





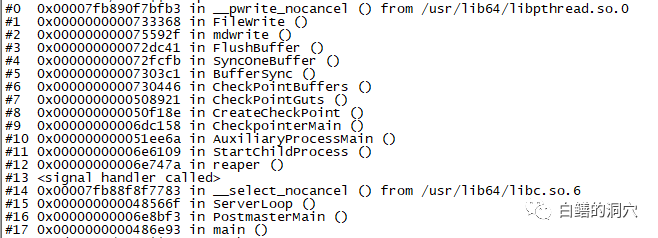
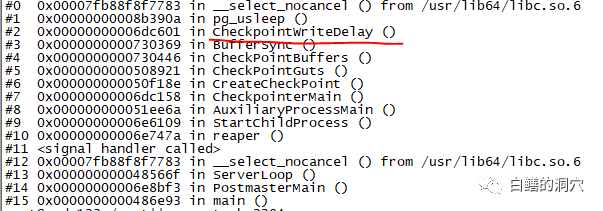
手动执行CHECKPOINT命令
执行需要隐式的检查点的命令(例如pg_start_backup,CREATE DATABASE,或pg_ctl stop|restart和其他一些命令)
自上一个检查点以来已达到配置的时间量(参数CHECKPOINT_TIMEOUT 设置)
自上一个检查点以来已经新生成了某个限额的的WAL数量(MAX_WAL_SIZE,checkpoint_completion_target)

文章转载自白鳝的洞穴,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
