




本文是boltdb探秘系列的第三篇,将分析boltdb的取值流程,预计耗时3~4分钟。
Get即遍历B+树的过程
(*Bucket).Get方法用于根据传入的key找到对应的value,调用核心是(*Cursor).seek方法。而seek方法的处理步骤是先定位到key所在的节点,再尝试取值,用于辅助定位的数据结构是Cursor。
func (b *Bucket) Get(key []byte) []byte {k, v, flags := b.Cursor().seek(key)...}
Cursor
每次调用Get都会新建一个Cursor对象,Cursor中包含的stack相当于遍历树找到目标节点的路径。
type Cursor struct {bucket *Bucketstack []elemRef}
在boltdb探秘系列的第二篇中提到,boltdb在磁盘中按page组织数据,在内存中会反序列化为node,elemRef对象将page和node关联到一起。B+树单个节点中会有多个key(中间节点表示子树,叶子节点表示实际的KV对),index属性表示搜索时选择的分支。
type elemRef struct {page *pagenode *nodeindex int}
(*Cursor).search方法
search方法是B+树搜索特定key的实现,入参数为key和pageid,根据pageid获取对应的page或者node,组装成elemRef并追加到stack。如果pageid对应的节点是叶子节点,则直接搜索对应的KV对,否则从子节点继续查找。
查找子节点优先调用searchNode方法从node查找;当node未被序列化时才调用searchPage从page查找。在这两个方法里都会递归调用search方法。不过就目前的流程看来,读事务都是直接读的page。
表面读DB,背后mmap
前文提到,读取某个值的会从文件里读入page。对于boltdb这种频繁读的场景,直接使用文件读取不是最优方案。
直接读取会发生两次拷贝:一次从磁盘读取到内核态缓存页,一次从内核拷贝到用户态。
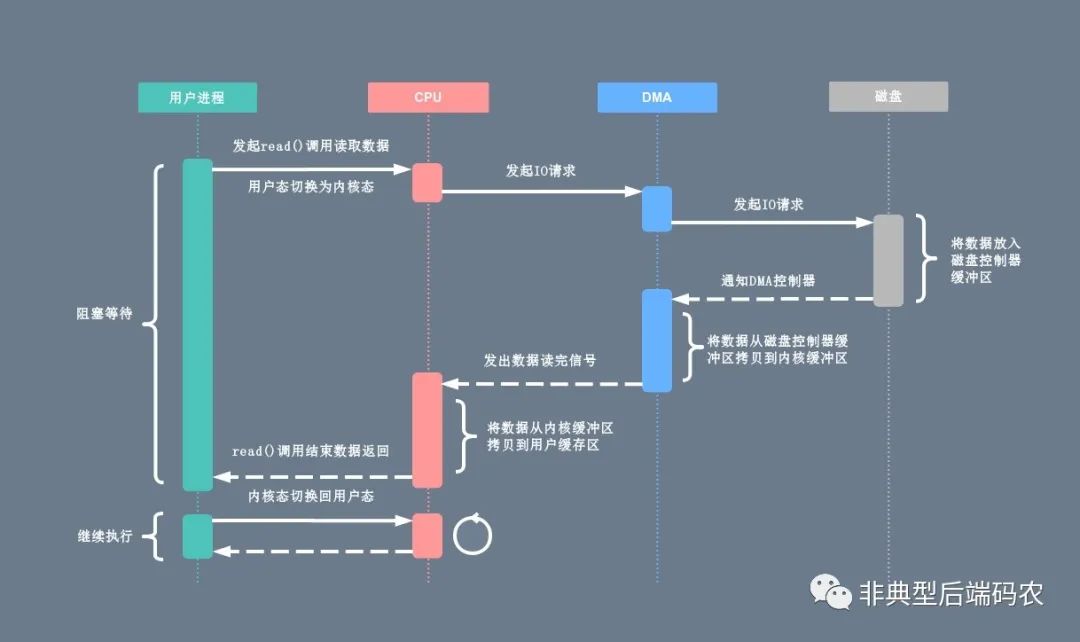
boltdb使用mmap对读进行优化:mmap将以一个文件直接映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。这样只需要一次数据拷贝就可以在进程虚拟地址中访问数据。
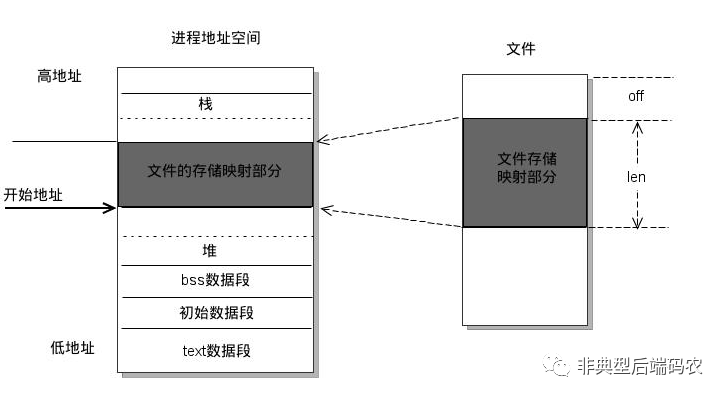
当进程发起对这边映射空间的访问时,页不存在则产生缺页异常,从磁盘中加载对应的页面。linux中默认的页面大小为4K,因此boltdb中的页大小也为4K,但这不是必定的,而是在DB初始化时通过os.Getpagesize读取的。
# 总结
boltdb读取一个key的流程实际上是在B+树上查询,借助Cursor对象定位到目标key所在的页面,再返回KV对。page和node一一对应,Cursor遍历的过程中优先查看node,否则从page中查找,而读事务里都只会直接从page中加载。为了减少数据拷贝,boltdb使用mmap优化读操作。
