




今天,我们将推出新功能,使您更容易将数据从Amazon简单存储服务(Amazon S3)导入新的DynamoDB表。这是一个完全受管理的功能,不需要编写代码或管理基础设施。在这篇文章中,我们将介绍来自S3的DynamoDB导入,并向您展示如何使用它执行批量导入。
概述
在从S3导入DynamoDB之前,将数据批量导入DynamoDB的选项有限。为传统模式设计的提取、转换、加载(ETL)工具和迁移工具可用,但对于各种NoSQL模式(包括单表设计和文档存储)可能并不简单。批量导入数据可能需要自定义数据加载器,这需要资源来构建和操作。加载TB数据可能需要几天或几周的时间,除非解决方案是多线程的,并部署在一组虚拟实例上,如Amazon EMR集群。容量决策、作业监控和异常处理增加了您只能运行一次的解决方案的复杂性。如果需要执行DBA任务,例如跨帐户表迁移,可以使用DynamoDB表导出到Amazon S3功能,但还需要构建自定义表加载例程,将数据导入回新的DynamoDB表。
从S3导入DynamoDB可以帮助您将来自AmazonS3的TB级数据批量导入到新的DynamoDB表中,而无需代码或服务器。与表导出到S3功能相结合,您现在可以更轻松地将DynamoDB表从一个应用程序、帐户或AWS区域移动、转换和复制到另一个区域。以CSV、DynamoDB JSON或ION格式存储的遗留应用程序数据可以导入到DynamoDB,从而加快云应用程序迁移。可以从AWS管理控制台、AWS命令行界面(AWS CLI)或使用AWS SDK启动导入。
从S3导入DynamoDB不会消耗任何写容量,因此在定义新表时不需要提供额外的容量。如果使用配置的容量模式,则只能指定所需的最终表设置,包括容量模式和容量单位。
在导入过程中,DynamoDB在解析数据时可能会遇到错误。对于每个错误,DynamoDB在Amazon CloudWatch日志中创建一个日志条目,并记录遇到的错误总数。如果该计数超过10000的阈值,则日志记录将停止,但导入将继续。因此,建议您首先使用一个小数据集测试导入,以确保它可以无错误地运行。S3 bucket中的数据必须是CSV、DynamoDB JSON或ION格式,并使用GZIP或ZSTD压缩,或者不压缩。每个记录还必须包括一个分区键值和一个排序键(如果表配置了一个),以匹配目标表的键模式。您还必须为键选择适当的数据类型,字符串、数字或二进制。
将数据从S3导入DynamoDB
现在您已经了解了从S3导入DynamoDB的基本知识,让我们使用它将数据从Amazon S3移动到新的DynamoDB表。您可以下载一组示例JSON文件并将其部署到您的S3 bucket中以开始。在本演练中,假设您将这些未压缩的DynamoDB JSON数据文件暂存在文件夹path/demo中名为S3 import demo的S3存储桶中,如下图1所示。
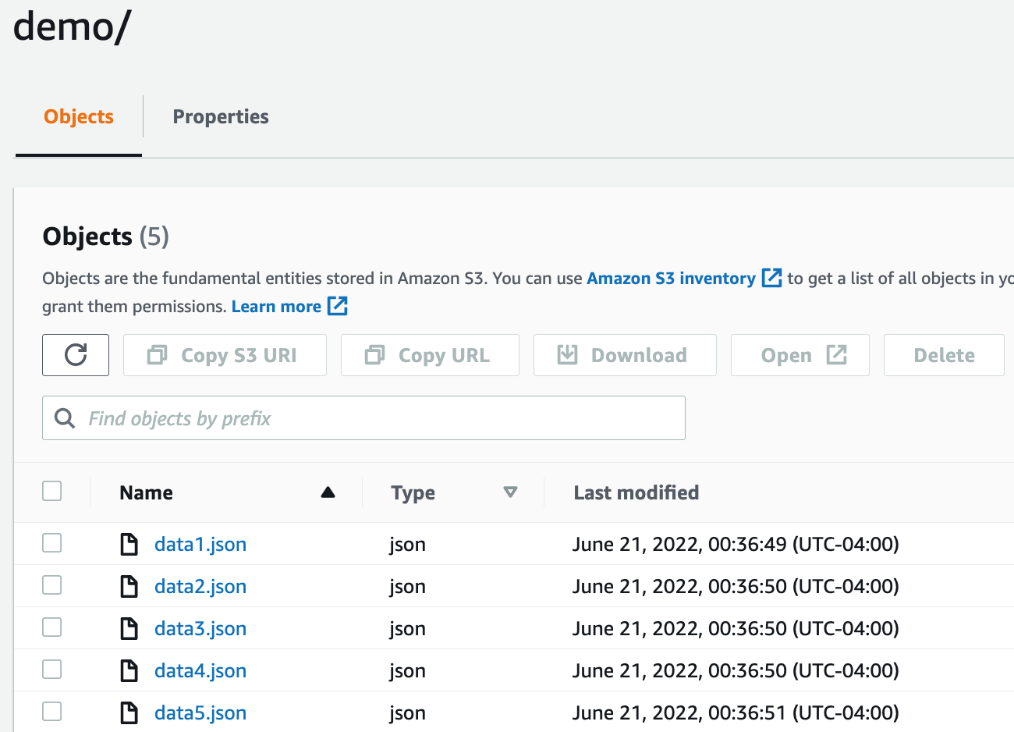
每个数据记录都包含一个PK和SK属性,用于一个表,该表具有一个名为PK的分区键和一个称为SK的排序键。您需要在导入过程中输入匹配的键名,以定义新表的键模式。下面的代码片段显示了DynamodbJSON格式的一些示例记录。
$ cat data2.json
{"Item":
{
"PK":{"S":"prd1002"},
"SK":{"S":"ver1"},
"record_type":{"S":"product"},"product_id":{"N":"1002"},"version":{"N":"1"},"product_name":{"S":"car"},"list_price":{"N":"36000.00"},"image_bucket":{"S":"dynamodb-images"},"image_object":{"S":"img/car1.jpg"}}}
{"Item":
{
"SK":{"S":"ver2"},
"record_type":{"S":"product"},"product_id":{"N":"1002"},"version":{"N":"2"},"product_name":{"S":"car"},"list_price":{"N":"37000.00"},"image_bucket":{"S":"dynamodb-images"},"image_object":{"S":"img/car2.jpg"}}}
请注意,第一个JSON记录同时具有PK和SK键属性,而第二个记录缺少PK属性。由于缺少键模式属性PK,第二条记录将在导入过程中导致错误。出于本演示的目的,样本数据中有意包含两条出错记录,一条缺少PK属性,另一条缺少SK属性。
将数据从S3导入DynamoDB
1.登录控制台并导航到DynamoDB服务。在导航窗格中选择从S3导入。
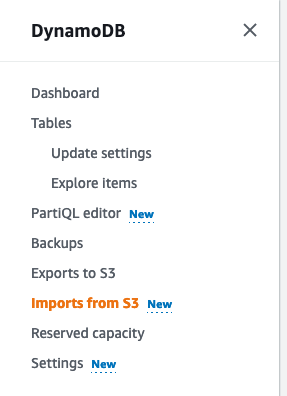
2.“从S3导入”页面列出了有关已创建的任何现有或最近导入作业的信息。选择从S3导入以移动到导入选项页面。
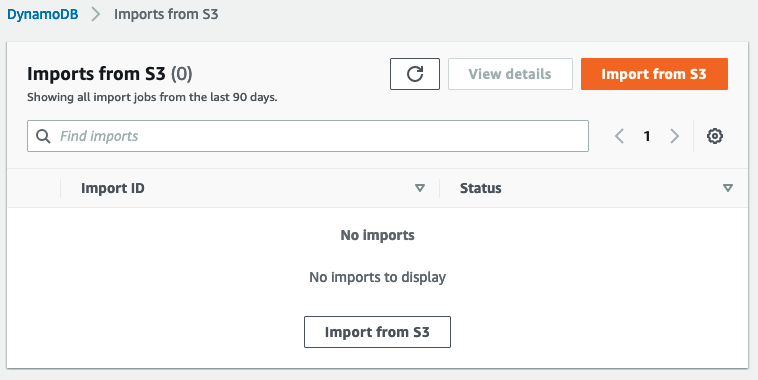
3.在“导入选项”页面上:
a.在S3 URL中,以URI格式输入源S3 bucket和任何文件夹的路径,例如S3://S3 import demo/demo
b.选择此AWS帐户作为存储桶所有者
c.验证其余字段是否设置为默认值:
导入文件格式:DynamoDB JSON
导入文件压缩:无
d.选择下一步
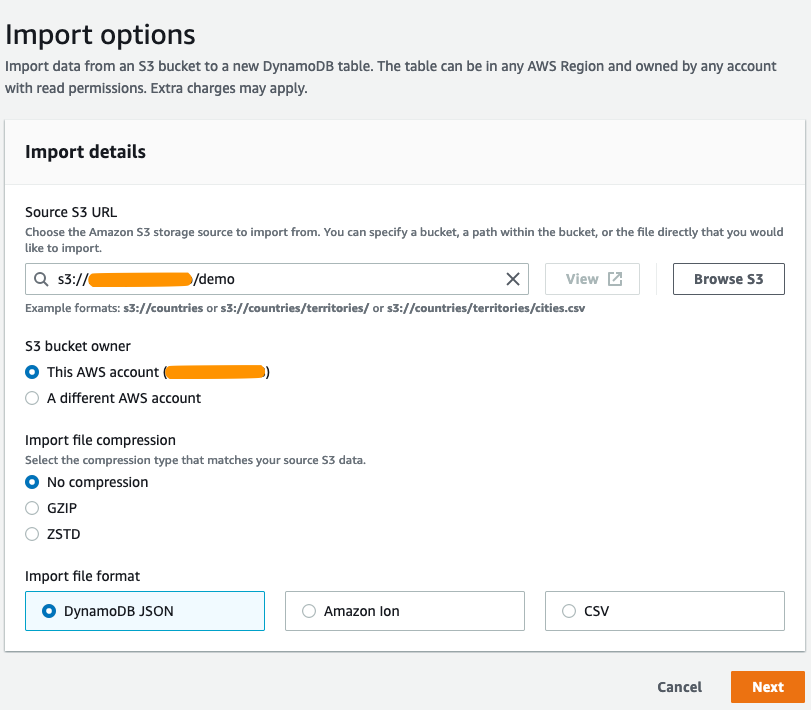
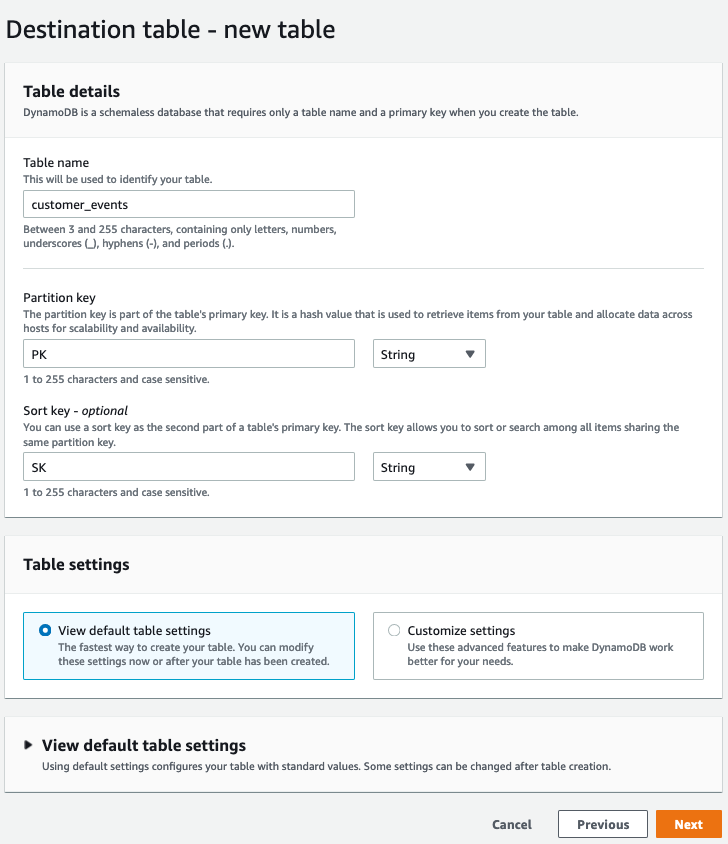
4.目标表上–新表
a.在“表名称”中,输入新表的名称。
b.在分区键中,输入PK作为名称,并选择String作为类型。
c.在本例中,我们的数据包括一个排序键。在“排序键”框中,通过输入SK作为排序键名称并选择String作为数据类型来定义排序键。
d.在“设置”中,确认已选择默认设置,然后选择“下一步”。这将创建一个具有5个读容量单元(RCU)和5个写容量单元(WCU)的配置容量的表。但是,导入不会消耗表的容量,也不依赖于这些设置。
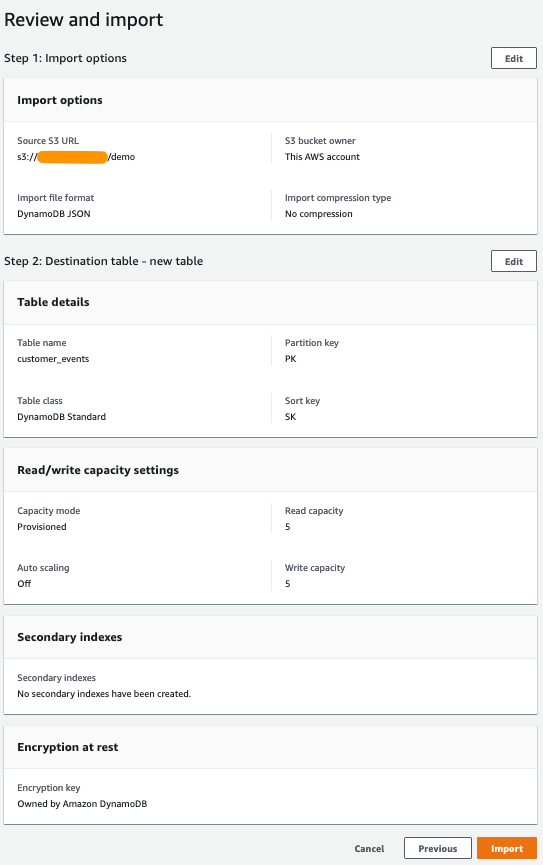
5.确认选择和设置正确,然后选择“导入”开始导入。
6.导入将需要一些时间。您可以在“从S3导入”页面上跟踪导入的状态。等待导入作业的状态从“导入”更改为“完成”,然后继续。
检查导入的结果
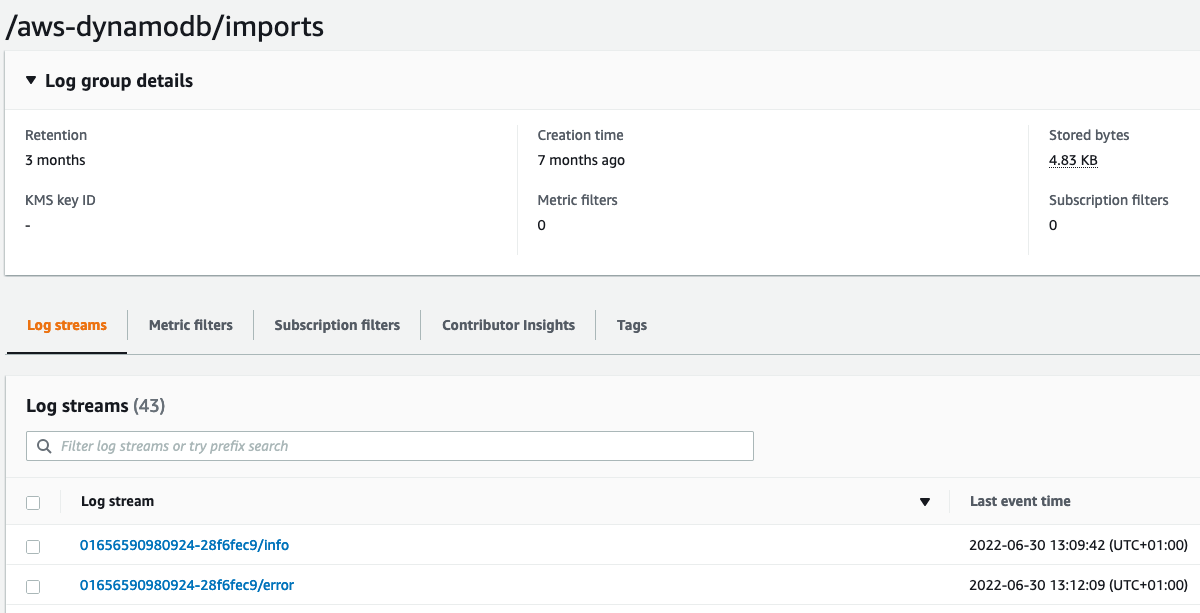
对于每个导入作业,DynamoDB在CloudWatch中记录一个初始/info日志流。此日志流指示导入的开始,并确保有足够的权限继续记录。如果不存在足够的权限,导入作业将立即失败。
下面的图7显示了CloudWatch中的日志流示例。
将记录导致错误的各个记录(总错误计数最多为10000),以及错误元数据,如S3对象中的记录编号和错误消息。
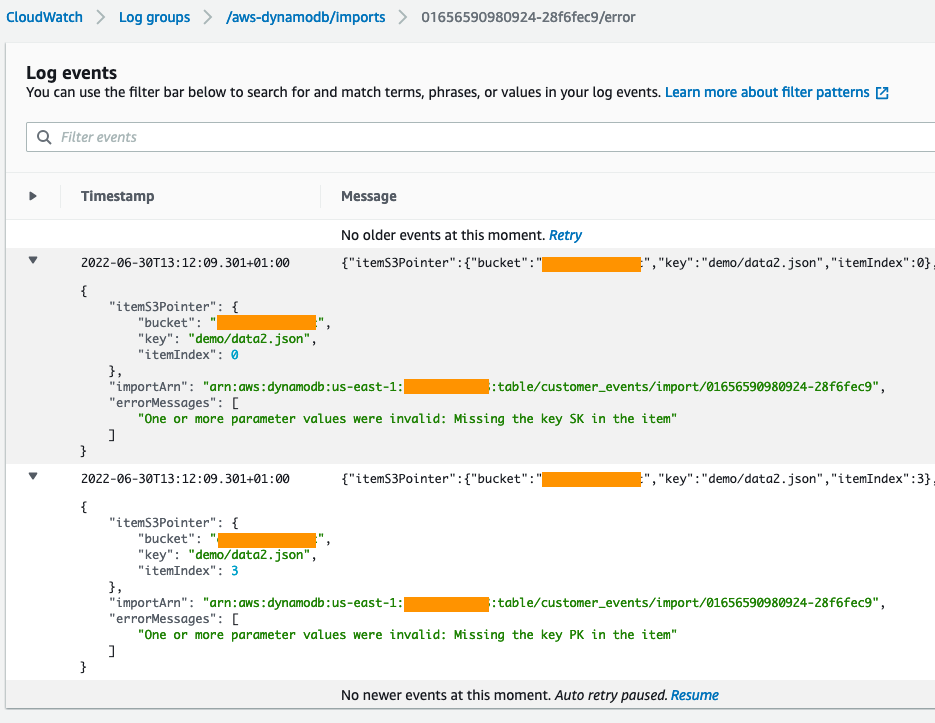
如上图8所示,两个故意放置的错误记录中的一个缺少PK属性,另一个缺少SK属性。DynamoDB需要这两个属性,因为它们是新表的分区键和排序键,因此DynamoDB无法将任何记录导入表中。
如前所述,如果错误计数超过10000,DynamoDB将停止记录错误,但继续导入剩余的源数据。请参阅《开发人员指南》中“验证错误”一节中有关故障排除的详细信息。当表状态为“正在创建”时,无法访问表中的数据,在这种情况下,表状态表示导入正在进行。
操作考虑
服务将尝试处理与指定源前缀匹配的所有S3对象。
S3存储桶不必与目标DynamoDB表位于同一区域。
如果要导入以前由DynamoDB表导出到S3功能创建的文件,则必须提供数据文件夹的路径。不使用父文件夹中包含的清单文件。下面是一个示例S3路径:
s3://my-bucket/AWSDynamoDB/01636728158007-9c06f1a9/data
为了跨AWS帐户导入数据,您需要确保导入请求者有权列出并从源S3存储桶中获取数据。S3存储桶策略还需要允许请求者访问。
当导入作业运行时,许多并行进程从S3读取对象并加载表。您不需要使用任何传统的写单元,也不必担心导入过程中的节流。执行导入所需的时间可能从几分钟到几小时不等,主要取决于源数据的大小和源数据中键的分布。源数据中高度倾斜的密钥分布可能会比密钥分布良好的数据导入速度慢。
您可能遇到的常见错误包括语法错误、格式问题和没有所需主键的记录。有关错误的信息记录在CloudWatch日志中,以供进一步调查。
与定义新的DynamoDB表的常规过程非常相似,您可以选择创建辅助索引以支持应用程序的其他访问模式。在数据加载期间定义辅助索引将导致在导入期间填充索引,与在表处于活动状态并消耗写容量单位后创建新的辅助索引相比,节省了时间和成本。
注意:导入过程只能将数据加载到导入过程中创建的全新表中。
成本考虑
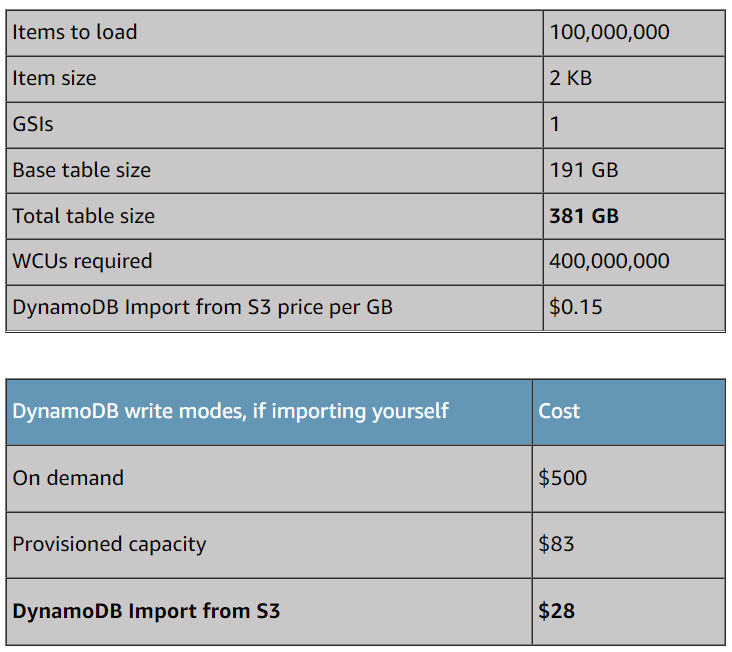
运行导入的成本基于S3中源数据的未压缩大小乘以每GB成本,在美国东部(北弗吉尼亚)地区为每GB 0.15美元。定义了一个或多个全局辅助索引(GSI)的表不会产生额外成本,但任何失败记录的大小都会增加总成本。
如果您目前使用DynamoDB按需备份,并且有恢复表的经验,您会发现新S3导入功能的成本和性能是相当的。
使用S3导入功能加载数据的总成本明显低于使用非本地解决方案将数据加载到DynamoDB中的正常写入成本,如此处显示的成本细分示例场景所示。
S3导入功能在所有区域都可用。有关详细信息,请参阅DynamoDB定价页面。
结论
在本文中,我们介绍了DynamoDB从S3导入功能,并向您展示了如何将数据从S3 bucket导入到DynamoDB中。将大型遗留数据集摄取到DynamoDB变得更加容易,因为现在您可以请求导入,而无需设置基础设施、编写加载例程或担心容量设置或限制错误。您可以使用以前发布的导出到S3功能来简化DynamoDB的管理;只需在控制台中单击几下,您就可以跨区域和跨帐户移动DynamoDB表数据。您可以使用此示例脚本作为脚本的模板,将MySQL数据转换为DynamoDB JSON格式,然后写入S3 bucket。
请在下面的评论部分告知我们您的反馈。
S3导入功能在所有区域都可用。有关详细信息,请参阅DynamoDB定价页面。
结论
在本文中,我们介绍了DynamoDB从S3导入功能,并向您展示了如何将数据从S3 bucket导入到DynamoDB中。将大型遗留数据集摄取到DynamoDB变得更加容易,因为现在您可以请求导入,而无需设置基础设施、编写加载例程或担心容量设置或限制错误。您可以使用以前发布的导出到S3功能来简化DynamoDB的管理;只需在控制台中单击几下,您就可以跨区域和跨帐户移动DynamoDB表数据。您可以使用此示例脚本作为脚本的模板,将MySQL数据转换为DynamoDB JSON格式,然后写入S3 bucket。
请在下面的评论部分告知我们您的反馈。
关于作者

Robert McCauley是波士顿的DynamoDB专业解决方案架构师。十年前,他在亚马逊机器人公司(Amazon Robotics)担任SQL开发人员,开始了自己的亚马逊职业生涯,之后在加入AWS之前,他曾担任过Alexa技能解决方案架构师。

Aman Dhingra是来自爱尔兰都柏林的DynamoDB专业解决方案架构师。他热衷于分布式系统,拥有大数据和分析技术方面的背景。作为DynamoDB专业解决方案架构师,Aman帮助客户设计、评估和优化由DynamoDB支持的工作负载。
原文标题:Amazon DynamoDB can now import Amazon S3 data into a new table
原文作者:Robert McCauley and Aman Dhingra
原文链接:https://aws.amazon.com/cn/blogs/database/amazon-dynamodb-can-now-import-amazon-s3-data-into-a-new-table/
