




TiDB中的SQL计算层TiDB Server会解析客户端的SQL请求并进行逻辑和物理上的优化,生成执行计划。本文简要介绍TiDB中的几种执行计划,了解不同算子在Explain中的输出信息。
1、TiDB SQL层架构
TiDB的SQL层即TiDB Server,负责将SQL翻译成Key-Value操作,将其转发给分布式Key-Value存储层TiKV,然后组装TiKV返回的结果,最终将查询结果返回给客户端。这一层的TiDB Server节点都是无状态的,节点本身并不存储数据,节点之间完全对等。
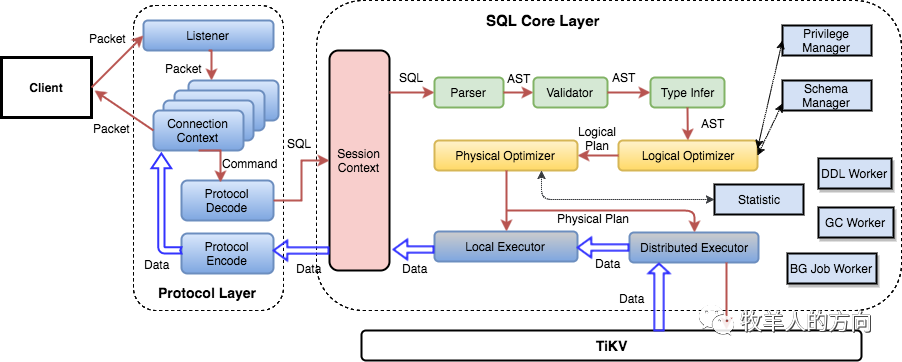
上图列出了TiDB SQL层重要的模块以及调用关系。用户的SQL请求会直接或者通过Load Balancer发送到TiDB Server,TiDB Server会解析MySQL Protocol Packet,获取请求内容,对SQL进行语法解析和语义分析,制定和优化查询计划,执行查询计划并获取和处理数据。数据全部存储在TiKV集群中,所以在这个过程中TiDB Server需要和TiKV交互,获取数据。最后TiDB Server需要将查询结果返回给用户。
1.1 表数据与key-value映射关系
TiDB中数据到(key,value)键值对的映射方案包括表数据和索引数据。
1)表数据和key-value映射关系
为了保证同一个表的数据放在一起, TiDB会为每个表分配一个表ID,用TableID表示。TableID是一个整数,在整个集群内唯一。
TiDB会为表中每行数据分配一个行ID,用RowID表示。RowID也是一个整数,在表内唯一。在TiDB中,对于RowID,如果某个表有整数型的主键,TiDB会使用主键的值当做这一行数据的行ID。
每行数据按照以上规则编码成(Key, Value)键值对:
Key: tablePrefix<<TableID>>_recordPrefixSep<<RowID>> => Value: [col1, col2, col3, col4]
其中tablePrefix和recordPrefixSep是特定的字符串常量,用于在Key空间内区分其他数据
2)索引数据和key-value的映射关系
TiDB中支持主键索引和二级索引,在索引数据和key-value的映射关系中,TiDB会为表中的每个索引分配一个索引ID,用IndexID表示。
对于主键和唯一索引,按照以下规则编码
Key: tablePrefix<<tableID>>_indexPrefixSep<<indexID>>_indexedColumnsValue => Value: RowID
对于不需要满足唯一性约束的普通二级索引,一个键值可能对应多行,按照如下规则编码成(Key, Value)键值对:
Key: tablePrefix<<TableID>>_indexPrefixSep<<IndexID>>_indexedColumnsValue_<<RowID>> => Value: null
3)Key-value对应关系例子
假设TiDB中有以下表,表结构如下:
CREATE TABLE User { ID int, Name varchar(20), Age int, PRIMARY KEY (ID), KEY idxAge (Age)};
表中有如下数据:
1, "TiDB", 102, "TiKV", 203, "PD",30
假设该表的TableID为101,则其存储在TiKV上的表数据为:
t101_r1 => ["TiDB",10]t101_r2 => ["TiKV",20]t101_r3 => ["PD",30]
该表还有一个非唯一的普通二级索引idxAge,假设这个索引的 IndexID 为1,则其存储在TiKV上的索引数据为:
t101_i1_10_1 => nullt101_i1_20_2 => nullt101_i1_30_3 => null
1.2 一条SQL的生命周期
TiDB Server客户端发送的SQL请求在Parser中解析为TiDB能够理解的语法树AST
TiDB中的SQL优化器首先会进行逻辑优化生成Logical Plan
再根据物理优化生成Physical,决定选择哪些索引和算子进行计算,过程中会使用到统计信息statistics的数据
生成的物理计划会在Executor中进行执行
如果是DML语句,TiDB会将用户更新的内容先缓存在Transaction模块中,等到用户执行事务的Commit时再进行两阶段提交,将结果写入到TiKV
对于复杂查询请求,TiDB 会通过DistSQL模块并行地向TiKV的多个region发送查询请求,然后再按照执行计划中的流程计算出查询结果来
TiDB采用两阶段提交的事务模型。为此需要向PD请求一个全局逻辑时间戳TSO,用来表明事务的开始时间与提交时间。为了不给PD造成过多的请求压力,TiDB通过单个线程一次为多个事务分配时间

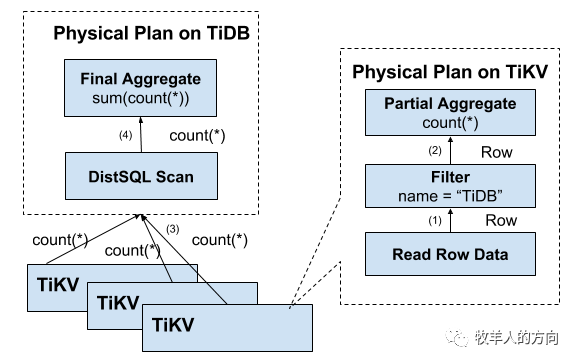
1.3 分布式SQL运算
首先,SQL中的谓词条件name = "TiDB" 被下推到每个存储节点进行计算,这样只需要返回有效的行,避免无意义的网络传输
然后,聚合函数Count()也可以被下推到存储节点,进行预聚合,每个节点只需要返回一个Count()的结果即可
再由SQL层将各个节点返回的Count(*)的结果累加求和。
以下是数据逐层返回的示意图:
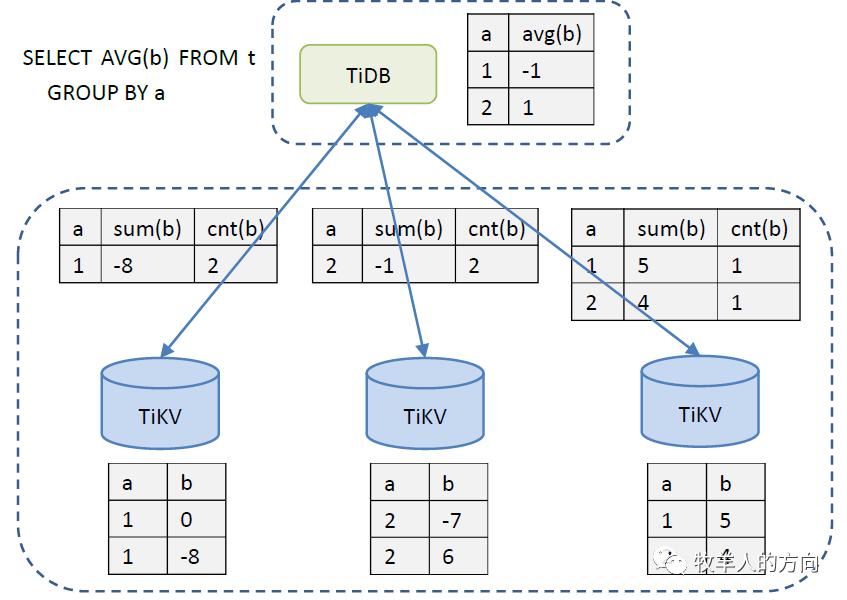
以下是分布式执行引擎的例子:
2、TiDB执行计划
TiDB优化器会根据当前数据表的最新的统计信息来选择最优的执行计划,执行计划由一系列的算子构成,在TiDB中可通过EXPLAIN语句返回的结果查看某条SQL的执行计划。
2.1 EXPLAIN输出
TiDB的EXPLAIN会输出5列,分别是:id,estRows,task,access object, operator info。
mysql> explain select * from tab01;+-----------------------+----------+-----------+---------------+--------------------------------+| id | estRows | task | access object | operator info |+-----------------------+----------+-----------+---------------+--------------------------------+| TableReader_5 | 10000.00 | root | | data:TableFullScan_4 || └─TableFullScan_4 | 10000.00 | cop[tikv] | table:tab01 | keep order:false, stats:pseudo |+-----------------------+----------+-----------+---------------+--------------------------------+
执行计划中每个算子都由这5列属性来描述,EXPLAIN结果中每一行描述一个算子。每个属性的具体含义如下:

通过观察EXPLAIN的结果,你可以知道如何给数据表添加索引使得执行计划使用索引从而加速SQL语句的执行速度;你也可以使用EXPLAIN来检查优化器是否选择了最优的顺序来JOIN数据表。
2.2 EXPLAIN ANALYZE输出
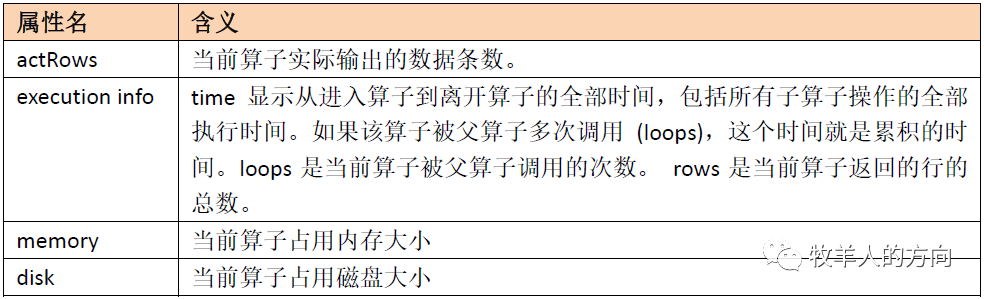
EXPLAIN ANALYZE会执行对应的SQL语句,记录其运行时信息,和执行计划一并返回出来,可以视为EXPLAIN语句的扩展。EXPLAIN ANALYZE语句的返回结果中增加了actRows, execution info,memory,disk这几列信息:
以下为例,优化器估算的estRows和实际执行中统计得到的actRows几乎是相等的,说明优化器估算的行数与实际行数的误差很小。同时TableReader_5算子在实际执行过程中使用了约282 Bytes 的内存,该 SQL 在执行过程中,没有触发过任何算子的落盘操作。
mysql> explain analyze select * from tab02;+-----------------------+---------+---------+-----------+---------------+-----------------------------------------------------------------------+----------------------+-----------+------+| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |+-----------------------+---------+---------+-----------+---------------+-----------------------------------------------------------------------+----------------------+-----------+------+| TableReader_5 | 4.00 | 4 | root | | time:1.626388ms, loops:2, rpc num: 1, rpc time:1.37835ms, proc keys:4 | data:TableFullScan_4 | 282 Bytes | N/A || └─TableFullScan_4 | 4.00 | 4 | cop[tikv] | table:tab02 | time:0s, loops:1 | keep order:false | N/A | N/A |+-----------------------+---------+---------+-----------+---------------+-----------------------------------------------------------------------+----------------------+-----------+------+
2.3 算子的执行顺序
如果一个算子有多个孩子节点,孩子节点ID后面有Build关键字的算子总是先于有Probe关键字的算子执行
TiDB在展现执行计划的时候,Build端总是第一个出现,接着才是Probe端
以下为例:
mysql> create table tt04 (id int(11),age int(4),primary key(`id`),key idx1(`id`));mysql> explain select * from tt04 use index(idx1) where age=1;+------------------------------+----------+-----------+----------------------------+--------------------------------+| id | estRows | task | access object | operator info |+------------------------------+----------+-----------+----------------------------+--------------------------------+| IndexLookUp_8 | 10.00 | root | | || ├─IndexFullScan_5(Build) | 10000.00 | cop[tikv] | table:tt04, index:idx1(id) | keep order:false, stats:pseudo || └─Selection_7(Probe) | 10.00 | cop[tikv] | | eq(tango.tt04.age, 1) || └─TableRowIDScan_6 | 10000.00 | cop[tikv] | table:tt04 | keep order:false, stats:pseudo |+------------------------------+----------+-----------+----------------------------+--------------------------------+
这里IndexLookUp_8算子有两个孩子节点:IndexFullScan_5(Build)和 Selection_7(Probe)。可以看到,IndexFullScan_5(Build)是第一个出现的,并且基于上面这条规则,要得到一条数据,需要先得到一个RowID以后,再由Selection_7(Probe)根据前者读上来的RowID去获取完整的一行数据。
2.4 扫表的执行计划
真正执行扫表操作的算子有如下几类:
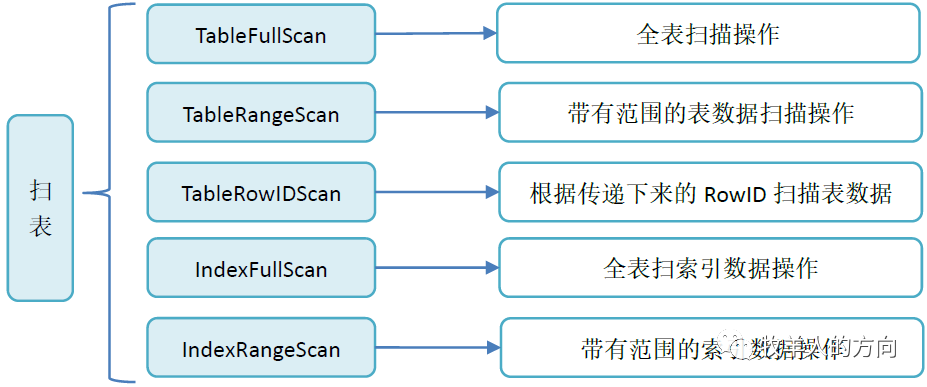
TableReader:将TiKV上底层扫表算子TableFullScan或TableRangeScan得到的数据进行汇总。
IndexReader:将TiKV上底层扫表算子IndexFullScan或IndexRangeScan得到的数据进行汇总。
IndexLookUp:先汇总Build端TiKV扫描上来的RowID,再去Probe端上根据这些RowID精确地读取TiKV上的数据。Build端是IndexFullScan或IndexRangeScan类型的算子,Probe端是TableRowIDScan类型的算子。
IndexMerge:和IndexLookupReader类似,可以看做是它的扩展,可以同时读取多个索引的数据,有多个Build端,一个Probe端。执行过程也很类似,先汇总所有Build端TiKV扫描上来的RowID,再去Probe端上根据这些RowID精确地读取TiKV上的数据。Build端是IndexFullScan或IndexRangeScan类型的算子,Probe端是TableRowIDScan类型的算子。
1)IndexLookUp示例
mysql> create table tt01 (id int(11),age int(4),primary key(`id`),key idx1(`id`));mysql> explain select * from tt01 use index(idx1);+-------------------------------+----------+-----------+----------------------------+--------------------------------+| id | estRows | task | access object | operator info |+-------------------------------+----------+-----------+----------------------------+--------------------------------+| IndexLookUp_6 | 10000.00 | root | | || ├─IndexFullScan_4(Build) | 10000.00 | cop[tikv] | table:tt01, index:idx1(id) | keep order:false, stats:pseudo || └─TableRowIDScan_5(Probe) | 10000.00 | cop[tikv] | table:tt01 | keep order:false, stats:pseudo |+-------------------------------+----------+-----------+----------------------------+--------------------------------+3 rows in set (0.07 sec)
IndexFullScan_4(Build) 执行索引全表扫,扫描索引idx1的所有数据,因为是全范围扫,这个操作将获得表中所有数据的RowID
由TableRowIDScan_5(Probe)根据这些RowID去扫描所有的表数据
可以预见的是,这个执行计划不如直接使用TableReader进行全表扫,因为同样都是全表扫,这里的IndexLookUp多扫了一次索引,带来了额外的开销。
2)TableReader示例
mysql> create table tt02 (a int(11),b int(11),primary key(`a`),key idx1(`a`));mysql> explain select * from tt02 where a>1 or b>100;+-------------------------+----------+-----------+---------------+------------------------------------------------+| id | estRows | task | access object | operator info |+-------------------------+----------+-----------+---------------+------------------------------------------------+| TableReader_7 | 8000.00 | root | | data:Selection_6 || └─Selection_6 | 8000.00 | cop[tikv] | | or(gt(tango.tt02.a, 1), gt(tango.tt02.b, 100)) || └─TableFullScan_5 | 10000.00 | cop[tikv] | table:tt02 | keep order:false, stats:pseudo |+-------------------------+----------+-----------+---------------+------------------------------------------------+3 rows in set (0.11 sec)
在上面例子中TableReader_7算子的孩子节点是Selection_6,以这个孩子节点为根的子树被当做了一个Cop Task下发给了相应的TiKV,这个Cop Task使用TableFullScan_5算子执行扫表操作。由TableFullScan_5可以看到,这个执行计划使用了全表扫描的操作,集群的负载将因此而上升,可能会影响到集群中正在运行的其他查询。这时候如果能够建立合适的索引,并且使用IndexMerge算子,将能够极大的提升查询的性能,降低集群的负载。
3)IndexMerge示例 IndexMerge是TiDB v4.0中引入的一种对表的新访问方式。在这种访问方式下,TiDB优化器可以选择对一张表使用多个索引,并将每个索引的返回结果进行合并。在某些场景下,这种访问方式能够减少大量不必要的数据扫描,提升查询的执行效率。
mysql> create table tt03 (a int(11),b int(11),primary key(`a`),key idx_a(`a`),key idx_b(`b`));Query OK, 0 rows affected (1.55 sec)mysql> explain select * from tt03 where a=1 or b=1;+-------------------------+----------+-----------+---------------+----------------------------------------------+| id | estRows | task | access object | operator info |+-------------------------+----------+-----------+---------------+----------------------------------------------+| TableReader_7 | 8000.00 | root | | data:Selection_6 || └─Selection_6 | 8000.00 | cop[tikv] | | or(eq(tango.tt03.a, 1), eq(tango.tt03.b, 1)) || └─TableFullScan_5 | 10000.00 | cop[tikv] | table:tt03 | keep order:false, stats:pseudo |+-------------------------+----------+-----------+---------------+----------------------------------------------+3 rows in set (0.00 sec)mysql> set @@tidb_enable_index_merge = 1;Query OK, 0 rows affected (0.15 sec)mysql> explain select * from tt03 use index(idx_a,idx_b) where a=1 or b=1;+--------------------------------+---------+-----------+----------------------------+---------------------------------------------+| id | estRows | task | access object | operator info |+--------------------------------+---------+-----------+----------------------------+---------------------------------------------+| IndexMerge_11 | 20.00 | root | | || ├─IndexRangeScan_8(Build) | 10.00 | cop[tikv] | table:tt03, index:idx_a(a) | range:[1,1], keep order:false, stats:pseudo || ├─IndexRangeScan_9(Build) | 10.00 | cop[tikv] | table:tt03, index:idx_b(b) | range:[1,1], keep order:false, stats:pseudo || └─TableRowIDScan_10(Probe) | 20.00 | cop[tikv] | table:tt03 | keep order:false, stats:pseudo |+--------------------------------+---------+-----------+----------------------------+---------------------------------------------+4 rows in set (0.04 sec)
在上述示例中,过滤条件是使用OR条件连接的WHERE子句。在启用 IndexMerge 前,每个表只能使用一个索引,不能将a = 1下推到索引idx_a,也不能将b = 1下推到索引idx_b。当 tt03中存在大量数据时,全表扫描的效率会很低。针对这类场景,TiDB引入了对表的新访问方式IndexMerge。
在IndexMerge访问方式下,优化器可以选择对一张表使用多个索引,并将每个索引的返回结果进行合并,生成一个 IndexMerge的执行计划。此时的IndexMerge_11算子有三个子节点,其中IndexRangeScan_8和 IndexRangeScan_9根据范围扫描得到符合条件的所有RowID,再由TableRowIDScan_10算子根据这些RowID精确地读取所有满足条件的数据。
2.5 聚合的执行计划
Hash Aggregate
Stream Aggregate
1)Hash Aggregate示例
TiDB上的Hash Aggregation算子采用多线程并发优化,执行速度快,但会消耗较多内存。下面是一个Hash Aggregate的例子:
mysql> create table t3 (x int) partition by hash(x) partitions 2;mysql> explain select *+ HASH_AGG() */ count(*) from t3;+------------------------------+----------+-----------+------------------------+--------------------------------+| id | estRows | task | access object | operator info |+------------------------------+----------+-----------+------------------------+--------------------------------+| HashAgg_10 | 1.00 | root | | funcs:count(1)->Column#3 || └─Union_13 | 20000.00 | root | | || ├─TableReader_15 | 10000.00 | root | | data:TableFullScan_14 || │ └─TableFullScan_14 | 10000.00 | cop[tikv] | table:t3, partition:p0 | keep order:false, stats:pseudo || └─TableReader_17 | 10000.00 | root | | data:TableFullScan_16 || └─TableFullScan_16 | 10000.00 | cop[tikv] | table:t3, partition:p1 | keep order:false, stats:pseudo |+------------------------------+----------+-----------+------------------------+--------------------------------+6 rows in set (0.01 sec)
一个在TiKV/TiFlash的Coprocessor上,在扫表算子读取数据时计算聚合函数的中间结果,如示例中的TableFullScan_14和TableFullScan_16
另一个在TiDB层,汇总所有Coprocessor Task的中间结果后,得到最终结果,如示例中HashAgg_10
其中explain表中的operator info列还记录了Hash Aggregation的其他信息,比如Aggregation所使用的聚合函数是什么。在上面的例子中,Hash Aggregation算子的operator info中的内容为funcs:count(1)->Column#3,我们可以得到Hash Aggregation使用了聚合函数count进行计算。
2)Stream Aggregate示例
TiDB中的Stream Aggregation算子通常会比Hash Aggregate占用更少的内存,有些场景中也会比Hash Aggregate执行得更快。当数据量太大或者系统内存不足时,可以试试Stream Aggregate算子,如下例所示:
mysql> explain select *+ STREAM_AGG() */ count(*) from tt01;+----------------------------+----------+-----------+---------------+---------------------------------+| id | estRows | task | access object | operator info |+----------------------------+----------+-----------+---------------+---------------------------------+| StreamAgg_20 | 1.00 | root | | funcs:count(Column#5)->Column#3 || └─TableReader_21 | 1.00 | root | | data:StreamAgg_8 || └─StreamAgg_8 | 1.00 | cop[tikv] | | funcs:count(1)->Column#5 || └─TableFullScan_18 | 10000.00 | cop[tikv] | table:tt01 | keep order:false, stats:pseudo |+----------------------------+----------+-----------+---------------+---------------------------------+4 rows in set (0.01 sec)
和Hash Aggregate类似,一般而言TiDB的Stream Aggregate也会分成两个阶段执行,一个在TiKV/TiFlash的Coprocessor上,在扫表算子读取数据时计算聚合函数的中间结果,比如上例中的TableFullScan_18。另一个在TiDB层,汇总所有Coprocessor Task的中间结果后,得到最终结果,如上例中的StreamAgg_20。
2.6 Join的执行计划
Hash Join
Merge Join
Index Join (Index Nested Loop Join)
Index Hash Join (Index Nested Loop Hash Join)
Index Merge Join (Index Nested Loop Merge Join)
1)Hash Join示例
TiDB的Hash Join算子采用了多线程优化,执行速度较快,但会消耗较多内存。如下所示:
mysql> create table tt04 (id int(11),a int(4));mysql> create table tt05 (id int(11),a int(4));mysql> EXPLAIN SELECT *+ HASH_JOIN(tt04, tt05) */ * FROM tt04, tt05 WHERE tt04.a = tt05.a;+------------------------------+----------+-----------+---------------+----------------------------------------------------+| id | estRows | task | access object | operator info |+------------------------------+----------+-----------+---------------+----------------------------------------------------+| HashJoin_8 | 12487.50 | root | | inner join, equal:[eq(tango.tt04.a, tango.tt05.a)] || ├─TableReader_15(Build) | 9990.00 | root | | data:Selection_14 || │ └─Selection_14 | 9990.00 | cop[tikv] | | not(isnull(tango.tt05.a)) || │ └─TableFullScan_13 | 10000.00 | cop[tikv] | table:tt05 | keep order:false, stats:pseudo || └─TableReader_12(Probe) | 9990.00 | root | | data:Selection_11 || └─Selection_11 | 9990.00 | cop[tikv] | | not(isnull(tango.tt04.a)) || └─TableFullScan_10 | 10000.00 | cop[tikv] | table:tt04 | keep order:false, stats:pseudo |+------------------------------+----------+-----------+---------------+----------------------------------------------------+7 rows in set (0.00 sec)
Hash Join会将Build端的数据缓存在内存中,根据这些数据构造出一个Hash Table,然后读取Probe端的数据,用Probe端的数据去探测Build端构造出来的Hash Table,将符合条件的数据返回给用户。其中explain表中的operator info列还记录了Hash Join的其他信息,包括Join的类型、Join的条件是什么。如上例中,该查询是一个Inner Join,其中Join的条件 equal:[eq(tango.tt04.a, tango.tt05.a)],和查询语句中 where tt04.a = tt05.a部分对应。
2)Merge Join示例
TiDB的Merge Join算子相比于Hash Join通常会占用更少的内存,但可能执行时间会更久。当数据量太大,或系统内存不足时,建议尝试使用。如下例所示:
mysql> create table tt04 (id int(11),a int(11),primary key(`id`),key idx1(`a`));mysql> create table tt05 (id int(11),a int(11),primary key(`id`),key idx1(`a`));Query OK, 0 rows affected (1.03 sec)mysql> EXPLAIN SELECT /*+ MERGE_JOIN(tt05, tt04) */ * FROM tt05, tt04 WHERE tt05.a = tt04.a;+-----------------------------+----------+-----------+---------------------------+-----------------------------------------------------------+| id | estRows | task | access object | operator info |+-----------------------------+----------+-----------+---------------------------+-----------------------------------------------------------+| MergeJoin_8 | 12487.50 | root | | inner join, left key:tango.tt05.a, right key:tango.tt04.a || ├─IndexReader_36(Build) | 9990.00 | root | | index:IndexFullScan_35 || │ └─IndexFullScan_35 | 9990.00 | cop[tikv] | table:tt04, index:idx1(a) | keep order:true, stats:pseudo || └─IndexReader_34(Probe) | 9990.00 | root | | index:IndexFullScan_33 || └─IndexFullScan_33 | 9990.00 | cop[tikv] | table:tt05, index:idx1(a) | keep order:true, stats:pseudo |+-----------------------------+----------+-----------+---------------------------+-----------------------------------------------------------+5 rows in set (0.00 sec)
Merge Join算子在执行时,会从Build端把一个Join Group的数据全部读取到内存中(示例中的IndexFullScan_35),接着再去读Probe端的数据(IndexFullScan_33),用Probe端的每行数据去和Build端的一个完整Join Group比较,依次查看是否匹配(示例中的MergeJoin_8)。Join Group指的是所有Join Key上值相同的数据。
3)Index Merge Join示例
该算法的使用条件包含Index Join的所有使用条件,但还需要添加一条:join keys 中的内表列集合是内表使用的 index 的前缀,或内表使用的index是join keys中的内表列集合的前缀,该算法相比于INL_JOIN会更节省内存。
mysql> create table tt02 (a int(11),b int(11),primary key(`a`),key idx1(`a`));mysql> create table tt03 (a int(11),b int(11),primary key(`a`),key idx1(`a`));mysql> insert into tt03 values(1,1)mysql> EXPLAIN SELECT *+ INL_MERGE_JOIN(tt02, tt03) */ * FROM tt02, tt03 WHERE tt02.a = tt03.a;+-------------------------------+---------+-----------+---------------+----------------------------------------------------------------------------------+| id | estRows | task | access object | operator info |+-------------------------------+---------+-----------+---------------+----------------------------------------------------------------------------------+| Projection_7 | 2.50 | root | | tango.tt02.a, tango.tt02.b, tango.tt03.a, tango.tt03.b || └─IndexMergeJoin_16 | 2.50 | root | | inner join, inner:TableReader_14, outer key:tango.tt03.a, inner key:tango.tt02.a || ├─TableReader_41(Build) | 2.00 | root | | data:TableFullScan_40 || │ └─TableFullScan_40 | 2.00 | cop[tikv] | table:tt03 | keep order:false || └─TableReader_14(Probe) | 1.00 | root | | data:TableRangeScan_13 || └─TableRangeScan_13 | 1.00 | cop[tikv] | table:tt02 | range: decided by [tango.tt03.a], keep order:true, stats:pseudo |+-------------------------------+---------+-----------+---------------+----------------------------------------------------------------------------------+6 rows in set (0.01 sec)
2.7 优化实例
1)下载数据bikeshare example database
[root@tango-01 src]# mkdir -p bikeshare-data && cd bikeshare-data[root@tango-01 src]# curl -L --remote-name-all https://s3.amazonaws.com/capitalbikeshare-data/{2017..2017}-capitalbikeshare-tripdata.zip[root@tango-01 src]# unzip \*-tripdata.zip[root@tango-01 bikeshare-data]# lltotal 595752-rw-r--r-- 1 root root 89576218 Mar 14 09:44 2017-capitalbikeshare-tripdata.zip-rw-r--r-- 1 root root 89276248 Mar 15 2018 2017Q1-capitalbikeshare-tripdata.csv-rw-r--r-- 1 root root 153392619 Mar 15 2018 2017Q2-capitalbikeshare-tripdata.csv-rw-r--r-- 1 root root 165260132 Mar 15 2018 2017Q3-capitalbikeshare-tripdata.csv-rw-r--r-- 1 root root 112536025 Mar 15 2018 2017Q4-capitalbikeshare-tripdata.csv
2)将数据load到表中
mysql> CREATE DATABASE bikeshare;Query OK, 0 rows affected (0.88 sec)mysql> USE bikeshare;Database changedmysql> CREATE TABLE trips ( -> trip_id bigint NOT NULL PRIMARY KEY AUTO_INCREMENT, -> duration integer not null, -> start_date datetime, -> end_date datetime, -> start_station_number integer, -> start_station varchar(255), -> end_station_number integer, -> end_station varchar(255), -> bike_number varchar(255), -> member_type varchar(255)-> );mysql> LOAD DATA LOCAL INFILE '/usr/local/src/bikeshare-data/2017Q1-capitalbikeshare-tripdata.csv' INTO TABLE trips FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\r\n' IGNORE 1 LINES (duration, start_date, end_date, start_station_number, start_station, end_station_number, end_station, bike_number, member_type);
3)explain语句
mysql> EXPLAIN SELECT count(*) FROM trips WHERE start_date BETWEEN '2017-01-01 00:00:00' AND '2017-02-01 23:59:59';+------------------------------+---------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------+| id | estRows | task | access object | operator info |+------------------------------+---------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------+| StreamAgg_20 | 1.00 | root | | funcs:count(Column#13)->Column#11 || └─TableReader_21 | 1.00 | root | | data:StreamAgg_9 || └─StreamAgg_9 | 1.00 | cop[tikv] | | funcs:count(1)->Column#13 || └─Selection_19 | 6.33 | cop[tikv] | | ge(bikeshare.trips.start_date, 2017-01-01 00:00:00.000000), le(bikeshare.trips.start_date, 2017-02-01 23:59:59.000000) || └─TableFullScan_18 | 253.00 | cop[tikv] | table:trips | keep order:false, stats:pseudo |+------------------------------+---------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------+5 rows in set (0.46 sec)
在上面的例子中,coprocessor上读取trips表上的数据(TableFullScan_18),寻找满足start_date BETWEEN '2017-01-01 00:00:00' AND '2017-02-01 23:59:59' 条件的数据(Selection_19),然后计算满足条件的数据行数(StreamAgg_9),最后把结果返回给TiDB。TiDB汇总各个coprocessor 返回的结果 (TableReader_21),并进一步计算所有数据的行数(StreamAgg_20),最终把结果返回给客户端。在上面这个查询中,TiDB根据trips表的统计信息估算出 TableScan_18 的输出结果行数为253.00,满足条件start_date BETWEEN '2017-01-01 00:00:00' AND '2017-02-01 23:59:59' 的有6.33条,经过聚合运算后,只有1条结果。
4)添加索引后再运行SQL语句
ALTER TABLE trips ADD INDEX (start_date);mysql> EXPLAIN SELECT count(*) FROM trips WHERE start_date BETWEEN '2017-01-01 00:00:00' AND '2017-02-01 23:59:59';+-----------------------------+---------+-----------+-------------------------------------------+---------------------------------------------------------------------------------+| id | estRows | task | access object | operator info |+-----------------------------+---------+-----------+-------------------------------------------+---------------------------------------------------------------------------------+| StreamAgg_17 | 1.00 | root | | funcs:count(Column#13)->Column#11 || └─IndexReader_18 | 1.00 | root | | index:StreamAgg_9 || └─StreamAgg_9 | 1.00 | cop[tikv] | | funcs:count(1)->Column#13 || └─IndexRangeScan_16 | 6.33 | cop[tikv] | table:trips, index:start_date(start_date) | range:[2017-01-01 00:00:00,2017-02-01 23:59:59], keep order:false, stats:pseudo |
+-----------------------------+---------+-----------+-------------------------------------------+---------------------------------------------------------------------------------+
4 rows in set (0.58 sec)
在添加完索引后的新执行计划中,使用IndexRangeScan_16直接读取满足条件start_date BETWEEN '2017-01-01 00:00:00' AND '2017-02-01 23:59:59' 的数据,可以看到,估算的要扫描的数据行数从之前的253降到了现在的6.33。
参考资料:
https://pingcap.com/blog-cn/tidb-source-code-reading-6/
https://docs.pingcap.com/zh/tidb/stable/sql-tuning-overview
https://book.tidb.io/session3/chapter4/performance-map.html
https://book.tidb.io/session1/chapter3/tidb-sql-layer-summary.html
https://book.tidb.io/session3/chapter1/sql-execution-plan.html
https://github.com/pingcap/docs/blob/master/import-example-data.md
