




点击上方"数据与人", 右上角选择“设为星标”
分享干货,共同成长!


不使用索引条件下推优化时存储引擎通过索引检索到数据,然后返回给MySQL服务器,服务器然后判断数据是否符合条件。
当使用索引条件下推优化时,如果存在某些被索引的列的判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器。
索引条件下推优化可以减少存储引擎查询基础表的次数,也可以减少MySQL服务器从存储引擎接收数据的次数。
换句话说:索引下推能减少回表查询次数,提高查询效率。
索引下推优化的原理
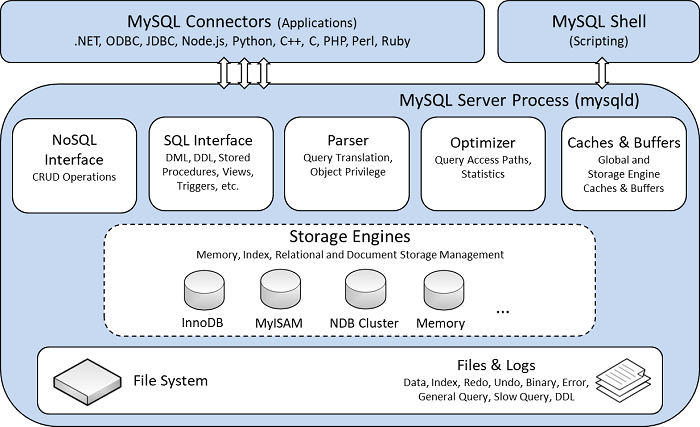
MySQL从上至下分为以下几层:
MySQL服务层:包括NoSQL和SQL接口、查询解析器、优化器、缓存和Buffer等组件。
存储引擎层:各种插件式的表格存储引擎,实现事务、索引等各种存储引擎相关的特性。
文件系统层: 读写物理文件。
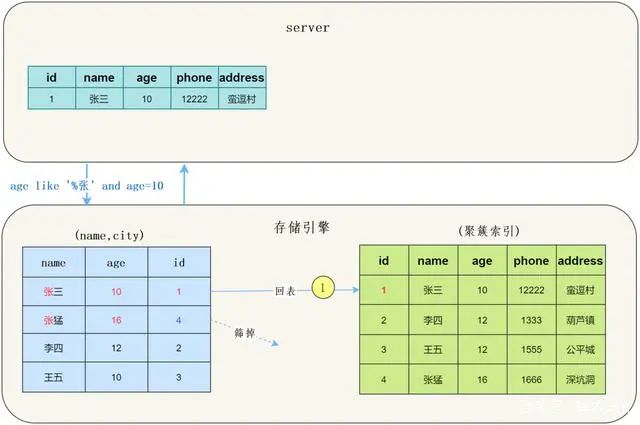
获取下一行,首先读取索引信息,然后根据索引将整行数据读取出来。
然后通过where条件判断当前数据是否符合条件,符合返回数据。
获取下一行的索引信息。
检查索引中存储的列信息是否符合索引条件,如果符合将整行数据读取出来,如果不符合跳过读取下一行。
用剩余的判断条件,判断此行数据是否符合要求,符合要求返回数据。
索引下推适用条件
需要整表扫描的情况。比如:range, ref, eq_ref, ref_or_null 。
适用于InnoDB 引擎和 MyISAM 引擎的查询。(5.6版本不适用分区表查询,5.7版本后可以用于分区表查询)。
对于InnDB引擎只适用于二级索引,因为InnDB的聚簇索引会将整行数据读到InnDB的缓冲区,这样一来索引条件下推的主要目的减少IO次数就失去了意义。因为数据已经在内存中了,不再需要去读取了。
引用子查询的条件不能下推。
调用存储过程的条件不能下推,存储引擎无法调用位于MySQL服务器中的存储过程。
触发条件不能下推。
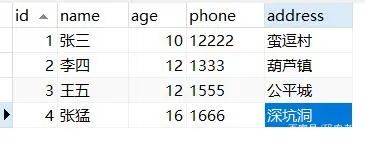
select * from tuser where name like '张%' and age=10;
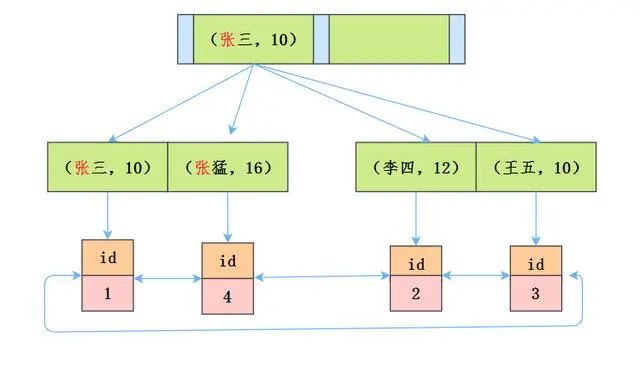
没有使用ICP
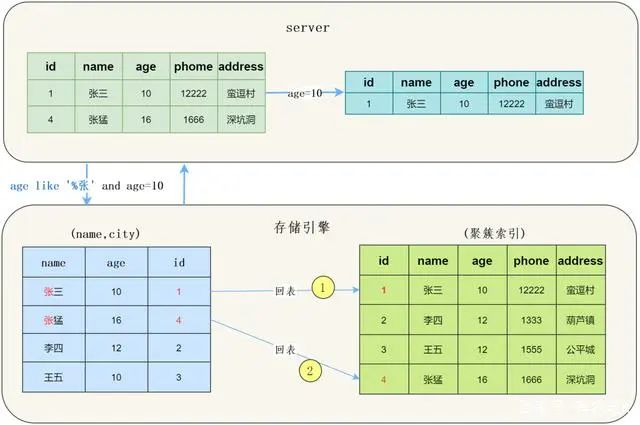
使用ICP
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra || 1 | SIMPLE | tuser | NULL | range | na_index | na_index | 102 | NULL | 2 | 25.00 | Using index condition |
相关系统参数
mysql> select @@optimizer_switch\G;index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on
set ="index_condition_pushdown=off";set ="index_condition_pushdown=on";
思考
索引下推优化技术其实就是充分利用了索引中的数据,尽量在查询出整行数据之前过滤掉无效的数据。
由于需要存储引擎将索引中的数据与条件进行判断,所以这个技术是基于存储引擎的,只有特定引擎可以使用。并且判断条件需要是在存储引擎这个层面可以进行的操作才可以,比如调用存储过程的条件就不可以,因为存储引擎没有调用存储过程的能力。
参考:
1、《 MySQL技术内幕 InnoDB存储引擎》
2、《MySQL实战45讲》

