




基本环境 环境搭建 编译Dinky 部署Dinky 远程debug源码 总结 参考
 GitHub 地址
GitHub 地址 一、基本环境
| 环境 | 版本 |
| jdk | 1.8.0.181 |
| flink | 1.13.5 |
| centos | 7.4 |
| CDH | 6.3.1 |
| hadoop | 3.0.0 |
| nvm | 0.37.2 |
| node | v12.22.8 |
| maven | 3.8.1 |
| git | 2.31.1 |
| idea | 2021.2.3 |
| nginx | 1.20.1 |
| mysql | 8.0 |
| Dinky | dev |
| MAC | 12.2.1 |
二、环境搭建
安装配置JDK
1、到 oracle 官网下载 jdk1.8.0.181.tar.gz
2、使用 root 用户或者具有 sudo 权限的用户在 linux 上创建 jdk 存放目录
mkdir usr/java3、将jdk下载好的 jdk 上传到 usr/java 目录
4、解压
tar -zxvf jdk1.8.0.181.tar.gz5、配置 java 环境变量
JAVA_HOME=/usr/java/jdk1.8.0_181
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME CLASSPATH
6、重新加载环境变量
source etc/profile7、校验 java 环境是否安装成功
# linux 终端输入
java -version
# 安装成功信息
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
安装scala
1、下载 scala
cd data/
wget https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.tgz
2、使用 root 用户或者具有 sudo 权限的用户在 linux 上创建 scala 存放目录
mkdir usr/sala3、解压
tar -zxvf scala-2.12.8.tgz -C usr/scala4、配置环境变量
SCALA_HOME=/usr/scala/scala-2.12.8
PATH=$PATH:$SCALA_HOME/bin
export SCALA_HOME
5、校验是否安装成功
scala -version安装Hadoop集群环境
部署 dlink 默认hadoop 集群已经部署完毕,本案例使用 cdh6.3.1 部署的 hadoop 集群。
安装配置 Flink
1、下载flik
# 在linux 终端切换到下载flink 安装包目录
cd data/
# 下载flink 安装包
wget https://dlcdn.apache.org/flink/flink-1.13.5/flink-1.13.5-bin-scala_2.12.tgz
2、解压
tar -zxvf flink-1.13.5-bin-scala_2.12.tgz3、重命名
mv flink-1.13.5 flink4、配置环境变量
JAVA_HOME=/usr/java/jdk1.8.0_181
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
HADOOP_HOME=/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop
HADOOP_CONF_DIR=/etc/hadoop/conf
FLINK_HOME=/data/flink
PATH=$PATH:$JAVA_HOME/bin:$FLINK_HOME/bin:$HADOOP_HOME/bin
export JAVA_HOME CLASSPATH HADOOP_HOME HADOOP_CONF_DIR FLINK_HOME PATH
5、配置flink-conf.yaml 注意: 1、配置文件需要根据自己hadoop环境来做修改 2、环境变量必须配置HADOOP_CONF_DIR
jobmanager.rpc.address: localhost
jobmanager.rpc.port: 6123
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 4
parallelism.default: 1
high-availability: zookeeper
high-availability.storageDir: hdfs://nameservice1/user/flink/ha/
high-availability.zookeeper.quorum: 172.17.0.13:2181,172.17.0.9:2181,172,172.17.0.8:2181
high-availability.zookeeper.path.root: /flink
state.backend: filesystem
state.checkpoints.dir: hdfs://nameservice1/user/flink/flink-checkpoints
state.savepoints.dir: hdfs://nameservice1/user/flink/flink-savepoints
jobmanager.execution.failover-strategy: region
yarn.application-attempts: 4
env.hadoop.conf.dir: /etc/hadoop/conf
安装配置nginx(可选)
1、安装
说明:使用 linux root 用户或者具备 sudo 权限的普通用户操作
# 下载centos 版本nginx yum 源
wget -O etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# 清除缓存
yum makecache
# 安装nginx
yum -y install epel-release
yum -y install nginx
2、修改nginx配置
vim etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/doc/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 4096;
include etc/nginx/mime.types;
default_type application/octet-stream;
# Load modular configuration files from the etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include etc/nginx/conf.d/*.conf;
server {
listen 12000;
#listen [::]:80;
server_name bigdata3;
root data/dlink/html;
gzip on;
gzip_min_length 1k;
gzip_comp_level 9;
gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;
gzip_vary on;
gzip_disable "MSIE [1-6]\.";
# Load configuration files for the default server block.
include etc/nginx/default.d/*.conf;
location {
# dlink html错在目录
root data/dlink/html;
index data/dlink/html/index.html data/dlink/html/index.htm;
try_files $uri $uri/ index.html;
}
error_page 404 404.html;
location = 404.html {
}
# To allow POST on static pages 允许静态页使用POST方法
error_page 500 502 503 504 50x.html;
location = 50x.html {
}
location ^~ api {
# dlink 服务所在机器IP:端口
proxy_pass http://172.17.0.17:8889;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Real-IP $remote_addr;
}
}
}
3、查看安装版本号
nginx -v4、启动
设置开机启动
sudo systemctl enable nginx启动、重启、停止、重新加载
sudo service nginx start
sudo service nginx restart
sudo service nginx stop
sudo service nginx reload
5、校验是否启动成功
ps -ef | grep nginx启动正常,显示如下:
nginx 3277 4245 0 2月10 ? 00:00:00 nginx: worker process
nginx 3278 4245 0 2月10 ? 00:00:00 nginx: worker process
nginx 3279 4245 0 2月10 ? 00:00:00 nginx: worker process
nginx 3280 4245 0 2月10 ? 00:00:00 nginx: worker process
root 4245 1 0 2月10 ? 00:00:00 nginx: master process /usr/sbin/nginx
root 8222 28340 0 18:52 pts/0 00:00:00 grep --color=auto nginx
安装mysql
参考:https://cloud.tencent.com/developer/article/1584093
三、编译Dinky
安装前端编译环境
1、安装nvm
nvm 是 nodejs 版本管理工具,一个 nvm 可以管理多个 node 版本和 npm 版本。
1、在终端输入如下脚本,安装 nvm
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.37.2/install.sh | bash2、查看版本号
nvm -v2、安装nodejs
项目开发时所需要代码库
1、在终端输入如下脚本,安装 nodejs
# 在终端输入
nvm install v12.22.8
2、查看版本号
node -v安装后端编译环境
克隆源码
git clone https://github.com/DataLinkDC/dlinkIDEA导入代码
1、idea 中导入项目打开idea -> 在打开的页面找到OPEN -> 找到Dinky源码所在目录pom.xml文件 -> 点击open按钮会自动导入
2、idea配置自定义mavenPreferences -> 搜索框输入maven -> 修改 Maven home path 为自定义maven的根目录 -> 修改User settingsfile 为自定义maven的setting文件 -> 修改Local rerpository 为本地自定义仓库
3、idea自动加载项目
编译
进入代码的根目录,输入以下命令进行编译
mvn clean install -Dmaven.test.skip=true四、部署Dinky
上传安装包
Dlinky编译后在代码根目录下 build 文件夹中有一个 dlink-release-0.6.0-SNAPSHOT.tar.gz 文件,将dlink-release-0.6.0-SNAPSHOT.tar.gz 上传到部署目录 data/ 下。
解压安装包
tar -zxvf dlink-release-0.6.0-SNAPSHOT.tar.gz 重命名
mv dlink-release-0.6.0-SNAPSHOT dlink初始化数据库
1、创建mysql用户
在安装 mysql linux 终端输入 mysql -u root -p 进入数据库客户端
create user 'dlink'@'localhost' identified by 'dlink';2、创建数据库和表
将 data/dlink/sql 下 dlink.sql 脚本中的内容拷贝到 mysql 客户端执行,具体见包内脚本。
3、授权远程访问
GRANT ALL ON dlink.* TO 'dlink'@'%' IDENTIFIED BY 'dlink'; 4、刷新权限
FLUSH PRIVILEGES;修改数据库配置
cd data/dlink/config
将application.yml文件中数据库连接、数据库用户名、密码修改为当前部署环境的配置,如下,数据库连接修改为172.17.0.89,用户名为修改为dlink,密码为dlink,服务端口为8888
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/dlink?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: dlink
password: dlink
driver-class-name: com.mysql.cj.jdbc.Driver
application:
name: dlink
server:
port: 8888
mybatis-plus:
mapper-locations: classpath:/mapper/*Mapper.xml
#实体扫描,多个package用逗号或者分号分隔
typeAliasesPackage: com.dlink.model
global-config:
db-config:
id-type: auto
configuration:
##### mybatis-plus打印完整sql(只适用于开发环境)
# log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
log-impl: org.apache.ibatis.logging.nologging.NoLoggingImpl
# Sa-Token 配置
sa-token:
# token名称 (同时也是cookie名称)
token-name: satoken
# token有效期,单位s 默认10小时, -1代表永不过期
timeout: 36000
# token临时有效期 (指定时间内无操作就视为token过期) 单位: 秒
activity-timeout: -1
# 是否允许同一账号并发登录 (为true时允许一起登录, 为false时新登录挤掉旧登录)
is-concurrent: false
# 在多人登录同一账号时,是否共用一个token (为true时所有登录共用一个token, 为false时每次登录新建一个token)
is-share: true
# token风格
token-style: uuid
# 是否输出操作日志
is-log: false
创建plugins文件夹并上传依赖jar
plugins 文件夹下存放 flink 及 hadoop 的官方扩展 jar,根据实际应用,把对应 jar 放入 plugins中。
mkdir data/dlink/plugins
cp data/flink/lib data/dlink/plugins
最终plugins包含jar如下:
commons-cli-1.3.1.jar
flink-csv-1.13.5.jar
flink-dist_2.12-1.13.5.jar
flink-json-1.13.5.jar
flink-shaded-hadoop-3-uber.jar
flink-shaded-zookeeper-3.4.14.jar
flink-table_2.12-1.13.5.jar
flink-table-blink_2.12-1.13.5.jar
mysql-connector-java-8.0.28.jar
注意:flink-shaded-hadoop-3-uber.jar 需要将jar中srvlet文件夹删除
启动服务
cd data/dlink
sh auto.sh start
五、远程debug源码
修改启动脚本,开启远程调试
1、修改服务器上auto.sh脚本 修改脚本的start方法,在java -jar 中间添加上 -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=50001,具体如下:
#!/bin/bash
# 定义变量
# 要运行的jar包路径,加不加引号都行。注意:等号两边 不能 有空格,否则会提示command找不到
JAR_NAME="./dlink-admin-*.jar"
#java -Djava.ext.dirs=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/jre/lib:./lib -classpath ."/lib/*.jar" -jar dlink-admin-*.jar
# 如果需要将FLINK依赖直接加入启动脚本,在SETTING中增加$FLINK_HOME/lib
SETTING="-Dloader.path=./lib,./plugins -Ddruid.mysql.usePingMethod=false"
# 首次启动时候自动创建plugins文件夹和引用flink\lib包!
if [ ! -d "./plugins" ];then
echo 'mkdir plugins now'
mkdir plugins
cd plugins
if [ ! -d ${FLINK_HOME} ];then
echo 'WARNING!!!...没有找到FLINK_HOME环境变量,无法引用Flink/lib到plugins,请手动引用或复制Flink jar到plugins文件夹'
echo 'WARNING!!!...not find FLINK_HOME environment variable to reference Flink/lib to plugins, please reference or copy Flink jar to the plugins folder manually!!'
else
ln -s ${FLINK_HOME}/lib
cd ..
fi
fi
# 如果输入格式不对,给出提示!
tips() {
echo ""
echo "WARNING!!!......Tips, please use command: sh auto.sh [start|stop|restart|status]. For example: sh auto.sh start "
echo ""
exit 1
}
# 启动方法
start() {
# 重新获取一下pid,因为其它操作如stop会导致pid的状态更新
pid=`ps -ef | grep $JAR_NAME | grep -v grep | awk '{print $2}'`
# -z 表示如果$pid为空时执行
if [ -z $pid ]; then
nohup java $SETTING -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=50001 -jar -Xms512M -Xmx2048M -XX:PermSize=512M -XX:MaxPermSize=1024M $JAR_NAME > dlink.log 2>&1 &
pid=`ps -ef | grep $JAR_NAME | grep -v grep | awk '{print $2}'`
echo ""
echo "Service ${JAR_NAME} is starting!pid=${pid}"
echo "........................Start successfully!........................."
else
echo ""
echo "Service ${JAR_NAME} is already running,it's pid = ${pid}. If necessary, please use command: sh auto.sh restart."
echo ""
fi
}
# 停止方法
stop() {
# 重新获取一下pid,因为其它操作如start会导致pid的状态更新
pid=`ps -ef | grep $JAR_NAME | grep -v grep | awk '{print $2}'`
# -z 表示如果$pid为空时执行。注意:每个命令和变量之间一定要前后加空格,否则会提示command找不到
if [ -z $pid ]; then
echo ""
echo "Service ${JAR_NAME} is not running! It's not necessary to stop it!"
echo ""
else
kill -9 $pid
echo ""
echo "Service stop successfully!pid:${pid} which has been killed forcibly!"
echo ""
fi
}
# 输出运行状态方法
status() {
# 重新获取一下pid,因为其它操作如stop、restart、start等会导致pid的状态更新
pid=`ps -ef | grep $JAR_NAME | grep -v grep | awk '{print $2}'`
# -z 表示如果$pid为空时执行。注意:每个命令和变量之间一定要前后加空格,否则会提示command找不到
if [ -z $pid ];then
echo ""
echo "Service ${JAR_NAME} is not running!"
echo ""
else
echo ""
echo "Service ${JAR_NAME} is running. It's pid=${pid}"
echo ""
fi
}
# 重启方法
restart() {
echo ""
echo ".............................Restarting.............................."
echo "....................................................................."
# 重新获取一下pid,因为其它操作如start会导致pid的状态更新
pid=`ps -ef | grep $JAR_NAME | grep -v grep | awk '{print $2}'`
# -z 表示如果$pid为空时执行。注意:每个命令和变量之间一定要前后加空格,否则会提示command找不到
if [ ! -z $pid ]; then
kill -9 $pid
fi
start
echo "....................Restart successfully!..........................."
}
# 根据输入参数执行对应方法,不输入则执行tips提示方法
case "$1" in
"start")
start
;;
"stop")
stop
;;
"status")
status
;;
"restart")
restart
;;
*)
tips
;;
esac
启动Dinky
sh auto.sh start1使用FinalShell将服务器上50001端口映射到本地开发机器
1、选择连接属性

2、隧道、添加
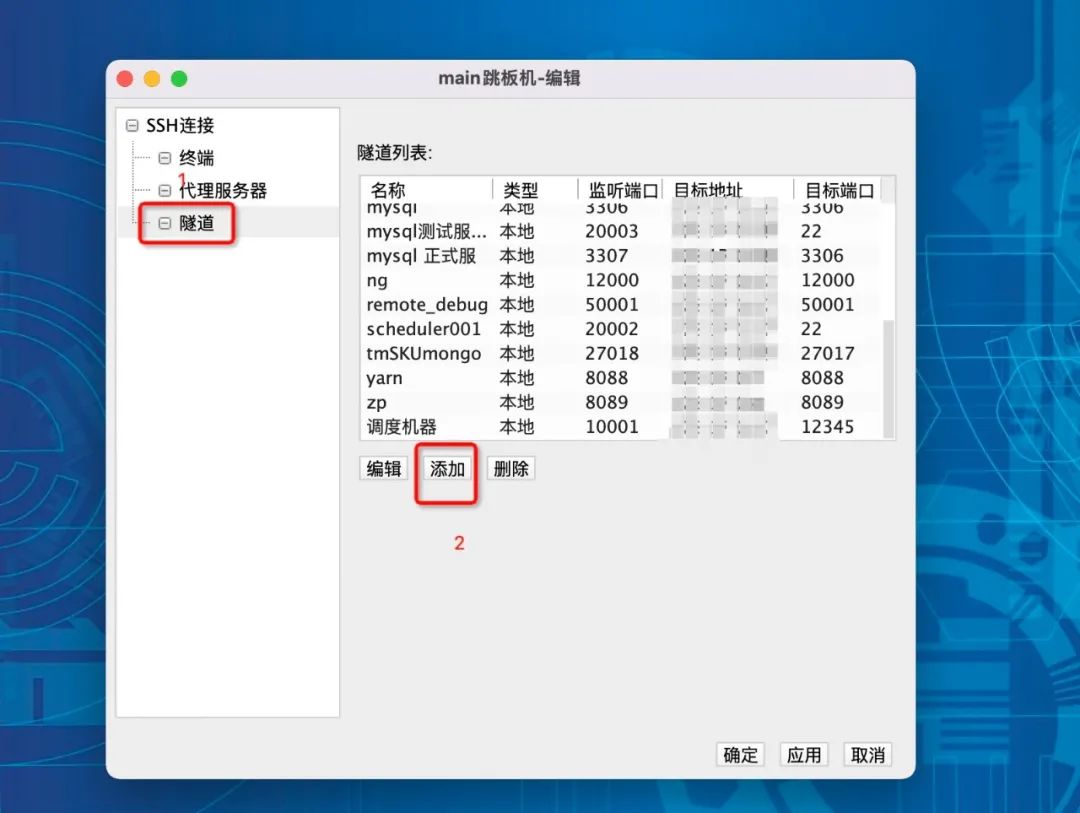
3、添加映射配置并点击确定

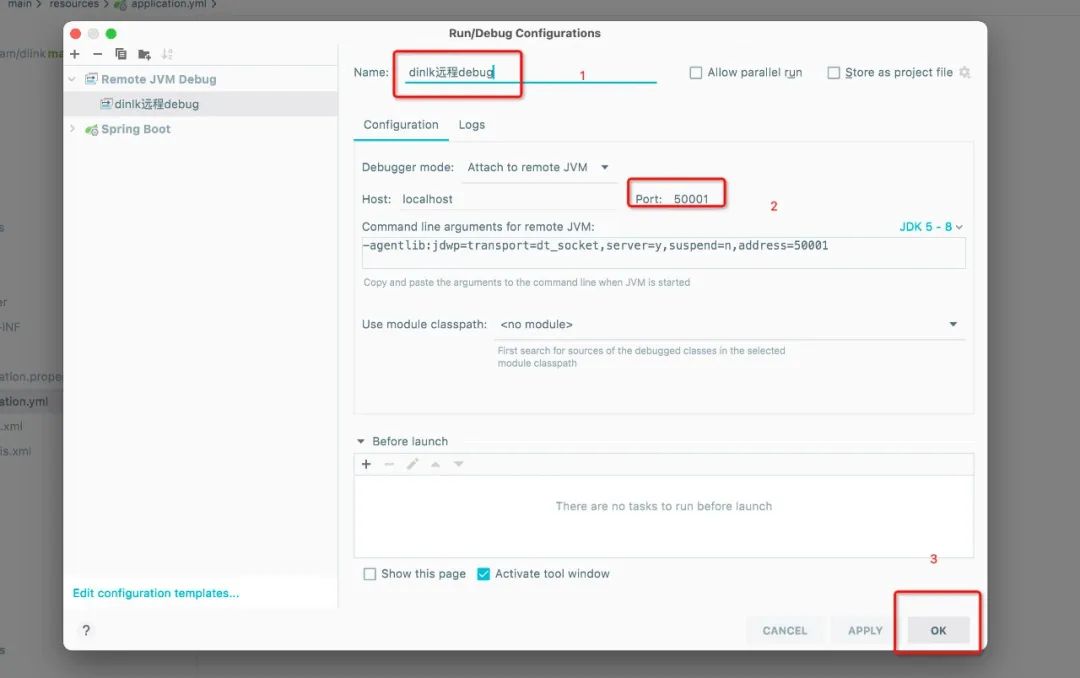
配置IDEA远程调试
1、进入idea 配置页面

2、找到远程调试选项

3、配置远程调试端口
Dinky上配置任务
flink on yarn Per-Job方式
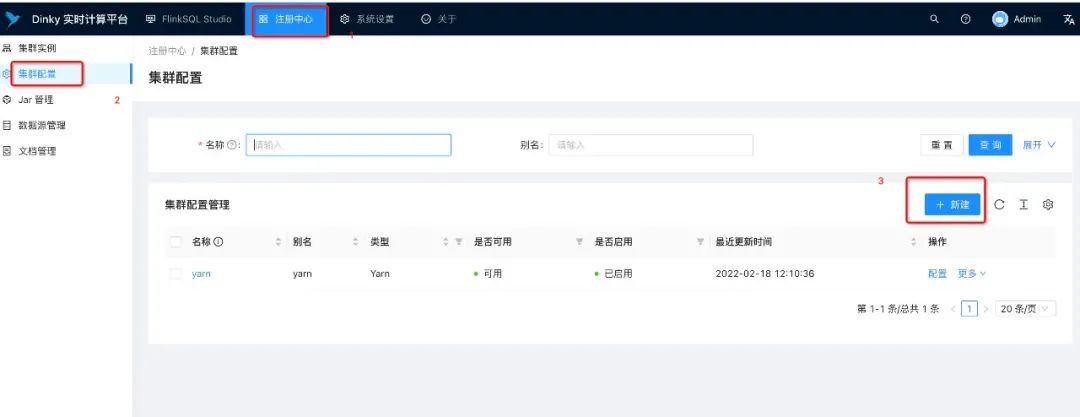
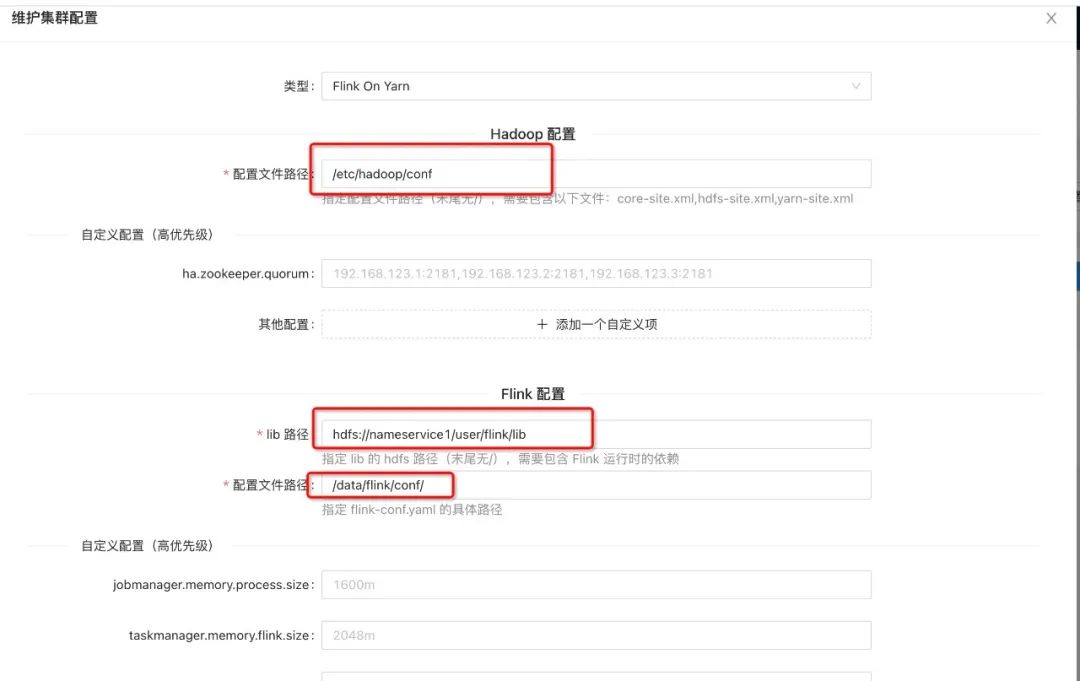
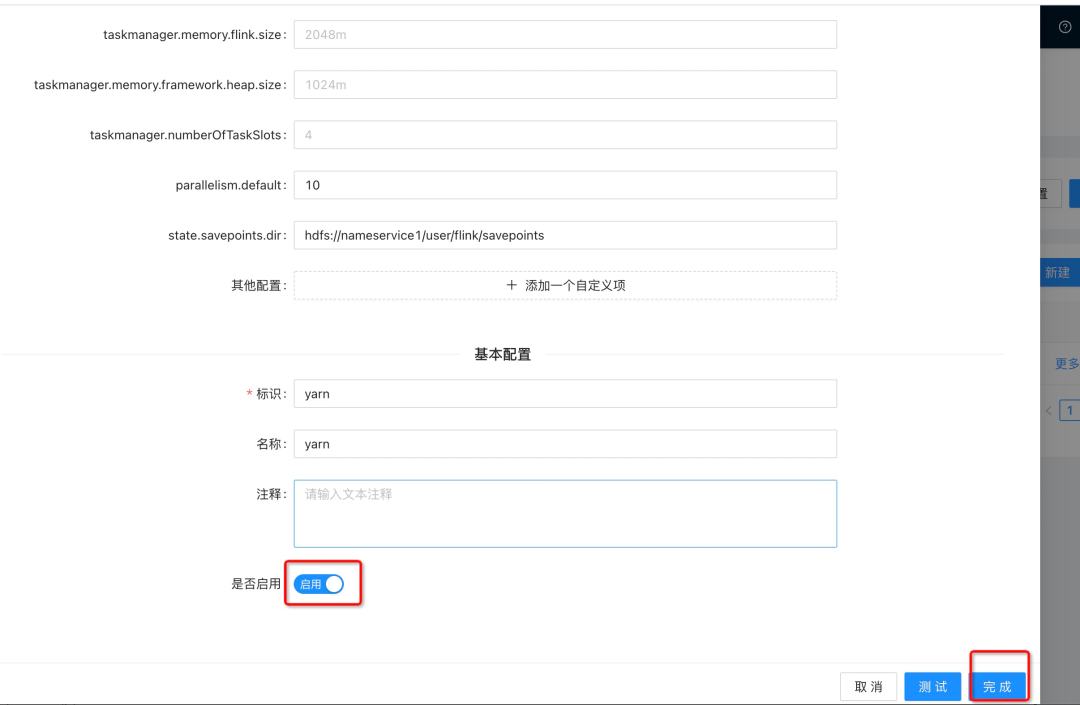
添加集群配置
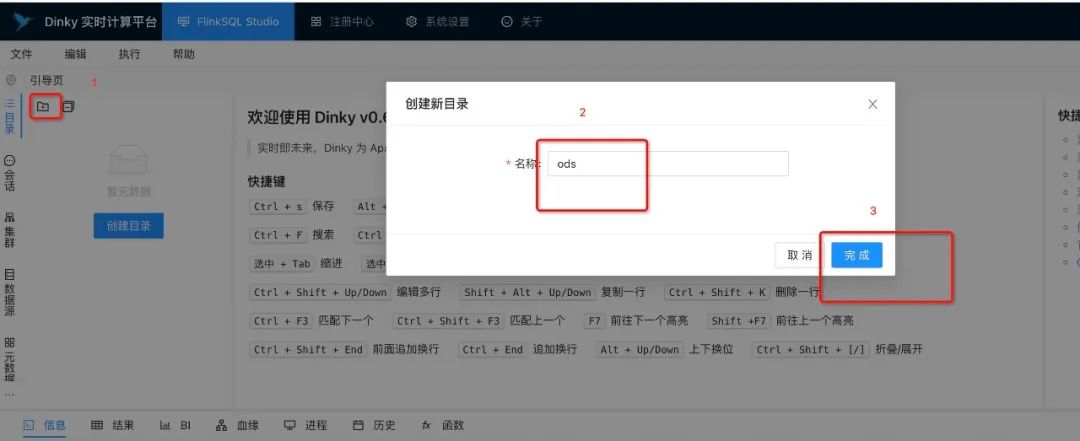
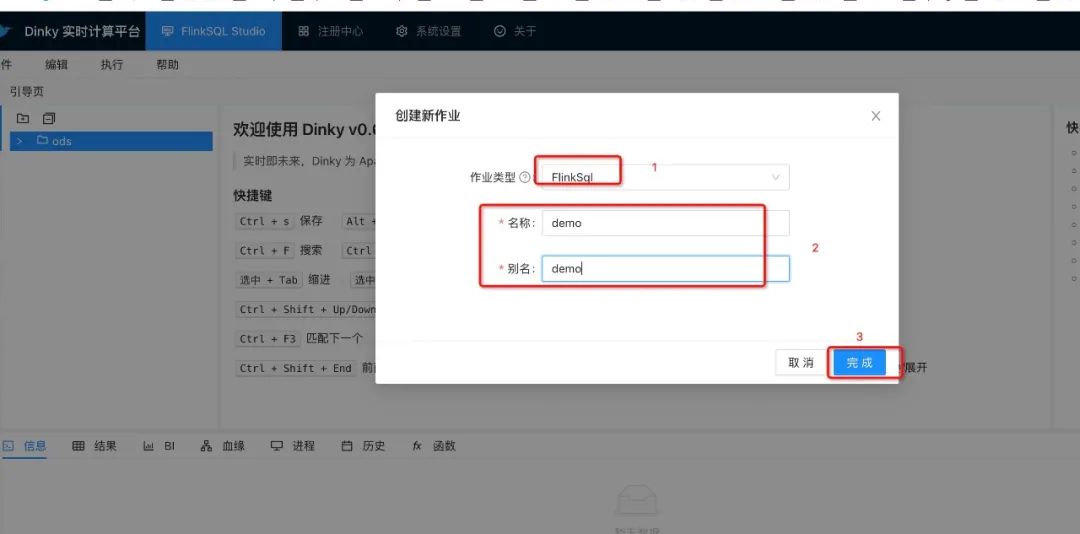
创建flinksql作业

CREATE TABLE datagen_source (
name VARCHAR,
score BIGINT
) WITH (
'connector' = 'datagen'
)
;
CREATE TABLE print_table (
name VARCHAR,
score BIGINT
) WITH (
'connector' = 'print'
);
CREATE TABLE print_table_a (
name VARCHAR,
score BIGINT
) WITH (
'connector' = 'print'
);
insert into print_table
select name,score from datagen_source;
insert into print_table_a
select name,score from datagen_source
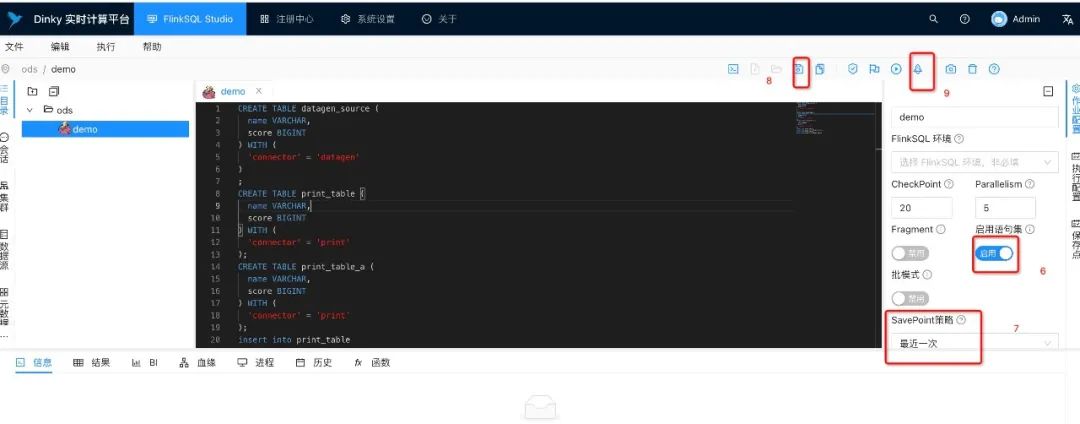
IDEA中远程调试
1、启动远程debug

2、页面提交flnksql 任务
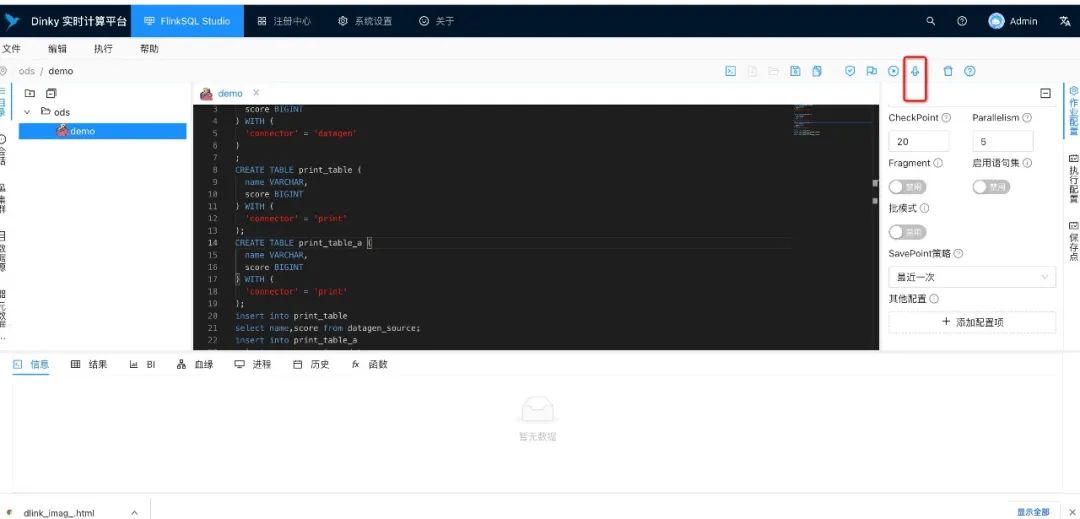
3、查看debug运行时明细

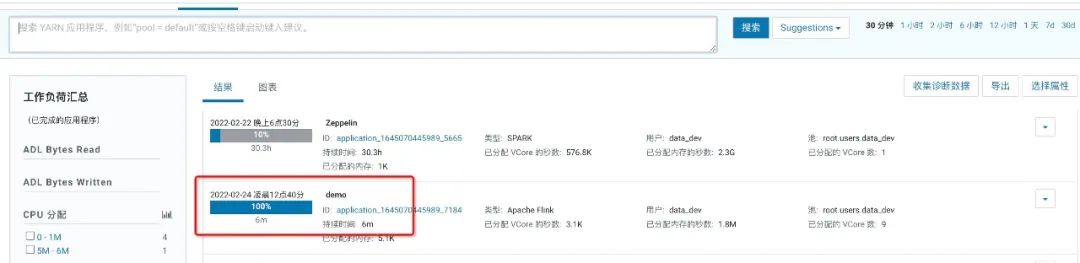
4、在cdh的yarn应用上查看是否提交成功
六、总结
七、参考


扫描二维码获取
更多精彩
DataLink
数据中台

