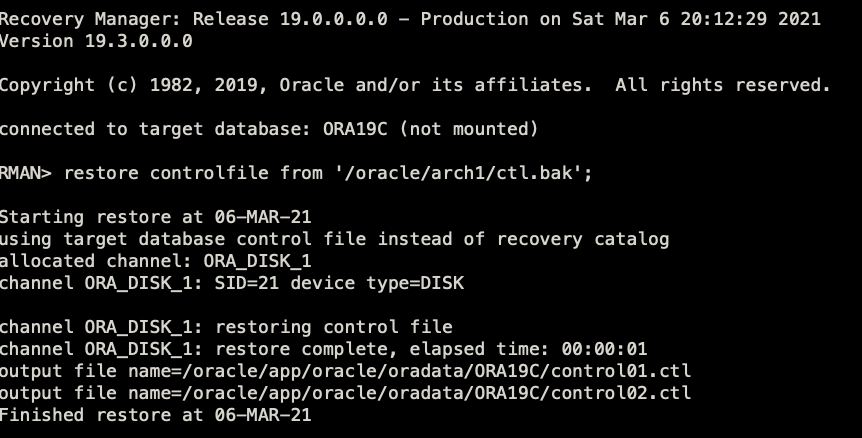
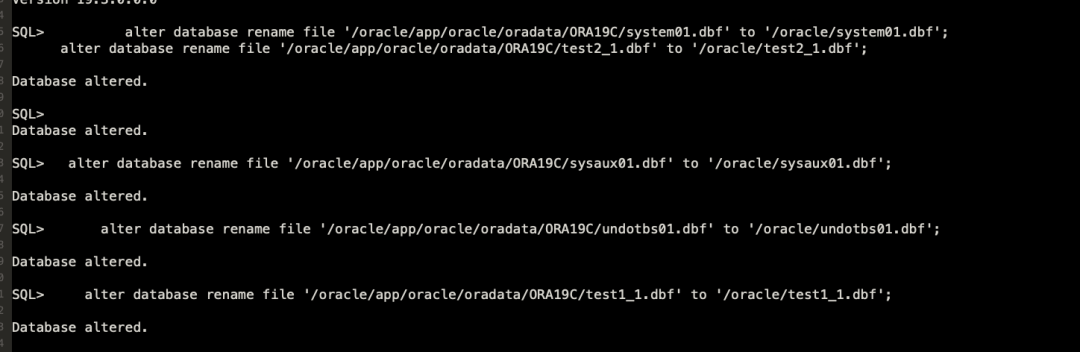
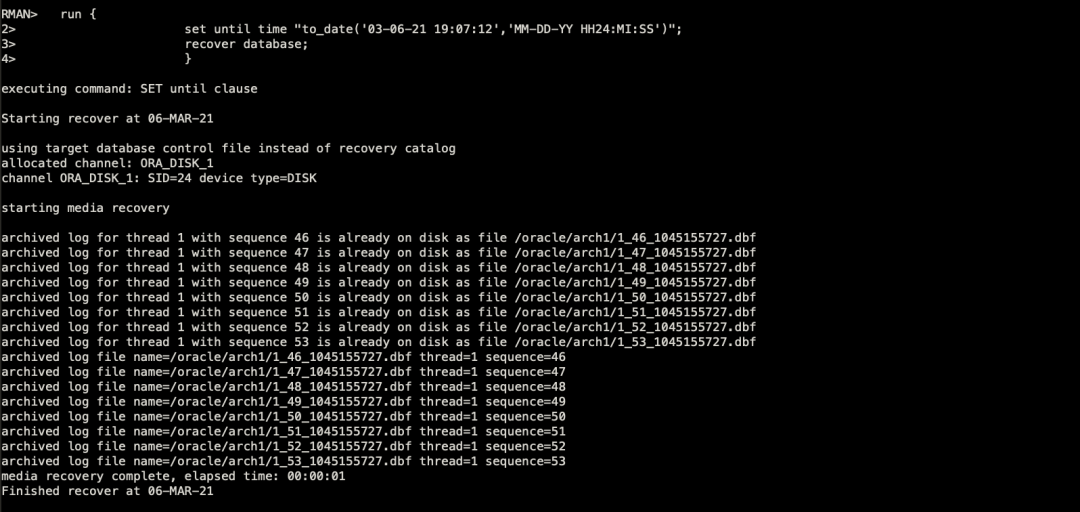
最近给一套库做不完全恢复,其中映象较为深刻的对RMAN-20207(如下图)的报错处理方式,下面在测试环境中来复现。

1、前提条件,全库备份在,后续归档文件在。

==》我这套测试环境中只有1,2,3,4,5。这个5个数据文件。system,sysaux,undo(rac环境中各个节点都要还原)这个三类表空间是必须要恢复的。5号表空间是模拟业务表空间,是我们这次要恢复的目标。
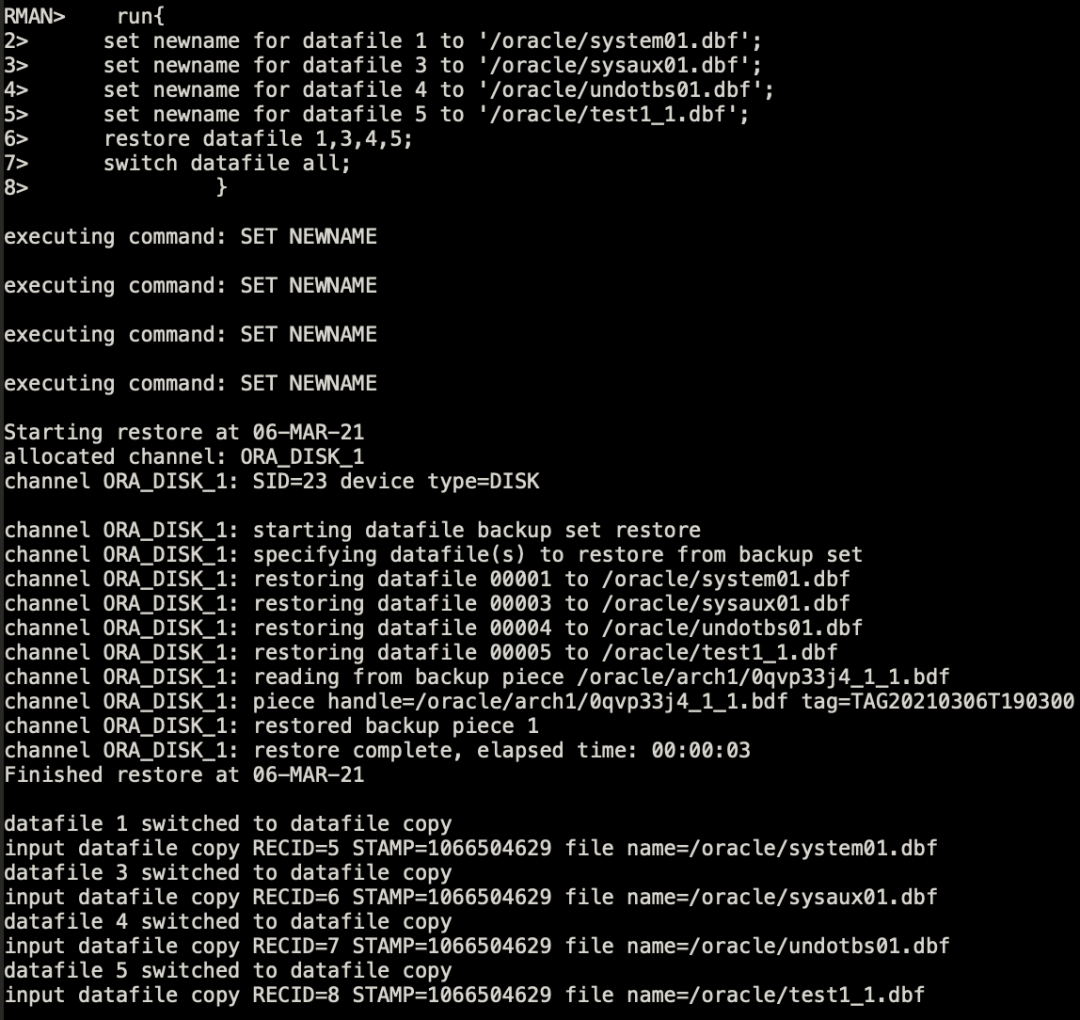
==》通过如上命令还原表空间对应的数据文件。
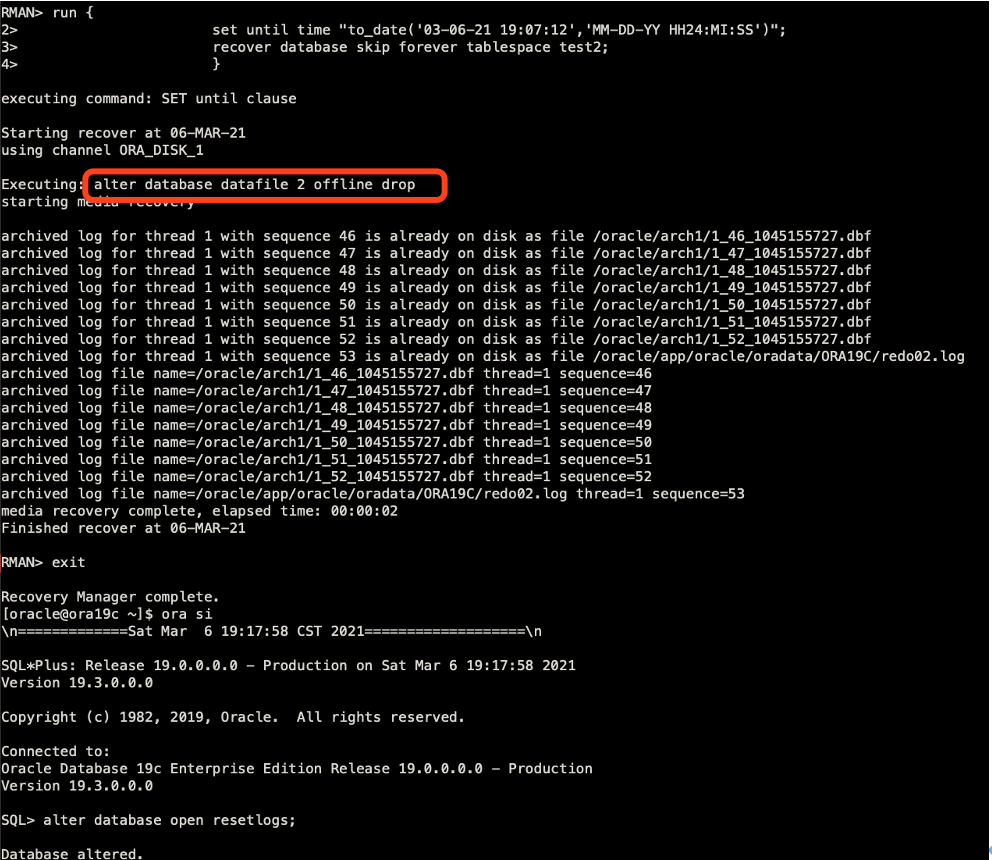
==》这里通过skip方式跳过不需要恢复的表空间,恢复完成后,使用resetlogs方式打开数据库。红框中2号文件被offlinedrop,这里的2号文件对应的是test2这个表空间。换个思路就是说,我们不使用skip命令,而是提前将不需要的表空间对应的数据文件给offlinedrop掉,就可以直接使用recoverdatabase ;进行恢复。(当然这是另外一种思路了)。
2、发现只恢复test1表空间,数据有丢失,需要二次恢复把test2表空间给加上如下图:
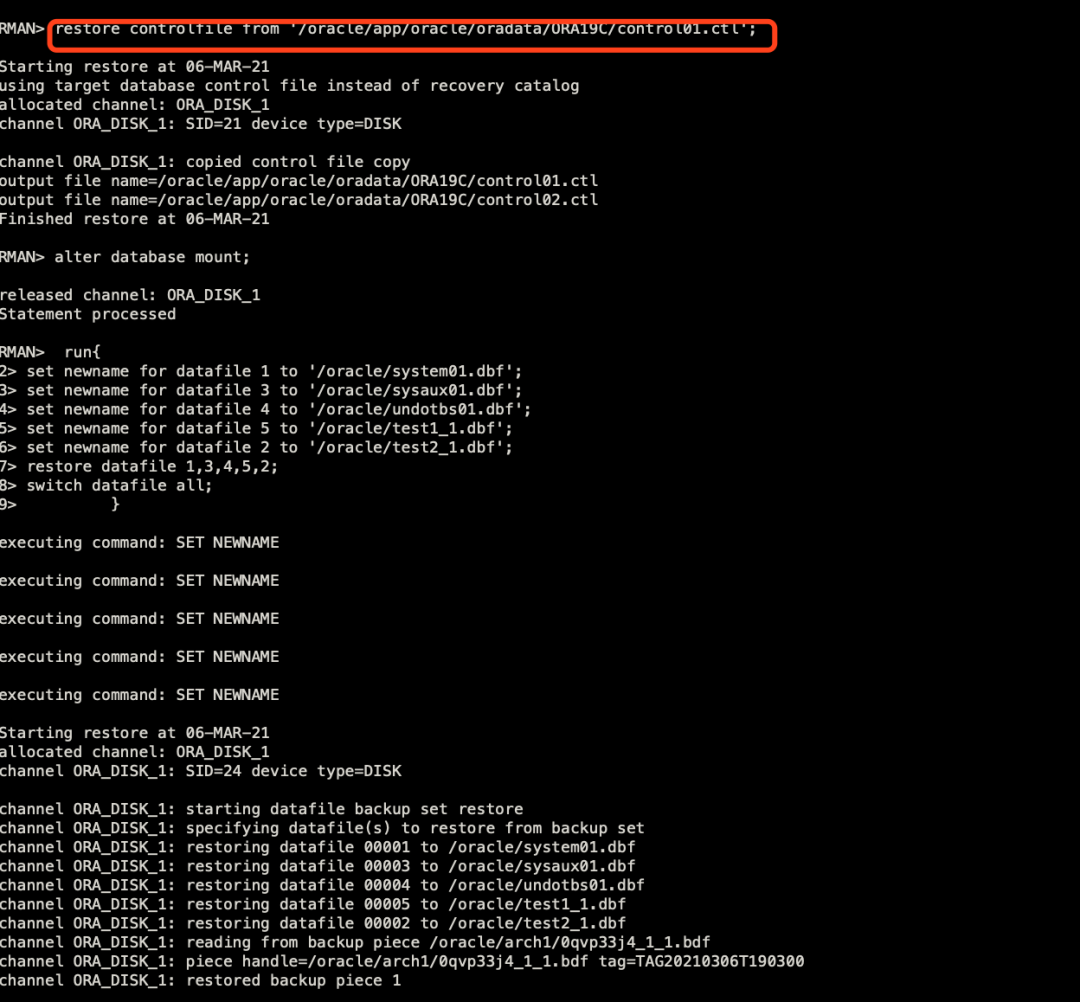
==》这里还原时新加了test2表空间对应的数据文件,2号文件。
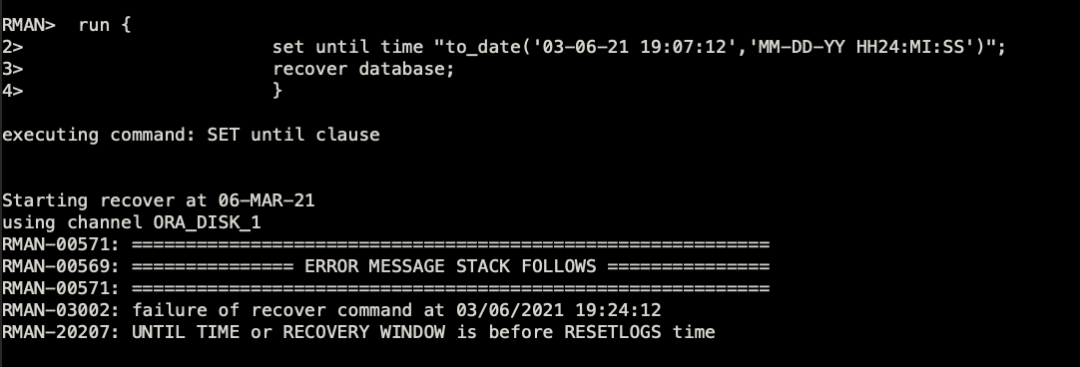
==》随后进行recover报RMAN-20209.这里就复现了之前生产的报错。
关于报错原因:
我这里模拟使用了resetlogs后的控制文件进行二次恢复的(如上图红框),因为incarnation发生了改变,导致恢复报错。实际上生产上进行了恢复就是犯了这个错误,从而引发后续一系列的问题。
1、通过resetdatabase toincarnation,调整到resetlog之前的incarnation号。此外,根据二次恢复需要,检查v$datafile中status状态,将新添加的文件修改为online(首次恢复,通过skip命令调整成了offline。实际生产中,我们虽然reset了incarnation,但是未将新增的文件给online就进行了recover,虽然recover没有报错,但在启库阶段数据库一直拉不起来,最终导致第三次重新恢复。

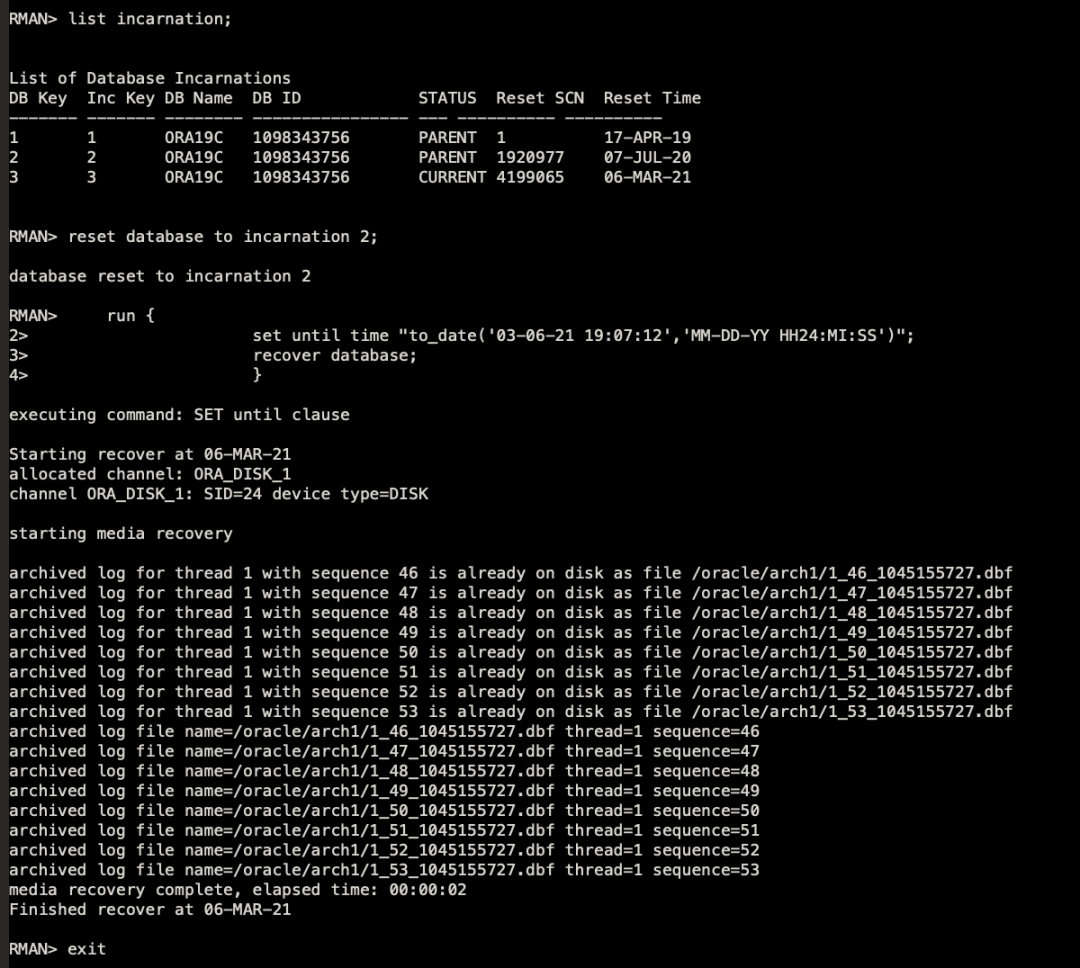
2、重新恢复一份resetlog前的控制文件,根据需要对文件进行重新rename,随后执行recover操作。