一个Mysql数据库的健康指标突然下降,健康指标从90多分下降了近10分。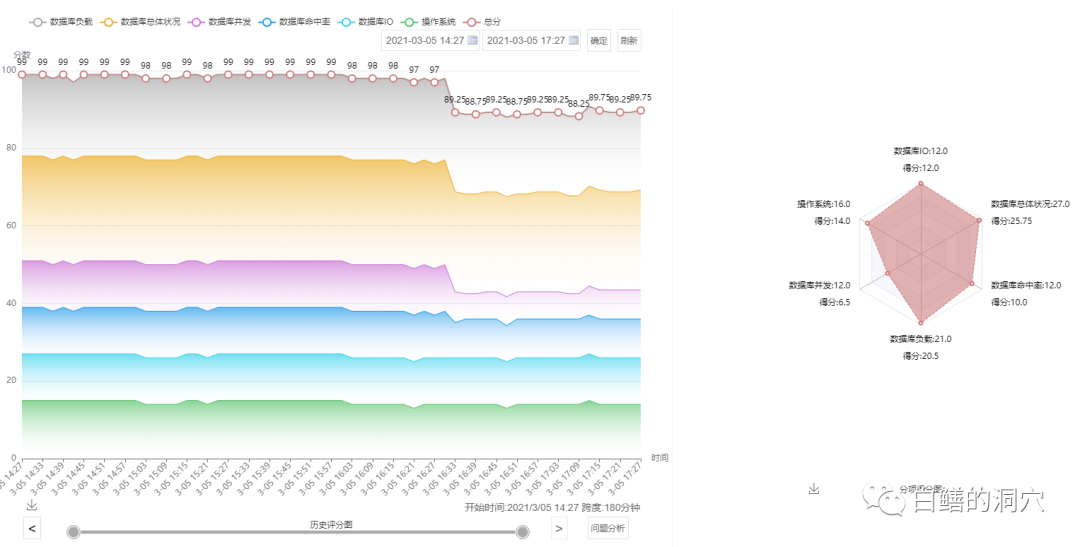
是什么原因导致的呢?通过健康模型的分析发现检查点延时量指标出现了较大的异常。
在数据库的健康模型里也没有发现什么特别的问题,于是只能采用模糊分析的方法,通过指标关联分析来看看是不是有一些关联性的指标和检查点延时有关。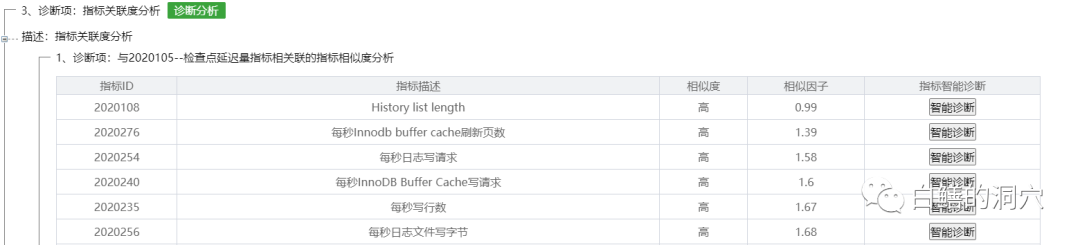
排在第一位的是一个十分陌生的指标,history list length。查看出问题的时段,发现这个指标确实出现过一个高值。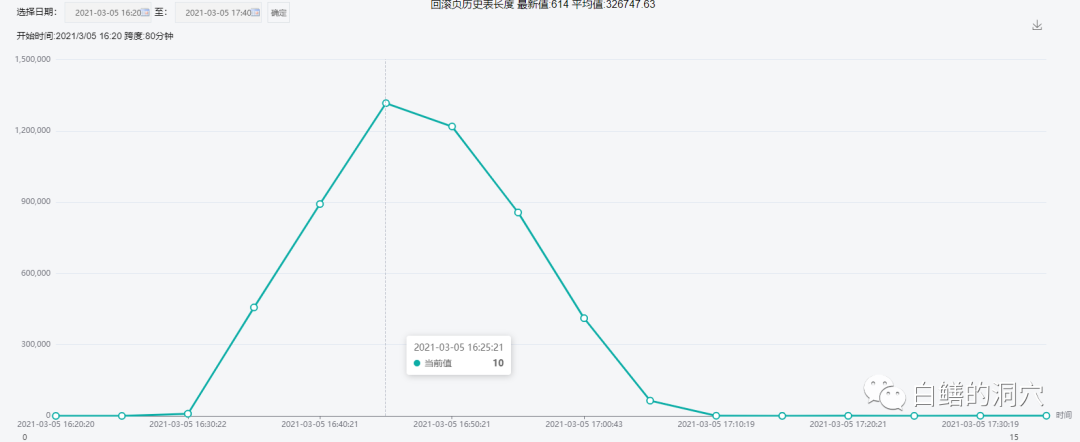
这个指标在16:30以后急剧增加,16:40左右达到了高峰,最高时候达到了130万+,随后逐渐下降。这个时段也正好是客户感觉系统性能存在一定问题的时候。老白学习MYSQL时间不长,不是很清楚这个指标的含义,于是去网上搜索了一下这个指标的定义。History list length是指在回滚空间中的未清除事务数。随着事务的提交,它的值会增加;随着清除线程的运行,它的值会减小。为了实现MVCC多版本并发控制,在MYSQL的UNDO LOG中保留了所有需要保证某个PRE-IMAGE能够被所需要的会话访问的所有的事务版本链表。而这个history list length就是这个链表的大小,单位是变更。这有点像是ORACLE 因为UNDO RETENTION保留的UNDO 记录的情况。按理说,一些不需要的UNDO记录是会被自动清理掉的,不过如果这些记录暂时还有人用,则不能清理。
如果这时候有一个事务没有提交,由于MYSQL的缺省事务隔离级别是REPEATABLE-READ,那么这个大事务后的UNDO记录就不能清理。随着没清理的UNDO记录数量剧增,清理UNDO操作的线程就要不断重复扫描这些数据,但是又无法清理掉这些数据。这时候MYSQL的性能就受到了影响。在repeatable-read隔离级别的会话中,如果有会话访问了某个数据,而这个会话没有提交事务,那么这个会话就需要第一次访问这张表的所有PRE-IMAGE数据,那么这些UNDO list数据就不能被清理。既然有了怀疑的方向就好办了,于是找开发人员问了一下16:40左右做了些什么异常的操作。问了一圈发现有一个小组当时在做数据修正工作,大批量修改了一些数据。不过开发人员认为他们修改的这部分数据和白天的业务关系不大,主要是晚上的统计业务会用到,因此他们才决定白天做这个操作,避免晚上做这个操作影响晚上的统计业务。看样子Mysql和ORACLE确实有很大的差异,在UNDO的内部机制上,这种操作对ORACLE数据库的影响不会是全局性的,顶多会影响这张表的用户,而在MYSQL上就不同了,可能会引起一些全局性的性能问题。不仅仅一个长时间运行的事务会导致这次性能问题类似的问题,一个长时间运行的SELECT语句也会因为这个原因而让History list length暴增,从而引发类似的性能问题。看样子,在MYSQL上,业务高峰期还是要尽可能避免此类的操作。





