Table of Contents
一. 特征工程
特征工程赢得了Kaggle竞赛:那些获胜的是那些能够从数据中创建最有用的功能的人。(这在很大程度上是正确的,因为获胜的模型,至少对于结构化数据来说,都倾向于梯度提升的变体)。这代表了机器学习中的一种模式:特征工程比模型构建和超参数调优有更大的投资回报。这是一篇关于这个主题的好文章。正如Andrew Ng喜欢说的那样:“应用机器学习基本上就是特征工程。”
在选择合适的模型和最优的设置是很重要的,模型只能从给定的数据中学习。确保这些数据尽可能与任务相关是数据科学家的工作(可能还有一些自动化工具来帮助我们)。
特征工程指的是一个遗传过程,它既包括特征构造:从现有数据中添加新特征,也包括特征选择:只选择最重要的特征或其他降维方法。我们可以使用许多技术来创建特性和选择特性。
当我们开始使用其他数据源时,我们将做大量的特性工程,但是在这个笔记本中,我们将只尝试两种简单的特性构造方法:
- 多项式特征
- 领域知识的特点
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
# 输入处理缺失值
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import PolynomialFeatures
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 为多项式特征建立一个新的数据dataframe
poly_features = app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH', 'TARGET']]
poly_features_test = app_test[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
imputer = SimpleImputer(strategy='median')
poly_target = poly_features['TARGET']
poly_features = poly_features.drop(columns=['TARGET'])
# 需要估算缺失值
poly_features = imputer.fit_transform(poly_features)
poly_features_test = imputer.transform(poly_features_test)
# 创建具有指定程度的多项式对象
poly_transformer = PolynomialFeatures(degree=3)
# 训练多项式特征
poly_transformer.fit(poly_features)
# 转化特征值
poly_features = poly_transformer.transform(poly_features)
poly_features_test = poly_transformer.transform(poly_features_test)
print('Polynomial Features shape: ', poly_features.shape)
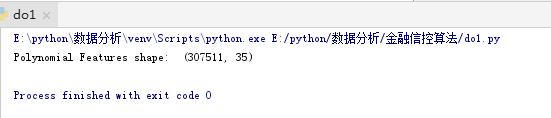
这创建了大量的新特性。要获得名称,我们必须使用多项式特性get_feature_names方法。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
# 输入处理缺失值
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import PolynomialFeatures
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 为多项式特征建立一个新的数据dataframe
poly_features = app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH', 'TARGET']]
poly_features_test = app_test[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
imputer = SimpleImputer(strategy='median')
poly_target = poly_features['TARGET']
poly_features = poly_features.drop(columns=['TARGET'])
# 需要估算缺失值
poly_features = imputer.fit_transform(poly_features)
poly_features_test = imputer.transform(poly_features_test)
# 创建具有指定程度的多项式对象
poly_transformer = PolynomialFeatures(degree=3)
# 训练多项式特征
poly_transformer.fit(poly_features)
# 转化特征值
poly_features = poly_transformer.transform(poly_features)
poly_features_test = poly_transformer.transform(poly_features_test)
#print('Polynomial Features shape: ', poly_features.shape)
poly_list = poly_transformer.get_feature_names(input_features = ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH'])[:50]
for p in poly_list:
print(p)

有35个特性,每个特性都被提升到3级和交互项。
现在,我们可以看到这些新特性是否与目标相关联。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
# 输入处理缺失值
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import PolynomialFeatures
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 为多项式特征建立一个新的数据dataframe
poly_features = app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH', 'TARGET']]
poly_features_test = app_test[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
imputer = SimpleImputer(strategy='median')
poly_target = poly_features['TARGET']
poly_features = poly_features.drop(columns=['TARGET'])
# 需要估算缺失值
poly_features = imputer.fit_transform(poly_features)
poly_features_test = imputer.transform(poly_features_test)
# 创建具有指定程度的多项式对象
poly_transformer = PolynomialFeatures(degree=3)
# 训练多项式特征
poly_transformer.fit(poly_features)
# 转化特征值
poly_features = poly_transformer.transform(poly_features)
poly_features_test = poly_transformer.transform(poly_features_test)
#print('Polynomial Features shape: ', poly_features.shape)
# 创建特性的dataframe
poly_features = pd.DataFrame(poly_features,
columns = poly_transformer.get_feature_names(['EXT_SOURCE_1', 'EXT_SOURCE_2',
'EXT_SOURCE_3', 'DAYS_BIRTH']))
# 增加目标值
poly_features['TARGET'] = poly_target
# 找到目标相关性
poly_corrs = poly_features.corr()['TARGET'].sort_values()
# 显示最不相关和最相关的一面
print(poly_corrs.head(10))
print(poly_corrs.tail(5))

一些新变量与目标的相关性(就绝对值大小而言)比原始特征更大。当我们构建机器学习模型时,我们可以尝试使用和不使用这些特性来确定它们是否真的有助于模型学习。
我们将把这些特性添加到训练和测试集的副本中,然后评估有和没有这些特性的模型。很多时候,在机器学习中,知道一种方法是否有效的唯一方法就是去尝试它!
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
# 输入处理缺失值
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import PolynomialFeatures
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
# 为多项式特征建立一个新的数据dataframe
poly_features = app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH', 'TARGET']]
poly_features_test = app_test[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
imputer = SimpleImputer(strategy='median')
poly_target = poly_features['TARGET']
poly_features = poly_features.drop(columns=['TARGET'])
# 需要估算缺失值
poly_features = imputer.fit_transform(poly_features)
poly_features_test = imputer.transform(poly_features_test)
# 创建具有指定程度的多项式对象
poly_transformer = PolynomialFeatures(degree=3)
# 训练多项式特征
poly_transformer.fit(poly_features)
# 转化特征值
poly_features = poly_transformer.transform(poly_features)
poly_features_test = poly_transformer.transform(poly_features_test)
#print('Polynomial Features shape: ', poly_features.shape)
# 创建特性的dataframe
poly_features = pd.DataFrame(poly_features,
columns = poly_transformer.get_feature_names(['EXT_SOURCE_1', 'EXT_SOURCE_2',
'EXT_SOURCE_3', 'DAYS_BIRTH']))
# 增加目标值
poly_features['TARGET'] = poly_target
# 找到目标相关性
poly_corrs = poly_features.corr()['TARGET'].sort_values()
# 将测试特征值放入dafaframe中
poly_features_test = pd.DataFrame(poly_features_test,
columns = poly_transformer.get_feature_names(['EXT_SOURCE_1', 'EXT_SOURCE_2',
'EXT_SOURCE_3', 'DAYS_BIRTH']))
# 将多项式特征合并到训练集中
poly_features['SK_ID_CURR'] = app_train['SK_ID_CURR']
app_train_poly = app_train.merge(poly_features, on = 'SK_ID_CURR', how = 'left')
# 将多项式特性合并到测试dafaframe中
poly_features_test['SK_ID_CURR'] = app_test['SK_ID_CURR']
app_test_poly = app_test.merge(poly_features_test, on = 'SK_ID_CURR', how = 'left')
# 对齐dafaframe
app_train_poly, app_test_poly = app_train_poly.align(app_test_poly, join = 'inner', axis = 1)
# 显示新的矩阵信息
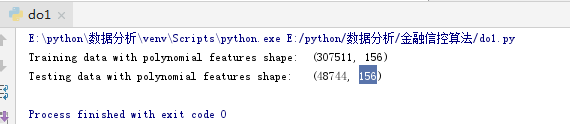
print('Training data with polynomial features shape: ', app_train_poly.shape)
print('Testing data with polynomial features shape: ', app_test_poly.shape)
二. 领域知识的特点
因为我不是信用专家,也许称这种“领域知识”并不完全正确,但或许我们可以称之为“应用有限金融知识的尝试”。
在这种思路下,我们可以创建一些功能,试图捕捉我们认为可能对判断客户是否会拖欠贷款很重要的内容。
在这里,我将使用由Aguiar的这个脚本启发的4个特性:
- CREDIT_INCOME_PERCENT:信用金额相对于客户的收入的百分比
- ANNUITY_INCOME_PERCENT:贷款年金相对于客户收入的百分比
- CREDIT_TERM:以月份为单位的付款期限(因为年金是每月应付金额
- DAYS_EMPLOYED_PERCENT:相对于客户的年龄,被雇佣的天数的百分比
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
# 输入处理缺失值
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import PolynomialFeatures
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
app_train_domain = app_train.copy()
app_test_domain = app_test.copy()
app_train_domain['CREDIT_INCOME_PERCENT'] = app_train_domain['AMT_CREDIT'] / app_train_domain['AMT_INCOME_TOTAL']
app_train_domain['ANNUITY_INCOME_PERCENT'] = app_train_domain['AMT_ANNUITY'] / app_train_domain['AMT_INCOME_TOTAL']
app_train_domain['CREDIT_TERM'] = app_train_domain['AMT_ANNUITY'] / app_train_domain['AMT_CREDIT']
app_train_domain['DAYS_EMPLOYED_PERCENT'] = app_train_domain['DAYS_EMPLOYED'] / app_train_domain['DAYS_BIRTH']
app_test_domain['CREDIT_INCOME_PERCENT'] = app_test_domain['AMT_CREDIT'] / app_test_domain['AMT_INCOME_TOTAL']
app_test_domain['ANNUITY_INCOME_PERCENT'] = app_test_domain['AMT_ANNUITY'] / app_test_domain['AMT_INCOME_TOTAL']
app_test_domain['CREDIT_TERM'] = app_test_domain['AMT_ANNUITY'] / app_test_domain['AMT_CREDIT']
app_test_domain['DAYS_EMPLOYED_PERCENT'] = app_test_domain['DAYS_EMPLOYED'] / app_test_domain['DAYS_BIRTH']
三. 可视化新变量
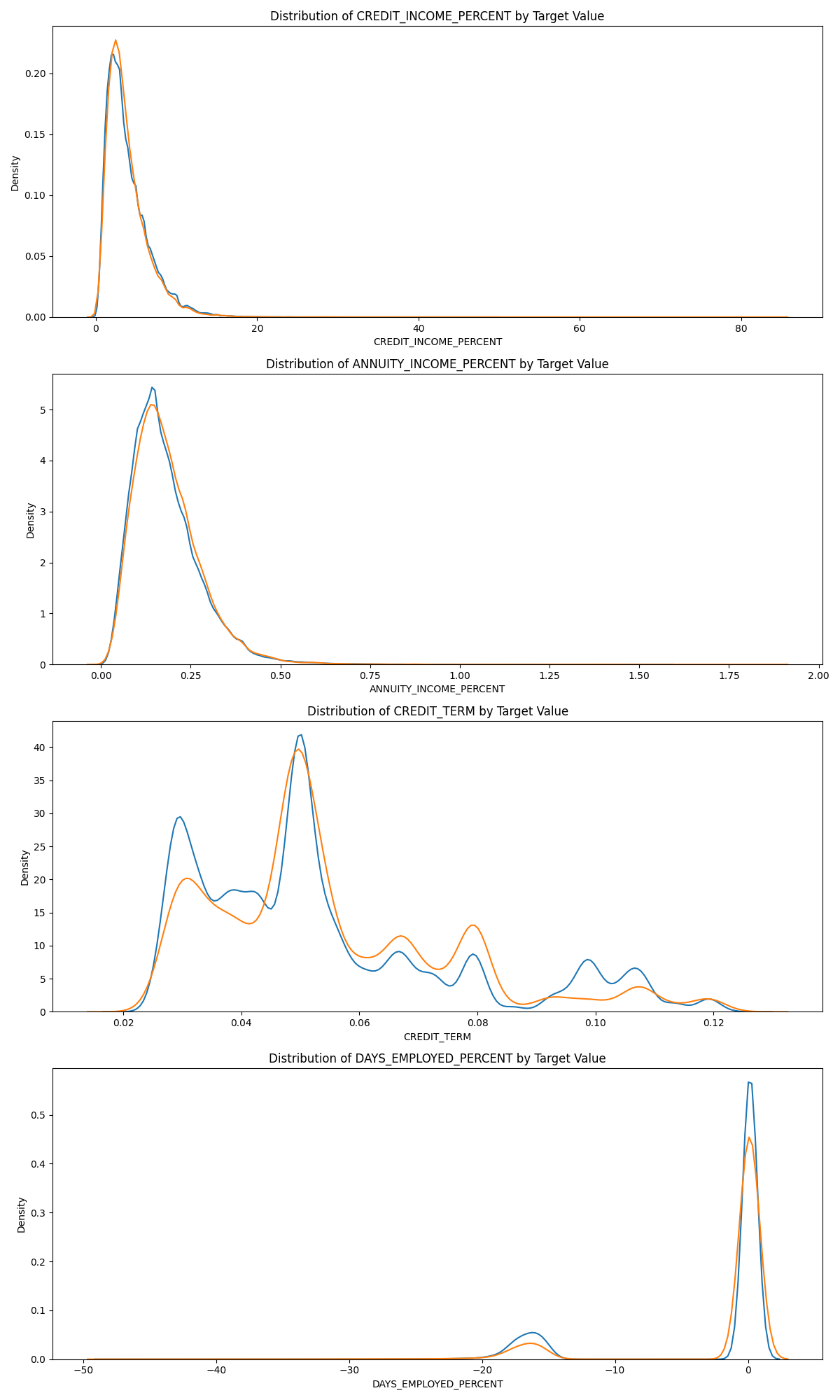
我们应该在图中直观地探讨这些领域知识变量。对于所有这些,我们将使相同的KDE图由目标值
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
# 输入处理缺失值
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import PolynomialFeatures
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
app_train_domain = app_train.copy()
app_test_domain = app_test.copy()
app_train_domain['CREDIT_INCOME_PERCENT'] = app_train_domain['AMT_CREDIT'] / app_train_domain['AMT_INCOME_TOTAL']
app_train_domain['ANNUITY_INCOME_PERCENT'] = app_train_domain['AMT_ANNUITY'] / app_train_domain['AMT_INCOME_TOTAL']
app_train_domain['CREDIT_TERM'] = app_train_domain['AMT_ANNUITY'] / app_train_domain['AMT_CREDIT']
app_train_domain['DAYS_EMPLOYED_PERCENT'] = app_train_domain['DAYS_EMPLOYED'] / app_train_domain['DAYS_BIRTH']
app_test_domain['CREDIT_INCOME_PERCENT'] = app_test_domain['AMT_CREDIT'] / app_test_domain['AMT_INCOME_TOTAL']
app_test_domain['ANNUITY_INCOME_PERCENT'] = app_test_domain['AMT_ANNUITY'] / app_test_domain['AMT_INCOME_TOTAL']
app_test_domain['CREDIT_TERM'] = app_test_domain['AMT_ANNUITY'] / app_test_domain['AMT_CREDIT']
app_test_domain['DAYS_EMPLOYED_PERCENT'] = app_test_domain['DAYS_EMPLOYED'] / app_test_domain['DAYS_BIRTH']
plt.figure(figsize=(12, 20))
# 迭代新特征
for i, feature in enumerate(
['CREDIT_INCOME_PERCENT', 'ANNUITY_INCOME_PERCENT', 'CREDIT_TERM', 'DAYS_EMPLOYED_PERCENT']):
# 为每个soruce创建一个新的子图
plt.subplot(4, 1, i + 1)
# 偿还贷款平面图
sns.kdeplot(app_train_domain.loc[app_train_domain['TARGET'] == 0, feature], label='target == 0')
# 未偿还贷款的平面图
sns.kdeplot(app_train_domain.loc[app_train_domain['TARGET'] == 1, feature], label='target == 1')
# 平面图的标签
plt.title('Distribution of %s by Target Value' % feature)
plt.xlabel('%s' % feature);
plt.ylabel('Density');
plt.tight_layout(h_pad=2.5)
plt.show()
三. 基线
原始的基准,我们可以猜测所有例子测试相同的值集。我们被要求预测的概率不偿还贷款,如果我们完全不确定,我们猜0.5测试集上的所有观测。这将给我们一个接收器的操作特性曲线下的面积(AUC ROC)0.5的竞争(随机猜测分类任务得分0.5)。
因为我们已经知道我们会得到什么分数,我们真的不需要做一个天真的基线猜测。
让我们用一个稍微复杂一点的模型来描述我们的实际基线:逻辑回归。
四. 逻辑回归的实现
在这里,我将侧重于实现模型而不是解释细节,但是对于那些想要更多地了解机器学习算法理论的人,我建议对统计学习和使用scikit - learning和TensorFlow的实际机器学习进行介绍。
这两本书都介绍了制作模型所需的理论和代码(分别用R和Python编写)。
他们都认为最好的学习方法就是实践,而且他们都非常有效!
为了获得基线,我们将在编码分类变量之后使用所有的特性。
我们将通过填充缺失值(赋值)和规范化特征的范围(特征缩放)对数据进行预处理。
下面的代码执行这两个预处理步骤。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
# 输入处理缺失值
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import MinMaxScaler
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
app_train = app_train.select_dtypes(['number'])
app_test = app_test.select_dtypes(['number'])
# 从训练数据中删除目标
if 'TARGET' in app_train:
train = app_train.drop(columns=['TARGET'])
else:
train = app_train.copy()
# 特征名称
features = list(train.columns)
# 复制测试集
test = app_test.copy()
# 缺失值的中值估算
imputer = SimpleImputer(strategy='median')
# 将每个特性缩放到0-1
scaler = MinMaxScaler(feature_range=(0, 1))
# 符合训练数据
imputer.fit(train)
# 转换训练和测试数据
train = imputer.transform(train)
test = imputer.transform(app_test)
# 重复的标量
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
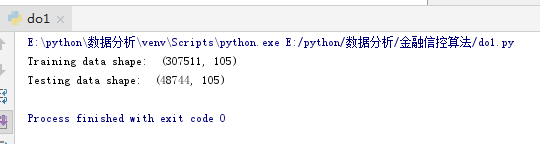
print('Training data shape: ', train.shape)
print('Testing data shape: ', test.shape)
我们将在第一个模型中使用来自Scikit-Learn的logisticregressionlearn。我们将对默认模型设置做的唯一更改是降低正则化参数C,该参数控制过拟合的数量(一个较低的值应该会减少过拟合)。这将使我们得到比默认逻辑回归略好的结果,但它仍然会为未来的任何模型设置一个较低的标准。
这里我们使用熟悉的Scikit-Learn建模语法:首先创建模型,然后使用.fit训练模型,然后使用.predict_proba对测试数据进行预测(记住,我们想要的是概率而不是0或1)。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
# 输入处理缺失值
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
train_labels = app_train['TARGET']
app_train = app_train.select_dtypes(['number'])
app_test = app_test.select_dtypes(['number'])
# 从训练数据中删除目标
if 'TARGET' in app_train:
train = app_train.drop(columns=['TARGET'])
else:
train = app_train.copy()
# 特征名称
features = list(train.columns)
# 复制测试集
test = app_test.copy()
# 缺失值的中值估算
imputer = SimpleImputer(strategy='median')
# 将每个特性缩放到0-1
scaler = MinMaxScaler(feature_range=(0, 1))
# 符合训练数据
imputer.fit(train)
# 转换训练和测试数据
train = imputer.transform(train)
test = imputer.transform(app_test)
# 重复的标量
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
# 使模型具有指定的正则化参数
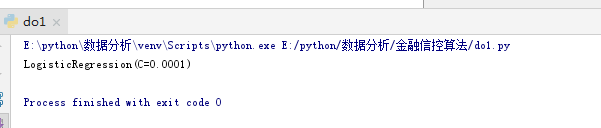
log_reg = LogisticRegression(C = 0.0001)
# 训练训练集
print(log_reg.fit(train, train_labels))
既然这个模型已经被训练过了,我们就可以用它来做预测。我们想预测不还贷的概率,所以我们用模型预测。proba方法。这将返回一个mx2数组,其中m是观察数。第一列是目标的概率是0,第二列是目标的概率是1(对于单个行,两列总和必须为1)。我们希望概率不偿还贷款,所以我们将选择第二列。
下面的代码进行预测并选择正确的列。
- 作出预测
- 确保只选择第二列
预测必须采用sample_submission中显示的格式。csv文件,其中只有两个列:SK_ID_CURR和TARGET。我们将以这种格式从测试集和名为submit的预测中创建一个dafaframe。
# 导入基本处理模块
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import os
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
# 输入处理缺失值
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
app_train = pd.read_csv('E:/home_credit_default_risk/application_train.csv')
app_test = pd.read_csv('E:/home_credit_default_risk/application_test.csv')
train_labels = app_train['TARGET']
app_train = app_train.select_dtypes(['number'])
app_test = app_test.select_dtypes(['number'])
# 从训练数据中删除目标
if 'TARGET' in app_train:
train = app_train.drop(columns=['TARGET'])
else:
train = app_train.copy()
# 特征名称
features = list(train.columns)
# 复制测试集
test = app_test.copy()
# 缺失值的中值估算
imputer = SimpleImputer(strategy='median')
# 将每个特性缩放到0-1
scaler = MinMaxScaler(feature_range=(0, 1))
# 符合训练数据
imputer.fit(train)
# 转换训练和测试数据
train = imputer.transform(train)
test = imputer.transform(app_test)
# 重复的标量
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
# 使模型具有指定的正则化参数
log_reg = LogisticRegression(C = 0.0001)
# 训练训练集
log_reg.fit(train, train_labels)
log_reg_pred = log_reg.predict_proba(test)[:, 1]
# 提交dafaframe
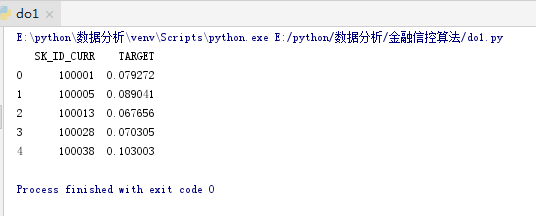
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = log_reg_pred
print(submit.head())
submit.to_csv('log_reg_baseline.csv', index = False)
因为我只选择了number类型的列,所以预测有一定的差异