




Table of Contents
概述
探究性数据分析第一步将数据可视化,然后从图中理解数据的趋势,数据异常等问题,再对数据进行处理,例如数据清洗等操作。
一. 检查目标列的分布
目标是我们被要求预测的:要么贷款的0被及时偿还,要么1表明客户有付款困难。我们可以先检查一下属于每个类别的贷款数量。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
# 显示可用列表
# print(os.listdir("E:/home_credit_default_risk"))
# 训练dataframe
#app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
#print('Training data shape: ', app_train.shape)
#print(app_train.head())
# 测试dafaframe特征
#app_test = pd.read_csv('E:/home_credit_default_risk//application_test.csv')
#print('Testing data shape: ', app_test.shape)
#print(app_test.head())
# target列分布
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
print(app_train['TARGET'].value_counts())
app_train['TARGET'].astype(int).plot.hist()
plt.show()
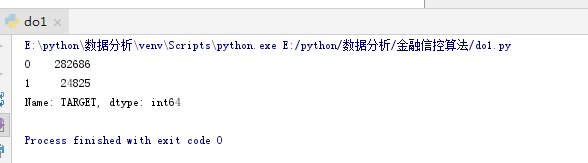
从结果图中,我们可以看出0比1的结果多很多,这样会导致我们的学习器出现错误,有可能在真实数据训练中出现过拟合的问题,然后把多数数据都看成了0不偿还,这样会降低准确度,损失用户,所以我们需要将数据进行均衡操作。
二. 检查缺失值
接下来,我们可以查看每列中缺失值的数量和百分比
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
# 计算丢失值的函数
def missing_values_table(df):
# 总缺失值
mis_val = df.isnull().sum()
# 计算缺失值的百分比
mis_val_percent = 100 * df.isnull().sum() / len(df)
# 显示结果的表格
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
# 重命名列
mis_val_table_ren_columns = mis_val_table.rename(
columns={0: 'Missing Values', 1: '% of Total Values'})
# 按下降百分比对表进行排序
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:, 1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
# 显示部分信息
print("Your selected dataframe has " + str(df.shape[1]) + " columns.\n"
"There are " + str(mis_val_table_ren_columns.shape[0]) +
" columns that have missing values.")
# 返回缺少的信息值
return mis_val_table_ren_columns
# 统计缺失值
missing_values = missing_values_table(app_train)
missing_values.head(20)
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
print(missing_values_table(app_train))
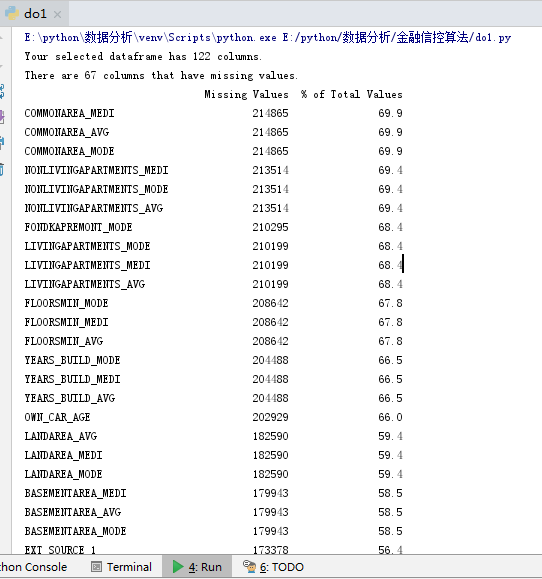
三. 列类型
让我们看看每个数据类型的列数。int64和float64是数值变量(可以是离散的,也可以是连续的)。对象列包含字符串,是类特征。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
print(app_train.dtypes.value_counts())
print(app_train.select_dtypes('object').apply(pd.Series.nunique, axis = 0))
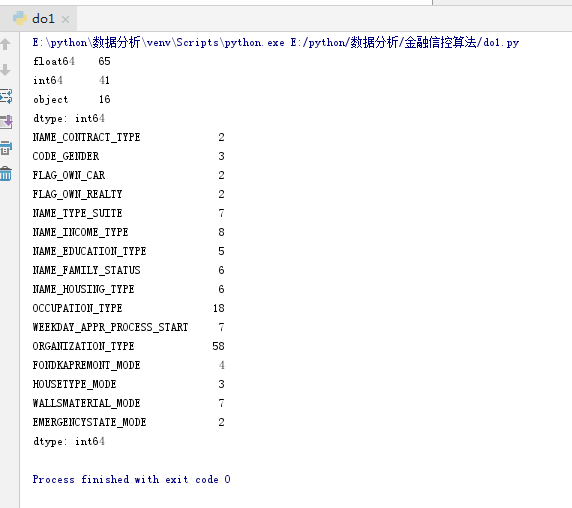
由结果可以看到,大部分分类变量都有相对缺少唯一的条目,现在我们需要找到一种方法去处理这些数据。
四. 编码分类变量
在我们进一步深入之前,我们需要处理麻烦的分类变量。但是机器学习模型不能处理分类变量(除了LightGBM等一些模型)。因此,在将这些变量传递给模型之前,我们必须找到一种方法将这些变量编码(表示)为数字。
这个过程主要有两种方式:
- 标签编码
- 独热编码
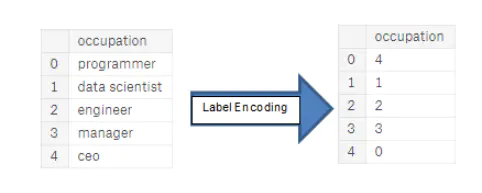
4.1 标签编码
在一个具有整数的类别变量中分配每个唯一的类别。没有创建新的列。下面是一个示例
4.2 独热编码
为类别变量中的每个惟一类别创建一个新列。每个观察值在相应的类别中在列中接受1,在所有其他新列中接受0,独热编码的唯一缺点是,特性(数据的维数)的数量可能会随着具有多个类别的分类变量而激增。为了解决这个问题,我们可以执行一次热编码,然后执行PCA或其他降维方法,以减少维数(同时仍然试图保留信息。
4.3 案例
让我们实现上面描述的策略:对于具有2个唯一类别的任何类别变量(dtype == object),我们将使用标签编码,对于具有2个以上唯一类别的任何类别变量,我们将使用one-hot编码。
4.3.1 标签编码案例
# 创建标签编码对象
le = LabelEncoder()
le_count = 0
# 迭代这些列
for col in app_train:
if app_train[col].dtype == 'object':
# 如果2个唯一类别的列或更少的类别的列使用标签编码:
if len(list(app_train[col].unique())) <= 2:
# 训练训练集
le.fit(app_train[col])
# 标签化训练集和测试集
app_train[col] = le.transform(app_train[col])
app_test[col] = le.transform(app_test[col])
# 计算标签编码作用了多少列
le_count += 1
print('%d columns were label encoded.' % le_count)

4.3.2 独热编码案例
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 对分类变量执行独热编码
app_train = pd.get_dummies(app_train)
app_test = pd.get_dummies(app_test)
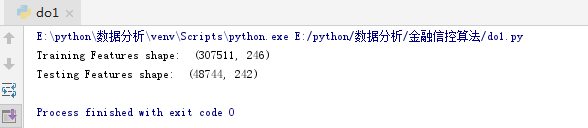
print('Training Features shape: ', app_train.shape)
print('Testing Features shape: ', app_test.shape)
六. 调整训练和测试数据
在训练和测试数据中需要有相同的特性(列)。One-hot编码在训练数据中创建了更多的列,因为有些类别变量在测试数据中没有表示。要删除不在测试数据中的训练数据中的列,我们需要对齐dataframes。首先,我们从训练数据中提取目标列(因为这不在测试数据中,但是我们需要保留这些信息)。当我们进行对齐时,我们必须确保将axis = 1设置为基于列而不是行对齐数据.
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
train_labels = app_train['TARGET']
# 对齐训练和测试数据,只保留两个数据格式中的列
app_train, app_test = app_train.align(app_test, join = 'inner', axis = 1)
# 将目标加入
app_train['TARGET'] = train_labels
print('Training Features shape: ', app_train.shape)
print('Testing Features shape: ', app_test.shape)

七. 探索性数据分析实例
7.1 异常
在做EDA时,我们总是希望注意的一个问题是数据中的异常。这些可能是由于输入错误的数字、测量设备的错误,或者它们可能是有效的但极端的测量。定量支持异常的一种方法是使用描述方法查看列的统计数据。DAYS_BIRTH列中的数字是负数,因为它们是相对于当前的贷款申请记录的。要查看这些数年的统计数据,我们可以将其倍数乘以-1,然后除以一年的天数
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
print((app_train['DAYS_BIRTH'] / -365).describe())
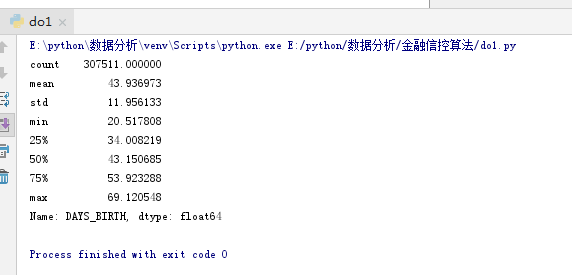
25%, 50%和75%是对应的四分位数。
四分位数(Quartile)是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。
第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由版小到大排列后第25%的数字。
第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。
第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
第三四分位数与第一四分位数的差距又称四分位距权(InterQuartile Range,IQR)。
这些年龄比值看起来没有问题了,大致均衡。那工作值呢?
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
print(app_train['DAYS_EMPLOYED'].describe())
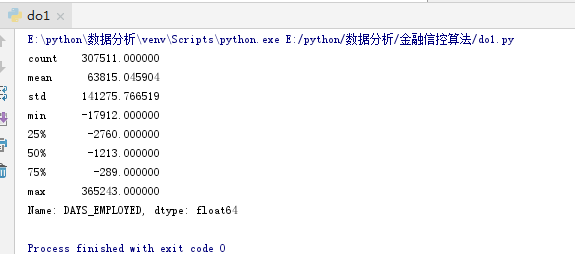
这个看起来就不对了!最大值大约是1000年!
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
app_train['DAYS_EMPLOYED'].plot.hist(title = 'Days Employment Histogram');
plt.xlabel('Days Employment');
plt.show()
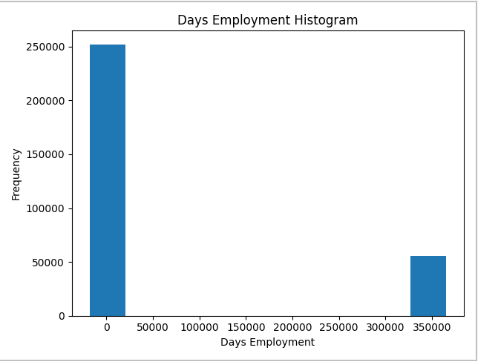
出于好奇,让我们对异常客户进行子集划分,看看他们的违约率是否比其他客户高或低
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
anom = app_train[app_train['DAYS_EMPLOYED'] == 365243]
non_anom = app_train[app_train['DAYS_EMPLOYED'] != 365243]
print('The non-anomalies default on %0.2f%% of loans' % (100 * non_anom['TARGET'].mean()))
print('The anomalies default on %0.2f%% of loans' % (100 * anom['TARGET'].mean()))
print('There are %d anomalous days of employment' % len(anom))
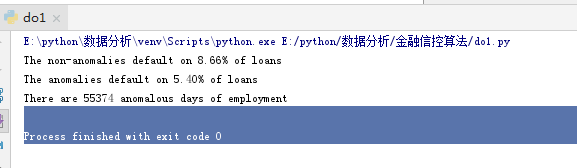
事实证明,异常现象的违约率较低。
处理异常取决于确切的情况,没有固定的规则。最安全的方法之一就是将异常值设置为缺失值,然后在机器学习之前将其填充(使用赋值)。在本例中,由于所有的异常值都完全相同,我们希望用相同的值来填充它们,以防所有这些贷款都有共同之处。异常值似乎有一定的重要性,所以我们想告诉机器学习模型如果我们真的填了这些值。作为解决方案,我们将使用非数字填充异常值(np.nan),然后创建一个新的布尔列,指示该值是否为异常。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 创建一个异常的标志列
app_train['DAYS_EMPLOYED_ANOM'] = app_train["DAYS_EMPLOYED"] == 365243
# 将异常值替换为nan
app_train['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace = True)
app_train['DAYS_EMPLOYED'].plot.hist(title = 'Days Employment Histogram');
plt.xlabel('Days Employment');
plt.show()
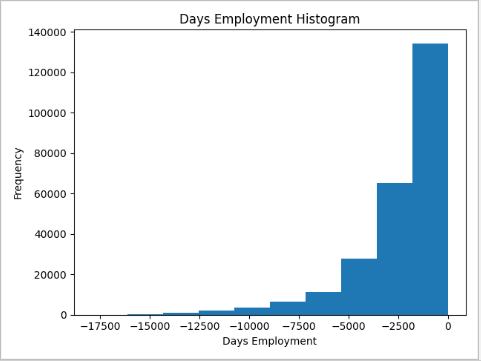
这个分布看起来更符合我们的期望,我们还创建了一个新的列来告诉模型这些值最初是反常的(因为我们将不得不用一些值来填充nans,可能是列的中值)。在dataframe中有天数的其他列看起来与我们所期望的没什么明显的异常值。
作为一个非常重要的提示,我们对训练数据所做的任何事情我们也必须对测试数据所做的。让我们确保创建新列并使用np填充现有列。在测试数据中。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 创建一个异常的标志列
app_train['DAYS_EMPLOYED_ANOM'] = app_train["DAYS_EMPLOYED"] == 365243
app_test['DAYS_EMPLOYED_ANOM'] = app_train["DAYS_EMPLOYED"] == 365243
# 将异常值替换为nan
app_train['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace = True)
app_test["DAYS_EMPLOYED"].replace({365243: np.nan}, inplace = True)
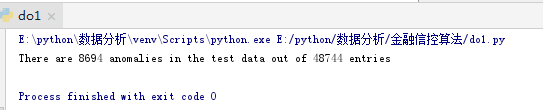
print('There are %d anomalies in the test data out of %d entries' % (app_test["DAYS_EMPLOYED_ANOM"].sum(), len(app_test)))
7.2 相关性
现在我们已经处理了分类变量和离群值,让我们继续处理EDA。一种尝试和理解数据的方法是在特征和目标之间寻找相关性。我们可以使用。校正 dafaframe法计算每个变量与目标之间的Pearson相关系数。
相关系数并不是表示特征“相关性”的最佳方法,但它确实让我们了解了数据中可能存在的关系。相关系数绝对值的一般解释有:
-0.19“很弱”
- 0.20-0.39“软弱”
- 0.40-0.59“温和”
- 0.60-0.79年“强大”
- 0.80-1.0“很强”
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 找到与目标的关联和排序
correlations = app_train.corr()['TARGET'].sort_values()
# 显示相关性
print('Most Positive Correlations:\n', correlations.tail(15))
print('\nMost Negative Correlations:\n', correlations.head(15))
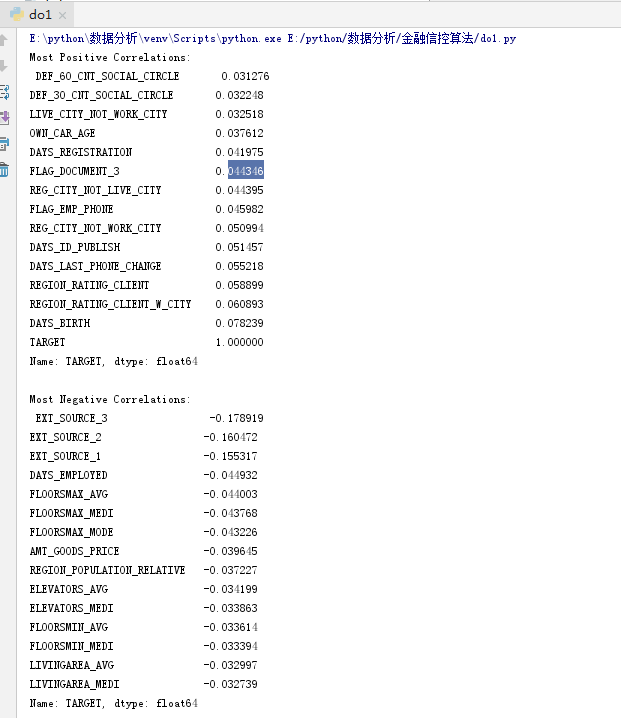
让我们来看看一些更重要的相关性:DAYS_BIRTH是最积极的相关性。(TARGET除外,因为变量与自身的相关性总是1!)。
负相关性不是表示没关系。在负相关的情况下,一个变量随着另一个变量的变化而发生相反方向的变化。统计学中常用相关系数r来表示两变量之间的相关关系。r的值介于-1与1之间,r为正时是正相关,反映当x增加(减少)时,y随之相应增加(减少);
呈正相关的两个变量之间的相关系数一定为正值,这个正值越大说明正相关的程度越高。当这个正值为1时就是完全正相关。r的绝对值越大,表示变量之间的相关程度越高,r为负数时,表示一个变量的增加可能引起另一个变量的减少,此时,叫做负相关。
7.3 年龄对还款的影响
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 找出出生后的积极天数与目标的相关性
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH'])
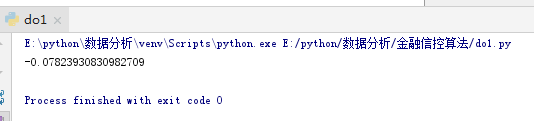
print(app_train['DAYS_BIRTH'].corr(app_train['TARGET']))
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 设置平面图的风格
plt.style.use('fivethirtyeight')
# 以年为单位绘制年龄分布
plt.hist(app_train['DAYS_BIRTH'] / 365, edgecolor = 'k', bins = 25)
plt.title('Age of Client'); plt.xlabel('Age (years)'); plt.ylabel('Count');
plt.show()
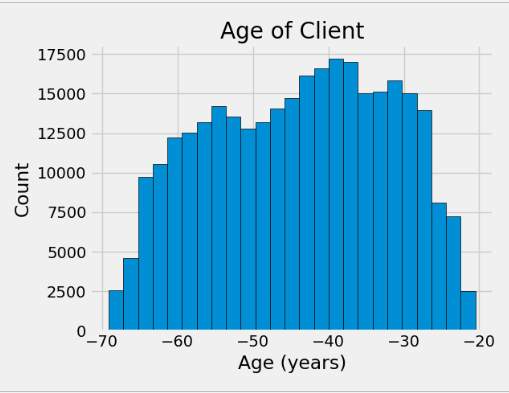
年龄分布本身并没有告诉我们太多,除了没有异常值,因为所有的年龄都是合理的。为了将年龄对目标的影响形象化,我们接下来将使用目标的值来绘制核密度估计图(KDE)。核密度估计图显示了单个变量的分布,可以认为它是平滑的直方图(它是通过计算每个数据点上的核(通常是高斯核),然后对所有单个核进行平均,得到一条平滑的曲线而创建的)。对于这个图,我们将使用seaborn kdeplot。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
plt.figure(figsize = (10, 8))
# KDE是按时偿还的贷款
sns.kdeplot(app_train.loc[app_train['TARGET'] == 0, 'DAYS_BIRTH'] / 365, label = 'target == 0')
# 未按时偿还的贷款
sns.kdeplot(app_train.loc[app_train['TARGET'] == 1, 'DAYS_BIRTH'] / 365, label = 'target == 1')
# 平面图的标签
plt.xlabel('Age (years)'); plt.ylabel('Density'); plt.title('Distribution of Ages');
plt.show()
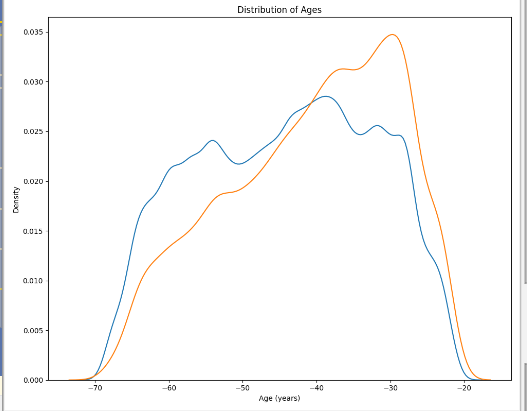
目标== 1曲线向较年轻的一端倾斜。
虽然这不是一个显著的相关(-0.07相关系数),但这个变量可能会在机器学习模型中有用,因为它确实会影响目标。
让我们以另一种方式来看待这种关系:未能按年龄组别偿还贷款的平均情况。
为了制作这个图表,我们首先把年龄分类切成每个5岁的箱子。
然后,对于每个箱子,我们计算目标的平均值,它告诉我们在每个年龄段没有偿还的贷款比例。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH'])
# 年龄信息分为一个单独的dafaframe
age_data = app_train[['TARGET', 'DAYS_BIRTH']]
age_data['YEARS_BIRTH'] = age_data['DAYS_BIRTH'] / 365
# 箱子年龄的dafaframe
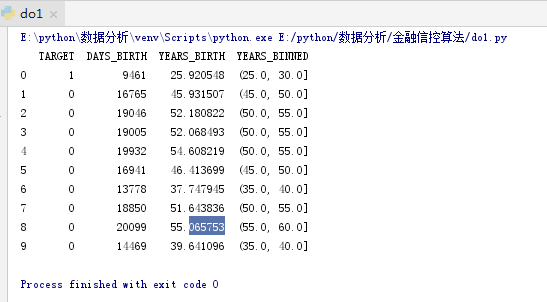
age_data['YEARS_BINNED'] = pd.cut(age_data['YEARS_BIRTH'], bins = np.linspace(20, 70, num = 11))
print(age_data.head(10))
将箱子分组并计算其平均值
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH'])
# 年龄信息分为一个单独的dafaframe
age_data = app_train[['TARGET', 'DAYS_BIRTH']]
age_data['YEARS_BIRTH'] = age_data['DAYS_BIRTH'] / 365
# 箱子年龄的dafaframe
age_data['YEARS_BINNED'] = pd.cut(age_data['YEARS_BIRTH'], bins = np.linspace(20, 70, num = 11))
# 将箱子分组并计算其平均值
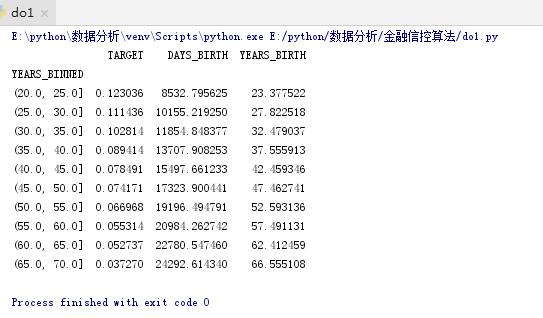
age_groups = age_data.groupby('YEARS_BINNED').mean()
print(age_groups)
将年龄箱和目标的平均值绘制成条形图
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH'])
# 年龄信息分为一个单独的dafaframe
age_data = app_train[['TARGET', 'DAYS_BIRTH']]
age_data['YEARS_BIRTH'] = age_data['DAYS_BIRTH'] / 365
# 箱子年龄的dafaframe
age_data['YEARS_BINNED'] = pd.cut(age_data['YEARS_BIRTH'], bins = np.linspace(20, 70, num = 11))
# 将箱子分组并计算其平均值
age_groups = age_data.groupby('YEARS_BINNED').mean()
plt.figure(figsize = (8, 8))
# 将年龄箱和目标的平均值绘制成条形图
plt.bar(age_groups.index.astype(str), 100 * age_groups['TARGET'])
# 平面图的标签
plt.xticks(rotation = 75); plt.xlabel('Age Group (years)'); plt.ylabel('Failure to Repay (%)')
plt.title('Failure to Repay by Age Group');
plt.show()
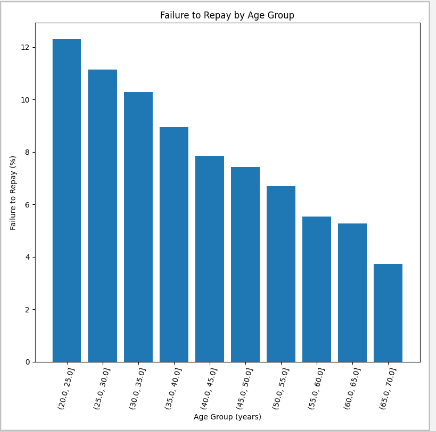
有一个明显的趋势:年轻的申请者更有可能无法偿还贷款!最年轻的三个年龄段的还款失败率超过10%,最年长的三个年龄段的还款失败率超过5%。
这是银行可以直接使用的信息:因为年轻的客户不太可能偿还贷款,也许他们应该得到更多的指导或理财建议。这并不意味着银行应该歧视年轻客户,但明智的做法是采取预防措施,帮助年轻客户按时付款。
7.4 外部来源
与目标具有最强负相关性的三个变量分别是EXT_SOURCE_1、EXT_SOURCE_2和EXT_SOURCE_3,外部数据源标准化分数。
我理解的是其它金融机构的一个信用评级。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
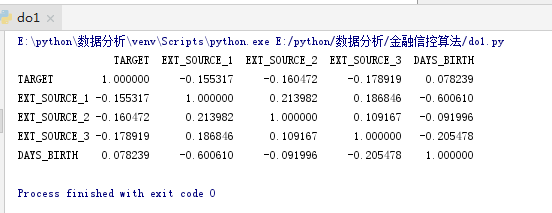
# 提取EXT_SOURCE变量并显示相关性
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
ext_data_corrs = ext_data.corr()
print(ext_data_corrs)
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 提取EXT_SOURCE变量并显示相关性
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
ext_data_corrs = ext_data.corr()
plt.figure(figsize = (8, 6))
# 相关性的热图
sns.heatmap(ext_data_corrs, cmap = plt.cm.RdYlBu_r, vmin = -0.25, annot = True, vmax = 0.6)
plt.title('Correlation Heatmap');
plt.show()
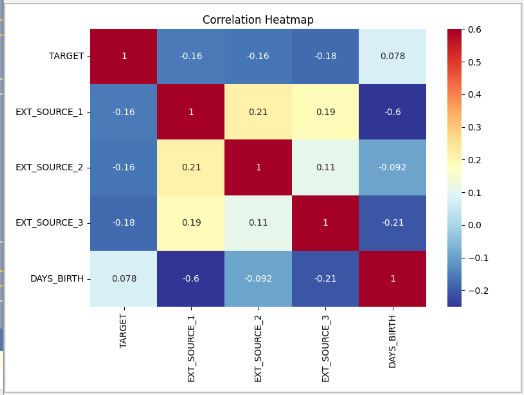
所有这三个EXT_SOURCE特性都与目标函数有负相关,表明随着EXT_SOURCE的值的增加,客户更有可能偿还贷款。
我们还可以看到DAYS_BIRTH与EXT_SOURCE_1呈正相关,表明这个评分中的一个因素可能是客户年龄。
接下来,我们可以看看由目标值着色的每个特征的分布。
这将使我们可视化这个变量对目标的影响。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 提取EXT_SOURCE变量并显示相关性
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
ext_data_corrs = ext_data.corr()
plt.figure(figsize=(10, 12))
# 遍历source
for i, source in enumerate(['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']):
# 为每个source创建新的子图
plt.subplot(3, 1, i + 1)
# 偿还贷款的平面图
sns.kdeplot(app_train.loc[app_train['TARGET'] == 0, source], label='target == 0')
# 未偿还的贷款的平面图
sns.kdeplot(app_train.loc[app_train['TARGET'] == 1, source], label='target == 1')
# 平面图的标签
plt.title('Distribution of %s by Target Value' % source)
plt.xlabel('%s' % source);
plt.ylabel('Density');
plt.tight_layout(h_pad=2.5)
plt.show()
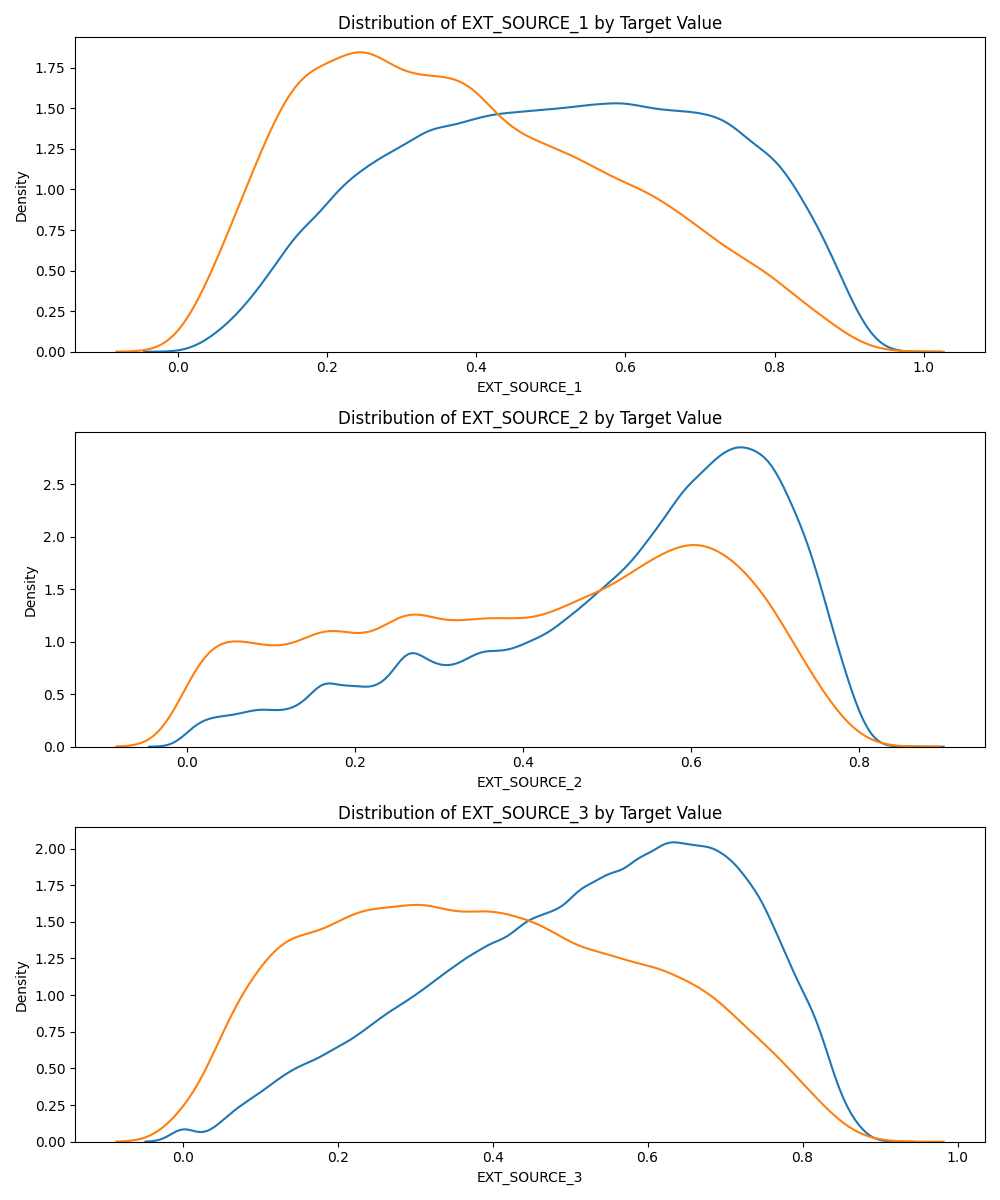
EXT_SOURCE_3显示了目标值之间最大的差异。我们可以清楚地看到,这个特性与申请人偿还贷款的可能性有一定的关系。这种关系并不很强(事实上,它们都被认为很弱,但这些变量对于机器学习模型仍然有用,可以用来预测申请人是否会按时偿还贷款。
7.5 最后平面图
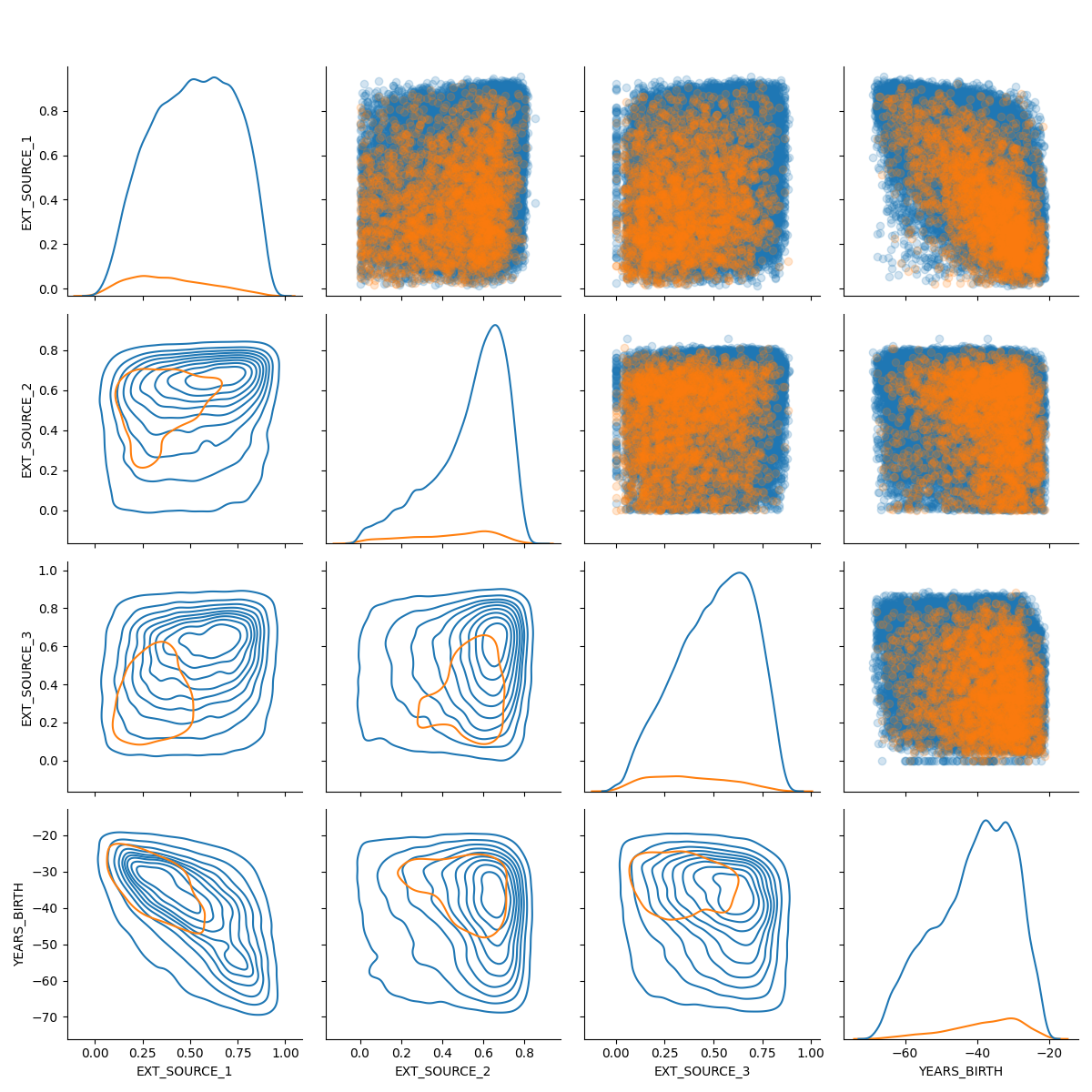
作为最后的探索性绘图,我们可以对EXT_SOURCE变量和DAYS_BIRTH变量进行配对。
对图是一个很好的探索工具,因为它让我们看到多对变量之间的关系以及单个变量的分布。
这里我们使用seaborn可视化库和配对网格函数创建一对图,上面三角形上有散点图,对角线上有直方图,下面三角形上有2D核密度图和相关系数。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 提取EXT_SOURCE变量并显示相关性
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
ext_data_corrs = ext_data.corr()
# 年龄信息分为一个单独的dafaframe
age_data = app_train[['TARGET', 'DAYS_BIRTH']]
age_data['YEARS_BIRTH'] = age_data['DAYS_BIRTH'] / 365
# 箱子年龄的dafaframe
age_data['YEARS_BINNED'] = pd.cut(age_data['YEARS_BIRTH'], bins = np.linspace(20, 70, num = 11))
# 复制数据用于绘图
plot_data = ext_data.drop(columns = ['DAYS_BIRTH']).copy()
# 加上客户的年龄
plot_data['YEARS_BIRTH'] = age_data['YEARS_BIRTH']
# 删除na值并限制为前100000行
plot_data = plot_data.dropna().loc[:100000, :]
# 函数计算两列之间的相关系数
def corr_func(x, y, **kwargs):
r = np.corrcoef(x, y)[0][1]
ax = plt.gca()
ax.annotate("r = {:.2f}".format(r),
xy=(.2, .8), xycoords=ax.transAxes,
size = 20)
# 创建pairgrid对象
grid = sns.PairGrid(data = plot_data, size = 3, diag_sharey=False,
hue = 'TARGET',
vars = [x for x in list(plot_data.columns) if x != 'TARGET'])
# 顶层是一个散点图
grid.map_upper(plt.scatter, alpha = 0.2)
# 对角线是一个直方图
grid.map_diag(sns.kdeplot)
# 底是密度图
grid.map_lower(sns.kdeplot, cmap = plt.cm.OrRd_r);
plt.suptitle('Ext Source and Age Features Pairs Plot', size = 32, y = 1.05);
plt.show()
参考:
- https://www.kaggle.com/c/home-credit-default-risk/data?select=application_test.csv
- https://aistudio.baidu.com/aistudio/datasetdetail/105246
- https://www.jianshu.com/p/c494a3a92af5
- https://wangjh.blog.csdn.net/article/details/81121122
