






长按二维码关注
大数据领域必关注的公众号

一、数仓架构
1.1 数仓相关概述
1.1.1 数据仓库(Data Warehouse)
1.1.2 商业智能(Business Intelligence)

1.1.3 OLTP vs OLAP
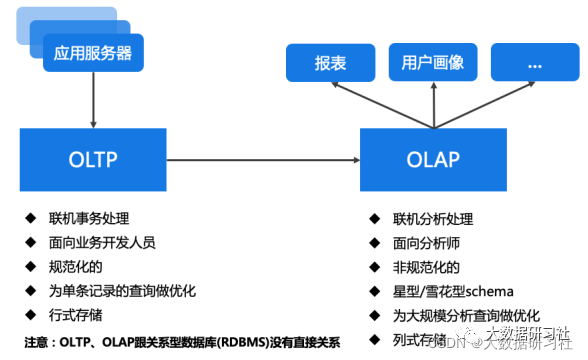
联机事务处理,侧重于数据库的增删改查等常⽤业务操作,强调事物和并发。
(2)OLAP(Online Analytical Process)-分析驱动
联机分析处理,即以多维的⽅式分析数据,强调磁盘IO吞吐,⼀般采⽤分区技术、并⾏处理技术。
OLAP是⼀种软件技术,它使分析⼈员能够迅速、⼀致、交互式的从各⽅⾯观察数据,以达到深⼊理解数据的⽬的。从各⽅⾯观察数据,也就是从不同纬度分析数据,因此也成为多维分析。
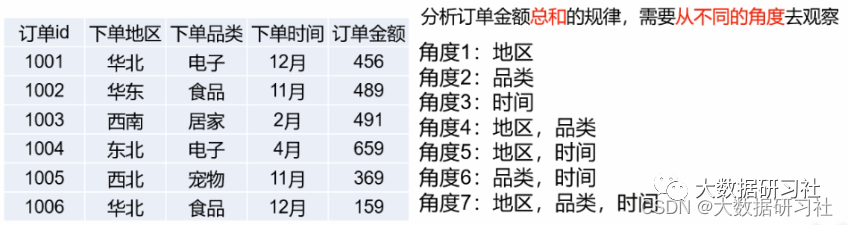
1.1.4 行存储与列存储
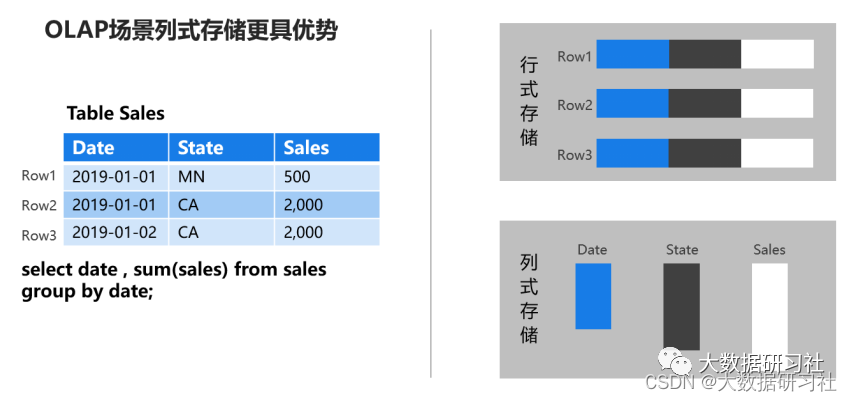

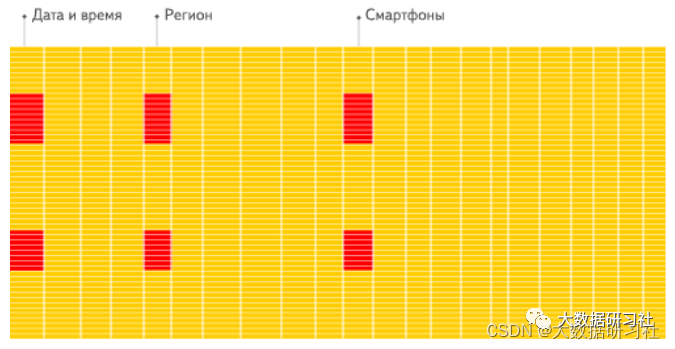
1. 对于分析查询,⼀般只需要⽤到少量的列,在列式存储中,只需要读取所需的数据列即可。例如,如果您需要100列中的5列,则I O减少20倍。
2. 按列分开存储,按数据包读取时因此更易于压缩。列中的数据具有相同特征也更易于压缩, 这样可以进⼀步减少I O量。
3. 由于减少了I O,因此更多数据可以容纳在系统缓存中,进⼀步提⾼分析性能。
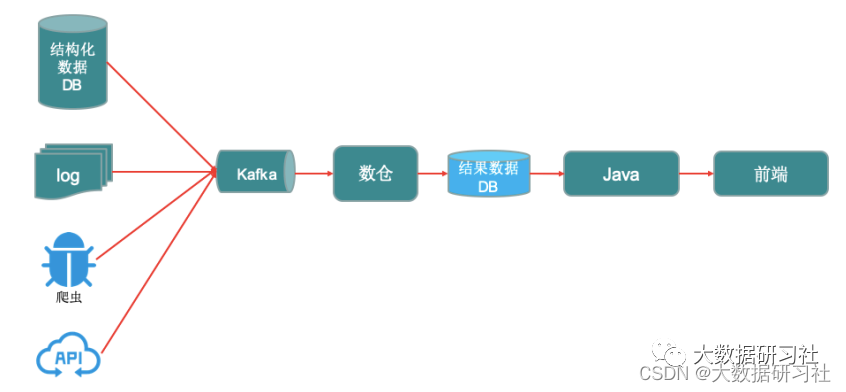
1.1.5 典型数仓数据流
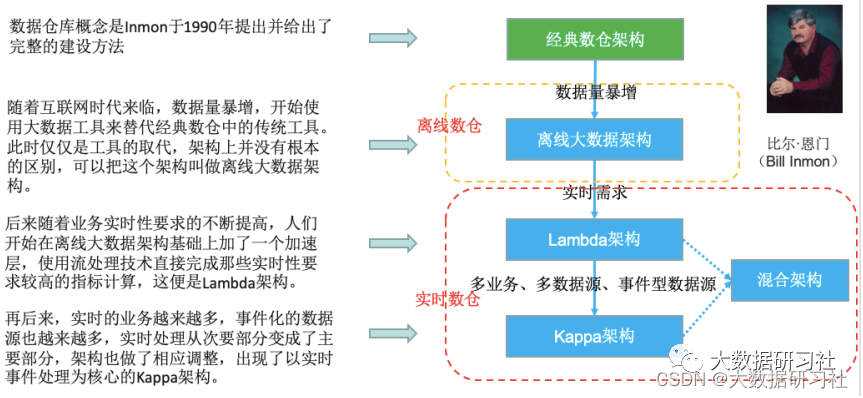
1.2 数仓架构演变概览
1.3 离线大数据数仓架构
1.3.1 离线大数据架构
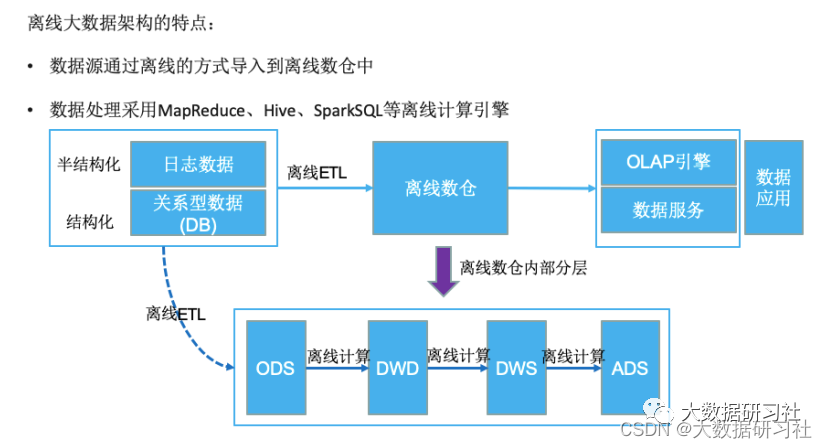
1.3.2 离线数仓分层
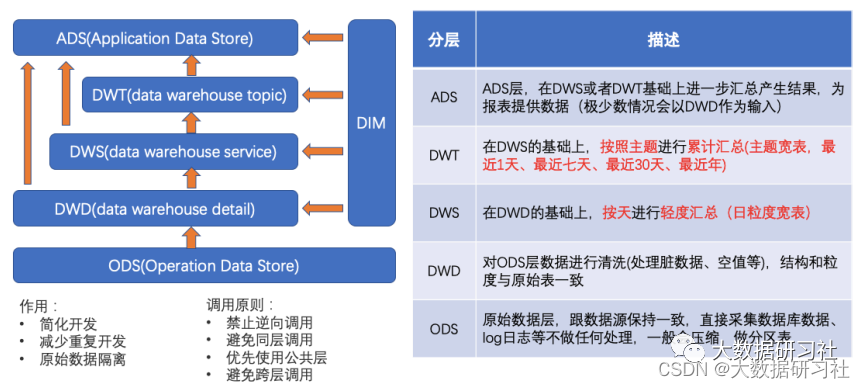
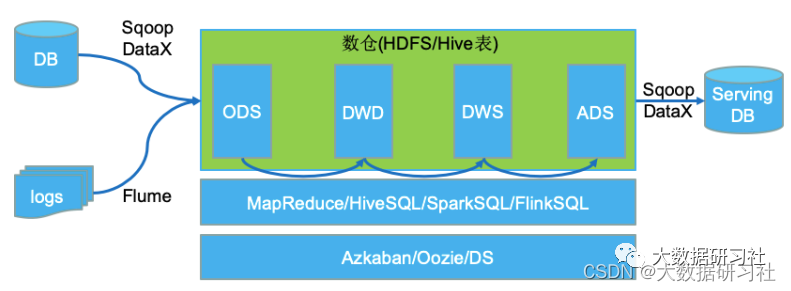
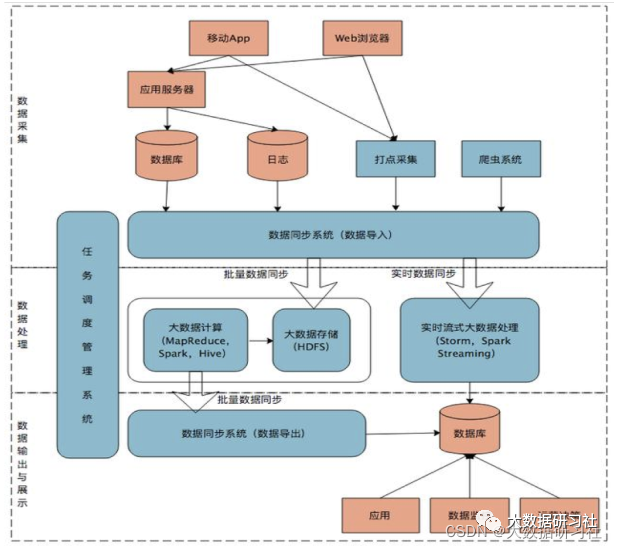
1.3.3 典型架构/案例
1.4 Lambda架构
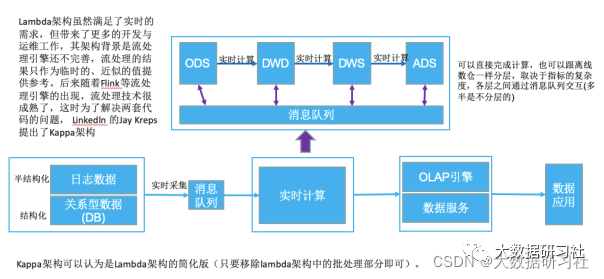
1.4.1 Lambda架构
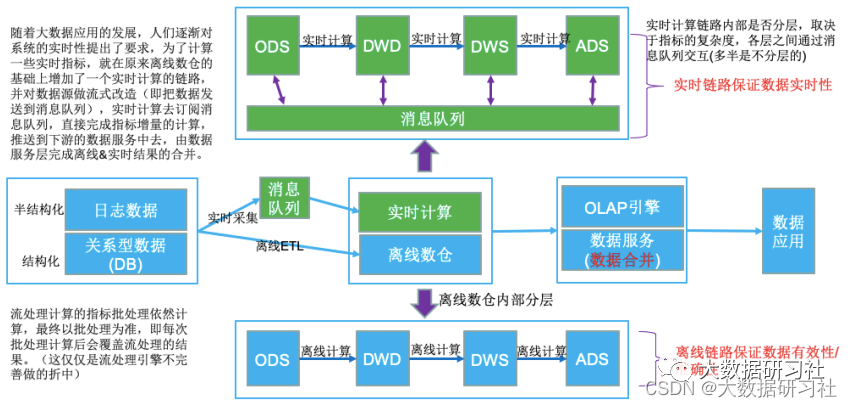
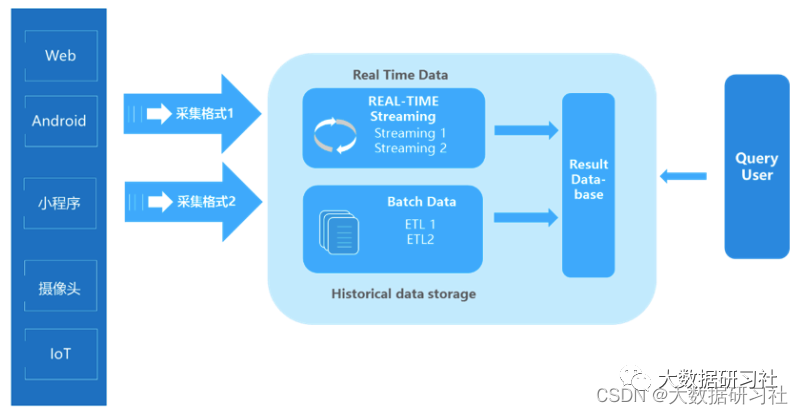
1.4.2 Lambda架构典型案例
1.4.3 Lambda架构的缺陷
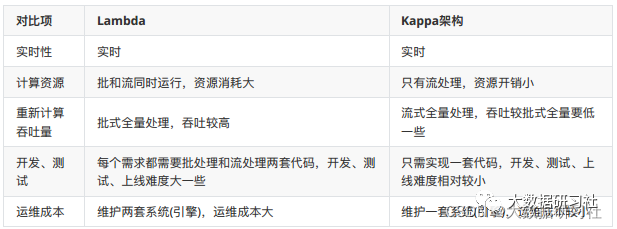
这是Lambda架构最大的问题,两套代码不仅仅意味着开发困难(同样的需求,⼀个在批处理引擎上实现,⼀个在流处理引擎上实现,还要分别构造数据测试保证两者结果⼀致),后期维护更加困难,⽐如需求变更后需要分别更改两套代码,独⽴测试结果,且两个作业需要同步上线。
(2)资源占⽤增多
同样的逻辑计算两次,整体资源占⽤会增多(多出实时计算这部分)。
(3)实时链路和离线链路数据差异容易让业务⽅困惑
例如业务方会发现,次日看到的数据比昨晚看到的要少。原因在于:数据在被放入Result Database时,⾛了两条线的计算⽅式:⼀条线是ETL按照某个⼝径“跑”过来,得到更为准确的批量处理结果;另⼀条线是通过Streaming“跑”过来,依靠一些算法得出的实时性结果。当然它牺牲了部分的准确性。可见,这两个来⾃批量的和实时的数据结果是对不上的,因此⼤家觉得很困惑。
注意:对于⽇志、⽤户⾏为这种不变的数据是不会造成误解的,但是这种情况⼜不太需要lambda架构。
1.5 Kappa架构
1.5.1 Kappa架构
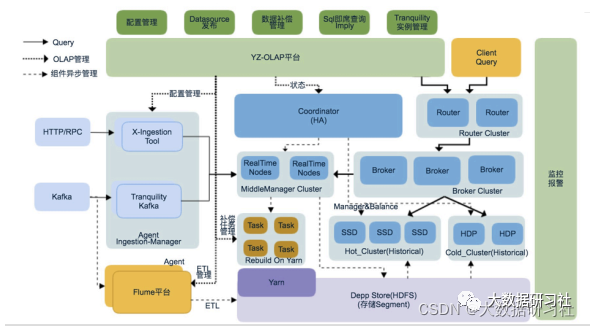
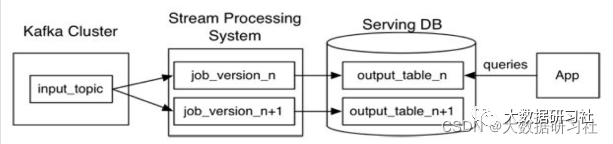
1.5.2 Kappa架构典型案例
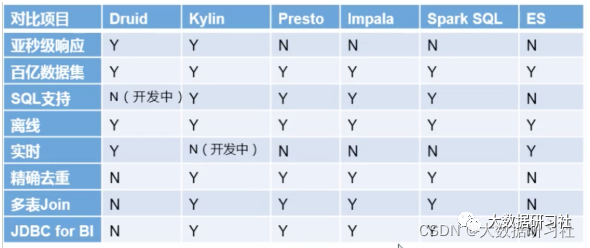
Kappa架构来构建数仓是妥妥的实时数仓,每个需求都⾃⼰开发流处理代码,⽐较繁琐,⼀个较好的办法是借助OLAP引擎,主流的引擎如下(个别的严格意义上来说不是OLAP引擎,但是具备相应功能):
Kylin3.0本身是Kappa架构,但是⽀持Lambda架构:
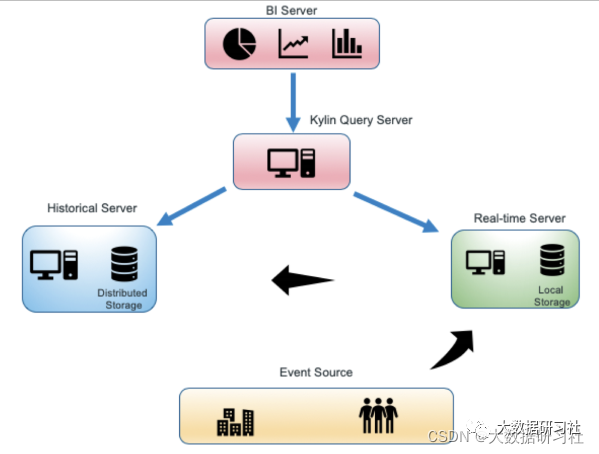
1.5.3 Kappa架构重处理过程
Kappa架构最大的问题是流式重新处理历史数据的吞吐能力会低于批处理,但这个可以通过增加计算资源来弥补。
重新处理是⼈们对Kappa架构最担⼼的点,但实际上并不复杂:
1. 选择⼀个具有重放功能的、能够保存历史数据并⽀持多消费者的消息队列,根据需求设置历史数据保存的时⻓,比如Kafka,可以保存全部历史数据。
2. 当某个或某些指标有重新处理的需求时,按照新逻辑写⼀个新作业,然后从上游消息队列的最开始重新消费,把结果写到⼀个新的下游表中。
3. 当新作业赶上进度后,应⽤切换数据源,读取2中产⽣的新结果表。
4. 停止老的作业,删除老的结果表。
1.5.4 Lambda vs Kappa架构
1.6 实时数仓与离线数仓

1.7 数仓发展趋势
(1)实时数据仓库:满⾜实时化&⾃动化决策需求
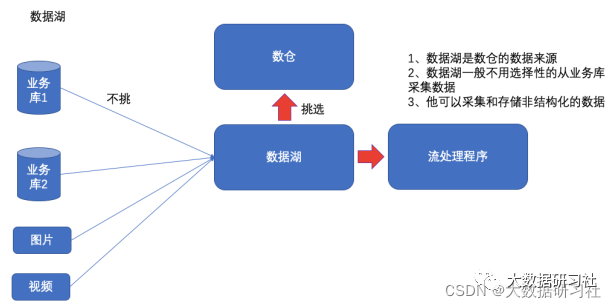
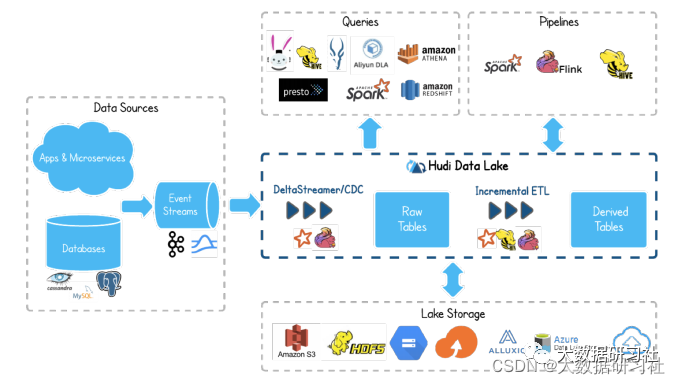
(2)结合数据湖:⽀持海量、复杂数据类型(⽂本、图像、视频、⾳频)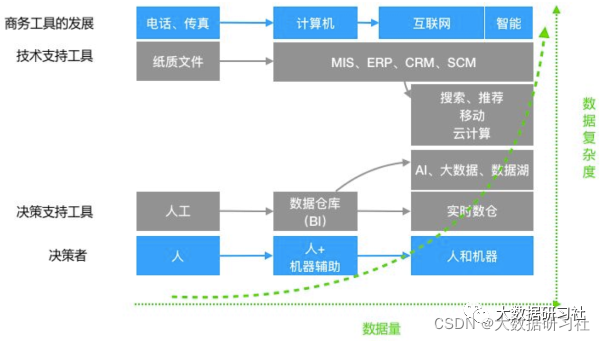
1.8 架构选择
(1)看具体业务需求,适合需求的架构才是最合适,离线⼤数据架构在很多公司仍然⽐较实⽤(性价⽐⾼)
(2)在真实的场景中,很多时候并不是完全规范的Lambda架构或Kappa架构,可以是两者的混合,比如⼤部分实时指标使⽤Kappa架构完成计算,少量关键指标(⽐如金额相关)使⽤Lambda架构⽤批处理重新计算,增加⼀次校对过程。
(3)为了应对更⼴泛的场景,大多数公司采用混合架构
1> 从架构层⾯来看是Lambda架构和Kappa架构混合
2>从数仓形态来说是离线数仓和实时数仓混合
3>通俗来讲:离线和实时数据链路都存在,根据每个业务需求选择在合适的链路上来实现
二、推荐系统架构及解决方案
2.1 推荐系统是什么
2.1.1 推荐系统的概念
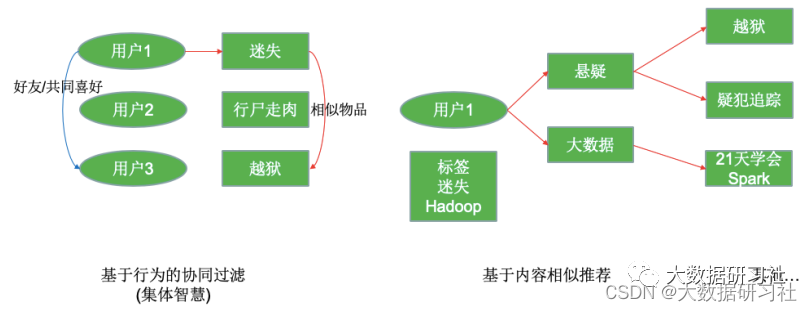
定义:根据⽤户的历史⾏为和基本信息,向⽤户推荐他感兴趣的内容,做到千⼈前⾯(个性化定制)。
2.1.2 推荐系统解决了什么问题
(1)解决信息过载问题
京东、天猫、拼多多、头条、抖⾳等互联⽹公司的商品、资讯、⽂章、视频基本都是⼏百上千万,甚⾄上亿,在这种信息过载的情况下,需要解决如下问题:
<1>⽤户侧:怎么样找到感兴趣的物品?
<2>系统侧:怎么样展示海量物品给⽤户已达到商业⽬的?
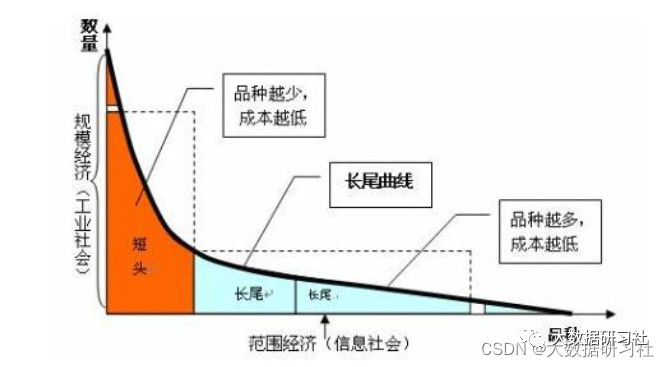
(2)挖掘⻓尾
<1>⼤多数冷⻔物品⽆法呈现给⽤户,但他们的价值可能超过热⻔物品
<2>举例:亚⻢逊图书类⽬57%的收⼊来⾃⻓尾冷⻔书籍
⻓尾理论:由于成本和效率的因素,当商品储存、流通、展示的场地和渠道⾜够宽⼴,商品⽣产成本急剧下降以⾄于个⼈都可以进⾏⽣产,并且商品的销售成本急剧降低时,⼏乎任何以前看似需求极低的产品,只要有卖,都会有⼈买。这些需求和销量不⾼的产品所占据的共同市场份额,可以和主流产品的市场份额相当,甚⾄更⼤。
(3)提⾼⽤户体验
搜索:⽬标明确⼀般直接采⽤搜索引擎,好的搜索结果可以提⾼⽤户体验
推荐:当⽤户需求不明确时,推荐系统可以推荐⽤户感兴趣的物品
推荐系统可以推荐⽤户感兴趣但很难在海量物品中⾃⼰发现的物品,例如:我们经常在各⼤电商买了⾃⼰感兴趣但是⾮必须的商品,这就是推荐系统的功劳。
2.1.3 学习推荐系统的必要性
有必要,但要量力而行,找准⾃⼰的⽅向,⼤多数⼈不适合做算法,不要硬上,容易⾛⽕⼊魔。
2.2 推荐主逻辑
挑战:从海量物品或者内容中挑选出感兴趣的条⽬,并满⾜50ms~300ms的低延迟要求( 99%的请求在300ms内返回 )。
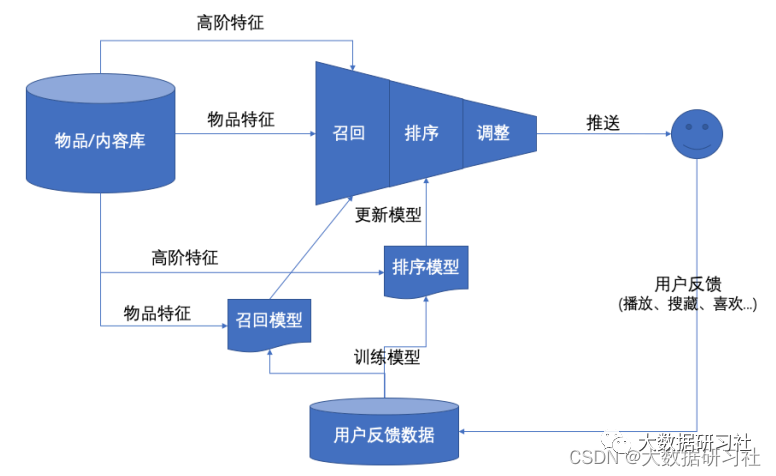
2.3 项目核心模块
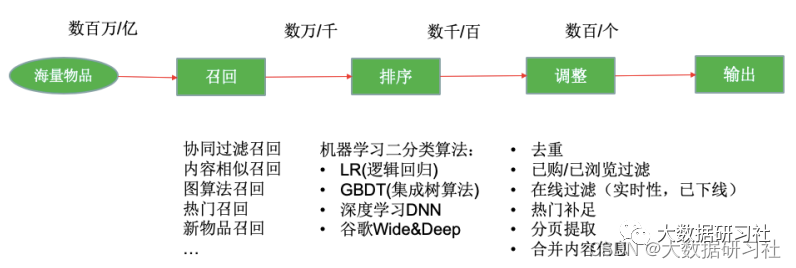
推荐系统的核心就是要在庞⼤的商品、⽂章、好友等⼈或物中找出⽬标⼈或者⼈群喜欢的⼈或者物,要完成这项⼯作整体流程是⽐较⻓的,⼀般按照先后顺序分为如下⼏个核⼼模块,下⾯是各模块的职责及说明:
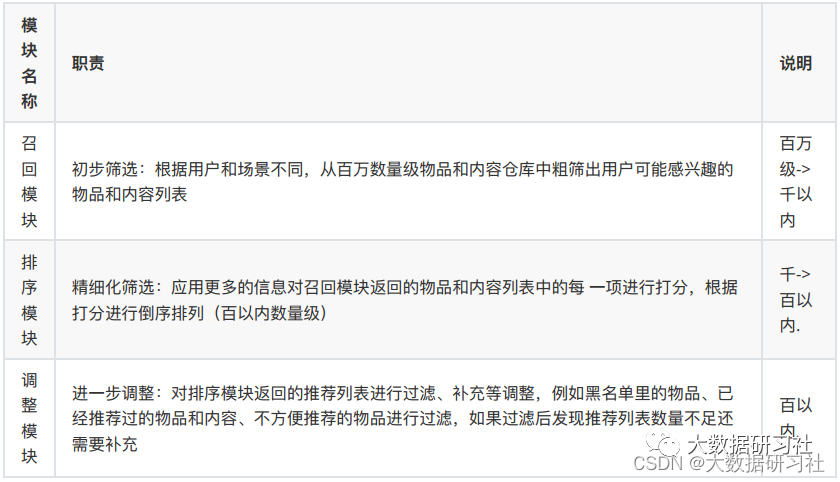
2.3.1 召回模块
召回模块的意义在于从海量的物品中找出⽤户可能感兴趣的⼩部分物品,不⾄于推荐的数量太多。因为要在原始的海量物品上进⾏召回,所以召回的规则、算法或者说模型不能太复杂,否则计算量成指数倍增⻓根本不可能实现。
常⻅的召回⼿段有如下⼀些:

2.3.2 排序模块
排序是推荐系统的第⼆阶段,从召回阶段获得少量的物品/内容交给排序阶段,排序阶段可以融⼊较多特征,使⽤复杂模型,来精准地做个性化推荐。排序所强调的是快和准,快指的是⾼效的反馈结果,准指的是推荐结果准确性⾼。
排序模块常⻅的⼿段有如下⼀些:

2.3.3 调整模块
经过召回阶段的初步筛选和排序阶段的精细化筛选剩下的物品/内容已经⾮常少了且更接近于⽤户的真实喜好,但是这些物品/内容还不能直接推荐给⽤户,⼀般来说根据业务需求还需要对推荐结果进⾏调整。常⻅的调整策略往往跟业务场景紧密挂钩,以电商为例,有如下策略:
1. 过滤掉⽤户已经购买过的物品
2. 过滤掉不适合公开展示的物品,⽐如成⼈⽤品
3. 去掉重复推荐的物品/内容
4. 去掉⽤户评分过低物品/内容
5. 去掉单独宣传的爆款商品避免曝光浪费
6. 替换成同型号利润率⾼的物品
注意:召回和排序阶段往往需要⼤量的运算,所以调整阶段的策略往往都不会放在召回和排序阶段去做,这也是调整模块独⽴出来的原因。
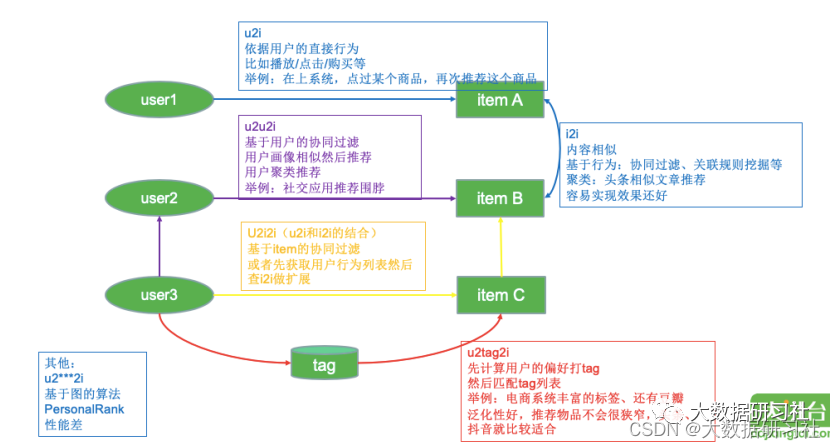
2.3.4 常⻅召回路径
推荐系统中常⻅的名词,如i2i、 u2i、 u2i2i、 u2u2i、 u2tag2i,它们指的是召回路径或者叫召回流派。这⾥通过⼀个图来给⼤家解释下召回路径:
2.4 推荐系统典型架构
2.4.1 Netflix经典推荐系统架构
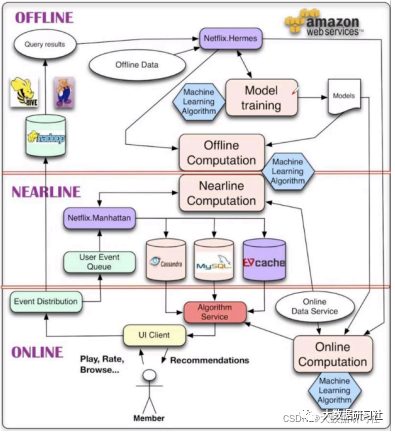
(1)在线层:
特点:既能处理海量数据,⼜能及时响应⽤户请求
优点:快速响应,使⽤最新输⼊数据,⽐如200ms
缺点:不能使⽤复杂算法,只能是简单算法(逻辑回归)
(2)离线层:
特点:⼤部分计算包括模型训练都在这⼀层完成
优点:⽀持复杂算法、可对海量数据进⾏计算
缺点:不能对最新情景和最新数据做出实时响应,只能按⼩时或者天粒度
(3)近线层:
特点:离线和在线的这种,⼀般将结果存⼊⾼速缓存
优点:能使⽤到⼏乎所有最新数据,延迟10秒~1分钟级别,允许更复杂算法,加载查询更多数据
(4)综合使⽤:
天粒度:离线层做矩阵分解,得到⽤户向量和物品向量,存储到MySQL(为什么不提前把每个⽤户的推荐列表计算出来并存起来?太⼤)
10秒:近线层根据⽤户⾏为,查询topn物品相似列表存⼊Cassandra
200毫秒:在线层查询第⼆步的结果,更新推荐列表
2.4.2 推荐系统通⽤架构
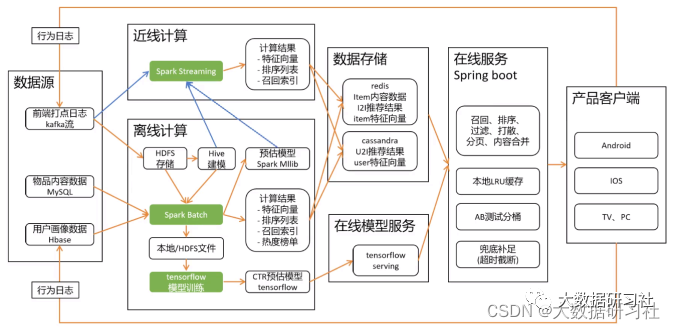
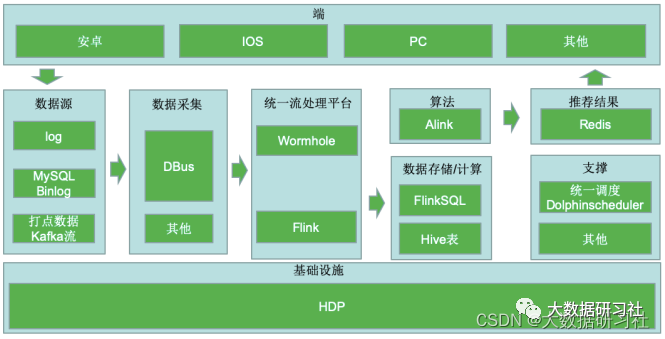
2.4.3 推荐系统架构Flink版
(1)核⼼架构如下图:
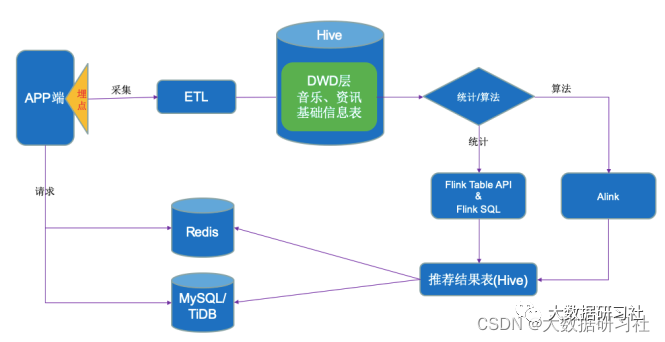
(2)项⽬应⽤:
三、补充:Flink+Alink当大数据遇见机器学习
⼤数据技术深度结合⼈⼯智能(AI)将是未来发展的⼀个重要⽅向,⽽机器学习是⼈⼯智能的重要分⽀和最流⾏的实现⽅式。
3.1 基于Spark的机器学习架构
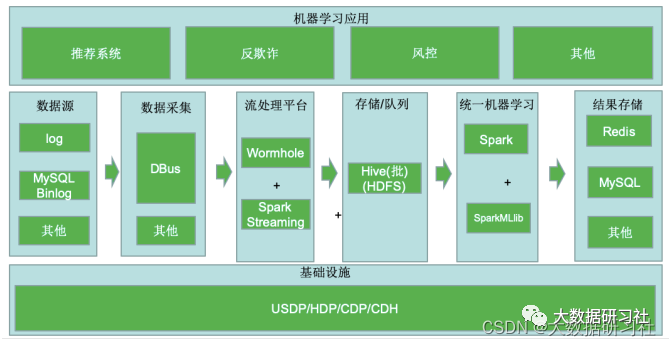
以往在⾯对⼤数据下的机器学习场景时,⼤家往往想到的是SparkMLlib,架构如下: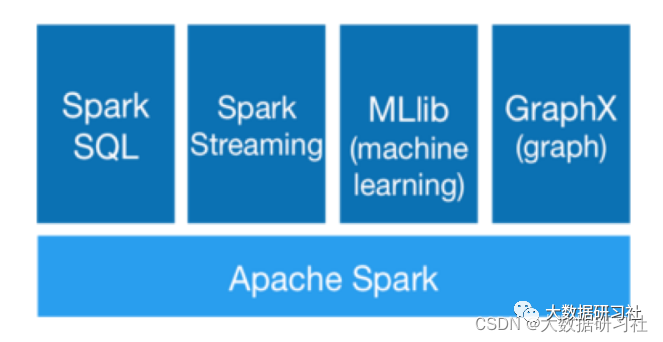
 3.2 从FlinkML到Alink
3.2 从FlinkML到Alink
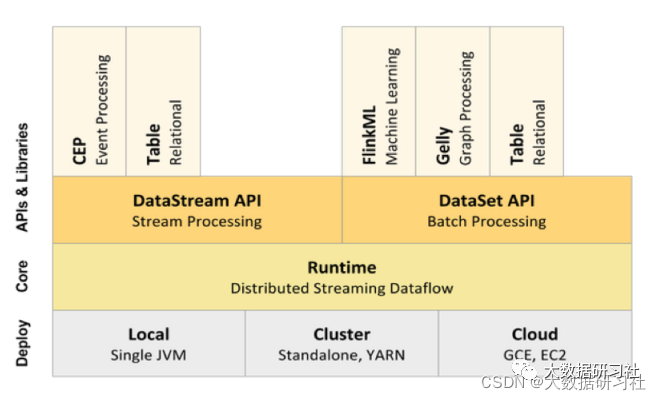
3.2.1 Flink1.9之前
3.2.2 Flink1.9之后
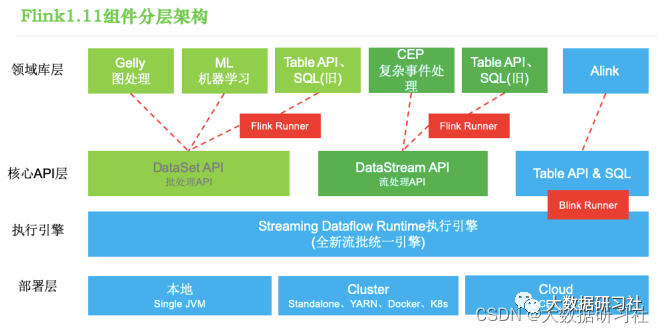
( 1)部署层
Flink⽀持本地( Local)模式、集群( Cluster)模式等。
( 2)执⾏引擎层
执⾏引擎层是核⼼API的底层实现,位于最低层。执⾏引擎层提供了⽀持Flink计算的全部核⼼实现。
执⾏引擎层的主要功能如下。
<1>分布式流处理。
<2>从作业图( JobGraph)到执⾏图( ExecutionGraph)的映射、调度等。
<3>为上层的API层提供基础服务。
<4>构建新的组件或算⼦。
执⾏引擎层的特点包括以下⼏点:灵活性⾼,但开发⽐较复杂;表达性强,可以操作状态、 Time等。
( 3)核⼼API层
核⼼API层主要对⽆界数据流和有界数据流进⾏处理,包括DataStream API和DataSet API,以及实现了更加抽象但表现⼒稍差的Table API、 SQL。
<1>DataStream API:⽤于处理⽆界数据,或者以流处理⽅式来处理有界数据。
<2>DataSet API:⽤于对有界数据进⾏批处理。⽤户可以⾮常⽅便地使⽤Flink提供的各种算⼦对分布式数据集进⾏处理。DataStream API和DataSet API是流处理应⽤程序和批处理应⽤程序的接⼝,程序在编译时⽣成作业图。在编译完成之后, Flink的优化器会⽣成不同的执⾏计划。根据部署⽅式的不同,优化之后的作业图将被提交给执⾏器执⾏。
<3>Table API、 SQL:⽤于对结构化数据进⾏查询,将结构化数据抽象成关系表,然后通过其提供的类SQL语⾔的DSL对关系表进⾏各种查询。
( 4) 领域库层
Flink还提供了⽤于特定领域的库,这些库通常被嵌⼊在API中,但不完全独⽴于API。这些库也因此可以继承API的所有特性,并与其他库集成。
在API层之上构建的满⾜特定应⽤的实现计算框架(库),分别对应⾯向流处理和⾯向批处理这两类。
<1>⾯向流处理⽀持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作)。
<2>⾯向批处理⽀持:FlinkML(机器学习库)、 Alink(新开源的机器学习库) 、 Gelly(图计算)。
Flink背后的商业公司Data Artisans被阿⾥收购之后,从Flink1.9开始FlinkML模块已经没有了,⼀直在重构,⾄今还没有正式回归;阿⾥开源的Alink(新开源的机器学习库)已经⾮常成熟。
3.3 基于Flink+Alink的机器学习架构
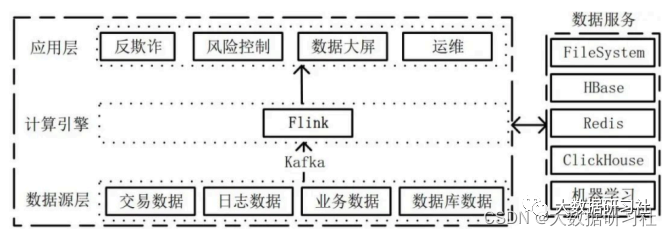
3.3.1 Flink在⼤数据架构中的位置
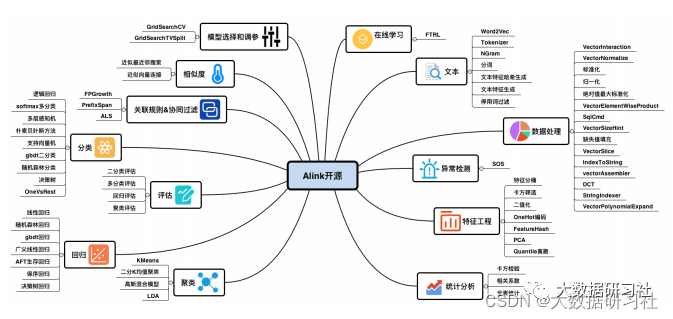
3.3.2 认识Alink
Alink是阿⾥巴巴计算平台事业部PAI团队研发的基于Flink的机器学习框架。
Alink于2019年11⽉正式开源。
Alink提供了丰富的算法组件,是业界⾸个同时⽀持批/流算法的机器学习框架。
开发者利⽤Alink可以⼀键搭建覆盖数据处理、特征⼯程、模型训练、模型预测的算法模型开发的全流程。
Alink的名称取⾃相关名称( Alibaba、 Algorithm、 AI、 Flink、 Blink)的结合。
https://gitee.com/mirrors/Alink
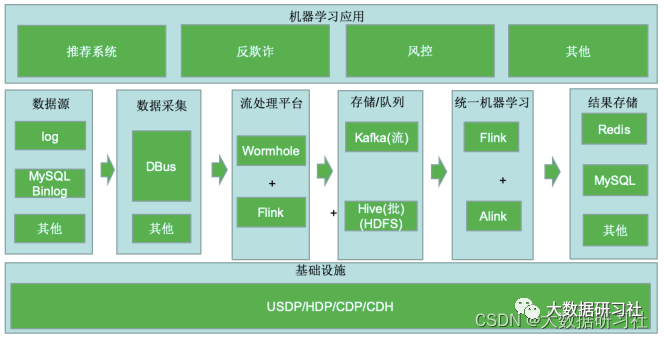
3.3.3 典型架构
3.4 Flink+其他主流⼈⼯智能框架
Flink+⽬前主流的⼈⼯智能框架(如PyTorch、 TensorFlow、 Kubeflow),可替代Alink,亦可与Alink互补,多为互补。
欢迎点赞 + 收藏 + 在看 素质三连 完
▼ 往期精彩回顾 ▼ 程序员,如何避免内卷 Apache 架构师总结的 30 条架构原则 【全网首发】Hadoop 3.0分布式集群安装 大数据运维工程师经典面试题汇总(附带答案) 大数据面试130题 某集团大数据平台整体架构及实施方案完整目录 大数据凉凉了?Apache将一众大数据开源项目束之高阁! 实战企业数据湖,抢先数仓新玩法 Superset制作智慧数据大屏,看它就够了 Apache Flink 在快手的过去、现在和未来 华为云-基于Ambari构建大数据平台(上) 华为云-基于Ambari构建大数据平台(下) 【HBase调优】Hbase万亿级存储性能优化总结 【Python精华】100个Python练手小程序 【HBase企业应用开发】工作中自己总结的Hbase笔记,非常全面! 【剑指Offer】近50个常见算法面试题的Java实现代码

