




1:讲讲flink checkpoint原理?对齐式和非对齐式checkpoint有什么区别?
checkpoint作用?
保证Flink集群在某个算子因为某些原因(如异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。checkpoint是一种容错恢复机制
checkpoint保存的是什么数据?
当前检查点开始时数据源(例如Kafka)中消息的offset。
记录了所有有状态的operator当前的状态信息(例如sum中的数值)。
checkpoint的执行流程?
1:Checkpoint Coordinator 周期性的向所有 source 节点 trigger Checkpoint;
2:source 节点向下游广播 barrier,这个 barrier 就是实现 Chandy-Lamport 分布式快照算法的核心,下游的 task 只有收到所有 input 的 barrier 才会执行相应的 Checkpoint
3:当 task 完成 state 备份后,会将备份数据的地址(state handle)通知给 Checkpointcoordinator
4:下游的 sink 节点收集齐上游两个 input 的 barrier 之后,会执行本地快照,这里特地展示了 RocksDB incremental Checkpoint 的流程,首先 RocksDB 会全量刷数据到磁盘上(红色大三角表示),然后 Flink 框架会从中选择没有上传的文件进行持久化备份(紫色小三角)。同样的,sink 节点在完成自己的 Checkpoint 之后,会将 state handle 返回通知 Coordinator
5:最后,当 Checkpoint coordinator 收集齐所有 task 的 state handle,就认为这一次的 Checkpoint 全局完成了,向持久化存储中再备份一个 Checkpoint meta 文件
barrier对齐和非对齐的区别?
checkpoint底层逻辑是通过插入序号单调递增的barrier,把无界的数据流划分成逻辑上的数据段,并通过段落标记barrier 来为这些数据段,加持'事务’特性:
每一段数据流要么被完整成功处理;
要么回滚一切不完整的影响(状态变化)
最终需要保证:快照在各个算子间的状态必须统一(必须是经过了相同数据的影响之后的状态值)
barrier对齐与barrier不对齐区别在于:
不对齐:at least once 最少一次,消息不会丢失,但是可能会重复
对齐:exactly once 精确一次性,但是处理性能会降低。
2:讲讲watermark工作机制?
watermark的意义:
标识 Flink 任务的事件时间进度,从而能够推动事件时间窗口的触发、计算。
解决事件时间窗口的乱序问题。
watermark的触发时机:
1:watermark时间 >= window_end_time 即max(timestamp, currentMaxTimestamp....)-allowedLateness >= window_end_time
2:在[window_start_time,window_end_time)中有数据存在
乱序处理可归纳为:
窗口window 的作用是为了周期性的获取数据。
watermark的作用是防止数据出现乱序(经常),事件时间内获取不到指定的全部数据,而做的一种保险方法。
allowLateNess是将窗口关闭时间再延迟一段时间。
sideOutPut是最后兜底操作,所有过期延迟数据,指定窗口已经彻底关闭了,就会把数据放到侧输出流。
watermark的分类:
flink1.10以前有以下两种:
方式一:AssignerWithPeriodicWatermarks【1.10及以前的版本,建议使用这种方式】
周期性水位线
周期性的生成 watermark,默认周期是200ms,也可以通过setAutoWatermarkInterval设置周期时间
常用的实现类是:BoundedOutOfOrdernessTimestampExtractor(延时时间)
方式二:AssignerWithPunctuatedWatermarks:
标点水位线
阶段性的生成 watermark,即每来一条数据就生成一个wartermark。这种方式下,窗口的触发与时间无关,而是决定于何时收到标记事件。在实际的生产中Punctuated方式在TPS很高的场景下会产生大量的Watermark,在一定程度上对下游算子造成压力,所以只有在实时性要求非常高的场景才会选择Punctuated的方式进行Watermark的生成。
flink1.11.0及版本以上推荐使用:WatermarkStrategy
方式一:固定乱序长度策略(forBoundedOutOfOrderness)
通过调用WatermarkStrategy对象上的forBoundedOutOfOrderness方法来实现,接收一个Duration类型的参数作为最大乱序(out of order)长度。WatermarkStrategy对象上的withTimestampAssigner方法为从事件数据中提取时间戳提供了接口
一般使用这种策略
方式二:单调递增策略(forMonotonousTimestamps)
通过调用WatermarkStrategy对象上的forMonotonousTimestamps方法来实现,无需任何参数,相当于将forBoundedOutOfOrderness策略的最大乱序长度outOfOrdernessMillis设置为0。
方式三:不生成策略(noWatermarks)
WatermarkStrategy.noWatermarks()
注意点:
多并行度的条件下, 向下游传递WaterMark的时候, 总是以最小的那个WaterMark为准! 木桶原理!
数据源中的某一个分区/分片在一段时间内未发送事件数据,则意味着watermarkStrategy也不会获得任何数据去生成watermark,在这种情况下可以通过设置有一个空闲时间(withIdleness),当超过这个时间则将这个分片或分区标记为空闲状态。
watermark对齐参数:WatermarkStrategy .<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20)) .withWatermarkAlignment("alignment-group-1", Duration.ofSeconds(20), Duration.ofSeconds(1));
3:flink双流join?
1:flink window join
join()
通俗理解,将两条实时流中元素分配到同一个时间窗口中完成Join。两条实时流数据缓存在Window State中,当窗口触发计算时,执行join操作。(窗口对齐才会触发)
支持Tumbling Window Join (滚动窗口),Sliding Window Join (滑动窗口),Session Widnow Join(会话窗口),支持处理时间和事件时间两种时间特征。
源码核心总结:windows窗口 + state存储 + 双层for循环执行join()
val env = ...// kafka 订单流val orderStream = ...// kafka 订单明细流val orderDetailStream = ...orderStream.join(orderDetailStream).where(r => r._1) 订单id.equalTo(r => r._2) 订单id.window(TumblingProcessTimeWindows.of(Time.seconds(60))).apply {(r1, r2) => r1 + " : " + r2}.print()
coGroup()
coGroup的作用和join基本相同,但有一点不一样的是,如果未能找到新到来的数据与另一个流在window中存在的匹配数据,仍会将其输出。
只有 inner join 肯定还不够,如何实现 left/right outer join 呢?答案就是利用 coGroup() 算子。
它的调用方式类似于 join() 算子,也需要开窗,但是 CoGroupFunction 比 JoinFunction 更加灵活,
可以按照用户指定的逻辑匹配左流和/或右流的数据并输出。以下的例子就实现了点击流 left join 订单流的功能,是很朴素的 nested loop join 思想(二重循环)。
clickRecordStream.coGroup(orderRecordStream).where(record -> record.getMerchandiseId()).equalTo(record -> record.getMerchandiseId()).window(TumblingProcessingTimeWindows.of(Time.seconds(10))).apply(new CoGroupFunction<AnalyticsAccessLogRecord, OrderDoneLogRecord, Tuple2<String, Long>>() {@Overridepublic void coGroup(Iterable<AnalyticsAccessLogRecord> accessRecords, Iterable<OrderDoneLogRecord> orderRecords, Collector<Tuple2<String, Long>> collector) throws Exception {for (AnalyticsAccessLogRecord accessRecord : accessRecords) {boolean isMatched = false;for (OrderDoneLogRecord orderRecord : orderRecords) {右流中有对应的记录collector.collect(new Tuple2<>(accessRecord.getMerchandiseName(), orderRecord.getPrice()));isMatched = true;}if (!isMatched) {右流中没有对应的记录collector.collect(new Tuple2<>(accessRecord.getMerchandiseName(), null));}}}}).print().setParallelism(1);
2:Flink Interval Join
join() 和 coGroup() 都是基于窗口做关联的。但是在某些情况下,两条流的数据步调未必一致。例如,订单流的数据有可能在点击流的购买动作发生之后很久才被写入,如果用窗口来圈定,很容易 join 不上。所以 Flink 又提供了"Interval join"的语义,按照指定字段以及右流相对左流偏移的时间区间进行关联,即:
right.timestamp ∈ [left.timestamp + lowerBound; left.timestamp + upperBound]
interval join 也是 inner join,虽然不需要开窗,但是需要用户指定偏移区间的上下界,并且只支持事件时间。示例代码如下。注意在运行之前,需要分别在两个流上应用 assignTimestampsAndWatermarks() 方法获取事件时间戳和水印。interval join 与 window join 不同,是两个 KeyedStream 之上的操作,并且需要调用 between() 方法指定偏移区间的上下界。如果想令上下界是开区间,可以调用 upperBoundExclusive()/lowerBoundExclusive() 方法。
clickRecordStream.keyBy(record -> record.getMerchandiseId()).intervalJoin(orderRecordStream.keyBy(record -> record.getMerchandiseId())).between(Time.seconds(-30), Time.seconds(30)).process(new ProcessJoinFunction<AnalyticsAccessLogRecord, OrderDoneLogRecord, String>() {@Overridepublic void processElement(AnalyticsAccessLogRecord accessRecord, OrderDoneLogRecord orderRecord, Context context, Collector<String> collector) throws Exception {collector.collect(StringUtils.join(Arrays.asList(accessRecord.getMerchandiseId(),orderRecord.getPrice(),orderRecord.getCouponMoney(),orderRecord.getRebateAmount()), '\t'));}}).print().setParallelism(1);
3:Flinksql Regular Join
Regular Join 是最为基础的没有缓存剔除策略的 Join。Regular Join 中两个表的输入和新都会对全局可见,影响之后所有的 Join 结果。举例,在一个如下的 Join 查询里,
Orders 表的新纪录会和 Product 表所有历史纪录以及未来的纪录进行匹配。-号代表回撤,+号代表最新数据
SELECT * FROM OrdersINNER JOIN ProductON Orders.productId = Product.id
因为历史数据不会被清理,所以 Regular Join 允许对输入表进行任意种类的更新操作(insert、update、delete)。然而因为资源问题 Regular Join 通常是不可持续的,一般只用做有界数据流的 Join。
4:flinksql Time-Windowed Join
Time-Windowed Join 利用窗口给两个输入表设定一个 Join 的时间界限,超出时间范围的数据则对 JOIN 不可见并可以被清理掉。值得注意的是,这里涉及到的一个问题是时间的语义,时间可以指计算发生的系统时间(即 Processing Time),也可以指从数据本身的时间字段提取的 Event Time。如果是 Processing Time,Flink 根据系统时间自动划分 Join 的时间窗口并定时清理数据;如果是 Event Time,Flink 分配 Event Time 窗口并依据 Watermark 来清理数据。
以更常用的 Event Time Windowed Join 为例,一个将 Orders 订单表和 Shipments 运输单表依据订单时间和运输时间 Join 的查询如下:
SELECT *FROMOrders o,Shipments sWHEREo.id = s.orderId ANDs.shiptime BETWEEN o.ordertime AND o.ordertime + INTERVAL '4' HOUR
5:flinksql 时态表
虽然 Timed-Windowed Join 解决了资源问题,但也限制了使用场景: Join 两个输入流都必须有时间下界,超过之后则不可访问。这对于很多 Join 维表的业务来说是不适用的,因为很多情况下维表并没有时间界限。针对这个问题,Flink 提供了 Temporal Table Join 来满足用户需求。
Temporal Table Join 类似于 Hash Join,将输入分为 Build Table 和 Probe Table。前者一般是纬度表的 changelog,后者一般是业务数据流,典型情况下后者的数据量应该远大于前者。在 Temporal Table Join 中,Build Table 是一个基于 append-only 数据流的带时间版本的视图,所以又称为 Temporal Table。Temporal Table 要求定义一个主键和用于版本化的字段(通常就是 Event Time 时间字段),以反映记录在不同时间的内容。
时态表可以划分成一系列带版本的表快照集合,表快照中的版本代表了快照中所有记录的有效区间,有效区间的开始时间和结束时间可以通过用户指定,根据时态表是否可以追踪自身的历史版本与否,时态表可以分为 版本表 和 普通表。
SELECT * FROM RatesHistory;currency_time currency rate============= ========= ====09:00:00 US Dollar 10209:00:00 Euro 11409:00:00 Yen 110:45:00 Euro 11611:15:00 Euro 11911:49:00 Pounds 108-- 视图中的去重 query 会被 Flink 优化并高效地产出 changelog stream, 产出的 changelog 保留了主键约束和事件时间。CREATE VIEW versioned_rates ASSELECT currency, rate, currency_time -- (1) `currency_time` 保留了事件时间FROM (SELECT *,ROW_NUMBER() OVER (PARTITION BY currency -- (2) `currency` 是去重 query 的 unique key,可以作为主键ORDER BY currency_time DESC) AS rowNumFROM RatesHistory )WHERE rowNum = 1;-- 视图 `versioned_rates` 将会产出如下的 changelog:(changelog kind) currency_time currency rate================ ============= ========= ====+(INSERT) 09:00:00 US Dollar 102+(INSERT) 09:00:00 Euro 114+(INSERT) 09:00:00 Yen 1+(UPDATE_AFTER) 10:45:00 Euro 116+(UPDATE_AFTER) 11:15:00 Euro 119+(INSERT) 11:49:00 Pounds 108
比如典型的一个例子是对商业订单金额进行汇率转换。假设有一个 Orders 流记录订单金额,需要和 RatesHistory 汇率流进行 Join。RatesHistory 代表不同货币转为日元的汇率,每当汇率有变化时就会有一条更新记录。两个表在某一时间节点内容如下:
SELECTo.amount * r.rateFROMOrders o,LATERAL Table(Rates(o.time)) rWHEREo.currency = r.currency
值得注意的是,不同于在 Regular Join 和 Time-Windowed Join 中两个表是平等的,任意一个表的新记录都可以与另一表的历史记录进行匹配,在 Temporal Table Join 中,Temoparal Table 的更新对另一表在该时间节点以前的记录是不可见的。这意味着我们只需要保存 Build Side 的记录直到 Watermark 超过记录的版本字段。因为 Probe Side 的输入理论上不会再有早于 Watermark 的记录,这些版本的数据可以安全地被清理掉。
时态表注意事项:
Temporal Table 可提供历史某个时间点上的数据。
Temporal Table 根据时间来跟踪版本。
Temporal Table 需要提供时间属性和主键。
Temporal Table 一般和关键词 LATERAL TABLE 结合使用。
Temporal Table 在基于 ProcessingTime 时间属性处理时,每个主键只保存最新版本的数据。
Temporal Table 在基于 EventTime 时间属性处理时,每个主键保存从上个 Watermark 到当前系统时间的所有版本。
Append-Only 表 Join 右侧 Temporal Table ,本质上还是左表驱动 Join ,即从左表拿到 Key ,根据 Key 和时间(可能是历史时间)去右侧 Temporal Table 表中查询。
Temporal Table Join 目前只支持 Inner Join。
Temporal Table Join 时,右侧 Temporal Table 表返回最新一个版本的数据。

4:讲讲flink状态后端,怎么选择,各有什么优缺点?
flink1.12之前:
MemoryStateBackend(默认使用)
该持久化存储主要将快照数据保存到 JobManager 的内存中,仅适合作为测试以 及快照的数据量非常小时使用,并不推荐用作大规模商业部署
局限性:
每个独立的状态(state)默认限制大小为5MB, 可以通过构造函数增加容量;
状态的大小不能超过akka的framesize大小。参考:配置 ;
聚合状态(aggregate state )必须放入JobManager的内存
适用场景:
本地开发和调试。 状态很少的作业,例如仅包含一次记录功能的作业(Map,FlatMap。Filter,...), kafka 的消费者需要很少的状态
FsStateBackend
基于文件系统进行存储, 需要注意而是虽然选择使用了 FsStateBackend ,但正在进行的数据仍然是存储在 TaskManager 的内存中的,只有在 checkpoint 时,才会将状态快照写入到指定文件系统上。
局限性:
由于带备份的状态先会存在 TaskManager 中,故状态的大小不能超过 TaskManager 的内存,以免发生OOM。
适用场景:
FsStateBackend 适用于处理大状态,长窗口,或大键值状态的有状态处理任务。
FsStateBackend 比较适合用于高可用方案。
可以在生产环境中使用。
RocksDBState-Backend
RocksDBStateBackend将工作状态保存在RocksDB数据库(RocksDB 是一个基于 LSM 实现的 KV 数据库,所以个人理解State数据部分存储在内存中,一部分存储在磁盘文件上)。
通过checkpoint, 整个RocksDB数据库被复制到配置的文件系统中。最小元数据保存jobManager的内存中。RocksDBStateBackend可以通过enableIncrementalCheckpointing参数配置是否进行增量Checkpoint(而MemoryStateBackend 和 FsStateBackend不能)。
跟FsStateBackend 不同的是,RocksDBStateBackend仅支持异步快照(asynchronous snapshots)。
局限性:
由于RocksDB的JNI API 是基于byte[] 的, 故 RocksDB 支持的单 key 和单 value 的大小不能超过 2^31 字节。
对于使用具有合并操作的状态的应用程序,例如 ListState,随着时间可能会累积到超过 2^31 字节大小,这将会导致在接下来的查询中失败。
当使用 RocksDB 时,状态大小只受限于TaskManager的磁盘可用空间的大小。这也使得 RocksDBStateBackend 成为管理超大状态的最佳选择。使用 RocksDB 的权衡点在于所有的状态相关的操作都需要序列化(或反序列化)才能跨越 JNI 边界。与上面提到的堆上后端相比,这可能会影响应用程序的吞吐量。
适用场景:
RocksDBStateBackend 最适合用于处理大状态,长窗口,或大键值状态的有状态处理任务。
RocksDBStateBackend 非常适合用于高可用(HA)方案。
RocksDBStateBackend 是目前唯一支持增量 checkpoint 的后端。增量 checkpoint 非常适用于超大状态的场景。
最好是对状态读写性能要求不高的作业。
flink 1.12之后
HashMapStateBackend是内存计算,读写速度非常快;
可以支持写入Memory和文件系统。
JobManagerCheckpointStorage() : jobmanager内存
JobManagerCheckpointStorage("file://path"): jobmanager本地文件
FileSystemCheckpointStorage(): filesystem中(oss、hdfs等)
局限性:
随着时间不停地增长,会耗尽内存资源
EmbeddedRocksDBStateBackend(同RocksDBState-Backend)

5:flink 维表关联的各种方案和优缺点?
1:预加载维表
通过定义一个类实现RichMapFunction,在open()中读取维表数据加载到内存中,在probe流map()方法中与维表数据进行关联。RichMapFunction中open方法里加载维表数据到内存的方式特点如下:
优点:实现简单. 缺点:因为数据存于内存维度信息全量加载到内存中,所以只适合小数据量并且维表数据更新频率不高的情况下。虽然可以在open中定义一个定时器定时更新维表,但是还是存在维表更新不及时的情况。下面是一个例子:
/ 使用redis ,这个代码核心是 open方法里开java 定时调度更新redis到算子本地变量// mysql预加载到redis也是一样的// 不只是可以从 MySQL 中去读取,可以自定义各种数据源、//各种 DB,甚至可以读取文件,也可以读取 Flink 的 Distributed Cache。static class SimpleFlatMapFunction extends RichFlatMapFunction<String,OutData>{private transient ConcurrentHashMap<String, String> hashMap = null;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);redisJedis jedisCluster = RedisFactory.getJedisCluster();ScanResult<Map.Entry<String, String>> areas =jedisCluster.hscan("areas", "0");List<Map.Entry<String, String>> result = areas.getResult();System.out.println("更新缓存");hashMap = new ConcurrentHashMap<>();for (Map.Entry<String, String> stringStringEntry : result) {String key = stringStringEntry.getKey();String[] split = stringStringEntry.getValue().split(",");for (String s : split) {hashMap.put(s, key);}}jedisCluster.close();ScheduledExecutorService scheduledExecutorService =Executors.newScheduledThreadPool(1);scheduledExecutorService.scheduleAtFixedRate(new Runnable() {@Overridepublic void run() {System.out.println("更新缓存");Jedis jedisCluster = RedisFactory.getJedisCluster();ScanResult<Map.Entry<String, String>> areas = jedisCluster.hscan("areas", "0");List<Map.Entry<String, String>> result = areas.getResult();hashMap = new ConcurrentHashMap<>();for (Map.Entry<String, String> stringStringEntry : result) {String key = stringStringEntry.getKey();String[] split = stringStringEntry.getValue().split(",");for (String s : split) {hashMap.put(s, key);}}jedisCluster.close();}}, 0, 3, TimeUnit.SECONDS);}@Overridepublic void flatMap(String s, Collector<OutData> collector) throws Exception {OriginData originData = JSONObject.parseObject(s, OriginData.class);String countryCode = originData.countryCode;ArrayList<Data> data = originData.data;String dt = originData.dt;String coutryCode = hashMap.get(countryCode);for (Data datum : data) {OutData of = OutData.of(dt, coutryCode, datum.type, datum.score, datum.level);collector.collect(of);}}}
2:热存储维表
这种方式是将维表数据存储在Redis、HBase、MySQL等外部存储中,实时流在关联维表数据的时候实时去外部存储中查询,这种方式特点如下:
优点:维度数据量不受内存限制,可以存储很大的数据量。缺点:因为维表数据在外部存储中,读取速度受制于外部存储的读取速度;另外维表的同步也有延迟。
3:广播维表
利用Flink的Broadcast State将维度数据流广播到下游做join操作。特点如下:
优点:维度数据变更后可以即时更新到结果中。
缺点:数据保存在内存中,支持的维度数据量比较小。
使用:
1.将维度数据发送到Kafka作为流S1。事实数据是流S2。
2.定义状态描述符MapStateDescriptor,如descriptor。
3.结合状态描述符,将S1广播出去,如S1.broadcast(descriptor),形成广播流(BroadcastStream) B1。
4.事实流S2和广播流B1连接,形成连接后的流BroadcastConnectedStream BC。
5.基于BC流,在KeyedBroadcastProcessFunction/BroadcastProcessFunction中实现Join的逻 辑处理。
4:异步IO+guava
异步IO主要目的是为了解决与外部系统交互时网络延迟成为了系统瓶颈的问题
使用Aysnc I/O的前提条件
1)为了实现以异步I/O访问数据库或K/V存储,数据库等需要有能支持异步请求的client;若是没有,可以通过创建多个同步的client并使用线程池处理同步call的方式实现类似并发的client,但是这方式没有异步I/O的性能好。
2)AsyncFunction不是以多线程方式调用的,一个AsyncFunction实例按顺序为每个独立消息发送请求;
Flink中可以使用异步IO来读写外部系统,这要求外部系统客户端支持异步IO,不过目前很多系统都支持异步IO客户端。但是如果使用异步就要涉及到三个问题:
超时:如果查询超时那么就认为是读写失败,需要按失败处理;
并发数量:如果并发数量太多,就要触发Flink的反压机制来抑制上游的写入;
返回顺序错乱:顺序错乱了要根据实际情况来处理,Flink支持两种方式:允许乱序、保证顺序
使用缓存来存储一部分常访问的维表数据,以减少访问外部系统的次数,比如使用guava Cache
优点:维度数据不受限于内存,支持较多维度数据
缺点:需要热存储资源,维度更新反馈到结果有延迟(热存储导入,cache)
适用场景:维度数据量大,可接受维度更新有一定的延迟。
5:Temporal table function join(时态表)
Temporal table是持续变化表上某一时刻的视图,Temporal table function是一个表函数,(历史表)
传递一个时间参数,返回Temporal table这一指定时刻的视图。
可以将维度数据流映射为Temporal table,主流与这个Temporal table进行关联,可以关联到某一个版本(历史上某一个时刻)的维度数据。
优点:维度数据量可以很大,维度数据更新及时,不依赖外部存储,可以关联不同版本的维度数据。
缺点:只支持在Flink SQL API中使用。 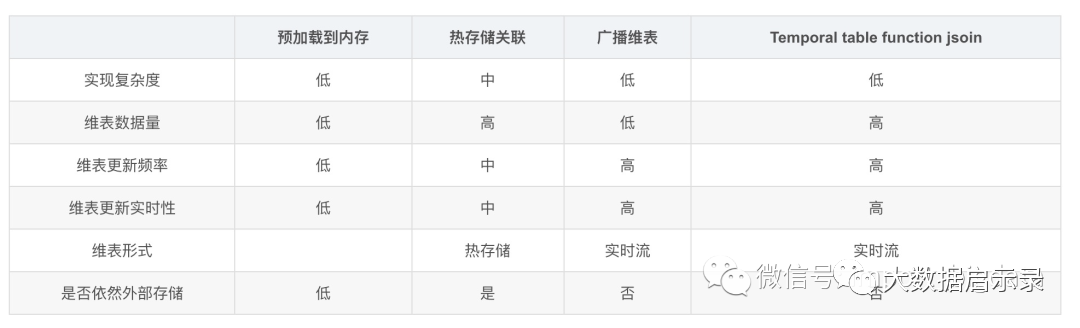
6:flink异步io?

异步io前置条件:
对外部系统进行异步IO访问的客户端API
或者在没有这样的客户端的情况下,可以通过创建多个客户端并使用线程池处理同步调用来尝试将同步客户端转变为有限的并发客户端。但是,这种方法通常比适当的异步客户端效率低。
异步io流式转换三步:
1、实现用来分发请求的AsyncFunction,用来向数据库发送异步请求并设置回调
2、获取操作结果的callback,并将它提交给ResultFuture
3、将异步I/O操作应用于DataStream, 当异步I/O请求超时时,默认情况下会抛出异常并重新启动Job,如果希望处理超时,可以覆盖AsyncFunction的timeout方法
异步io参数含义:
Timeout:超时参数定义了异步操作执行多久未完成、最终认定为失败的时长,如果启用重试,则可能包括多个重试请求。它可以防止一直等待得不到响应的请求。
Capacity:容量参数定义了可以同时进行的异步请求数。即使异步 I/O 通常带来更高的吞吐量,执行异步 I/O 操作的算子仍然可能成为流处理的瓶颈。限制并发请求的数量可以确保算子不会持续累积待处理的请求进而造成积压,而是在容量耗尽时触发反压。
AsyncRetryStrategy: 重试策略参数定义了什么条件会触发延迟重试以及延迟的策略,例如,固定延迟、指数后退延迟、自定义实现等。
超时处理 #
当异步 I/O 请求超时的时候,默认会抛出异常并重启作业。如果你想处理超时,可以重写 AsyncFunction#timeout 方法。重写 AsyncFunction#timeout 时别忘了调用 ResultFuture.complete() 或者 ResultFuture.completeExceptionally() 以便告诉Flink这条记录的处理已经完成。如果超时发生时你不想发出任何记录,你可以调用 ResultFuture.complete(Collections.emptyList()) 。
结果的顺序 #
AsyncFunction 发出的并发请求经常以不确定的顺序完成,这取决于请求得到响应的顺序。Flink 提供两种模式控制结果记录以何种顺序发出。
无序模式:异步请求一结束就立刻发出结果记录。流中记录的顺序在经过异步 I/O 算子之后发生了改变。当使用 处理时间 作为基本时间特征时,这个模式具有最低的延迟和最少的开销。此模式使用 AsyncDataStream.unorderedWait(...) 方法。
有序模式: 这种模式保持了流的顺序。发出结果记录的顺序与触发异步请求的顺序(记录输入算子的顺序)相同。为了实现这一点,算子将缓冲一个结果记录直到这条记录前面的所有记录都发出(或超时)。由于记录或者结果要在 checkpoint 的状态中保存更长的时间,所以与无序模式相比,有序模式通常会带来一些额外的延迟和 checkpoint 开销。此模式使用 AsyncDataStream.orderedWait(...) 方法。
事件时间 #
当流处理应用使用事件时间时,异步 I/O 算子会正确处理 watermark。对于两种顺序模式,这意味着以下内容:
无序模式:Watermark 既不超前于记录也不落后于记录,即 watermark 建立了顺序的边界。只有连续两个 watermark 之间的记录是无序发出的。在一个 watermark 后面生成的记录只会在这个 watermark 发出以后才发出。在一个 watermark 之前的所有输入的结果记录全部发出以后,才会发出这个 watermark。
这意味着存在 watermark 的情况下,无序模式 会引入一些与有序模式 相同的延迟和管理开销。开销大小取决于 watermark 的频率。
有序模式:连续两个 watermark 之间的记录顺序也被保留了。开销与使用处理时间 相比,没有显著的差别。
请记住,摄入时间 是一种特殊的事件时间,它基于数据源的处理时间自动生成 watermark。
详细说明:异步 I/O | Apache Flink
7:flink savepoint与checkpoint的应用和区别?
savepoint:
触发:用户手动触发
应用:有计划的备份,比如修改代码,并行度。
savepoint是对某个时间进行全局快照,在快照时,会对整个flink程序有一定影响。
checkpoint:
触发:根据用户设置的参数,交给flink程序自行触发。
应用:某个task的任务,由网络抖动导致超时异常。checkpoint能够快速恢复。
特点:任务量轻,自动从故障点恢复。
8:flink task slot 并行度之间的关系
TaskSlot是静态的概念,代表着Taskmanager具有的并发执行能力
parallelism是动态的概念,是指程序运行时实际使用的并发能力
Flink中slot是任务执行所申请资源的最小单元,同一个TaskManager上的所有slot都只是做了内存分离,没有做CPU隔离。
每一个TaskManager都是一个JVM进程,如果某个TaskManager 上只有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行,如果有多个 slot 就意味着更多 subtask 共享同一 JVM。
一般情况下有多少个subtask,就是有多少个并行线程,而并行执行的subtask要发布到不同的slot中去执行。
Flink 默认会将能链接的算子尽可能地进行链接,也就是算子链,flink 会将同一个算子链分组内的subtask都发到同一个slot去执行,也就是说一个slot可能要执行多个subtask,即多个线程。
flink 可以根据需要手动地将各个算子隔离到不同的 slot 中。
一个任务所用的总共slot为所有资源隔离组所占用的slot之和,同一个资源隔离组内,按照算子的最大并行度来分配slot。
经验上讲Slot的数量与CPU-core的数量一致为好。但考虑到超线程,可以slotNumber=2*cpuCore.
在Yarn集群中Job分离模式下,Taskmanger的数量=slot数量/并行度(向上取整)。slotNumber>=taskmanger*并行度;并行度上限不能大于slot的数量
9:flink 内存管理
jobmanger内存:
可以看到JobManager的内存模型很简单了,主要是堆内存,堆外内存,JVM Metaspace和JVM Overhead组成。
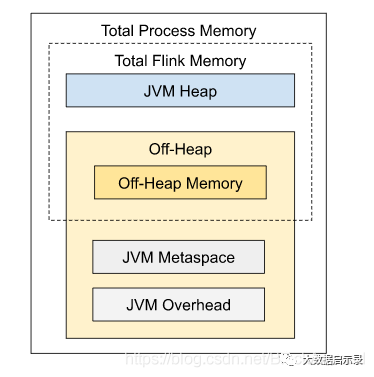
TaskManger内存:
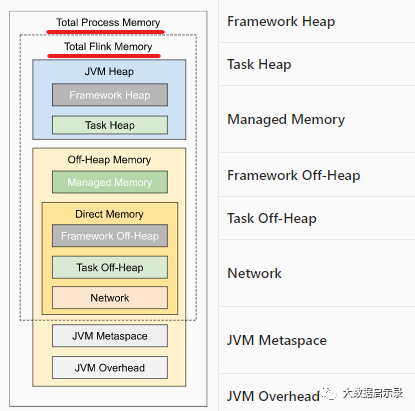
总体内存
1、Total Process Memory:Flink Java 应用程序(包括用户代码)和 JVM 运行整个进程所消耗的总内存。
总进程内存(Total Process Memory) = Flink 总内存 + JVM 元空间 + JVM 执行开销
Total Flink Memory
仅 Flink Java 应用程序消耗的内存,包括用户代码,但不包括 JVM 为其运行而分配的内存。
Flink 总内存 = Framework堆内外 + task 堆内外 + network + managed Memory
JVM Heap (JVM 堆上内存)
Framework Heap :框架堆内存,Flink框架本身使用的内存,即TaskManager本身所占用的堆上内存,不计入Slot的资源中。
Task Heap : 任务堆内存,如果内存大小没有指定,它将被推导出为总 Flink 内存减去框架堆内存、框架堆外内存、任务堆外内存、托管内存和网络内存。Task执行用户代码时所使用的堆上内存。
TaskManager 的堆内存主要被分成了三个部分:
Network Buffers: 一定数量的32KB大小的 buffer,主要用于数据的网络传输。在 TaskManager 启动的时候就会分配。默认数量是 2048 个,可以通过 taskmanager.network.numberOfBuffers 来配置。
Memory Manager Pool: 这是一个由 MemoryManager 管理的,由众多MemorySegment组成的超大集合。Flink 中的算法(如 sort/shuffle/join)会向这个内存池申请 MemorySegment,将序列化后的数据存于其中,使用完后释放回内存池。默认情况下,池子占了堆内存的 70% 的大小。
Remaining (Free) Heap: 这部分的内存是留给用户代码以及 TaskManager 的数据结构使用的。因为这些数据结构一般都很小,所以基本上这些内存都是给用户代码使用的。从GC的角度来看,可以把这里看成的新生代,也就是说这里主要都是由用户代码生成的短期对象。
注意:Memory Manager Pool 主要在Batch模式下使用。在Steaming模式下,该池子不会预分配内存,也不会向该池子请求内存块。也就是说该部分的内存都是可以给用户代码使用的。不过社区是打算在 Streaming 模式下也能将该池子利用起来。(flink1.13之后已经可以实现流批统一了)
Off-Heap Mempry(JVM 堆外内存)
Managed memory: 托管内存
由 Flink 管理的原生托管内存,保留用于排序、哈希表、中间结果缓存和 RocksDB 状态后端。
托管内存由 Flink 管理并分配为原生内存(堆外)。以下工作负载使用托管内存:
流式作业可以将其用于 RocksDB 状态后端。流和批处理作业都可以使用它进行排序、哈希表、中间结果的缓存。流作业和批处理作业都可以使用它在 Python 进程中执行用户定义的函数。
托管内存配置时如果两者都设置,则大小将覆盖分数。如果大小和分数均未明确配置,则将使用默认分数。
DirectMemory:JVM 直接内存
Framework Off-Heap Memory:Flink 框架堆外内存。即 TaskManager 本身所占用的对外内存,不计入 Slot 资源。
Task Off-Heap :Task 堆外内存。专用于Flink 框架的堆外直接(或本机)内存。Network Memory:网络内存。网络数据交换所使用的堆外内存大小,如网络数据交换 缓冲区。
JVM metaspace:JVM 元空间。
Flink JVM 进程的元空间大小,默认为256MB。
JVM Overhead:JVM执行开销。
JVM 执行时自身所需要的内容,包括线程堆栈、IO、 编译缓存等所使用的内存,这是一个上限分级成分的的总进程内存
内存数据结构
内存段:MemorySegment,是 Flink 中最小的内存分配单元,即可以是堆上内存(Java 的 byte 数组),也可以是堆外内存(基于 Netty 的 DirectByteBuffer)
内存页:是 MemorySegment 之上的数据访问视图,数据读取抽象为 DataInputView,数据写入抽象为 DataOutputView。使用时就无需关心 MemorySegment 的细节,会自 动处理跨 MemorySegment 的读取和写入。
buffer:Task 算子之间在网络层面上传输数据,使用的是 Buffer,申请和释放由 Flink自行管理
Buffer 资源池:BufferPool 用来管理 Buffer,包含 Buffer 的申请、释放、销毁、可用 Buffer 通知等,实现类是 LocalBufferPool,每个 Task 拥有自己的 LocalBufferPool。BufferPoolFactory 用 来 提 供 BufferPool 的 创 建 和 销 毁 , 唯 一 的 实 现 类 是NetworkBufferPool , 每 个 TaskManager 只 有 一 个 NetworkBufferPool 。同一个TaskManager 上的 Task 共享 NetworkBufferPool,在 TaskManager 启动的时候创建并分配内存。
10:flink三种提交方式的区别?
session模式:
集群生命周期:客户端连接到一个预先存在的、长期运行的集群,该集群可以接受多个作业提交。即使所有作业完成后,集群(和 JobManager)仍将继续运行直到手动停止 session 为止。因此,Flink Session 集群的寿命不受任何 Flink 作业寿命的约束。
资源隔离:TaskManager slot 由 ResourceManager 在提交作业时分配,并在业完成时释放。由于所有作业都共享同一集群,因此在集群资源方面存在一些竞争 — 例如提交工作阶段的网络带宽。此共享设置的局限性在于,如果 TaskManager 崩溃,则在此 TaskManager 上运行 task 的所有作业都将失败;类似的,如果 JobManager 上发生一些致命错误,它将影响集群中正在运行的所有作业。(作业共享集群资源)
其他注意事项:拥有一个预先存在的集群可以节省大量时间申请资源和启动 TaskManager。有种场景很重要,作业执行时间短并且启动时间长会对端到端的用户体验产生负面的影响 — 就像对简短查询的交互式分析一样,希望作业可以使用现有资源快速执行计算。
适用场景:Session模式一般用来部署那些对延迟非常敏感但运行时长较短的作业,需要频繁提交小job的场景。
pre-job模式:
集群生命周期:在 Flink pre-Job 集群中,可用的集群管理器(例如 YARN)用于为每个提交的作业启动一个集群,并且该集群仅可用于该作业。在这里,客户端首先从集群管理器请求资源启动 JobManager,然后将作业提交给在这个进程中运行的 Dispatcher。然后根据作业的资源请求惰性的分配 TaskManager。一旦作业完成,Flink Job 集群将被拆除。
资源隔离:JobManager 中的致命错误仅影响在 Flink Job 集群中运行的一个作业。(每个作业单独启动集群)
其他注意事项:由于 ResourceManager 必须应用并等待外部资源管理组件来启动 TaskManager 进程和分配资源,因此 Flink Job 集群更适合长期运行、具有高稳定性要求且对较长的启动时间不敏感的大型作业。
适用场景:Per-Job模式一般用来部署那些长时间运行的作业。
application模式(推荐生产使用):
集群生命周期:Flink Application 集群是专用的 Flink 集群,仅从 Flink 应用程序执行作业,并且 main()方法在集群上而不是客户端上运行。提交作业是一个单步骤过程:无需先启动 Flink 集群,然后将作业提交到现有的 session 集群;相反,将应用程序逻辑和依赖打包成一个可执行的作业 JAR 中,并且集群入口(ApplicationClusterEntryPoint)负责调用 main()方法来提取 JobGraph。例如,这允许你像在 Kubernetes 上部署任何其他应用程序一样部署 Flink 应用程序。因此,Flink Application 集群的寿命与 Flink 应用程序的寿命有关。
资源隔离:在 Flink Application 集群中,ResourceManager 和 Dispatcher 作用于单个的 Flink 应用程序,相比于 Flink Session 集群,它提供了更好的隔离。(每个job独享一个集群)
总结:
application:每个job独享一个集群,job退出则集群退出。main方法在集群上运行。
session:多个job共享集群资源,job退出集群也不会退出。main方法在客户端运行。
pre-job:每个job独享一个集群,job退出则集群退出。main方法在客户端运行。
11:flink 背压原理?定位与解决方式?

反压是什么?
反压是流式系统中关于处理能力的动态反馈机制,并且是从下游到上游的反馈。(上下游数据生产和消费速率不均衡)
上游 Producer 向下游 Consumer 发送数据,在发送端和接受端都有相应的 Send Buffer 和 Receive Buffer,但是上游 Producer 生成数据的速率比下游 Consumer 消费数据的速率快。
此时可能会出现两种情况:
下游消费者会丢弃新到达的数据,因为下游消费者的缓冲区放不下
为了不丢弃数据,所以下游消费者的 Receive Buffer 持续扩张,最后耗尽消费者的内存,OOM,程序挂掉
Flink 的 checkpoint 反压还会影响到两项指标: checkpoint 时长和 state 大小。
反压原理?
v1.5之前 TCP反压
流程太长,省略...
TCP的反压,通过callback实现的,当socket发送数据到receive buffer后,receiver反馈给send端,目前receiver端的buffer还有多少剩余空间,让后send端会根据剩余空间,控制发送速率。
TCP反压的弊端:
① 单个Task的反压,阻塞了整个TaskManager的socket,导致checkpoint barrier也无法传播,最终导致checkpoint时间增长甚至checkpoint超时失败。② 反压路径太长,导致反压时间延迟
v1.5之后 Credit-based反压
Credit信用值,backlog值===》专有buffer 队列
反压机制作用于 Flink 的应用层,即在 ResultSubPartition 和 InputChannel 这一层引入了反压机制。
① 每一次 ResultPartition 向 InputGate 发送数据的时候,都会发送一个 backlog size 告诉下游准备发送多少消息,下游就会去计算有多少的 Buffer 去接收消息。(backlog 的作用是为了让消费端感知到我们生产端的情况)
② 如果下游有充足的 Buffer ,就会返还给上游 Credit (表示剩余 buffer 数量),告知发送消息(图上两个虚线是还是采用 Netty 和 Socket 进行通信)。
详细:Flink如何分析及处理反压? - 民宿 - 博客园 (cnblogs.com)
反压定位?
要解决反压首先要做的是定位到造成反压的节点,这主要有两种办法:
通过 Flink Web UI 自带的反压监控面板;
通过 Flink Task Metrics。
监控面板:


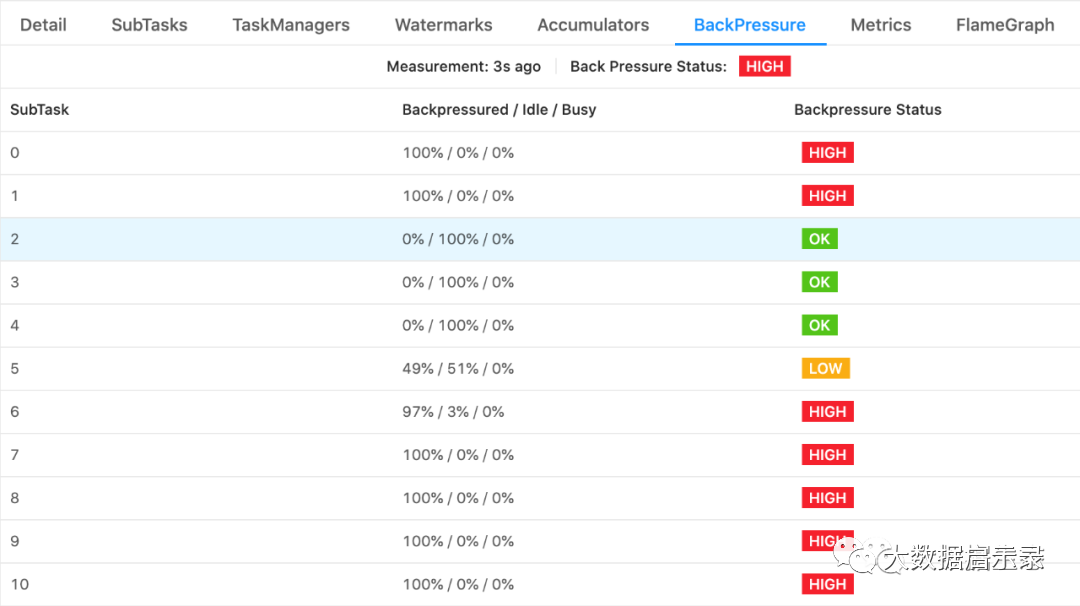
backpressure Tab页面:backpressure status 和backpressured/Idle/BUsy
idleTimeMsPerSecond
busyTimeMsPerSecond
backPressuredTimeMsPerSecond
Flink Task Metrics
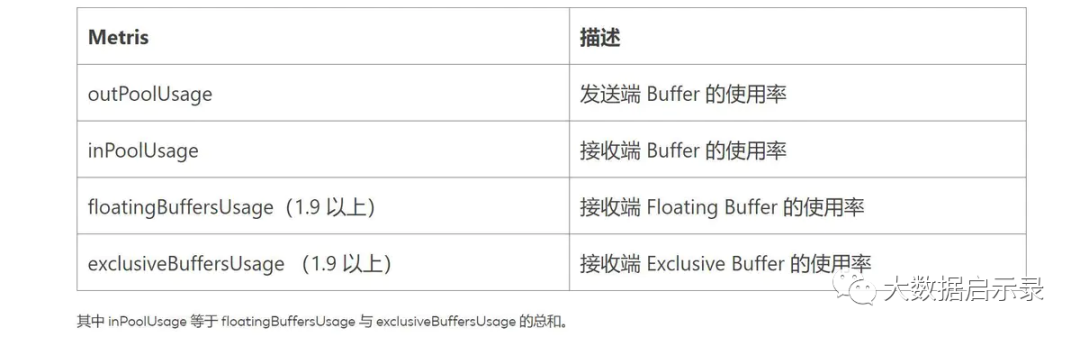
解释:
① outPoolUsage 和 inPoolUsage 同为低表明当前 Subtask 是正常的,同为高分别表明当前 Subtask 被下游反压。
② 如果一个 Subtask 的 outPoolUsage 是高,通常是被下游 Task 所影响,所以可以排查它本身是反压根源的可能性。
③ 如果一个 Subtask 的 outPoolUsage 是低,但其 inPoolUsage 是高,则表明它有可能是反压的根源。因为通常反压会传导至其上游,导致上游某些 Subtask 的 outPoolUsage 为高。
注意:反压有时是短暂的且影响不大,比如来自某个 channel 的短暂网络延迟或者 TaskManager 的正常 GC,这种情况下可以不用处理。
① floatingBuffersUsage 为高则表明反压正在传导至上游。
② exclusiveBuffersUsage 则表明了反压可能存在倾斜。如果floatingBuffersUsage 高、exclusiveBuffersUsage 低,则存在倾斜。因为少数 channel 占用了大部分的 floating Buffer(channel 有自己的 exclusive buffer,当 exclusive buffer 消耗完,就会使用floating Buffer)。
反压常见原因和解决方案?
(1)数据倾斜
通过 Web UI 各个 SubTask 的 Records Sent 和 Record Received 来确认,另外 Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。解决方式把数据分组的 key 进行本地/预聚合来消除/减少数据倾斜。或者增加并发或者增加机器
(2)用户代码的执行效率
对 TaskManager 进行 CPU profile,分析 TaskThread 是否跑满一个 CPU 核:如果没有跑满,需要分析 CPU 主要花费在哪些函数里面,比如生产环境中偶尔会卡在 Regex 的用户函数(ReDoS);如果没有跑满,需要看 Task Thread 阻塞在哪里,可能是用户函数本身有些同步的调用,可能是 checkpoint 或者 GC 等系统活动。
(3)TaskManager 的内存以及 GC
TaskManager JVM 各区内存不合理导致的频繁 Full GC 甚至失联。可以加上 -XX:+PrintGCDetails 来打印 GC 日志的方式来观察 GC 的问题。推荐TaskManager 启用 G1 垃圾回收器来优化 GC。
12:flink数据倾斜怎么定位?怎么处理?

flink数据倾斜定位?
步骤1:定位反压
定位反压有2种方式:Flink Web UI 自带的反压监控(直接方式)、Flink Task Metrics(间接方式)。通过监控反压的信息,可以获取到数据处理瓶颈的 Subtask。
步骤2:确定数据倾斜
Flink Web UI 自带Subtask 接收和发送的数据量。当 Subtasks 之间处理的数据量有较大的差距,则该 Subtask 出现数据倾斜。如下图所示,红框内的 Subtask 出现数据热点。
flink数据倾斜方案解决汇总?
keyby之前发生发生的数据倾斜
keyBy前存在数据倾斜,上游算子的某些实例可能处理的数据比较多,某些实例可能处理的数据较少,产生情况可能时因为数据源的数据不均匀
解决方案:
把数据进行打散,重新均匀分配。(需要让 Flink 任务强制进行 shuffle。使用 shuffle、rebalance 或 rescale算子即可将数据均匀分配,从而解决数据倾斜的问题。)
通过调整并发度,解决数据源消费不均匀或者数据源反压的情况
keyBy后聚合操作存在数据倾斜(通过Flink LocalKeyBy思想来解决)
在 keyBy 上游算子数据发送之前,首先在上游算子的本地对数据进行聚合后再发送到下游,使下游接收到的数据量大大减少,从而使得 keyBy 之后的聚合操作不再是任务的瓶颈。类似 MapReduce 中 Combiner 的思想,但是这要求聚合操作必须是多条数据或者一批数据才能聚合,单条数据没有办法通过聚合来减少数据量。从 Flink LocalKeyBy 实现原理来讲,必然会存在一个积攒批次的过程,在上游算子中必须攒够一定的数据量,对这些数据聚合后再发送到下游。
注意:Flink 是实时流处理,如果 keyby 之后的聚合操作存在数据倾斜,且没有开窗口
的情况下,简单的认为使用两阶段聚合,是不能解决问题的。因为这个时候 Flink 是来一条
处理一条,且向下游发送一条结果,对于原来 keyby 的维度(第二阶段聚合)来讲,数据
量并没有减少,且结果重复计算(非 FlinkSQL,未使用回撤流)
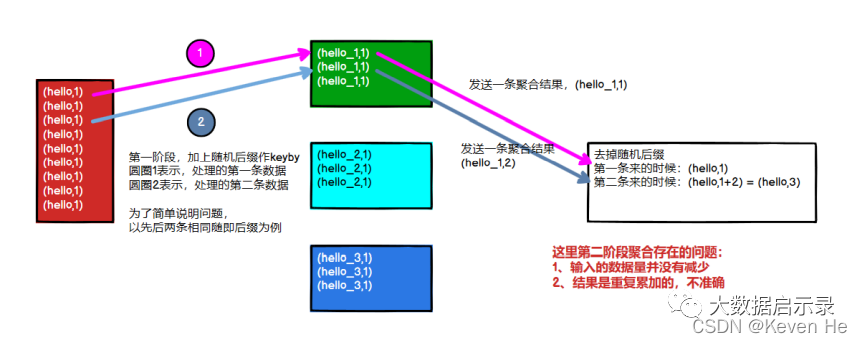
keyBy后窗口聚合操作存在数据倾斜(两阶段聚合)
因为使用了窗口,变成了有界数据的处理,窗口默认是触发时才会输出一条结果发往下游,所以可以使用两阶段聚合的方式:
实现思路:
第一阶段聚合:key 拼接随机数前缀或后缀,进行 keyby、开窗、聚合
注意:聚合完不再是 WindowedStream,要获取 WindowEnd 作为窗口标记作为第二阶段分组依据,避免不同窗口的结果聚合到一起)
第二阶段聚合:去掉随机数前缀或后缀,按照原来的 key 及 windowEnd 作 keyby、聚合
sql方式解决数据倾斜
开启LocalGloBal。
LocaGloBal是把数据攒在一起进行聚合,然后使用Accumulator进行累加后
合并(merge)开启LocalGlobal需要实现UDAF函数,进行merge累加。
这种方式与Aggregate方法非常相似。都是来筛选数据倾斜,减少下游数
据。
13:flink去重方案?
1:mapState/ValueState+状态后端
使用RocksDBStateBackend,因为数据是存储在磁盘上,元数据保存在内存中。适合非常大的状态。在算子中,使用MapState数据结构,对key进行保存。
数据来了查看MapState是否存在,存在 + 1,不存在设置为1。
缺点:如果使用机械硬盘的话,flink数据量过大,磁盘会成为性能瓶颈。随之导致整个IO急剧下降。可能会出现背压情况!
优点:精确去重
2:基于HyperLogLog
HyperLogLog是去重计数的利器,能够以很小的精确度误差作为trade-off大幅减少内存空间占用,在不要求100%准确的计数场景极为常用
优点:高效,占用空间少
缺点:近似去重
3:布隆过滤器+状态后端/布隆过滤器+redis
类似Set集合,用于判断当前元素是否存在当前集合中。
布隆过滤器,当前的key是否存在容器中,不存在直接返回
缺点:不能百分之百的保证精确。
优点:插入和查询效率是非常的高
4: RoaringBitmap去重(推荐)
BitMap - 优点:精确去重,占用空间小(在数据相对均匀的情况下)。缺点:只能用于数字类型(int或者long)。
RoaringBitmap:BitMap固然好用,但是对去重的字段只能用int或者long类型;但是如果去重字段不是int或者long怎么办呢?那我们就构建一个字段与BitIndex的映射关系表,通过MapFunction拿到字段对应的BitIndex之后,就可以直接进行去重逻辑了。
5:hashset+hbase rowkey(不可行)
优点:能够对大的数据量高效去重
缺点:hbase不支持数据无法保证exactly-once。
6:flink+starrocks/hudi(推荐)
通过starrocks和hudi的主键直接去重
优点:高效快速去重
缺点:超大规模数据性能待验证

14:flink如何回溯历史数据?
1:时态表或回撤流
2:hudi、iceberg、delta lake
3: cdc到kafk或pulsar

15:flink ttl的几种策略?

根据程序的运行时间,我们的状态是不断的积累,占用的空间越来越多,当达到内存瓶颈时,容易出现OOM。
因此引入了TTL特性,对作业的状态(state)进行清理。
自flink1.8后,一共有三种ttl清理策略。
1、全量快照清理策略(cleanupFullSnapshot):
是针对checkpoint/savepoint全局快照的。
当快照过期,并不会删除。等待重启checkpoint/savepoint时,才会删除过期的
全局快照状态。过期时间是在代码中设置。
2、清理增量策略(cleanupIncrementally)
是针对状态后端的。
存储后端会为状态条目维护一个惰性全局迭代器。每次触发时,就会向前迭代删
除已遍历的数据。过期的数据是根据代码来设置。
.cleanupIncrementally(5, false) 第一个参数条目数量,第二个参数是是否删除
3、RocksDB过滤器清理策略(cleanupInRocksdbCompactFilter):
Flink会异步对RocksDB的状态进行压缩合并更新,减少存储空间。
对Flink条目进行清理达到1000条,会检查当前的条目是否处于属于过期状态。
如果是过期状态会进行删除。
.cleanupInRocksdbCompactFilter(1000)
16:flink如何保证端到端的exactly-once ?
不能百分之百保证exactly-once,只能尽可能的保证。需从每个阶段保证。
source端保证:使用可以记录数据位置并重设读取位置的组件(如kafka,文件)
flink内部保证:使用checkpint+state 将状态值保存在状态后端里,并且checkpoint需要设置为精确一次性语义
sink端保证:从故障恢复时,数据不会重复写入外部系统(幂等写入、事务写入)
幂等写入:幂等操作是指,同一个操作,可以执行很多次,但是不会对结果造成影响,与执行一次的结果保持一致
事务写入:在CheckPoint开始构建一个事务,当CheckPoint彻底完成时,提交事务。
事务写入又可以分为两种---WAL预写日志和2pc两阶段提交。DataStream API 提供了GenericWriteAheadSink模板类和TwoPhaseCommitSinkFunction 接口,可以方便地实现这两种方式的事务性写入。
flink两阶段提交流程不在此处讲解
17:任务链(Operator Chains)和 SlotSharing(子任务共享)有什么区别?
SlotSharing(子任务共享)是让同一个Job中不同Task的SubTask运行在同一个Slot中,它的目的是为了更好的均衡资源,避免不同的Slot出现“一半火山一半冰山”的情况。如果没有重分区的算子(即只有one-to-one的数据传递模式),它是不会有不同slot或不同taskmanager数据交互的,并且同一个线程中的SubTask进行数据传递,不需要经过IO,不需要经过序列化,直接发送数据对象到下一个SubTask,性能得到提升。但是,如果有重分区的算子(即有redistributing的数据传递模式),它还是会出现不同slot或不同taskmanager数据交互的,这样数据会经过IO和序列化。
而任务链(Operator Chains)是将并行度相同且关系为one-to-one的前后两个subtask,融合形成一个task,是更细粒度的“融合”,它一方面可以减少task的数量,提高taskManager的资源利用率,另一方面,由于是one-to-one的数据传递模式,并且task只能存在于一个slot中,数据是不会有IO和序列化的。
18: flink两阶段提交?
flink两阶段提交流程?
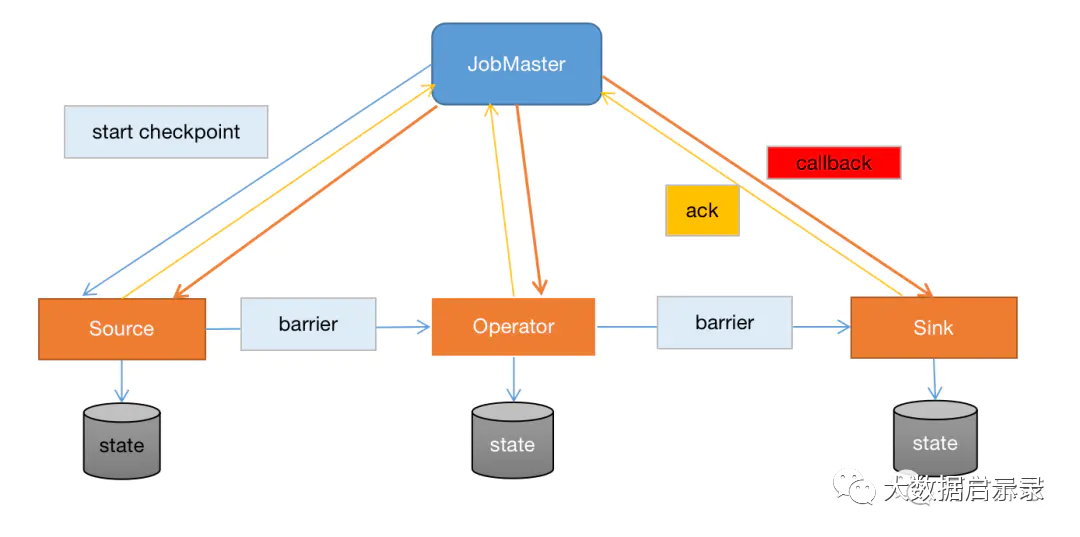
1. jobMaster 会周期性的发送执行checkpoint命令(start checkpoint);
2.当source端收到执行指令后会产生一条barrier消息插入到input消息队列中,当处理到barrier时会执行本地checkpoint, 并且会将barrier发送到下一个节点,当checkpoint完成之后会发送一条ack信息给jobMaster ;
3. 当DAG图中所有节点都完成checkpoint之后,jobMaster会收到来自所有节点的ack信息,那么就表示一次完整的checkpoint的完成;
4. JobMaster会给所有节点发送一条callback信息,表示通知checkpoint完成消息,这个过程是异步的,并非必须的,方便做一些其他的事情,例如kafka offset提交到kafka。
对比Flink整个checkpoint机制调用流程可以发现与2PC非常相似,JobMaster相当于协调者,所有的处理节点相当于执行者,start-checkpoint消息相当于pre-commit消息,每个处理节点的checkpoint相当于pre-commit过程,checkpoint ack消息相当于执行者反馈信息,最后callback消息相当于commit消息,完成具体的提交动作。那么我们应该怎么去使用这种机制来实现2PC呢?
Flink提供了CheckpointedFunction与CheckpointListener这样两个接口,CheckpointedFunction中有snapshotState方法,每次checkpoint触发执行方法,通常会将缓存数据放入状态中,可以理解为是一个hook,这个方法里面可以实现预提交,CheckpointListener中有notifyCheckpointComplete方法,checkpoint完成之后的通知方法,这里可以做一些额外的操作,例如FlinkKafakConsumerBase 使用这个来完成kafka offset的提交,在这个方法里面可以实现提交操作。
在2PC中提到如果对应流程2预提交失败,那么本次checkpoint就被取消不会执行,不会影响数据一致性,那么如果流程4提交失败了,在flink中可以怎么处理的呢?我们可以在预提交阶段(snapshotState)将事务的信息保存在state状态中,如果流程4失败,那么就可以从状态中恢复事务信息,并且在CheckpointedFunction的initializeState方法中完成事务的提交,该方法是初始化方法只会执行一次,从而保证数据一致性。
flink自定义两阶段提交?
Flink将两阶段提交协议中的通用逻辑抽象为了一个类—TwoPhaseCommitSinkFunction。
我们在实现端到端exactly-once的应用程序时,只需实现这个类的4个方法即可:
beginTransaction:开始事务时,会在目标文件系统上的临时目录中创建一个临时文件,之后将处理数据写入该文件。
preCommit:在预提交时,我们会刷新文件,关闭它并不再写入数据。我们还将为下一个Checkpoint的写操作启动一个新事务。
commit:在提交事务时,我们自动将预提交的文件移动到实际的目标目录。
abort:中止时,将临时文件删除。
如果出现任何故障,Flink将应用程序的状态恢复到最近一次成功的Checkpoint。如果故障发生在预提交成功之后,但还没来得及通知JobManager之前,在这种情况下,Flink会将operator恢复到已经预提交但尚未提交的状态。

