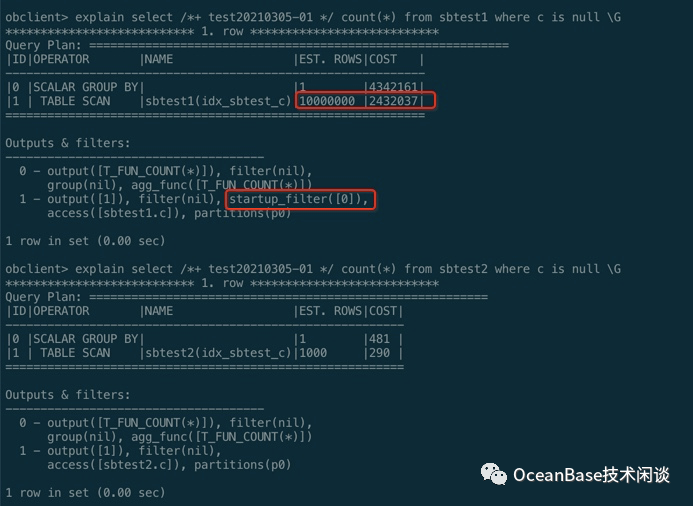
startup_filter([0])信息)。
索引列等值查询
select /*+ test20210305-02 */ * from sbtest1 where c ='10676430684-17587037436-43492067438-02978392453-17382292196-18617843758-31971657195-07771170431-78457836714-38765745127';select /*+ test20210305-02 */ * from sbtest2 where c = '10676430684-17587037436-43492067438-02978392453-17382292196-18617843758-31971657195-07771170431-78457836714-38765745127';
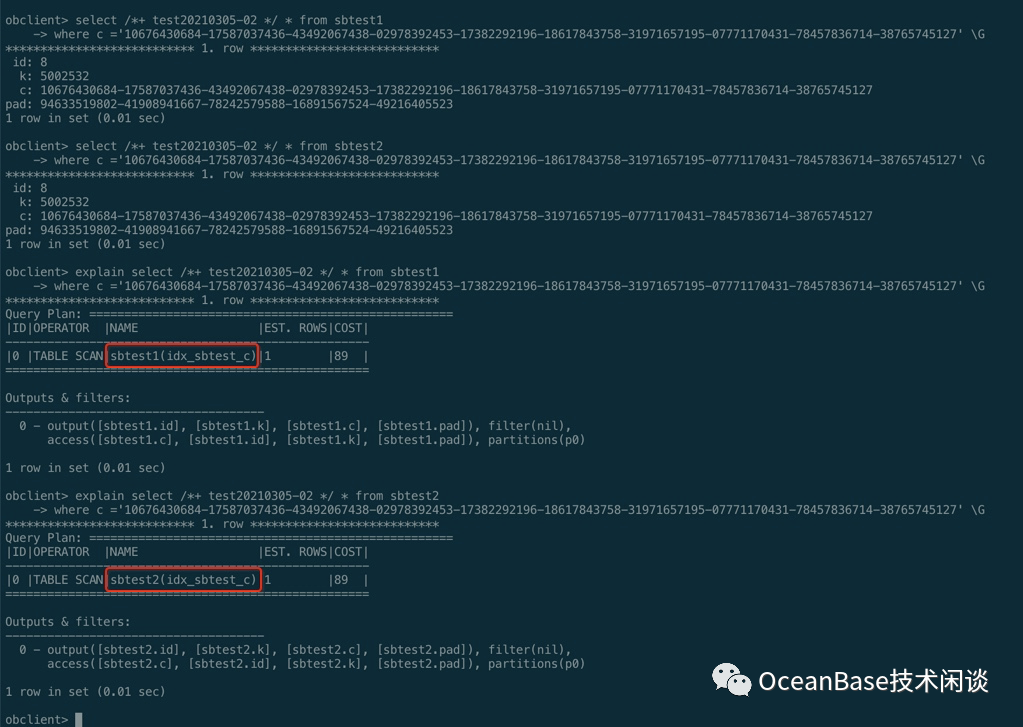

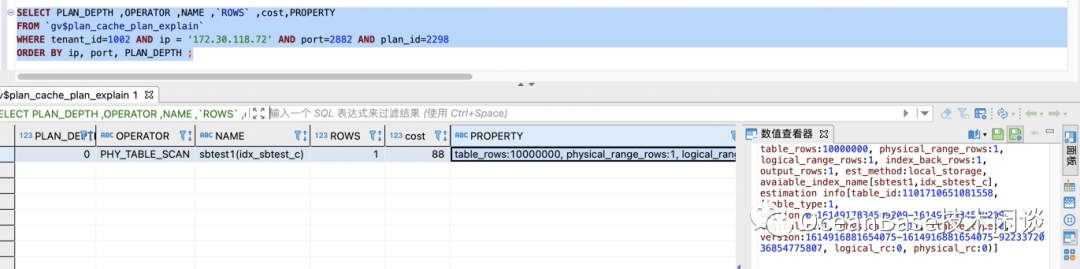
索引列模糊查询
select /*+ test20210305-03 */ * from sbtest1 where c like '10676430684-%';select /*+ test20210305-03 */ * from sbtest2 where c like '10676430684-%';
测试多列索引跟NULL关系
前导列等值查询
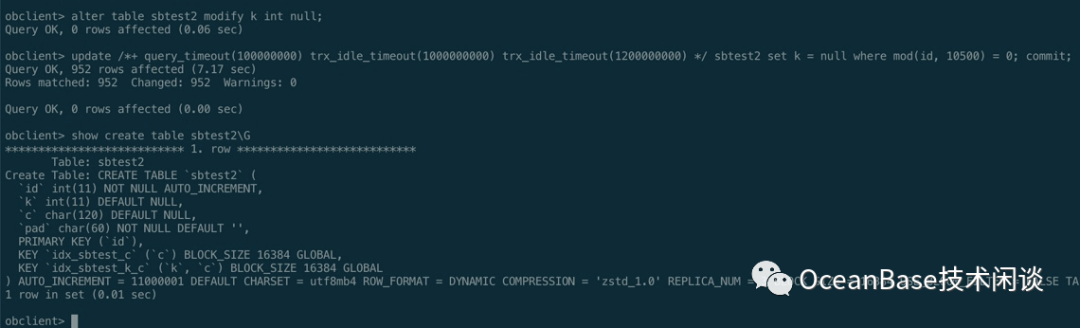
alter table sbtest2 modify k int null;update /*+ query_timeout(100000000) trx_idle_timeout(1000000000) trx_idle_timeout(1200000000) */ sbtest2 set k = null where mod(id, 10500) = 0; commit;show create table sbtest2\Gselect count(*) from sbtest2 where c is null;create index idx_sbtest_k_c on sbtest1(k, c);create index idx_sbtest_k_c on sbtest2(k, c);
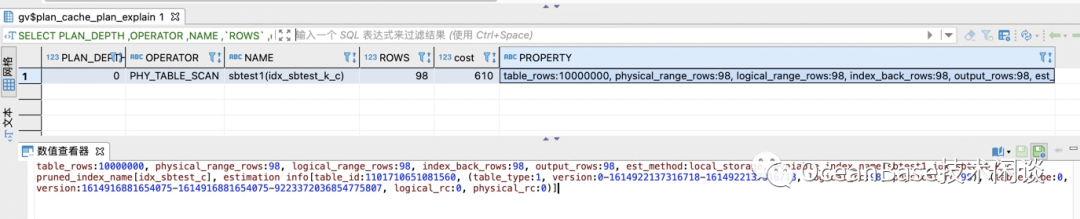
select /*+ test20210305-04 */ * from sbtest1 where k=5028116 ;select /*+ test20210305-04 */ * from sbtest2 where k=5028116 ;

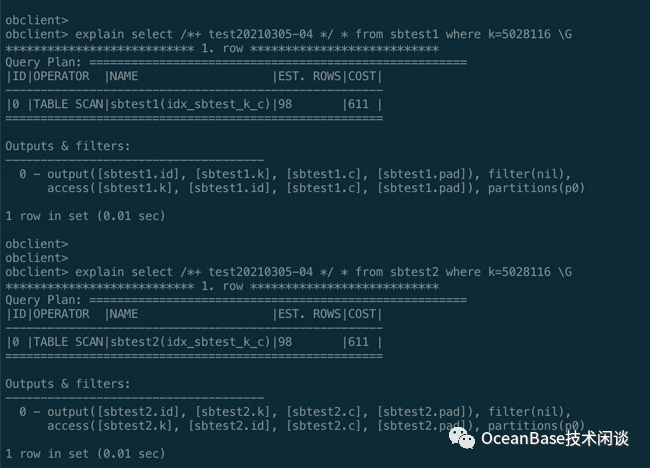
所有列等值查询
select /*+ test20210305-04 */ * from sbtest1 where k=5028116 and c = '95853251151-92786089934-87253544789-58438024614-82823928273-73185621814-81143279998-07697837769-56511602204-24615932635' ;select /*+ test20210305-04 */ * from sbtest2 where k=5028116 and c = '95853251151-92786089934-87253544789-58438024614-82823928273-73185621814-81143279998-07697837769-56511602204-24615932635' ;



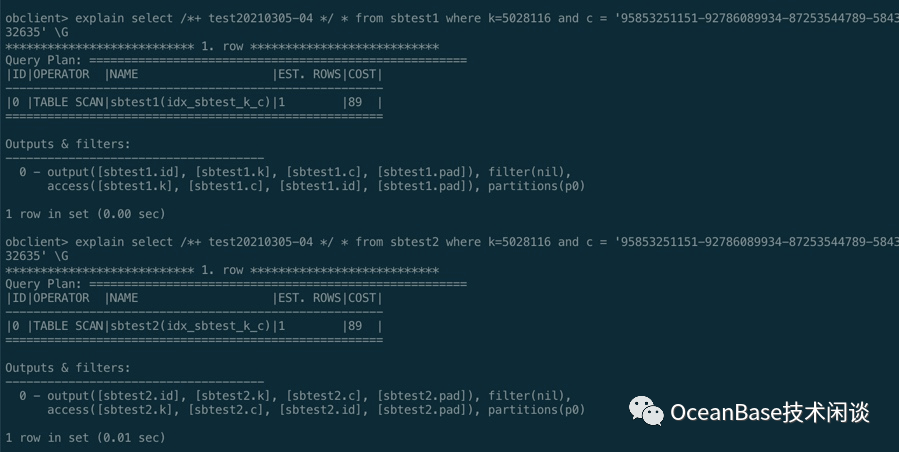
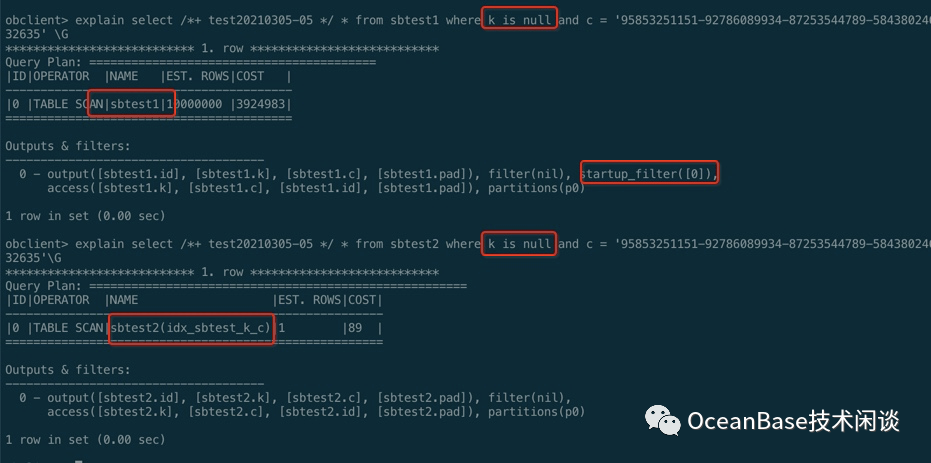
前导列 IS NULL 查询
select /*+ test20210305-05 */ * from sbtest1 where k is null and c = '95853251151-92786089934-87253544789-58438024614-82823928273-73185621814-81143279998-07697837769-56511602204-24615932635' ;select /*+ test20210305-05 */ * from sbtest2 where k is null and c = '95853251151-92786089934-87253544789-58438024614-82823928273-73185621814-81143279998-07697837769-56511602204-24615932635' ;
没有前导列条件的查询
alter table sbtest1 drop index idx_sbtest_c ;alter table sbtest2 drop index idx_sbtest_c ;select /*+ test20210305-06 */ * from sbtest1 where c = '95853251151-92786089934-87253544789-58438024614-82823928273-73185621814-81143279998-07697837769-56511602204-24615932635' ;select /*+ test20210305-06 */ * from sbtest2 where c = '95853251151-92786089934-87253544789-58438024614-82823928273-73185621814-81143279998-07697837769-56511602204-24615932635' ;


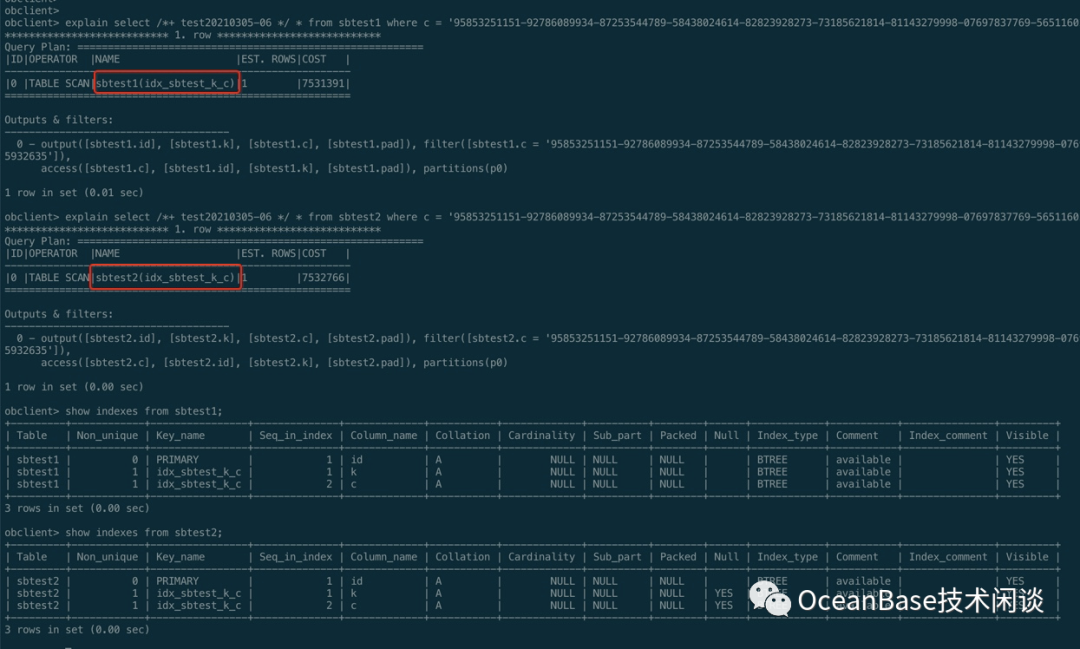
INDEX SKIP SCAN。尽管比
INDEX RANGE SCAN要慢一些,相比去扫描全表,那依然是个不错的选择。MySQL也只是在8.0后才支持
INDEX SKIP SCAN。
INDEX SKIP SCAN,不过OB的CBO也会考虑使用这个索引。扫描这个索引做过滤(
filter)操作,可能会比去扫描全表更快。当然这取决于这个SQL返回的记录数。如果记录数很大的话,内部回表还是有一定成本,CBO可能也会最终选择扫描全表。
INDEX SKIP SCAN也是同理。
ORACLE租户跟MySQL租户有区别吗
构造测试数据
从MySQL租户导出表数据
ob-dumper-loader导出 MySQL租户的两个表。
./obdumper --csv -h 127.1 -P 2883 -t obmysql01 -c obdemo -u user01 -p 123456 -D sysbenchdb --table sbtest1,sbtest2 -f data/1/obdumper --sys-password `cat ~/.syspassword`
/data/1/obdumper/data/sysbenchdb/TABLE。
准备oracle租户环境
CREATE USER user01 identified BY 123456;GRANT CONNECT,resource TO user01;
obclient -hobserver00 -P2883 -uuser01@oboracle01#obdemo -p123456 -c -A user01CREATE TABLE sbtest1 ( id number NOT NULL , k number NOT NULL DEFAULT '0', c char(120) NOT NULL DEFAULT '', pad char(60) NOT NULL DEFAULT '', PRIMARY KEY (id));CREATE TABLE sbtest2 ( id number NOT NULL , k number NULL , c char(120) NULL , pad char(60) NOT NULL DEFAULT '', PRIMARY KEY (id));
到ORACLE租户导入表数据
cd data/1/obdumper/data/sysbenchdb/TABLEls *.csv |awk -F'.csv' '{print "mv "$1".csv "toupper($1)".csv"}' |bash
./obloader --csv -h 127.1 -P 2883 -t oboracle01 -c obdemo -u user01 -p 123456 -D user01 --table SBTEST1,SBTEST2 -f data/1/obdumper --sys-password `cat ~/.syspassword`
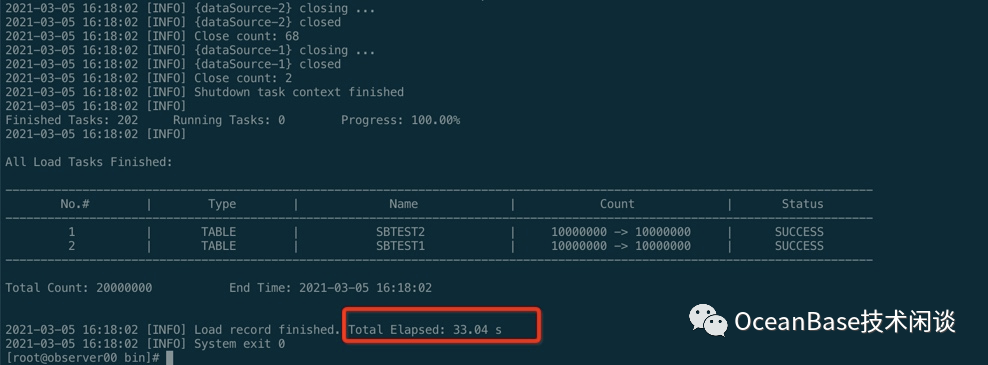
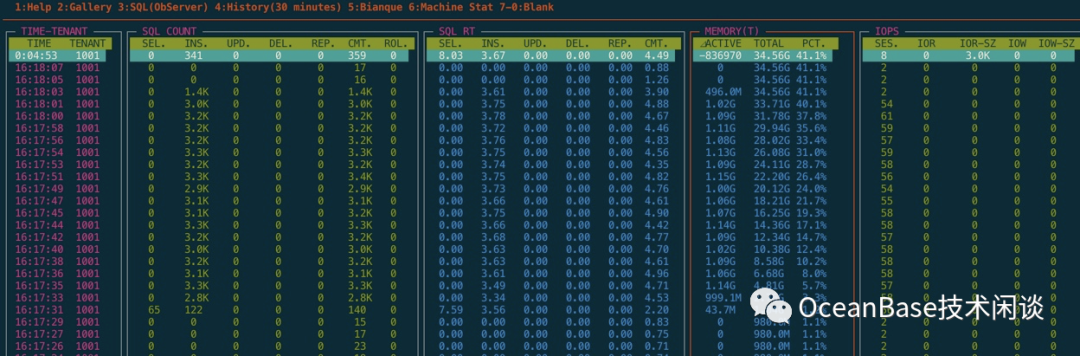
单表查询测试
多表连接测试
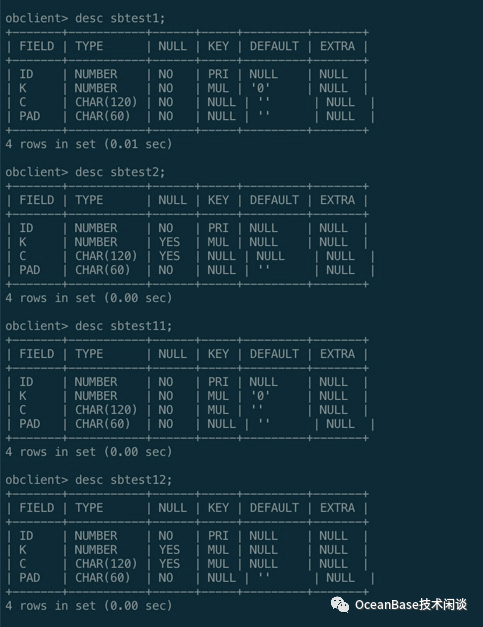
SELECT table_owner, table_Name, index_name, listagg( column_name,',') WITHIN GROUP (ORDER BY column_position) indexed_columns FROM all_ind_columns WHERE table_owner = 'USER01' GROUP BY table_owner, table_name, index_nameORDER BY table_owner, table_name, index_name;+-------------+------------+-------------------------------+-----------------+| TABLE_OWNER | TABLE_NAME | INDEX_NAME | INDEXED_COLUMNS |+-------------+------------+-------------------------------+-----------------+| USER01 | SBTEST1 | IDX_SBTEST1_C_2 | C || USER01 | SBTEST1 | IDX_SBTEST1_K_C_2 | K,C || USER01 | SBTEST1 | SBTEST1_OBPK_1614952866197016 | ID || USER01 | SBTEST11 | IDX_SBTEST1_C | C || USER01 | SBTEST11 | IDX_SBTEST1_K_C | K,C || USER01 | SBTEST11 | SBTEST1_OBPK_1614932239752654 | ID || USER01 | SBTEST12 | IDX_SBTEST2_C | C || USER01 | SBTEST12 | IDX_SBTEST2_K_C | K,C || USER01 | SBTEST12 | SBTEST2_OBPK_1614932244447062 | ID || USER01 | SBTEST2 | IDX_SBTEST2_C_2 | C || USER01 | SBTEST2 | IDX_SBTEST2_K_C_2 | K,C || USER01 | SBTEST2 | SBTEST2_OBPK_1614952868052137 | ID |+-------------+------------+-------------------------------+-----------------+12 rows in set (0.01 sec)
INNER JOIN 查询
EXPLAIN SELECT t1.*, t2.* FROM SBTEST1 t1 JOIN SBTEST11 t2 ON (t1.k=t2.K)WHERE t2.C LIKE '04420889655%';EXPLAIN SELECT t1.*, t2.* FROM SBTEST2 t1 JOIN SBTEST12 t2 ON (t1.k=t2.K)WHERE t2.C LIKE '04420889655%';
obclient> EXPLAIN -> SELECT t1.*, t2.* -> FROM SBTEST1 t1 JOIN SBTEST11 t2 ON (t1.k=t2.K) -> WHERE t2.C LIKE '04420889655%' -> \G*************************** 1. row ***************************Query Plan: ==========================================================|ID|OPERATOR |NAME |EST. ROWS|COST|----------------------------------------------------------|0 |NESTED-LOOP JOIN| |1 |84 ||1 | TABLE SCAN |T2(IDX_SBTEST1_C) |1 |84 ||2 | TABLE SCAN |T1(IDX_SBTEST1_K_C_2)|6 |115 |==========================================================Outputs & filters:------------------------------------- 0 - output([T1.ID], [T1.K], [T1.C], [T1.PAD], [T2.ID], [T2.K], [T2.C], [T2.PAD]), filter(nil), conds(nil), nl_params_([T2.K]) 1 - output([T2.K], [T2.C], [T2.ID], [T2.PAD]), filter([(T_OP_LIKE, T2.C, ?, '\')]), access([T2.K], [T2.C], [T2.ID], [T2.PAD]), partitions(p0) 2 - output([T1.K], [T1.ID], [T1.C], [T1.PAD]), filter(nil), access([T1.K], [T1.ID], [T1.C], [T1.PAD]), partitions(p0)1 row in set (0.00 sec)obclient> EXPLAIN -> SELECT t1.*, t2.* -> FROM SBTEST2 t1 JOIN SBTEST12 t2 ON (t1.k=t2.K) -> WHERE t2.C LIKE '04420889655%' -> \G*************************** 1. row ***************************Query Plan: ==========================================================|ID|OPERATOR |NAME |EST. ROWS|COST|----------------------------------------------------------|0 |NESTED-LOOP JOIN| |1 |84 ||1 | TABLE SCAN |T2(IDX_SBTEST2_C) |1 |84 ||2 | TABLE SCAN |T1(IDX_SBTEST2_K_C_2)|6 |115 |==========================================================Outputs & filters:------------------------------------- 0 - output([T1.ID], [T1.K], [T1.C], [T1.PAD], [T2.ID], [T2.K], [T2.C], [T2.PAD]), filter(nil), conds(nil), nl_params_([T2.K]) 1 - output([T2.K], [T2.C], [T2.ID], [T2.PAD]), filter([(T_OP_LIKE, T2.C, ?, '\')]), access([T2.K], [T2.C], [T2.ID], [T2.PAD]), partitions(p0) 2 - output([T1.K], [T1.ID], [T1.C], [T1.PAD]), filter(nil), access([T1.K], [T1.ID], [T1.C], [T1.PAD]), partitions(p0)1 row in set (0.01 sec)
LEFT JOIN 查询
EXPLAIN SELECT t1.*, t2.* FROM SBTEST1 t1 LEFT JOIN SBTEST11 t2 ON (t1.k=t2.K AND t2.C LIKE '04420889655%');EXPLAIN SELECT t1.*, t2.* FROM SBTEST2 t1 LEFT JOIN SBTEST12 t2 ON (t1.k=t2.K AND t2.C LIKE '04420889655%');
obclient> EXPLAIN -> SELECT t1.*, t2.* -> FROM SBTEST1 t1 LEFT JOIN SBTEST11 t2 ON (t1.k=t2.K AND t2.C LIKE '04420889655%') -> \G*************************** 1. row ***************************Query Plan: ==============================================================|ID|OPERATOR |NAME |EST. ROWS|COST |--------------------------------------------------------------|0 |HASH RIGHT OUTER JOIN| |10000000 |7488265||1 | TABLE SCAN |T2(IDX_SBTEST1_C)|1 |84 ||2 | TABLE SCAN |T1 |10000000 |3945573|==============================================================Outputs & filters:------------------------------------- 0 - output([T1.ID], [T1.K], [T1.C], [T1.PAD], [T2.ID], [T2.K], [T2.C], [T2.PAD]), filter(nil), equal_conds([T1.K = T2.K]), other_conds(nil) 1 - output([T2.K], [T2.C], [T2.ID], [T2.PAD]), filter([(T_OP_LIKE, T2.C, ?, '\')]), access([T2.K], [T2.C], [T2.ID], [T2.PAD]), partitions(p0) 2 - output([T1.K], [T1.ID], [T1.C], [T1.PAD]), filter(nil), access([T1.K], [T1.ID], [T1.C], [T1.PAD]), partitions(p0)1 row in set (0.00 sec)obclient> EXPLAIN -> SELECT t1.*, t2.* -> FROM SBTEST2 t1 LEFT JOIN SBTEST12 t2 ON (t1.k=t2.K AND t2.C LIKE '04420889655%') -> \G*************************** 1. row ***************************Query Plan: ==============================================================|ID|OPERATOR |NAME |EST. ROWS|COST |--------------------------------------------------------------|0 |HASH RIGHT OUTER JOIN| |10000000 |7488266||1 | TABLE SCAN |T2(IDX_SBTEST2_C)|1 |84 ||2 | TABLE SCAN |T1 |10000000 |3945573|==============================================================Outputs & filters:------------------------------------- 0 - output([T1.ID], [T1.K], [T1.C], [T1.PAD], [T2.ID], [T2.K], [T2.C], [T2.PAD]), filter(nil), equal_conds([T1.K = T2.K]), other_conds(nil) 1 - output([T2.K], [T2.C], [T2.ID], [T2.PAD]), filter([(T_OP_LIKE, T2.C, ?, '\')]), access([T2.K], [T2.C], [T2.ID], [T2.PAD]), partitions(p0) 2 - output([T1.K], [T1.ID], [T1.C], [T1.PAD]), filter(nil), access([T1.K], [T1.ID], [T1.C], [T1.PAD]), partitions(p0)1 row in set (0.00 sec)
EXISTS子查询
EXPLAIN SELECT * FROM SBTEST1 t1 WHERE exists ( SELECT k FROM sbtest11 t2 WHERE t2.k = t1.k AND t2.C LIKE '04420889655%');EXPLAIN SELECT * FROM SBTEST2 t1 WHERE exists ( SELECT k FROM sbtest12 t2 WHERE t2.k = t1.k AND t2.C LIKE '04420889655%');
obclient> EXPLAIN -> SELECT * FROM SBTEST1 t1 -> WHERE exists ( -> SELECT k FROM sbtest11 t2 WHERE t2.k = t1.k AND t2.C LIKE '04420889655%' -> )\G*************************** 1. row ***************************Query Plan: ==========================================================|ID|OPERATOR |NAME |EST. ROWS|COST|----------------------------------------------------------|0 |NESTED-LOOP JOIN| |1 |84 ||1 | SUBPLAN SCAN |VIEW1 |1 |84 ||2 | HASH DISTINCT | |1 |84 ||3 | TABLE SCAN |T2(IDX_SBTEST1_C) |1 |84 ||4 | TABLE SCAN |T1(IDX_SBTEST1_K_C_2)|6 |115 |==========================================================Outputs & filters:------------------------------------- 0 - output([T1.ID], [T1.K], [T1.C], [T1.PAD]), filter(nil), conds(nil), nl_params_([VIEW1.T2.K]) 1 - output([VIEW1.T2.K]), filter(nil), access([VIEW1.T2.K]) 2 - output([T2.K]), filter(nil), distinct([T2.K]) 3 - output([T2.K]), filter([(T_OP_LIKE, T2.C, ?, '\')]), access([T2.K], [T2.C]), partitions(p0) 4 - output([T1.K], [T1.ID], [T1.C], [T1.PAD]), filter(nil), access([T1.K], [T1.ID], [T1.C], [T1.PAD]), partitions(p0)1 row in set (0.01 sec)obclient> EXPLAIN -> SELECT * FROM SBTEST2 t1 -> WHERE exists ( -> SELECT k FROM sbtest12 t2 WHERE t2.k = t1.k AND t2.C LIKE '04420889655%' -> )\G*************************** 1. row ***************************Query Plan: ==========================================================|ID|OPERATOR |NAME |EST. ROWS|COST|----------------------------------------------------------|0 |NESTED-LOOP JOIN| |1 |84 ||1 | SUBPLAN SCAN |VIEW1 |1 |84 ||2 | HASH DISTINCT | |1 |84 ||3 | TABLE SCAN |T2(IDX_SBTEST2_C) |1 |84 ||4 | TABLE SCAN |T1(IDX_SBTEST2_K_C_2)|6 |115 |==========================================================Outputs & filters:------------------------------------- 0 - output([T1.ID], [T1.K], [T1.C], [T1.PAD]), filter(nil), conds(nil), nl_params_([VIEW1.T2.K]) 1 - output([VIEW1.T2.K]), filter(nil), access([VIEW1.T2.K]) 2 - output([T2.K]), filter(nil), distinct([T2.K]) 3 - output([T2.K]), filter([(T_OP_LIKE, T2.C, ?, '\')]), access([T2.K], [T2.C]), partitions(p0) 4 - output([T1.K], [T1.ID], [T1.C], [T1.PAD]), filter(nil), access([T1.K], [T1.ID], [T1.C], [T1.PAD]), partitions(p0)1 row in set (0.00 sec)
结论:不管列是否包含 NULL ,EXISTS 的执行计划是一样的。
NOT EXISTS 子查询
EXPLAIN SELECT * FROM SBTEST1 t1 WHERE NOT exists ( SELECT k FROM sbtest11 t2 WHERE t2.k = t1.k AND t2.C LIKE '044208%');EXPLAIN SELECT * FROM SBTEST2 t1 WHERE NOT exists ( SELECT k FROM sbtest12 t2 WHERE t2.k = t1.k AND t2.C LIKE '044208%');
obclient> EXPLAIN -> SELECT * FROM SBTEST1 t1 -> WHERE NOT exists ( -> SELECT k FROM sbtest11 t2 WHERE t2.k = t1.k AND t2.C LIKE '044208%' -> )\G*************************** 1. row ***************************Query Plan: =============================================================|ID|OPERATOR |NAME |EST. ROWS|COST |-------------------------------------------------------------|0 |HASH RIGHT ANTI JOIN| |9999995 |7488278||1 | TABLE SCAN |T2(IDX_SBTEST1_C)|1 |93 ||2 | TABLE SCAN |T1 |10000000 |3945573|=============================================================Outputs & filters:------------------------------------- 0 - output([T1.ID], [T1.K], [T1.C], [T1.PAD]), filter(nil), equal_conds([T2.K = T1.K]), other_conds(nil) 1 - output([T2.K]), filter([(T_OP_LIKE, T2.C, ?, '\')]), access([T2.K], [T2.C]), partitions(p0) 2 - output([T1.K], [T1.ID], [T1.C], [T1.PAD]), filter(nil), access([T1.K], [T1.ID], [T1.C], [T1.PAD]), partitions(p0)1 row in set (0.01 sec)obclient> EXPLAIN -> SELECT * FROM SBTEST2 t1 -> WHERE NOT exists ( -> SELECT k FROM sbtest12 t2 WHERE t2.k = t1.k AND t2.C LIKE '044208%' -> )\G*************************** 1. row ***************************Query Plan: =============================================================|ID|OPERATOR |NAME |EST. ROWS|COST |-------------------------------------------------------------|0 |HASH RIGHT ANTI JOIN| |9999995 |7488278||1 | TABLE SCAN |T2(IDX_SBTEST2_C)|1 |93 ||2 | TABLE SCAN |T1 |10000000 |3945573|=============================================================Outputs & filters:------------------------------------- 0 - output([T1.ID], [T1.K], [T1.C], [T1.PAD]), filter(nil), equal_conds([T2.K = T1.K]), other_conds(nil) 1 - output([T2.K]), filter([(T_OP_LIKE, T2.C, ?, '\')]), access([T2.K], [T2.C]), partitions(p0) 2 - output([T1.K], [T1.ID], [T1.C], [T1.PAD]), filter(nil), access([T1.K], [T1.ID], [T1.C], [T1.PAD]), partitions(p0)1 row in set (0.00 sec)
结论:不管列是否包含 NULL ,NOT EXISTS 的执行计划是一样的。
IN 子查询
EXPLAIN SELECT * FROM SBTEST1 t1 WHERE t1.k IN ( SELECT k FROM sbtest11 t2 WHERE t2.C LIKE '04420889655%');EXPLAIN SELECT * FROM SBTEST2 t1 WHERE t1.k IN ( SELECT k FROM sbtest12 t2 WHERE t2.C LIKE '04420889655%');
obclient> EXPLAIN -> SELECT * FROM SBTEST1 t1 -> WHERE t1.k IN ( -> SELECT k FROM sbtest11 t2 WHERE t2.C LIKE '04420889655%' -> ) -> \G*************************** 1. row ***************************Query Plan: ==========================================================|ID|OPERATOR |NAME |EST. ROWS|COST|----------------------------------------------------------|0 |NESTED-LOOP JOIN| |1 |84 ||1 | SUBPLAN SCAN |VIEW1 |1 |84 ||2 | HASH DISTINCT | |1 |84 ||3 | TABLE SCAN |T2(IDX_SBTEST1_C) |1 |84 ||4 | TABLE SCAN |T1(IDX_SBTEST1_K_C_2)|6 |115 |==========================================================Outputs & filters:------------------------------------- 0 - output([T1.ID], [T1.K], [T1.C], [T1.PAD]), filter(nil), conds(nil), nl_params_([VIEW1.T2.K]) 1 - output([VIEW1.T2.K]), filter(nil), access([VIEW1.T2.K]) 2 - output([T2.K]), filter(nil), distinct([T2.K]) 3 - output([T2.K]), filter([(T_OP_LIKE, T2.C, ?, '\')]), access([T2.C], [T2.K]), partitions(p0) 4 - output([T1.K], [T1.ID], [T1.C], [T1.PAD]), filter(nil), access([T1.K], [T1.ID], [T1.C], [T1.PAD]), partitions(p0)1 row in set (0.01 sec)obclient> EXPLAIN -> SELECT * FROM SBTEST2 t1 -> WHERE t1.k IN ( -> SELECT k FROM sbtest12 t2 WHERE t2.C LIKE '04420889655%' -> )\G*************************** 1. row ***************************Query Plan: ==========================================================|ID|OPERATOR |NAME |EST. ROWS|COST|----------------------------------------------------------|0 |NESTED-LOOP JOIN| |1 |84 ||1 | SUBPLAN SCAN |VIEW1 |1 |84 ||2 | HASH DISTINCT | |1 |84 ||3 | TABLE SCAN |T2(IDX_SBTEST2_C) |1 |84 ||4 | TABLE SCAN |T1(IDX_SBTEST2_K_C_2)|6 |115 |==========================================================Outputs & filters:------------------------------------- 0 - output([T1.ID], [T1.K], [T1.C], [T1.PAD]), filter(nil), conds(nil), nl_params_([VIEW1.T2.K]) 1 - output([VIEW1.T2.K]), filter(nil), access([VIEW1.T2.K]) 2 - output([T2.K]), filter(nil), distinct([T2.K]) 3 - output([T2.K]), filter([(T_OP_LIKE, T2.C, ?, '\')]), access([T2.C], [T2.K]), partitions(p0) 4 - output([T1.K], [T1.ID], [T1.C], [T1.PAD]), filter(nil), access([T1.K], [T1.ID], [T1.C], [T1.PAD]), partitions(p0)1 row in set (0.00 sec)
NOT IN 子查询
EXPLAINSELECT * FROM SBTEST1 t1 WHERE t1.k NOT IN ( SELECT k FROM sbtest11 t2 WHERE t2.C LIKE '044208%') AND t1.c LIKE '044208%';EXPLAIN SELECT * FROM SBTEST2 t1 WHERE t1.k NOT IN ( SELECT k FROM sbtest12 t2 WHERE t2.C LIKE '044208%') AND t1.c LIKE '044208%';
obclient> EXPLAIN -> SELECT * FROM SBTEST1 t1 -> WHERE t1.k NOT IN ( -> SELECT k FROM sbtest11 t2 WHERE t2.C LIKE '044208%' -> ) AND t1.c LIKE '044208%' -> \G*************************** 1. row ***************************Query Plan: =============================================================|ID|OPERATOR |NAME |EST. ROWS|COST|-------------------------------------------------------------|0 |NESTED-LOOP ANTI JOIN| |0 |93 ||1 | TABLE SCAN |T1(IDX_SBTEST1_C_2)|1 |93 ||2 | TABLE SCAN |T2(IDX_SBTEST1_K_C)|1 |40 |=============================================================Outputs & filters:------------------------------------- 0 - output([T1.ID], [T1.K], [T1.C], [T1.PAD]), filter(nil), conds(nil), nl_params_([T1.K]) 1 - output([T1.K], [T1.C], [T1.ID], [T1.PAD]), filter([(T_OP_LIKE, T1.C, ?, '\')]), access([T1.K], [T1.C], [T1.ID], [T1.PAD]), partitions(p0) 2 - output([1]), filter([(T_OP_LIKE, T2.C, ?, '\')]), access([T2.C]), partitions(p0)1 row in set (0.00 sec)obclient> EXPLAIN -> SELECT * FROM SBTEST2 t1 -> WHERE t1.k NOT IN ( -> SELECT k FROM sbtest12 t2 WHERE t2.C LIKE '044208%' -> ) AND t1.c LIKE '044208%' -> \G*************************** 1. row ***************************Query Plan: =============================================================|ID|OPERATOR |NAME |EST. ROWS|COST|-------------------------------------------------------------|0 |NESTED-LOOP ANTI JOIN| |0 |185 ||1 | TABLE SCAN |T1(IDX_SBTEST2_C_2)|1 |93 ||2 | MATERIAL | |1 |93 ||3 | TABLE SCAN |T2(IDX_SBTEST2_C) |1 |93 |=============================================================Outputs & filters:------------------------------------- 0 - output([T1.ID], [T1.K], [T1.C], [T1.PAD]), filter(nil), conds([(T_OP_OR, T1.K = T2.K, (T_OP_IS, T1.K, NULL, 0), (T_OP_IS, T2.K, NULL, 0))]), nl_params_(nil) 1 - output([T1.K], [T1.C], [T1.ID], [T1.PAD]), filter([(T_OP_LIKE, T1.C, ?, '\')]), access([T1.K], [T1.C], [T1.ID], [T1.PAD]), partitions(p0) 2 - output([T2.K]), filter(nil) 3 - output([T2.K]), filter([(T_OP_LIKE, T2.C, ?, '\')]), access([T2.C], [T2.K]), partitions(p0)1 row in set (0.00 sec)
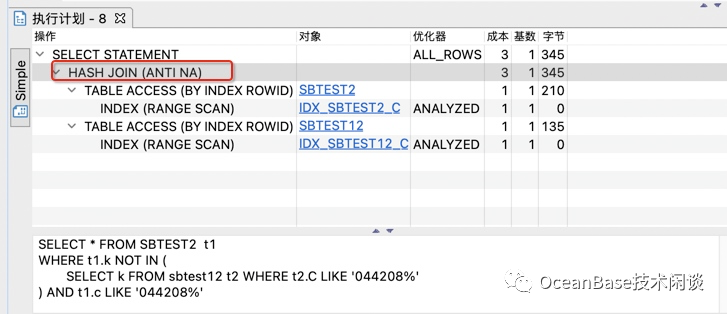
结论
更多参考
oracle的nested loop anti join :
http://www.juliandyke.com/Optimisation/Operations/NestedLoopsAnti.php
如果觉得本文有帮助就点个赞😄️,有问题欢迎进钉钉群讨论。
文章转载自OceanBase技术闲谈,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
