





数据湖是一个集中式的存储库。如上图所示,在数据湖的外围会有各类不同的应用或者系统,这些应用产生的数据就好比是一条条小溪,不需要做任何的加工或结构化处理,可以直接汇聚到数据湖里。 任意规模数据湖必须要提供任意规模的数据存储能力。理想情况下,数据湖的存储能力最好能够保存企业所有的数据,因为随着数据规模不断地增加,数据湖必须要支持超大规模的存储。而且,这个存储是可以任意扩展的。所以,数据湖底层的存储普遍都是采用对象存储或者 hadoop 的 HDFS。 任意结构数据湖可以存储海量任意类型的数据。这些数据包含结构化数据(行和列)、半结构化数据(如CSV、日志、XML、JSON)、非结构化数据(如email、文档、PDF等)和二进制数据(如图像、音频、视频)。 数据湖中的数据是原始数据,是业务数据的完整副本,这些数据应该保持在业务系统中原来的状态。 数据湖需要具备完善的数据管理能力(包括元数据),能够管理各类数据相关的要素,包括数据源、数据格式、连接信息、数据schema、权限管理等。如果不具备完善的数据的管理功能,数据湖就很容易变成数据沼泽。 数据湖要具备完善的数据生命分析管理能力。数据湖需要支撑各种各样的数据源,同时要从这些数据源中去获得全量的或者是增量的数据进行规范的存储,并能够把结果保存到合适的存储的引擎中,满足不同的应用的访问需求。
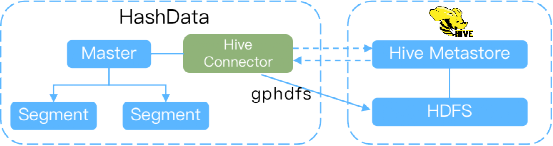
Hive连接器
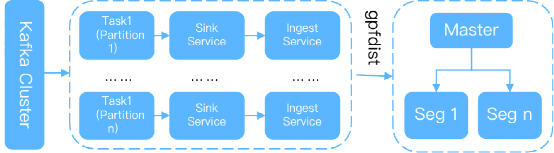
Kafka连接器
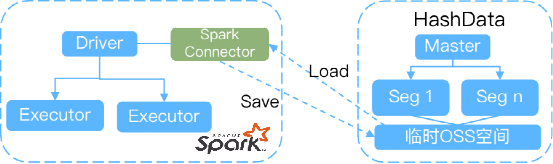
Spark连接器
构建数据联邦,无需搬迁数据,可以通过标准SQL实现多数据源联邦查询; 连接各类数据源,完成数据采集,且满足企业批量和实时的时效性要求。通常来说,外部表可以满足企业对跑批业务的需求,而连接器可以很好地满足对实时性比较高的业务需求; 实现Spark 计算引擎集成,构建企业级湖仓一体的数据分析平台。

文章转载自HashData,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
