




介绍
数据科学面试包括统计和概率、线性代数、向量、微积分、机器学习/深度学习数学、Python、OOPs 概念和 Numpy/Tensor 操作等问题。除此之外,面试官还会询问您的项目及其目标。简而言之,面试官关注的是基本概念和项目。
本文是数据科学面试系列的第 1 部分,将涵盖一些基本的数据科学面试问题。我们将讨论面试问题及其答案:
什么是 OLS?为什么,我们在哪里使用它?
OLS(或普通最小二乘法)是一种线性回归技术,有助于估计可能影响输出的未知参数。这种方法依赖于最小化损失函数。损失函数是实际值和预测值之间的残差平方和。残差是目标值和预测值之间的差值。误差或残差为:
最小化∑( yi – ŷ i) ^2
其中ŷ i 是预测值,yi 是实际值。
当我们有多个输入时,我们使用 OLS。这种方法将数据视为矩阵,并使用线性代数运算估计最佳系数。
什么是正则化?我们在哪里使用它?
正则化是一种减少训练模型过拟合的技术。这种技术用于模型过度拟合数据的地方。
当模型在训练集上表现良好但在测试集上表现不佳时,就会发生过拟合。该模型对训练集的误差最小,但对测试集的误差很高。
因此,正则化技术惩罚损失函数以获得完美拟合模型。
L1 和 L2 正则化有什么区别?
L1 正则化也称为 Lasso(最小绝对收缩和选择算子)回归。该方法通过添加系数幅值的绝对值作为惩罚项来惩罚损失函数。
当我们有很多功能时,Lasso 效果很好。这种技术适用于模型选择,因为它通过将系数缩小到零来减少不太重要的变量的特征。
因此,它删除了一些不太重要的特征,并选择了一些重要的特征。
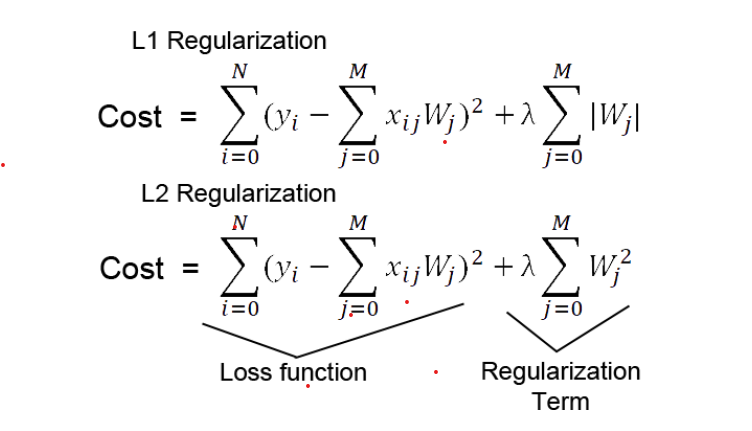
L2 正则化(或岭回归)随着模型复杂性的增加而惩罚模型。正则化参数 (lambda) 惩罚除截距之外的所有参数,以便模型泛化数据并且不会过拟合。
岭回归将系数的平方幅度作为惩罚项添加到损失函数中。当 lambda 值为零时,它变得类似于 OLS。虽然 lambda 很大,但惩罚会太大,导致欠拟合。
此外,岭回归将系数推向更小的值,同时保持非零权重和非稀疏解。由于损失函数中的平方项破坏了使 L2 对异常值敏感的异常值残差,惩罚项试图通过惩罚权重来纠正它。
当所有输入特征以大致相等的大小影响输出时,岭回归表现更好。此外,岭回归还可以学习复杂的数据模式。
什么是 R 方?
R Square 是一种统计量度,显示数据点与拟合回归线的接近程度。它计算由线性模型计算的预测变量变化的百分比。

R-Square 的值介于 0% 和 100% 之间,其中 0 表示模型无法解释预测值在其均值附近的变化。此外,100% 表示该模型可以解释输出数据在其均值附近的整体可变性。
简而言之,R-Square 值越高,模型对数据的拟合越好。
调整后的 R 平方
R 方度量有一些缺点,我们也将在这里解决。
问题是,如果我们在模型中添加垃圾自变量或重要自变量或有影响的自变量,R-Squared 值将始终增加。它永远不会随着新的自变量添加而减少,无论它可能是有影响的、无影响的还是无关紧要的变量。因此,我们需要另一种方法来测量等效 R 方,这会用任何垃圾自变量来惩罚我们的模型。
因此,我们在通用 R 平方公式中通过更好的调整来计算调整后的 R 平方。

什么是均方误差?
均方误差告诉我们回归线与一组数据点的接近程度。它计算从数据点到回归线的距离并将这些距离平方。这些距离是模型对预测值和实际值的误差。
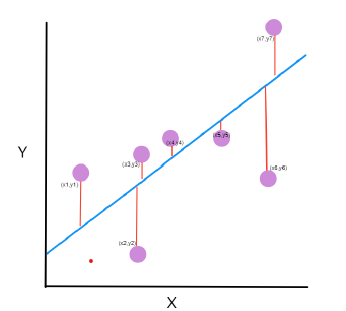
线性方程为 y = MX+C
M是斜率,C是截距系数。目标是找到 M 和 C 的值以最适合数据并最小化误差。
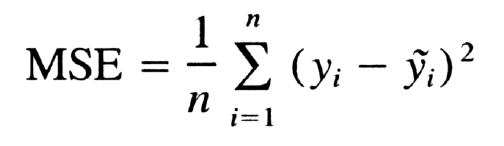
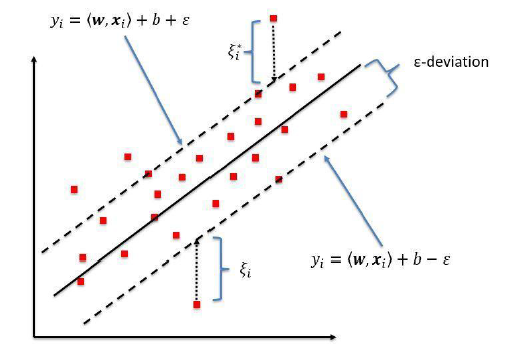
为什么支持向量回归?SVR和简单回归模型的区别?
简单回归模型的目标是最小化错误率,而 SVR 试图将错误拟合到某个阈值。
主要概念:
- 边界
- 核心
- 支持向量
- 超平面
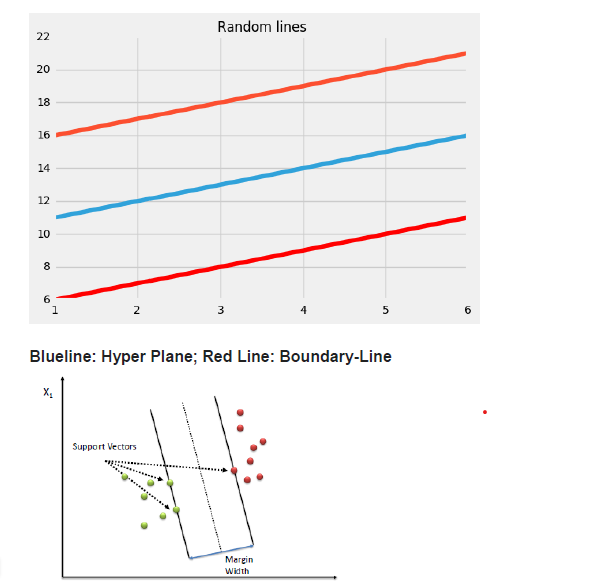
最佳拟合线是其上具有最大点数的线。SVR 尝试在距基本超平面 'e' 的距离处计算决策边界,以使数据点最接近该超平面,并且支持向量位于该边界线内。
结论
我们已经介绍了一些关于线性回归的基本数据科学面试问题。您可能会在入门级工作的面试中遇到这些问题中的任何一个。本文的一些关键要点如下:
- 普通最小二乘技术估计未知系数并依赖于最小化残差。
- L1 和 L2 正则化分别用系数值的绝对值和平方来惩罚损失函数。
- R 平方值表示响应围绕其平均值的变化。
- R-square 有一些缺点,为了克服这些缺点,我们使用调整后的 R-Square。
- 均方误差计算回归线上的点与数据点之间的距离。
- SVR 将误差拟合在某个阈值内,而不是将其最小化。
但是,一些面试官可能会更深入地研究任何问题。如果您想深入研究这些概念的数学,请随时发表评论或在此处与我联系。我将尝试在任何进一步的数据科学面试问题文章中解释这一点。
原文标题:Data Science Interview Series: Part-1
原文作者:Kavish111
原文地址:https://www.analyticsvidhya.com/blog/2022/06/data-science-interview-series-part-1/
