




instance.xml配置,主要指canal.instance.global.spring.xml参数,即“全局的spring配置方式的组件文件”。
常用的主要以下几种:
1、canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
2、canal.instance.global.spring.xml = classpath:spring/file-instance.xml
3、canal.instance.global.spring.xml = classpath:spring/default-instance.xml
4、canal.instance.global.spring.xml = classpath:spring/group-instance.xml
在介绍instance配置之前,先了解一下canal如何维护一份增量订阅&消费的关系信息:
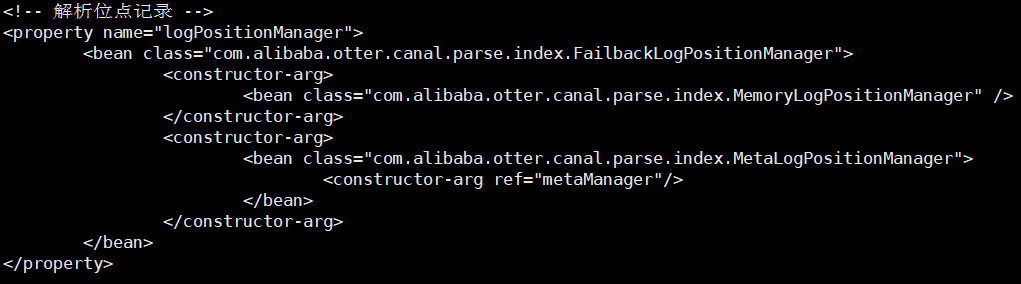
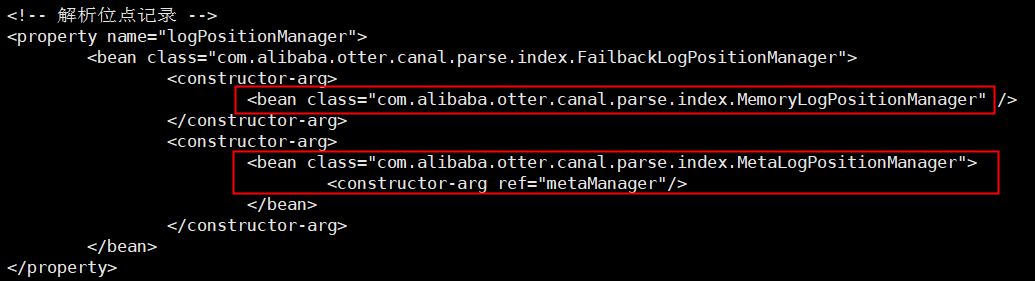
解析位点 (parse模块会记录,上一次解析binlog到了什么位置,对应组件为:CanalLogPositionManager)
消费位点 (canal server在接收了客户端的ack后,就会记录客户端提交的最后位点,对应的组件为:CanalMetaManager)
对应的两个位点组件,目前都有几种实现:
memory (memory-instance.xml中使用)
zookeeper
mixed
period (default-instance.xml中使用,集合了zookeeper+memory模式,先写内存,定时刷新数据到zookeeper上)
下面是解释:
1、memory-instance.xml介绍
所有的组件(parser , sink , store)都选择了内存版模式,记录位点的都选择了memory模式,重启后又会回到初始位点进行解析
特点:速度最快,依赖最少(不需要zookeeper)
场景:一般应用在quickstart,或者是出现问题后,进行数据分析的场景,不应该将其应用于生产环境
cat memory-instance.xml


2、file-instance.xml介绍
基于file的持久化模式。
特点:支持单机持久化
场景:生产环境,无HA需求,简单可用.
采用该模式的时候,如果关闭了canal,会在destination中生成一个meta.dat,用来记录关键信息。如果想要启动canal之后马上订阅最新的位点,需要把该文件删掉。
cat meta.dat
{“clientDatas”:[{“clientIdentity”:{“clientId”:1001,“destination”:“xxxxx”,“filter”:""},“cursor”:{“identity”:{“slaveId”:-1,“sourceAddress”:{“address”:“xxxxxxxxx”,“port”:3307}},“postion”:{“gtid”:"",“included”:false,“journalName”:“mysql_bin.000105”,“position”:409163747,“serverId”:10001,“timestamp”:1615534442000}}}],“destination”:“xxxxx”}
cat file-instance.xml

3、default-instance.xml介绍
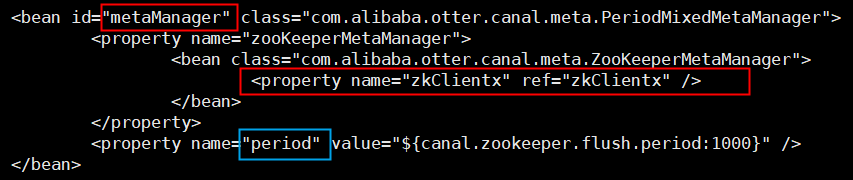
store选择了内存模式,其余的parser/sink依赖的位点管理选择了持久化模式,目前持久化的方式主要是写入zookeeper,保证数据集群共享.
特点:支持HA
场景:生产环境,集群化部署.
cat default-instance.xml
解析/parse配置
4、group-instance.xml介绍
主要针对需要进行多库合并时,可以将多个物理instance合并为一个逻辑instance,提供客户端访问。
场景:分库业务。 比如产品数据拆分了4个库,每个库会有一个instance,如果不用group,业务上要消费数据时,需要启动4个客户端,分别链接4个instance实例。使用group后,可以在canal server上合并为一个逻辑instance,只需要启动1个客户端,链接这个逻辑instance即可.


