






长按二维码关注
大数据领域必关注的公众号

111、Hadoop中libjars参数的作用及使用?
参考答案:
(1)作用:指定MR第三方jar包
(2)使用:hadoop jar wordcount.jar com.dajiangtai.WordCount -libjars $LIBJARS input output 注:libjars这个参数一定要放到类名的后面,参数的前面。这样就可以方便使用第三方jar包了。
112、Hadoop的性能调优从哪些方面着手?
jstat -gcutil 12122 1000
jvisualvm+jstatd
a)NameNode和DataNode内存调整在hadoop-env.sh文件中 NameNode:export HADOOP_NAMENODE_OPTS="-Xmx512m -Xms512m -Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS" DataNode:export HADOOP_DATANODE_OPTS="-Xmx256m -Xms256m -Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS" -Xmx -Xms这两个参数一般保持一致,以避免每次垃圾回收完成后JVM重新分配内存。b)REsourceManager和NodeManager内存调整在yarn-env.sh文件中 REsourceManager:export YARN_RESOURCEMANAGER_HEAPSIZE=1000 默认 export YARN_RESOURCEMANAGER_OPTS="..........."可以覆盖上面的值 NodeManager:export YARN_NODEMANAGER_HEAPSIZE=1000 默认 export YARN_NODEMANAGER_OPTS="";可以覆盖上面的值 常驻内存经验配置:namenode:16G datanode:2-4G ResourceManager:4G NodeManager:2G Zookeeper:4G Hive Server:2G
配置文件mapred-default.xml:mapreduce.cluster.local.dir
配置文件hdfs-default.xml:提高可靠性 dfs.namenode.name.dir dfs.namenode.edits.dir dfs.datanode.data.dir
a)配置mapred-site.xml文件中配置 mapreduce.map.output.compress true mapreduce.map.output.compress.codec org.apache.hadoop.io.compress.SnappyCodec 程序运行时指定参数 hadoop jar home/hadoop/tv/tv.jar MediaIndex -Dmapreduce.compress.map.output=true -Dmapreduce.map.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec tvdata media
113、Hadoop中通过拆分任务到多个节点运行来实现并行计算,但某些节点运行较慢会拖慢整个任务的运行,Hadoop采用什么机制应对这个情况?
Speculative Execution 推测执行
114、MapReduce二次排序原理?
默认情况下,Map输出的结果会对Key进行默认的排序,但是有时候需要对Key排序的同时还需要对Value进行排序,这时候就要用到二次排序了。
1)Map起始阶段
在Map阶段,使用job.setInputFormatClass()定义的InputFormat,将输入的数据集分割成小数据块split,同时InputFormat提供一个RecordReader的实现。在这里我们使用的是TextInputFormat,它提供的RecordReader会将文本的行号作为Key,这一行的文本作为Value。这就是自定 Mapper的输入是 的原因。然后调用自定义Mapper的map方法,将一个个键值对输入给Mapper的map方法。
2)Map最后阶段
在Map阶段的最后,会先调用job.setPartitionerClass()对这个Mapper的输出结果进行分区,每个分区映射到一个Reducer。每个分区内又调用job.setSortComparatorClass()设置的Key比较函数类排序。可以看到,这本身就是一个二次排序。如果没有通过job.setSortComparatorClass()设置 Key比较函数类,则使用Key实现的compareTo()方法。
3)Reduce阶段
在Reduce阶段,reduce()方法接受所有映射到这个Reduce的map输出后,也会调用job.setSortComparatorClass()方法设置的Key比较函数类,对所有数据进行排序。然后开始构造一个Key对应的Value迭代器。这时就要用到分组,使用 job.setGroupingComparatorClass()方法设置分组函数类。只要这个比较器比较的两个Key相同,它们就属于同一组,它们的 Value放在一个Value迭代器,而这个迭代器的Key使用属于同一个组的所有Key的第一个Key。最后就是进入Reducer的 reduce()方法,reduce()方法的输入是所有的Key和它的Value迭代器,同样注意输入与输出的类型必须与自定义的Reducer中声明的一致。
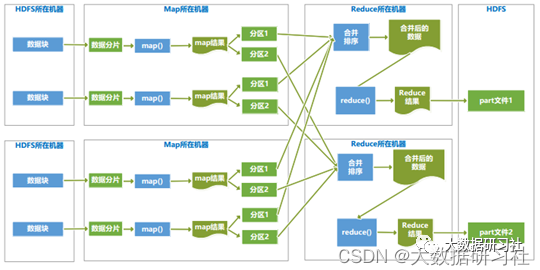
115、分析MapReduce数据处理及shuffle的流程,以及各个阶段的先后顺序。
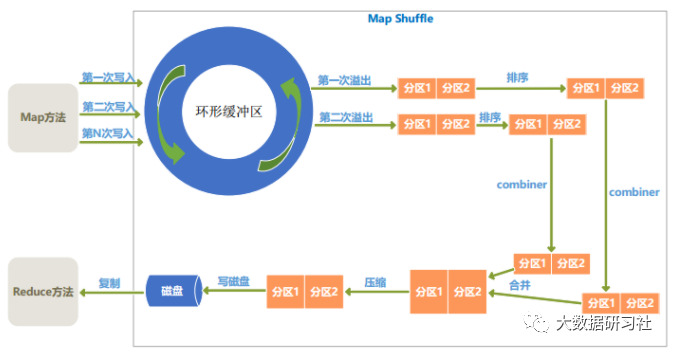
2)Map端shuffle过程
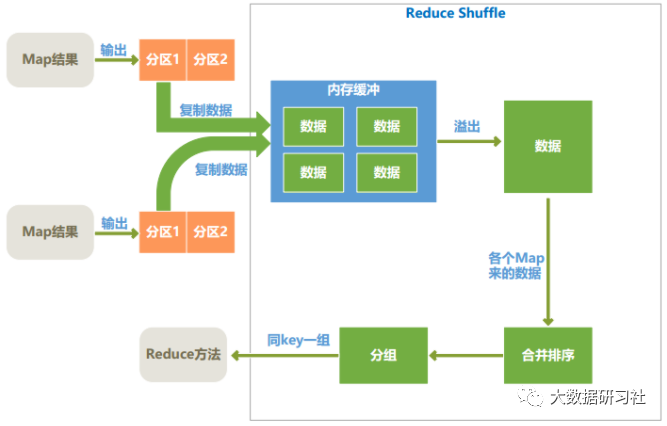
3)Reduce端的shuffle过程
完

