




Part 1:从库延迟越来越大,数据库怎么了?
有一天突然收到告警系统报某某从库的延迟大于200秒,通过查看监控趋势图,发现监控系统显示Seconds_Behind_Master的值突然升高到超过200(PS:目前业界有采用Seconds_Behind_Master的值来监控延迟,定时采集数据上报给监控系统(open-falcon或zabbix等),监控系统根据阈值或者趋势,分析发现主从复制延迟问题)。确定是主从复制出现延迟了,赶忙登录数据库,执行show slave status和show processlist,执行结果如下所示:
mysql> show slave status\G*************************** 1. row ***************************Slave_IO_State: Waiting for master to send eventMaster_Host: xxx.xxx.xxx.xxxMaster_User: replMaster_Port: 13307Connect_Retry: 60Master_Log_File: mysql-bin.000006Read_Master_Log_Pos: 304804759Relay_Log_File: mysql-relay-bin.000004Relay_Log_Pos: 57925450Relay_Master_Log_File: mysql-bin.000006Slave_IO_Running: YesSlave_SQL_Running: YesReplicate_Do_DB:Replicate_Ignore_DB:Replicate_Do_Table:Replicate_Ignore_Table:Replicate_Wild_Do_Table:Replicate_Wild_Ignore_Table:Last_Errno: 0Last_Error:Skip_Counter: 0Exec_Master_Log_Pos: 57925237Relay_Log_Space: 304805432Until_Condition: NoneUntil_Log_File:Until_Log_Pos: 0Master_SSL_Allowed: NoMaster_SSL_CA_File:Master_SSL_CA_Path:Master_SSL_Cert:Master_SSL_Cipher:Master_SSL_Key:Seconds_Behind_Master: 1749Master_SSL_Verify_Server_Cert: NoLast_IO_Errno: 0Last_IO_Error:Last_SQL_Errno: 0Last_SQL_Error:Replicate_Ignore_Server_Ids:Master_Server_Id: 12713307Master_UUID: fe3729d3-5d01-11e9-b003-061b88000461Master_Info_File: mysql.slave_master_infoSQL_Delay: 0SQL_Remaining_Delay: NULLSlave_SQL_Running_State: Waiting for Slave Workers to free pending eventsMaster_Retry_Count: 86400Master_Bind:Last_IO_Error_Timestamp:Last_SQL_Error_Timestamp:Master_SSL_Crl:Master_SSL_Crlpath:Retrieved_Gtid_Set: fe3729d3-5d01-11e9-b003-061b88000461:1-100371Executed_Gtid_Set: fe3729d3-5d01-11e9-b003-061b88000461:1-27Auto_Position: 1Replicate_Rewrite_DB:Channel_Name:Master_TLS_Version:
mysql> show processlist\G;*************************** 1. row ***************************Id: 2User: rootHost: localhost:59853db: NULLCommand: QueryTime: 0State: startingInfo: show processlist*************************** 2. row ***************************Id: 21User: system userHost:db: NULLCommand: ConnectTime: 4095State: Waiting for master to send eventInfo: NULL*************************** 3. row ***************************Id: 56User: system userHost:db: NULLCommand: ConnectTime: 2State: Slave has read all relay log; waiting for more updatesInfo: NULL*************************** 4. row ***************************Id: 57User: system userHost:db: wxlCommand: ConnectTime: 1613State: altering tableInfo: alter table t1 add names2 varchar(1000) not null*************************** 5. row ***************************Id: 58User: system userHost:db: NULLCommand: ConnectTime: 1344State: Waiting for an event from CoordinatorInfo: NULL......19 rows in set (0.00 sec)
从slave status的结果中可以看出来Seconds_Behind_Master的值越来越大,Executed_Gtid_Set的值确一直卡在fe3729d3-5d01-11e9-b003-061b88000461:1-27,说明MySQL一直在回放这个gtid对应的事务。通过processlist的结果可以看出一直在做alter table 加字段操作,执行时间1613秒。
发现导致延迟的原因后,那么问题来了:
1、Seconds_Behind_Master的含义,为啥可以用来监控延迟?
2、有哪些情况会导致延迟?
3、MySQL是如何计算复制延迟的,这样的计算是否准确?
4、有没有更精确延迟监控方式?
按照官方文档的解释,Seconds_Behind_Master表示从机和主机之间的延迟,当从机正在主动应用主上的binlog时,此字段显示从机上当前时间戳与当前正在回放处理的事件上记录的原始时间戳(主机执行时间)之间的差异。Seconds_Behind_Master的值有NULL、>=0。在MySQL5.7中如果从机的SQL线程没有运行,或者SQL线程已经消耗了所有relay log且从机的IO线程没有运行,则此字段为NULL(未定义或未知),在之前的版本中,如果从机的SQL线程或者IO线程没有运行或没有连接到主机,则此字段为NULL。通过官方解释的我们可以看出Seconds_Behind_Master是可以反应当前主从之间事务执行的时间差,所以可以用来监控延迟。
接下来让我们来一一分析后面的几个问题。
Part 2:导致从库复制延迟的原因探索
先简单回顾下主从复制的知识点:
MySQL主从复制涉及到三个线程,一个运行在master(dump线程)上、另外两个(IO线程,SQL线程)运行在salve,如下图所示:
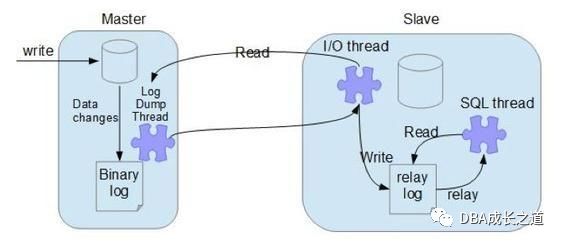
在master上把数据更改记录到binlog后,dump线程会读取master上binlog中的事件,通过网络发送给slave的I/O线程,I/O线程收到binlog 事件后会记录到中继日志中,SQL线程读取中继日志中的事件,进行回放。
了解基本的复制过程,下面来简单说明下可能导致复制延迟的几个原因:
1)网络问题
网络不稳定可能导致主从延迟的问题,比如主机或者从机的带宽打满、主从之间网络延迟很大,有可能会导致主上的binlog没有全量传输到从机,从而造成延迟。
2)机器性能
主从机器的性能差别较大,例如相同的SQL在主上执行可能只需要1s,在从机就需要1.25s。
从机高负载?有很多业务会在从机上做统计,把从机跑的高负载,从而造成从机延迟很大的情况,这种使用top命令即可快速发现。
从机磁盘有问题?磁盘、raid卡、调度策略有问题的情况下,有的时候会出现单个IO延迟很高的情况,比如raid卡电池充放电的时候,在没有设置强行write back的情况下得会将write back模式修改为write through。使用iostat命令查看DB数据盘的IO情况,是否是单个IO的执行时间很长,块大小和磁盘队列情况等。
3)大事务
是否是经常会有大事务?如执行带有大量的delete操作又或者一个表的alter操作等,都会导致延迟情况的发生。这种通过查看processlist相关信息以及使用mysqlbinlog查看binlog中的SQL就能快速进行确认。Part 1中遇到的问题就是执行了alter table这类的大事务导致的问题。
4)业务写入读取频繁
当主库的TPS并发较高时,产生的DML数量超过slave的l线程所能承受的范围时也会出现复制延迟问题(MySQL从5.6开始才支持多线程复制[或者叫并行复制])。
除了上述说的四个原因外,还有复制报错中断、主库和从库的参数配置不一样、从库执行备份操作导致压力过大、表上无主键的情况、从库设置了延迟复制等因素。
Part 3:延迟计算方式和影响延迟计算准确性的因素
主备同步过程如下,主库更新产生binlog, 备库io线程拉取主库binlog生成relay log。备库sql线程回放relay log从而保持和主库同步。
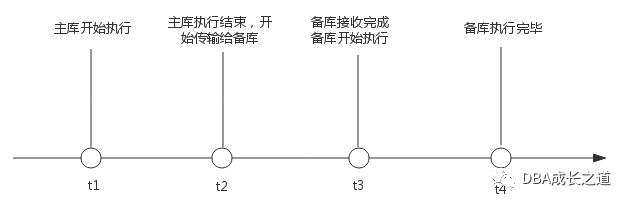
理论上主库有更新时,备库都存在延迟,且延迟时间为备库执行时间+网络传输时间即从库执行完毕时间-主库执行结束时间(t4-t2)。
那么在MySQL是如何从库延迟Seconds_Behind_Master的?
我们先来看下Seconds_Behind_Master的伪代码:
if (SQL thread is running){if (SQL thread processed all the available relay log){if (IO thread is running)print 0;elseprint NULL;}elsecompute Seconds_Behind_Master;}elseprint NULL;
从伪代码中可以看出来:
1、SQL线程没有运行,或者SQL线程已经消耗了所有relay log且从机的IO线程没有运行,此字段为NULL。
2、当SQL线程应用完所有relay log并且IO线程仍在运行的情况下,Seconds_Behind_Master=0。
3、只有在SQL线程和IO线程同时运行的时候,且不满足2中条件时,Seconds_Behind_Master的值会计算。
Seconds_Behind_Master计算的源码实现如下:
//判断SQL线程运行是否正常if (mi->rli->slave_running){/*判断io线程拉取的主库最大文件名和位置与SQL线程当前执行的文件和位置是否一致(Master_Log_File=Relay_Master_Log_File 和Read_Master_Log_Pos=Exec_Master_Log_Pos),即SQL线程是否处理了所有可用的中继日志。*/if ((mi->get_master_log_pos() == mi->rli->get_group_master_log_pos()) &&(!strcmp(mi->get_master_log_name(), mi->rli->get_group_master_log_name()))){//SQL线程处理了所有可用的中继日志后判断io线程是否正常,正常则将Seconds_Behind_Master设置为0,否则设置为NULL。if (mi->slave_running == MYSQL_SLAVE_RUN_CONNECT)protocol->store(0LL);elseprotocol->store_null();}else{long time_diff= ((long)(time(0) - mi->rli->last_master_timestamp)- mi->clock_diff_with_master);/*当计算后的time_diff如果小于0或者位不可能的值(1970的时间戳)的话,将值修改为0,确保Seconds_Behind_Master不会有负数。在某些系统上,可能会出现时间差可以小于0,原因如下:1、在级联复制的情况下,当前的主是另外一个主的从,相对于binlog中记录的事务的真正执行时间可能差距较大。2、在主上显示的使用set timestamp更改了时间戳3、与粒度到秒的时间函数有关(与MySQL本身无关),如:假设主从的时间完全同步,在从机连接到主机的时候,会先读取主机的时间戳(假设为1),并且很短的时候后接着读取从机的时间戳(假设为2)。在线上slave status时,假设slave当前的时间戳和rli->last_master_timestamp之间的差为0(即它们在同一秒内),则最后得到的Seconds_Behind_Master=0-(2-1)=-1,这会迷惑用户。last_master_timestamp == 0(1970年这个不可能的时间戳)是一个特殊标记,表示为“复制已经赶上了”。*/protocol->store((longlong)(mi->rli->last_master_timestamp ?max(0L, time_diff) : 0));}}else{//SQL线程未运行的情况下,将Seconds_Behind_Master设置成NULLprotocol->store_null();}
通过源码我们的得出Seconds_Behind_Master=丛库的当前时间(time(0))- 主库执行binlog事件的时间(last_master_timestamp)-主从库之间的时间差(clock_diff_with_master)。
clock_diff_with_master:
io线程启动时会向主库发送sql语句“SELECT UNIX_TIMESTAMP()”,获取主库当前时间,然而用从库当前时间减去此时间或者主从时间差值即为clock_diff_with_master。这里如果有用户中途修改了主库系统时间或修改了timestamp变量的值以及在级联复制情况下(当前的主是另外一个主的从,两个机器时间不一致),那么计算出从库延迟时间就是不准确的。
last_master_timestamp:
表示主库执行binlog事件的时间。此时间在并行复制和非并行复制时的计算方法是不同的。
接下来分别看下并行复制和非并行复制时,last_master_timestamp的值分别是什么?
1)非并行复制:
从库sql线程读取了relay log中的事件,事件未执行之前就会更新last_master_timestamp,这里时间的更新是以事件为单位。
情况一:/*Even if we don't execute this event, we keep the master timestamp,so that seconds behind master shows correct delta (there are eventsthat are not replayed, so we keep falling behind).If it is an artificial event, or a relay log event (IO thread generatedevent) or ev->when is set to 0, or a FD from master, or a heartbeatevent with server_id '0' then we don't update the last_master_timestamp.In case of parallel execution last_master_timestamp is only updated whena job is taken out of GAQ. Thus when last_master_timestamp is 0 (whichindicates that GAQ is empty, all slave workers are waiting for events fromthe Coordinator), we need to initialize it with a timestamp from the firstevent to be executed in parallel.*/if ((!rli->is_parallel_exec() || rli->last_master_timestamp == 0) &&!(ev->is_artificial_event() || ev->is_relay_log_event() ||(ev->common_header->when.tv_sec == 0) ||ev->get_type_code() == binary_log::FORMAT_DESCRIPTION_EVENT ||ev->server_id == 0)){rli->last_master_timestamp= ev->common_header->when.tv_sec +(time_t) ev->exec_time;DBUG_ASSERT(rli->last_master_timestamp >= 0);}情况二:另外一种情况是sql线程在等待io线程获取binlog时,会将last_master_timestamp设为0,按上面的算法Seconds_Behind_Master为0,此时任务备库是没有延迟的。if (!rli->is_parallel_exec())rli->last_master_timestamp= 0;
ev->when.tv_sec表示事件的开始时间。exec_time指事件在主库的执行时间,只有Query_log_event和Load_log_event才会统计exec_time。
2)并行复制:
并行复制有一个分发队列GAQ,sql线程将binlog事务读取到GAQ,然后再分发给worker线程执行。并行复制时,binlog事件是并发穿插执行的,GAQ中有一个checkpoint点称为lwm, lwm之前的binlog都已经执行,而lwm之后的binlog有些执行有些没有执行(并行复制详细知识自查,本文不做过多说明)。
并行复制更新GAQ checkpiont时,会推进lwm点,同时更新last_master_timestamp为lwm所在事务结束的event(从机work队列的第一个作业)的时间。因此,并行复制是在事务执行完成后才更新last_master_timestamp,更新是以事务为单位。同时更新GAQ checkpiont还受slave_checkpoint_period参数(MySQL5.7.25中slave_checkpoint_period默认是300毫秒)的影响。
另外当sql线程等待io线程时且GAQ 队列为空时,会将last_master_timestamp设为0。同样此时认为没有延迟,计算得出seconds_Behind_Master为0。
last_master_timestamp= new_ts;new_ts的计算方式:/*更新rli->last_master_timestamp,如果gaq为空,则将其设置为零。否则,用从机work队列的第一个作业的时间戳更新它。它是在log_event::get_slave_worker()函数中分配的。*/ts= rli->gaq->empty()? 0: reinterpret_cast<Slave_job_group*>(rli->gaq->head_queue())->ts;rli->reset_notified_checkpoint(cnt, ts, need_data_lock, true);
从上面的说明可以看出Seconds_Behind_Master计算延迟是不够准确,可能会受以下因素影响:
1、如果有用户中途修改了主库系统时间或修改了timestamp变量以及在级联复制情况下(当前的主是另外一个主的从,两个机器时间不一致),会影响clock_diff_with_master的值,那么计算出备库延迟时间就是不准确的。
2、如果网络状况特别差,导致sql线程需等待io线程的情况(主上binlog没有发送到从上),那么这两个位点可能相等,会导致误认为延迟为0。
3、last_master_timestamp这个时间在并行复制和非并行复制时的计算方法是不同的。
part 4:更精确延迟监控方式
下面简单给大家介绍两种更精确的延迟监控方式:
1、使用第三工具pt-hearbeat
监控原理:
在 master 中建一个 heartbeat 表,其中有一个 时间戳 字段,pt-heartbeat 会周期性的修改时间戳的值。
slave 会复制 heartbeat表,其中就包含了 master执行修改动作的时间戳,对其和 slave 的本地时间进行对比,得到一个差值,就是复制延迟的值,从而判断复制状态是否正常,以及延迟时间是否符合预期。但是这样的监控方式有个缺点,就是要判断实例的主从关系,避免在从上写入。
2、通过GTID或Postion位点
从主上获取master的GTID 位点Executed_Gtid_Set,在从上获取GTID位点Executed_Gtid_Set,进行计算得出主从相差多少个gtid事务。
例如Part 1中看到的:延迟事务个数=fe3729d3-5d01-11e9-b003-061b88000461:1-100371-fe3729d3-5d01-11e9-b003-061b88000461:1-27=100371-27=100344个事务。
上述所讲的几个延迟监控方式都隐含着一个问题,监控数据的采集频率,如果频率过低,会导致可能发现不了最大位数据获取间隔的延迟情况。采集频率过高,会为MySQL实例带来性能损耗。这个频率的取值需要根据业务重要性、性能、监控发现粒度多方面考虑,这里不做过多说明。
总结
1、导致复制延迟的原因有:
网络、机器性能、大事务、业务写入读取频繁、复制报错中断、主库和从库的参数配置不一样、从库执行备份操作导致压力过大、表上无主键的情况、从库设置了延迟复制等因素。
2、Seconds_Behind_Master=当前时间(time(0))- 表示主库执行binlog事件的时间(last_master_timestamp)-主备库之间的时间差(clock_diff_with_master)
3、并行复制是在在事务执行完成后才更新last_master_timestamp,更新是以事务为单位。而非并行复制是在event未执行之前就会更新last_master_timestamp,这里时间的更新是以event为单位。所以并行复制和非并行复制下看到Seconds_Behind_Master可能不一样。
4、Seconds_Behind_Master计算延迟在有些情况下是不够准确。
用户中途修改了主库系统时间或修改了timestamp变量。
网络状况特别差,导致sql线程需等待io线程的情况
并行复制和非并行复制时计算方式不一致导致延迟不准确。
5、更精确的延迟监控方式:
使用第三工具pt-hearbeat、通过GTID或Postion位点
6、上述的三种监控延迟的方式都存在监控数据的采集频率的问题。
注意:预知延迟优化解决方案,敬请期待下一篇(只要努力就为时不晚,趁春光正好,一定要追到主库)
参考资料
官方文档:https://dev.mysql.com/doc/refman/5.7/en/show-slave-status.html
备库Seconds_Behind_Master计算 https://blog.csdn.net/huyi91/article/details/77529838
