




介绍
本文是数据科学访谈系列的第二部分,到目前为止,我们已经介绍了回归分析。本文将讨论随机森林、SVM、偏差-方差权衡和集成方法。这些概念在面试中经常被问到。因此,在参加任何数据科学面试之前,必须通过数学模型清楚地了解这些概念。
常见面试问题
下面列出了一些涵盖主题的问题 - 随机森林、SVM、偏差-方差权衡和集成方法。
决策树如何处理数字和分类数据?
决策树能够同时处理:数字和分类特征。
基于特征的决策树中的每个拆分:
- 拆分中的分类变量元素属于特定类。
- 拆分中的连续变量元素高于阈值。
此外,更好的方法是使用编码技术(例如 LabelEncoding 或 OneHotEncoding)将分类变量转换为连续变量。
什么是随机森林算法?
随机森林是一种遵循 bagging 方法的集成算法。决策树是随机森林的基本估计量。顾名思义,森林是许多树的集合,随机森林是各种决策树的集合。随机森林随机选择一个特征集,在每个决策树节点处选择最佳分割。
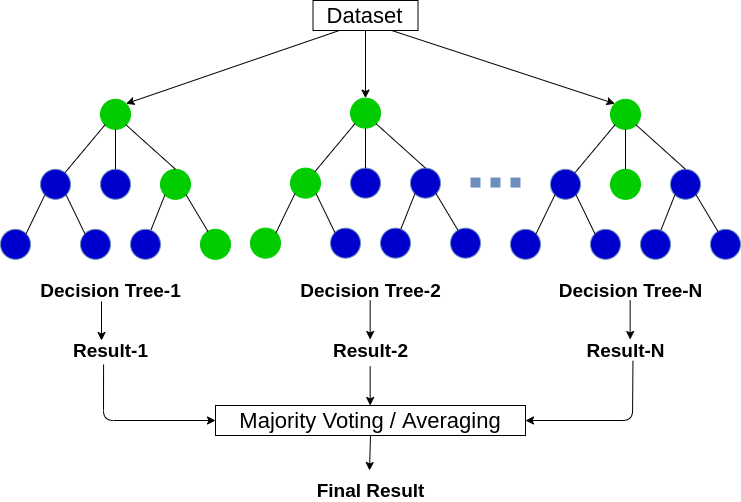
随机森林是一种用于回归和分类问题的监督机器学习算法。
模型
- 从数据集中创建随机子集也称为引导。
- 一组随机特征将决定每个决策树节点的最佳分割。
- 它适合每个子集的决策树模型。
- 最终预测将是所有决策树预测的平均值。
随机森林主要适用于特征重要性选择。方法 (._feature_importances_) 找到随机森林模型的特征重要性。
一些重要参数:-
1. n_estimators :- 随机森林中决策树的数量。
2.标准:- “基尼”或“熵”。
3. min_samples_split :- 拆分前叶节点中的最小样本数或数据点数。
4. max_features : - 每个决策树中分割的最大特征数。
5. n_jobs :- 为 fit 和 predict 执行的作业数。设置为 (-1) 以利用所有可用内核进行并行处理。
随机森林方法在 Scikit-Learn 库中可用,可以通过以下代码导入和使用:
从 sklearn.ensemble 导入 RandomForestClassifier 模型 = RandomForestClassifier()
什么是偏差和方差权衡?
预测模型中的预测误差主要有两个原因:
- 偏见
- 方差
偏差-方差权衡告诉我们最小化预测中的偏差和方差,以避免模型欠拟合和过拟合。
偏见
由于机器学习算法的过度简化,导致模型出现偏差。误差是平均预测值与实际值之间的差异。因此,偏差衡量模型预测与正确预测的距离。高偏差总是导致高错误的训练和测试集。
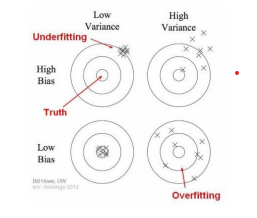
方差
由于复杂的机器学习算法,会出现方差错误。方差表示给定数据点的预测值与实际值的可变性。方差是模型预测在不同模型实现之间的差异程度。
例如:在一次选举中,投票 Jack 13,投票 John 16,未回答者 21 总共 50。投票 Jack 的概率是 13/50,即 44.8%。We predicted that John would win by 10 points, but when the election results came out, he lost by 10 points. 但是我们哪里做错了?
答案是我们的预测可能是对有偏差的源数据进行的,或者样本量很小。小样本量会增加方差。增加样本量将使结果更加一致,但由于有偏差的来源,仍然可能非常不准确。但是,这将减少方差。
因此,如果我们试图减少偏差,方差会增加,反之亦然。因此,我们根据我们的要求以一种换另一种,并尽量将两者保持在最低限度。
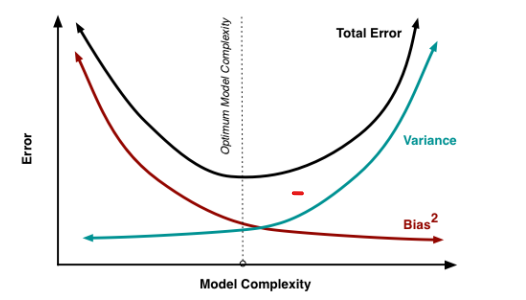
什么是集成方法?Bagging 和 Boosting 有什么区别?
集成方法是一组弱学习器聚集在一起形成一个强学习器。有两种技术可用于制作集成模型:
- Bagging(引导聚合)
- 提升
Bagging
如果我们的目标是减少过拟合模型的方差,那么我们使用 Bootstrapped 集成模型。让我们了解 bagging 技术与决策树模型的工作原理。
这个概念是从带有替换的训练数据中产生几个随机子集。现在,每个子集数据集合都被用来训练他们的决策树。结果,我们最终得到了不同模型的集合。使用来自所有树的所有预测的平均值,这比单个决策树更稳健。
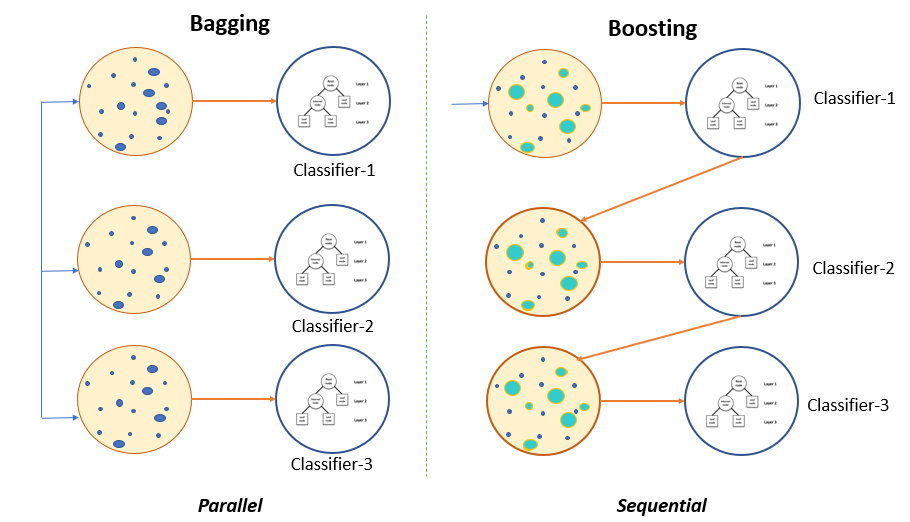
我们可以通过上图清楚地识别 Bagging 和 Boosting 之间的区别。
提升
Boosting 技术适合早期学习者使用一个简单的模型来顺序学习并分析数据中的错误。换句话说,boosting 用随机样本拟合连续树,并减少每一步初步决策树的净误差。
当假设错误地预测输入时,其权重会更新。因此,即将到来的假设更有可能正确预测输出。最后混合整个集合将易受攻击的学习者转变为性能更好的模型。
不同类型的 Boosting 算法有:
- AdaBoost
- 梯度提升
- XGBoost
什么是 SVM 分类?
SVM 或支持向量机是一种监督机器学习算法,它使用两种类型的 SVM 分类器进行分类:
- 线性支持向量机
- 非线性支持向量机
线性支持向量机
线性 SVM 通过划分两个类的直线超平面来分离数据点。该超平面也称为最大边距超平面。
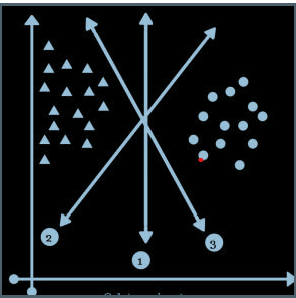
上图显示了具有三个超平面的线性 SVM 模型构建过程。这些超平面将数据点分为两类,但超平面 1与最近的数据样本具有最大的边距。因此,它将被选择用于最终预测。

上图显示了用于执行 SVM 进行二进制分类的 Python 代码。SVM 默认使用线性内核。SVM 对象具有用于支持向量分类器的 SVC 方法。
非线性支持向量机
多类分类任务中的数据点不仅仅存在于二维空间中。因此,使用线性超平面将它们分开在 p 维中是不可行的。因为在 p 维中,数据变得非线性可分,无法使用线性内核进行分离。因此,我们使用内核技巧使用更高的维度进行线性分离。内核绘制非线性超平面,使区分变得容易。
一些标准内核是:
- 多项式核
- RBF内核
- 高斯核
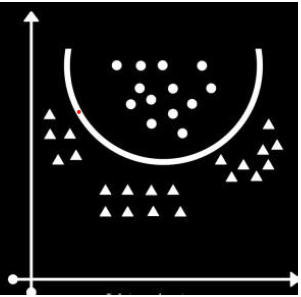
上图代表了多类分类问题的 SVM 模型构建过程。该模型使用内核作为超平面将数据点分类到各自的类或标签中。
尽管线性和非线性 SVM 的 Python 代码保持不变,只是内核发生了变化。让我们通过以下示例了解区别:
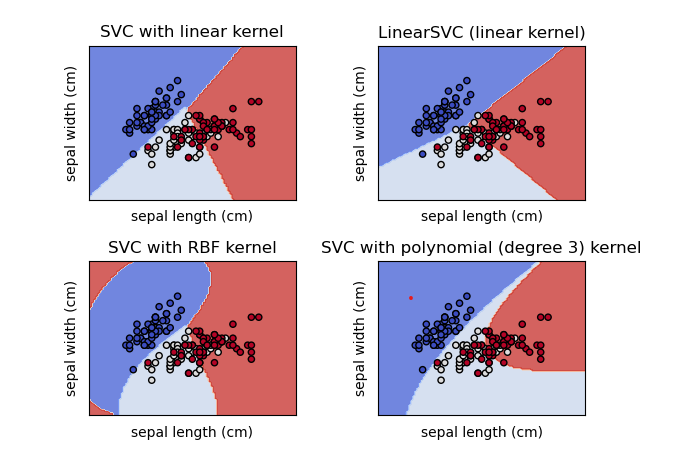
上图显示了在 iris 数据集上完成的多类分类。分类分为三类:Iris Setosa、Iris Versicolour 和 Iris Virginica。这张图片显示了关于两个特征的不同内核的分类,萼片长度和萼片宽度。
带有线性内核的 SVC 与 LinearSVC 相同。RBF 内核和多项式内核用非线性超平面分离数据。由于所有这些模型都只使用二维,因此带有内核的分类看起来像带有线性的分类。但是,如果我们使用多维空间,则通过 Kernels 进行分类会更准确,但不幸的是,我们无法在这里将多维空间可视化。所以我们只需要想象一下。
SVM 分类器的优点
- SVM 对于大量特征也非常有效。
- 我们还可以使用内核技巧对非线性数据进行分类。
- SVM 倾向于与文本分类很好地配合,例如垃圾邮件或非垃圾邮件分类。
- SVM 是一种稳健的分类模型,因为它使边际最大化。
SVM分类器的缺点
- SVM 的主要挑战是选择内核。错误的内核会更多地增加错误。
- 它在大量样本时表现不佳。
- SVM 在测试阶段可能非常慢。
- 由于二次规划,SVM算法非常复杂并且消耗大量内存。
结论
我们讨论了一些数据科学面试问题,包括决策树、随机森林、集成学习和 SVM。所有这些概念对于面试都是必不可少的。这些概念经常用于现实生活中的项目;因此,在准备数据科学面试时,对这些概念有一个很好的理解是至关重要的。SVM 的实际应用是生物信息学、手写识别、人脸检测、图像分类、文本分类、垃圾邮件检测等。此外,正如您所听说的,随机森林在大多数项目中用于查找特征重要性。随机森林和基于树的算法在任何 Hackathon 和 Kaggle 比赛中获得高分也非常有效。
让我们用几个关键要点来总结这篇文章:
- 要处理分类变量,请使用编码技术。
- 随机森林是决策树的自举模型。
- 我们应始终将偏差和方差保持在可行的最小值。
- bagging Ensemble 技术使一组弱学习器创建一个强学习器;Boosting 适合早期学习者使用一个简单的模型来按顺序学习以减少错误。
- SVM 使用超平面来分离数据点并最大化边距。
- 线性 SVM 只能分离线性可分的数据点。因此,我们使用内核技巧来分离非线性可分数据。
- Ensemble 技术通常与基于树的算法配合得更好,并提供最佳结果。
- 许多数据科学家使用 Ensemble 技术赢得了数据科学黑客马拉松和 Kaggle 比赛。
原文标题:Data Science Interview Series: Random Forest and SVM
原文作者:Kavish111
原文链接:https://www.analyticsvidhya.com/blog/2022/07/data-science-interview-series-part-2-random-forest-and-svm/
