





01
背景简介
Background introduction
1.1 Kafka简介

1.2 Kafka与数据库进行交互的场景
典型的关系型数据库,需要面临大量的数据对外输出的需求,不仅仅是通过ODBC、JDBC、Python等接口为应用提供数据,同时也有ETL场景或作为数据同步源(或目的)端的需求。当业务基于不同平台、模块化开发时,数据同步、推送时往往需要在多种传统关系型数据库(Oracle、MySQL、PostgreSQL),半结构化数据存储(JSON\XML),NoSQL 类型(Redis、Hive、Hbase)数据源中进行交互,所以关系型数据库如何把数据推送、写入,也衍生出了多种方案,这里我们从三个典型的技术方案(非产品化产品)来进行解析。
02
HGDB与Kafka的数据交互方案
HGDB and Kafka data interaction scheme
(基础测试环境:CentOS 7 + HGDB V6的测试环境)
2.1 Kafka Connector方案
2.1.1 Kafka Connector介绍
Kafka作为消息中间件,提供了非常多的类型数据源支持,connector顾名思义连接器,就是用来在Kafka与其他数据库、应用程序间进行可扩展且可靠的流式传输的(Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka® and other data systems)。按照源端与目的端的划分,可分为Source connector和Sink connector,分别用于数据写入和写出Kafka。
2.1.2 Kafka Connector部署和使用
主要组件;
分别启动各组件,如下;
/opt/kafka_2.12-3.1.0/bin/zookeeper-server-start.sh opt/kafka_2.12-3.1.0/config/zookeeper.properties 1>/dev/null 2>&1 &
/opt/kafka_2.12-3.1.0/bin/kafka-server-start.sh opt/kafka_2.12-3.1.0/config/server.properties 1>/dev/null 2>&1 &
/opt/kafka_2.12-3.1.0/bin/connect-standalone.sh opt/kafka_2.12-3.1.0/config/connect-standalone.properties opt/kafka_2.12-3.1.0/config/source-postgresql.properties opt/kafka_2.12-3.1.0/config/sink-postgresql.propps
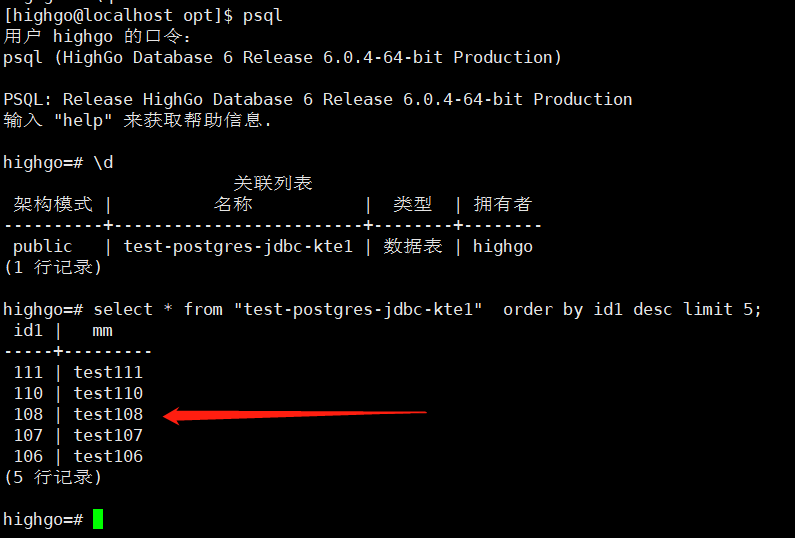
测试HGDB中的数据写入Kafka,如下;
测试表中插入数据,并用Kafka消费端去查看数据,如下所示;
./kafka-console-consumer.sh --bootstrap-server 192.168.98.18:9092 --topic test-postgres-jdbc-kte1 --from-beginning


测试Kafka数据写入HGDB,如下;
我们可以用刚刚写入Kafka的数据,写入到另外一个数据库,这里新开一台测试机并部署HGDB数据库,并使用sink connector从Kafka中写入数据。
先查看之前source connector生成的topic,如图;

新启动一个数据库,配置sink connector后,启动sink,如下所示;
/opt/kafka_2.12-3.1.0/bin/connect-standalone.sh opt/kafka_2.12-3.1.0/config/connect-standalone.properties opt/kafka_2.12-3.1.0/config/sink-postgresql.properties
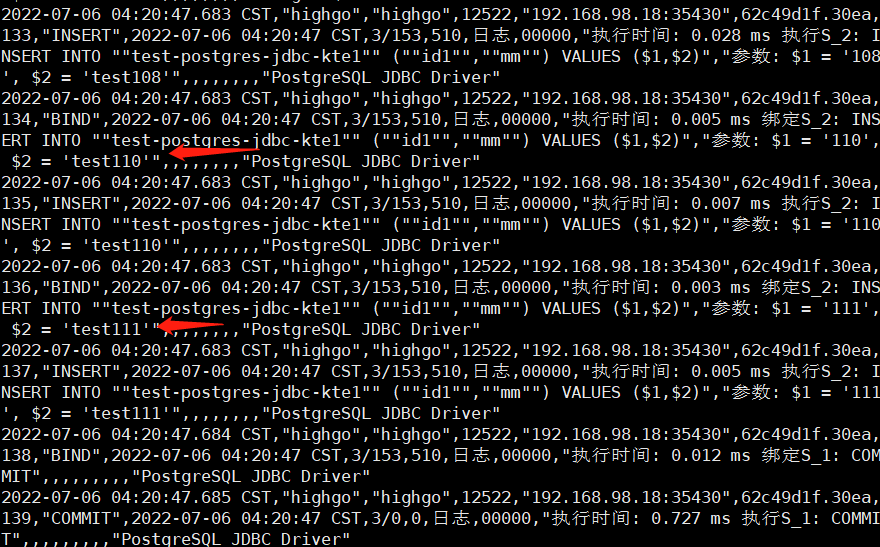
查看目的端数据库的日志,数据是以insert形式插入的(另外还支持upsert ),如图;
2.2 Kafka_FDW方案
2.2.1 Kafka_FDW介绍
看到FDW字眼,一定就是PostgreSQL声名在外的外部数据封装器功能了。
FDW的介绍可访问以下网址了解:
https://wiki.postgresql.org/wiki/Foreign_data_wrappers
FDW的一句话总结就是“只要网络通,全都能连上”。
关于Kafka_Fdw的GitHub请移步:
https://github.com/adjust/kafka_fdw
请注意本方案目前不建议作为生产实践使用(At this point the project is not yet production ready)。
2.2.2 Kafka_FDW 在HGDB上部署
准备编译环境和编译安装,如下;
Kafka_Fdw依赖了librdkafka C库,所以需要先进行准备,可使用源码编译安装(librdkafka-master)或者yum(需配置相关repo路径)安装,根据GitHub中的readme操作即可,这里未做展示。
对Kafka_Fdw的安装,使用源码安装(最新版本即可)。
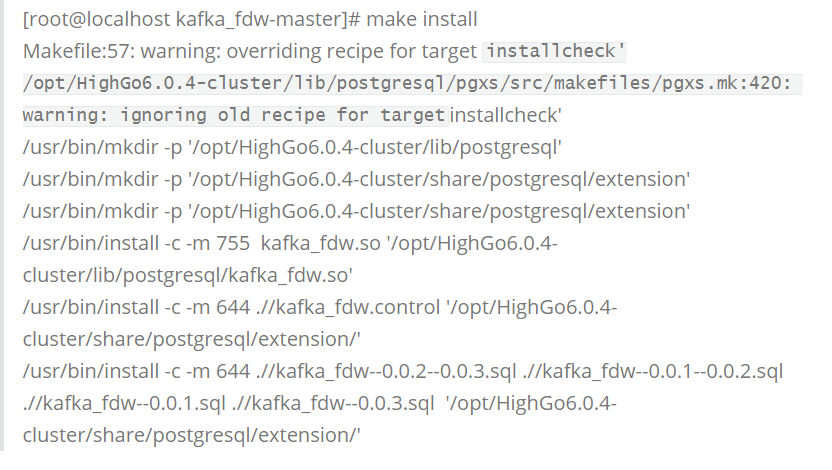
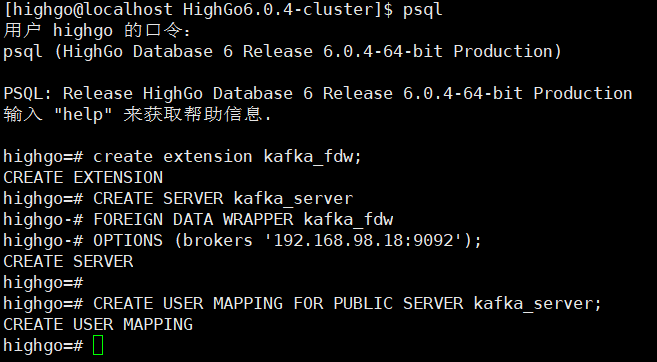
创建Kafka_Fdw插件,如图。
2.2.3 Kafka_FDW使用
使用Kafka_Fdw进行数据交互;
创建Kafka的topic,如下;
./kafka-topics.sh --create --bootstrap-server 192.168.98.18:9092 --replication-factor 1 --partitions 1 --topic kafka_hgdb

在数据库中创建外部表,如下;
CREATE FOREIGN TABLE kafka_test ( id int, mm text ) SERVER kafka_server OPTIONS (format 'csv', topic 'kafka_hgdb', batch_size '30', buffer_delay '100');

在HGDB插入数据,在Kafka侧读取,如下;
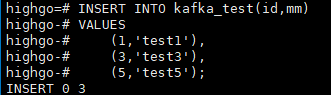
插入数据,并附图;
INSERT INTO kafka_test(id,mm) VALUES (1,'test1'), (3,'test3'), (5,'test5');
在Kafka侧读取,附图;

在Kafka中插入数据,在HGDB读取,如下;
直接用Kafaka生成数据,插入 (7,test7),(9,test9),附图;

在外部表中查看,数据同样可在外部表中查阅到,附图;
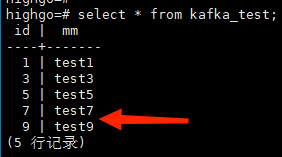
2.3 日志解析输出到Kafka方案
2.3.1 日志解析技术
Wal日志文件是数据库已提交事务的落盘文件,直接对wal文件进行解析,可避免直连数据库,对数据库服务器的压力明显减小。
2.3.2 日志解析方案
主要使用到的组件:
组件 | 说明 |
Libjansson | C library for encoding, decoding and manipulating JSON data |
avro | 数据序列化 |
libserdes | schema-based serializer C/C++ library with support for Avro |
Kafkacat | 基于Kafka C语言的librdkafka库的Kafka客户端 |
wal2json | 数据库日志文件输出为JSON格式 |
2.3.3 日志解析使用
在postgresql.conf配置中预载wal2json,如图;

创建PG slot,如下;
(使用-P参数指定wal2json plugin)
pg_recvlogical -h 127.0.0.1 -p 5432 -U postgres -d test --slot test_slot --create-slot-P wal2json
创建Kafka的topic,如下;
./kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic testtopic1
测试wal2json插件的解析,-f - 表示输出到屏幕,如下;
pg_recvlogical -h 127.0.0.1 -p 5432 -U postgres -d test -S test_slot --start -f -
开启一个psql,对表插入一条数据后查看,如下;
insert into test_table values (300,'aaaabbbb');

把wal输出给通过通道传输给kafkacat,如下;
pg_recvlogical -h 127.0.0.1 -p 5432 -U postgres -d test -S test_slot --start -f - |kafkacat -b 127.0.0.1:9092 -t testtopic1

2.4 方案对比
本次使用了3个方案,简单对比一下。
| 方案 | 源端 | 目的端 | 连接方式 |
Connector方案 | √ | √ | JDBC |
FDW方案 | √ | √ | 外部表方式 |
日志解析方案 | √ | 不适用 | 复制槽 |
03
瀚高数据库同步软件
Hangao data synchronization software
小结
上述的3种方案,是关系型数据库通过Kafka进行数据交互的典型思路,但在生产环境中,通过人工管理数据同步存在这配置文件过多、管理复杂和监控手段匮乏的问题,对运维人员并不友好。为此,瀚高从简单易用和稳定高效的角度出发,为用户打造了一款专用于数据同步的产品:瀚高数据同步软件V1.0。
瀚高数据同步软件支持跨操作系统、异构数据源间的实时数据同步和数据处理,并全面兼容国产平台。瀚高数据同步软件支持集中调度和分布式部署,将数据捕获、传输、处理、监控等功能集于一身,帮助用户紧贴业务本质、化繁为简。数据捕获支持数据库接口或直接对事务日志进行解析,支持对增量数据实时捕获,利用消息传输机制屏蔽异构平台的差异,可实现在极小系统开销前提下的秒级数据同步。
通过软件提供的全图形化界面,用户可直观的对多种类型的源端、目的端数据库进行配置管理,按需定制同步对象,并支持消息的转换、映射、过滤、脱敏,同时为数据同步作业提供任务调度和运行状态的全图形化监控。
瀚高数据同步软件已提供对多品牌的数据库支持,支持一对一、一对多、多对多等使用方式,支持数据同步、(多源)数据汇聚、数据下发、新老系统双轨并行期双向数据复制等,适用于各类数据同步场景。
目前,瀚高数据同步软件已成功上线多个省市的生产系统,化身数据流转“大动脉”,为业务系统数据流转提供“新鲜血液”,保障了多业务系统的健康、稳定运转。
本期内容到这里就结束啦,感谢您的喜欢~
--/THE END/--
完

