




显然,连接操作需要定义左、右两张动态表,左表沿用上一篇的学生得分记录的score_info数据集:
| name | score |
| Tom | 12 |
| John | 15 |
| Tom | 18 |
| Tom | 19 |
右表采用学生信息的student_info数据集:
| name | age |
| Tom | 8 |
| John | 9 |
此次主要考察Innner Join和Left Join两种连接方式的输出行为,通过左表在name上连接右表得到带有学生信息的得分数据。然而,得分记录和学生信息的发送顺序是不定的。
-- 1.inner join时的SQL代码select t1.name as name,t2.age as age,t1.score as scorefrom(select name,scorefrom score_info) as t1INNER JOIN(select name,agefrom student_info) as t2on t1.name = t2.name-- 2.left join时的SQL代码select t1.name as name,t2.age as age,t1.score as scorefrom(select name,scorefrom score_info) as t1LEFT JOIN(select name,agefrom student_info) as t2on t1.name = t2.name
普通连接操作在Flink中对应的StreamExecNode的实现类为StreamExecJoin类,Transformation、Operator、Function的生成逻辑在其内部的translateToPlanInternal方法中。
protected Transformation<RowData> translateToPlanInternal(PlannerBase planner) {// 得到左、右表的两个输入边final ExecEdge leftInputEdge = getInputEdges().get(0);final ExecEdge rightInputEdge = getInputEdges().get(1);final Transformation<RowData> leftTransform =(Transformation<RowData>) leftInputEdge.translateToPlan(planner);final Transformation<RowData> rightTransform =(Transformation<RowData>) rightInputEdge.translateToPlan(planner);final RowType leftType = (RowType) leftInputEdge.getOutputType();final RowType rightType = (RowType) rightInputEdge.getOutputType();...// 获取连接键final int[] leftJoinKey = joinSpec.getLeftKeys();final int[] rightJoinKey = joinSpec.getRightKeys();...// 采用Code生成判断关联条件的Function源代码GeneratedJoinCondition generatedCondition =JoinUtil.generateConditionFunction(tableConfig, joinSpec, leftType, rightType);long minRetentionTime = tableConfig.getMinIdleStateRetentionTime();AbstractStreamingJoinOperator operator;// 获取连接类型FlinkJoinType joinType = joinSpec.getJoinType();// 根据连接类型生成不同的Operatorif (joinType == FlinkJoinType.ANTI || joinType == FlinkJoinType.SEMI) {// Flink 1.13版本中并没有实现Anti与Semi连接,这里不再研究...} else {// 生成内/外连接的Operatorboolean leftIsOuter = joinType == FlinkJoinType.LEFT || joinType == FlinkJoinType.FULL;boolean rightIsOuter =joinType == FlinkJoinType.RIGHT || joinType == FlinkJoinType.FULL;operator =new StreamingJoinOperator(leftTypeInfo,rightTypeInfo,generatedCondition,leftInputSpec,rightInputSpec,leftIsOuter,rightIsOuter,joinSpec.getFilterNulls(),minRetentionTime);}final RowType returnType = (RowType) getOutputType();// 创建的Transformation对象类型是具有两个上游输入的TwoInputTransformationfinal TwoInputTransformation<RowData, RowData, RowData> transform =new TwoInputTransformation<>(leftTransform,rightTransform,getDescription(),operator,InternalTypeInfo.of(returnType),leftTransform.getParallelism());// set KeyType and Selector for stateRowDataKeySelector leftSelect =KeySelectorUtil.getRowDataSelector(leftJoinKey, leftTypeInfo);RowDataKeySelector rightSelect =KeySelectorUtil.getRowDataSelector(rightJoinKey, rightTypeInfo);transform.setStateKeySelectors(leftSelect, rightSelect);transform.setStateKeyType(leftSelect.getProducedType());return transform;}
浏览整个创建过程,可以提炼出以下三点信息:
1.Join操作产生的执行图上有两个上游输入节点,对应连接的左、右两张表。
// 处理左表输入记录public void processElement1(StreamRecord<RowData> element) throws Exception {processElement(element.getValue(), leftRecordStateView, rightRecordStateView, true);}// 处理右表输入记录public void processElement2(StreamRecord<RowData> element) throws Exception {processElement(element.getValue(), rightRecordStateView, leftRecordStateView, false);}
private void processElement(RowData input,JoinRecordStateView inputSideStateView,JoinRecordStateView otherSideStateView,boolean inputIsLeft)throws Exception {// 根据输入侧标识得到每一侧表是否为外连接。boolean inputIsOuter = inputIsLeft ? leftIsOuter : rightIsOuter;boolean otherIsOuter = inputIsLeft ? rightIsOuter : leftIsOuter;boolean isAccumulateMsg = RowDataUtil.isAccumulateMsg(input);...// 获取对侧输入记录能被连接记录AssociatedRecords associatedRecords =AssociatedRecords.of(input, inputIsLeft, otherSideStateView, joinCondition);// 上游仅追加记录的处理过程if (isAccumulateMsg) {// 处理输入侧是外连接的情况if (inputIsOuter) {// 这里需要先将输入侧的记录状态转为外连接记录状态的类型OuterJoinRecordStateView inputSideOuterStateView =(OuterJoinRecordStateView) inputSideStateView;// 如果对侧还没有能被连接的记录,则对侧先用null填充,并输出if (associatedRecords.isEmpty()) {outRow.setRowKind(RowKind.INSERT);outputNullPadding(input, inputIsLeft);inputSideOuterStateView.addRecord(input, 0);// 对侧能被连接的情形} else {// 如果对侧是外连接,并且还没有被连接到过,则需要先撤销之前输出采用null填充的结果。if (otherIsOuter) {OuterJoinRecordStateView otherSideOuterStateView =(OuterJoinRecordStateView) otherSideStateView;for (OuterRecord outerRecord : associatedRecords.getOuterRecords()) {RowData other = outerRecord.record;if (outerRecord.numOfAssociations == 0) {outRow.setRowKind(RowKind.DELETE);outputNullPadding(other, !inputIsLeft);}otherSideOuterStateView.updateNumOfAssociations(other, outerRecord.numOfAssociations + 1);}}// 然后输出关联到的结果集outRow.setRowKind(RowKind.INSERT);for (RowData other : associatedRecords.getRecords()) {output(input, other, inputIsLeft);}// 向输入侧记录状态添加当前输入记录以及关联到记录的数目inputSideOuterStateView.addRecord(input, associatedRecords.size());}// 输入侧不是外连接的处理过程} else {// 向输入侧记录状态添加当前输入记录inputSideStateView.addRecord(input);// 能被连接的记录非空才产生输出if (!associatedRecords.isEmpty()) {// 如果对侧是外连接,与之前的处理过程类似if (otherIsOuter) {OuterJoinRecordStateView otherSideOuterStateView =(OuterJoinRecordStateView) otherSideStateView;for (OuterRecord outerRecord : associatedRecords.getOuterRecords()) {if (outerRecord.numOfAssociations== 0) {outRow.setRowKind(RowKind.DELETE);outputNullPadding(outerRecord.record, !inputIsLeft);}otherSideOuterStateView.updateNumOfAssociations(outerRecord.record, outerRecord.numOfAssociations + 1);}outRow.setRowKind(RowKind.INSERT);} else {outRow.setRowKind(inputRowKind);}// 输出结果for (RowData other : associatedRecords.getRecords()) {output(input, other, inputIsLeft);}}}} else {// 不研究上游有撤回的情况...}}
1.根据输入参数,判断输入侧、对侧的连接是否为外连接。
3.连接两侧记录,输出结果。
(2)如果输入侧为内连接,则能关联到对侧记录才能输出结果,如果对侧曾经输出过缺省结果,则与(1)中处理方式相同。
1.输入侧为外连接时,如果连接不到对侧的记录,会输出缺省值;而内连接不会进行输出。当能连接到时,二者会输出当前记录的连接结果。
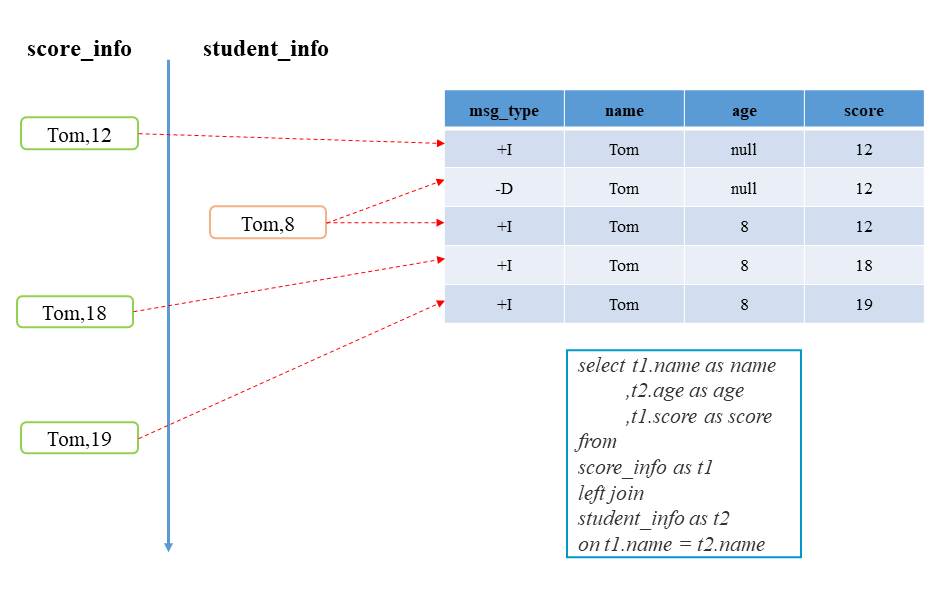
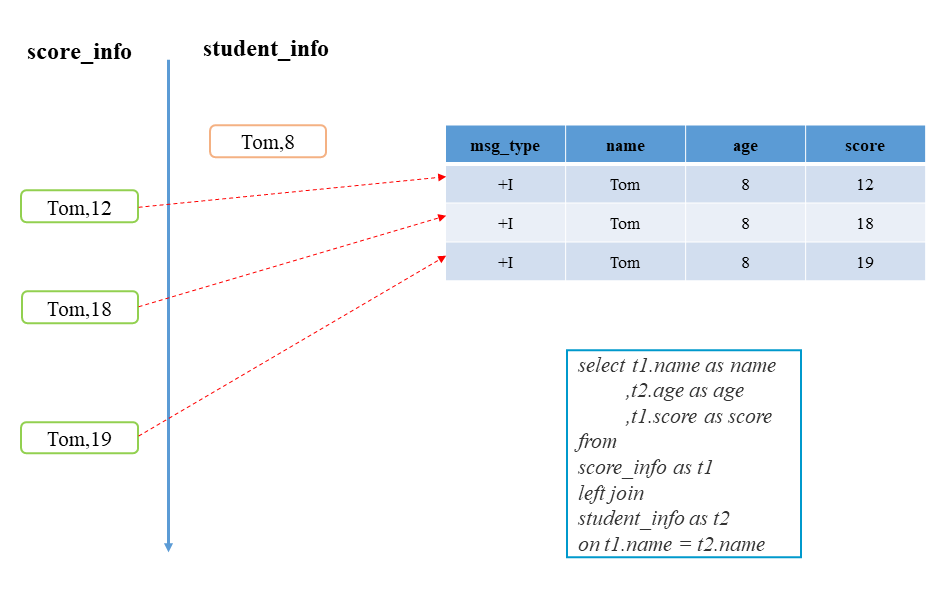
本节将会通过普通连接中输入记录的存取来介绍Flink的状态管理。其实在前一篇介绍分组聚合操作的内容中,状态存储碍于篇幅限制并没有被深入探讨,其问题在于同一个Task会处理多个分组键或连接键的记录,那么当处理某一条记录时,Task如何获取到相同键的状态。
private void processElement(RowData input,JoinRecordStateView inputSideStateView,JoinRecordStateView otherSideStateView,boolean inputIsLeft)throws Exception {...// 获取对侧输入记录能被连接记录AssociatedRecords associatedRecords =AssociatedRecords.of(input, inputIsLeft, otherSideStateView, joinCondition);...}
public static AssociatedRecords of(RowData input,boolean inputIsLeft,JoinRecordStateView otherSideStateView,JoinCondition condition)throws Exception {List<OuterRecord> associations = new ArrayList<>();// 如果状态视图类型是外连接,则连接条件成立的同时还需要获得对侧输入是否被连接的次数if (otherSideStateView instanceof OuterJoinRecordStateView) {OuterJoinRecordStateView outerStateView =(OuterJoinRecordStateView) otherSideStateView;Iterable<Tuple2<RowData, Integer>> records =outerStateView.getRecordsAndNumOfAssociations();for (Tuple2<RowData, Integer> record : records) {boolean matched =inputIsLeft? condition.apply(input, record.f0): condition.apply(record.f0, input);if (matched) {associations.add(new OuterRecord(record.f0, record.f1));}}} else {Iterable<RowData> records = otherSideStateView.getRecords();for (RowData record : records) {boolean matched =inputIsLeft? condition.apply(input, record): condition.apply(record, input);if (matched) {// use -1 as the default number of associationsassociations.add(new OuterRecord(record, -1));}}}return new AssociatedRecords(associations);}
public Iterable<RowData> getRecords() throws Exception {return new IterableIterator<RowData>() {// 从状态中获取迭代器对象private final Iterator<Map.Entry<RowData, Integer>> backingIterable =recordState.entries().iterator();...};}
public interface MapState<UK, UV> extends State {...Iterable<Map.Entry<UK, UV>> entries() throws Exception;...}
public Iterable<Map.Entry<UK, UV>> entries() {// 从状态表中获取当前状态的MapMap<UK, UV> userMap = stateTable.get(currentNamespace);return userMap == null ? Collections.emptySet() : userMap.entrySet();}
public S get(N namespace) {return get(keyContext.getCurrentKey(), keyContext.getCurrentKeyGroupIndex(), namespace);}// 真正调用的方法private S get(K key, int keyGroupIndex, N namespace) {checkKeyNamespacePreconditions(key, namespace);StateMap<K, N, S> stateMap = getMapForKeyGroup(keyGroupIndex);if (stateMap == null) {return null;}// 根据键、命名空间获取键控状态return stateMap.get(key, namespace);}
| key | value |
| Tom | (Tom,12) |
| Tom | (Tom,18) |
| Tom | (Tom,19) |
private static <T> void processRecord1(StreamRecord<T> record, TwoInputStreamOperator<T, ?, ?> streamOperator)throws Exception {// 设置当前记录的键streamOperator.setKeyContextElement1(record);streamOperator.processElement1(record);}private static <T> void processRecord2(StreamRecord<T> record, TwoInputStreamOperator<?, T, ?> streamOperator)throws Exception {// 设置当前记录的键streamOperator.setKeyContextElement2(record);streamOperator.processElement2(record);}
当然,这些关于状态的内容只是Flink状态管理机制的冰山一角,但对于研究Flink SQL的计算过程已经够用了。
2.探讨了输入侧和对侧在内、外连接的特性和输出行为,讨论了两侧不同输入顺序时的输出差异。
3.简要介绍了Flink SQL中使用的状态管理机制。
Flink SQL算子篇持续更新中,敬请期待!
