




Apache Kafka和Apache Flink是流行的数据流应用平台。但是,配置和管理您自己的集群可能具有挑战性并且会产生运营开销。Amazon Web Services (AWS) 提供这些平台的完全托管、高度可用的版本,可与其他 AWS 服务进行本地集成。在这篇博文中,我们将通过部署一个简单的数据流应用程序来探索 AWS 产品的功能和局限性。
这篇博文分为两部分。在第 1 部分中,我们将创建一个 Apache Kafka 集群并部署一个 Apache Kafka Connect 连接器来生成虚假图书购买事件。在第 2 部分中,我们将部署一个 Apache Flink 流应用程序,该应用程序将读取这些事件以计算每分钟的书店销售额。
AWS 上的 Apache Kafka
托管 Apache Kafka 服务称为Amazon Managed Streaming for Apache Kafka或简称“Amazon MSK”。它于 2018 年 11 月首次推出,并于 2019 年 5 月全面上市。以下是它的一些主要功能:
完全托管
您只需要提供所需的配置,该服务将负责配置代理和 Apache Zookeeper 节点。它还将自动应用服务器补丁和升级,并设置监控和警报。
高可用性
您的集群分布在多个可用区 (AZ) 中。该服务会自动替换不正常的节点,而不会导致您的应用程序停机。此外,该服务使用多可用区数据复制来防止数据丢失。
按使用付费的定价
您只需为使用的内容付费。此外,您无需为 Apache Zookeeper 节点或集群内代理和 Apache Zookeeper 节点之间发生的数据传输付费。
托管的 Apache Kafka Connect 服务称为Amazon MSK Connect。它与 Apache Kafka Connect 完全兼容,因此您可以部署任何可用的连接器或提升和转移现有应用程序。该服务负责配置基础设施、监控它并根据连接器负载自动扩展它。
您可以在文档中找到有关这两种服务的更多详细信息。
演示
下图显示了数据流应用程序的整体架构以及我们将要部署的相关服务。为简单起见,我们将仅在两个 AZ 中部署 Amazon MSK,并且 Amazon MSK 和堡垒主机将驻留在同一个公有子网中。在生产环境中,您应该使用三个 AZ 以获得更高的可用性,并将 Amazon MSK 和堡垒主机分别部署在单独的私有子网和公共子网中。因此,您的 Amazon MSK 集群将无法从 AWS 网络外部访问,从而改善您的安全状况。
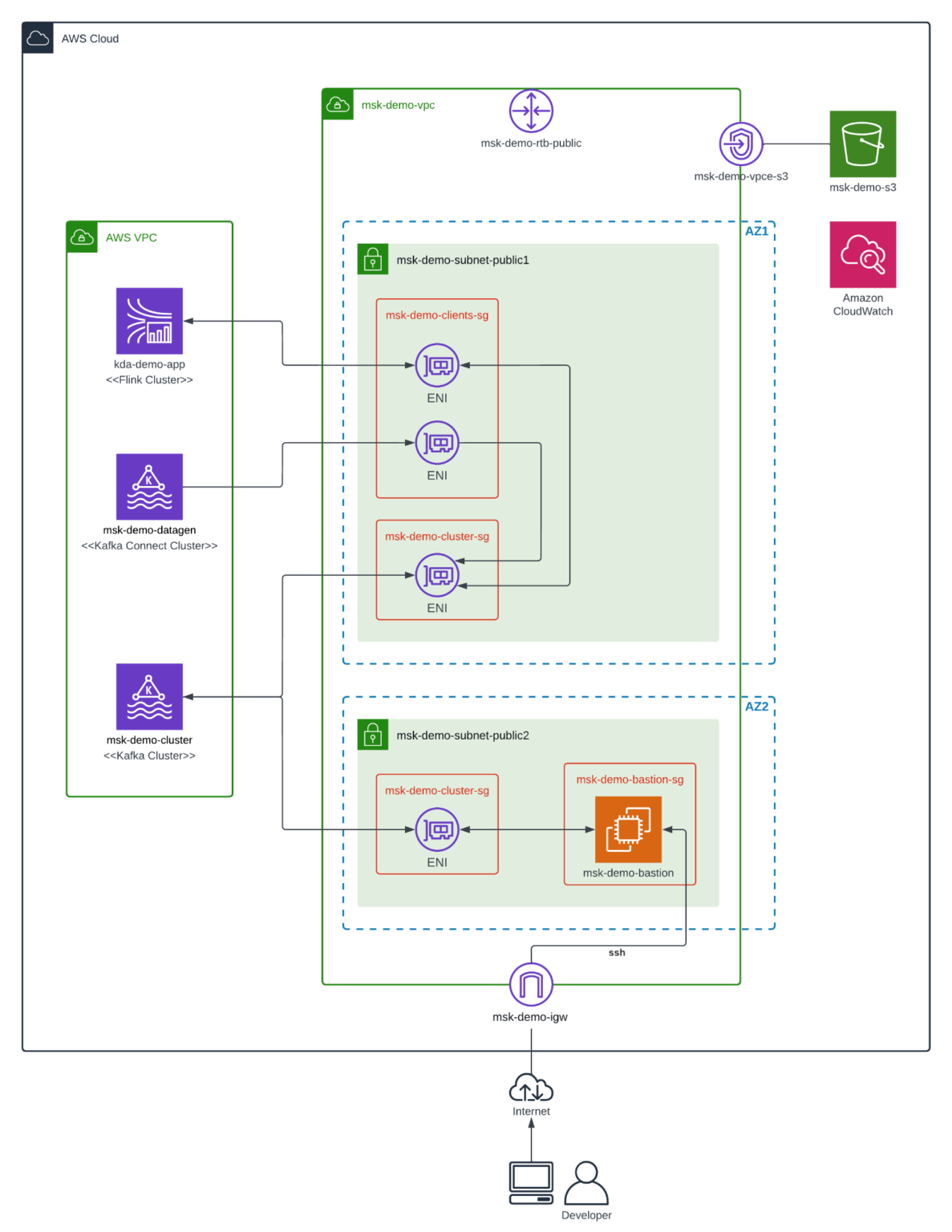
以下是主要组件的简要说明:
msk-demo-cluster
亚马逊 MSK 集群,将虚假图书购买数据存储在三个主题中:“书”、“书店”和“购买”。
msk-demo-datagen
运行Amazon MSK 数据生成器实例的 Amazon MSK Connect 集群。它为上述三个主题生成数据。
kda-demo-app
Apache Flink 应用程序部署在Amazon Kinesis Data Analytics或简称“Amazon KDA”上。我们将在本博客的第 2 部分中了解有关此服务的更多信息。同时,可以说它是一个无服务器、完全托管的 Apache Flink 版本。数据流应用程序读取“购买”和“书店”主题,计算每分钟书店销售额并将结果存储在“销售”主题中。
msk-demo-bastion
用作堡垒主机的Amazon EC2实例。我们可以使用 ssh 连接到它,然后使用kafkacat等工具验证 Amazon MSK 集群的内容。
msk-demo-s3
将 JAR 文件部署到 Amazon KDA 和 Amazon MSK Connect 所需的Amazon S3存储桶。此外,来自 Amazon MSK 和 Amazon MSK Connect 的日志转储到此处以方便查阅。
msk-demo-vpc
包含演示应用程序所需的公有子网和其他连接资源的Amazon VPC网络。定义了多个安全组以限制对源和目标资源上特定端口的访问。
部署
我们不会介绍部署 Amazon MSK 集群和 Amazon MSK 数据生成器所需的所有步骤。如果您正在寻找详细信息,请查看MSK Connect和MSK 实验室页面上的如何部署 MSK 数据生成器。相反,我们将专注于设置集群时遇到的具体配置和困难。
亚马逊 MSK
截至撰写本文时,AWS 控制台中显示的推荐 Apache Kafka 版本为 2.6.2,最新支持的版本为 2.8.1。但是,Apache Kafka 的最新版本是 3.2.0。因此,如果您需要最新版本的 Apache Kafka,Amazon MSK 可能不适合您。在最新版本可用之前有一点延迟。
Amazon MSK 集群的配置很简单,您只需指定代理实例的类型和数量、可用区的数量和每个代理的存储空间。AWS 提供了一个方便的电子表格,可以帮助您根据所需的吞吐量调整集群的大小。此外,AWS 最近推出了 Amazon MSK Serverless,它可以自动预置和扩展计算和存储资源。此外,您只需为流式传输和保留的数据付费。但是,它有一些限制。它只能保留 24 小时的数据,吞吐量上限为入口 200 MBps 和出口 400 MBps。
配置
由于我们的集群仅部署在两个 AZ 中,我们必须调整默认配置以将复制因子设置为 2 并将同步副本设置为 1(见下文)。默认配置假定有 3 个代理,因此除非您对其进行调整,否则当 Amazon MSK 数据生成器尝试发布消息时,您将收到“NOT_ENOUGH_REPLICAS”错误。
auto.create.topics.enable=true
delete.topic.enable=true
default.replication.factor=2
min.insync.replicas=1
num.io.threads=8
num.network.threads=5
num.partitions=1
num.replica.fetchers=2
replica.lag.time.max.ms=30000
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
socket.send.buffer.bytes=102400
unclean.leader.election.enable=true
zookeeper.session.timeout.ms=18000
transaction.state.log.replication.factor=2
transaction.state.log.min.isr=1
transaction.max.timeout.ms=900000
亚马逊 MSK 连接
在 Amazon MSK Connect 上部署 Amazon MSK 数据生成器也很简单,但如果设置不正确(安全组、IAM 角色、身份验证等),可能很难使其正常工作。因此,请确保将日志传输配置到 S3 存储桶,以便您可以解决问题。
配置
下面的 Amazon MSK 数据生成器配置每两秒为“书”、“书店”和“购买”主题生成数据。请注意,“purchase”主题中的“bookstore_id”和“book_id”属性引用“bookstore”和“book”主题中的键。因此,演示应用程序可以“加入”来自相关主题的事件。
connector.class=com.amazonaws.mskdatagen.GeneratorSourceConnector
tasks.max=3
# book
genkp.book.with=#{Internet.uuid}
genv.book.title.with=#{Book.title}
genv.book.genre.with=#{Book.genre}
genv.book.author.with=#{Book.author}
# bookstore
genkp.bookstore.with=#{Internet.uuid}
genv.bookstore.name.with=#{Company.name}
genv.bookstore.city.with=#{Address.city}
genv.bookstore.state.with=#{Address.state}
# purchase
genkp.purchase.with=#{Internet.uuid}
genv.purchase.book_id.matching=book.key
genv.purchase.bookstore_id.matching=bookstore.key
genv.purchase.customer.with=#{Name.username}
genv.purchase.quantity.with=#{number.number_between '1','5'}
genv.purchase.unit_price.with=#{number.number_between '10','75'}
genv.purchase.timestamp.with=#{date.past '10','SECONDS'}
# global
global.throttle.ms=2000
global.history.records.max=1000
下面的自定义工作器配置以 JSON 格式序列化生成的数据,而不向每条记录添加 JSON 模式。我们的演示应用程序没有使用架构注册表,但如果您需要架构管理,您可以使用AWS Glue 架构注册表。
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
堡垒主机
我们在与 Amazon MSK 集群相同的 VPC 中的一个公有子网中启动了一个 Ubuntu EC2 实例。如果您不熟悉启动 EC2 实例,可以在Amazon EC2 Linux 实例入门教程中找到更多信息。
为了读取 Amazon MSK 集群中的数据,您需要安装一个工具,例如kafkacat。这可以通过在实例启动并运行后通过 ssh 运行以下命令来完成:
sudo apt update
sudo apt install kafkacat
配置
确保将“自动分配公共 IP”设置为“启用”并创建一个安全组,只允许端口 22 上的传入流量。同样,Amazon MSK 集群的安全组需要允许端口 9092 和 2181 上的连接来自堡垒主机的安全组。最后,创建一个密钥对并将其分配给 EC2 实例以通过 ssh 启用连接。
结果
一旦 Amazon MSK 集群处于“活动”状态并且 Amazon MSK 数据生成器处于“运行”状态,您应该会在控制面板中看到活动:
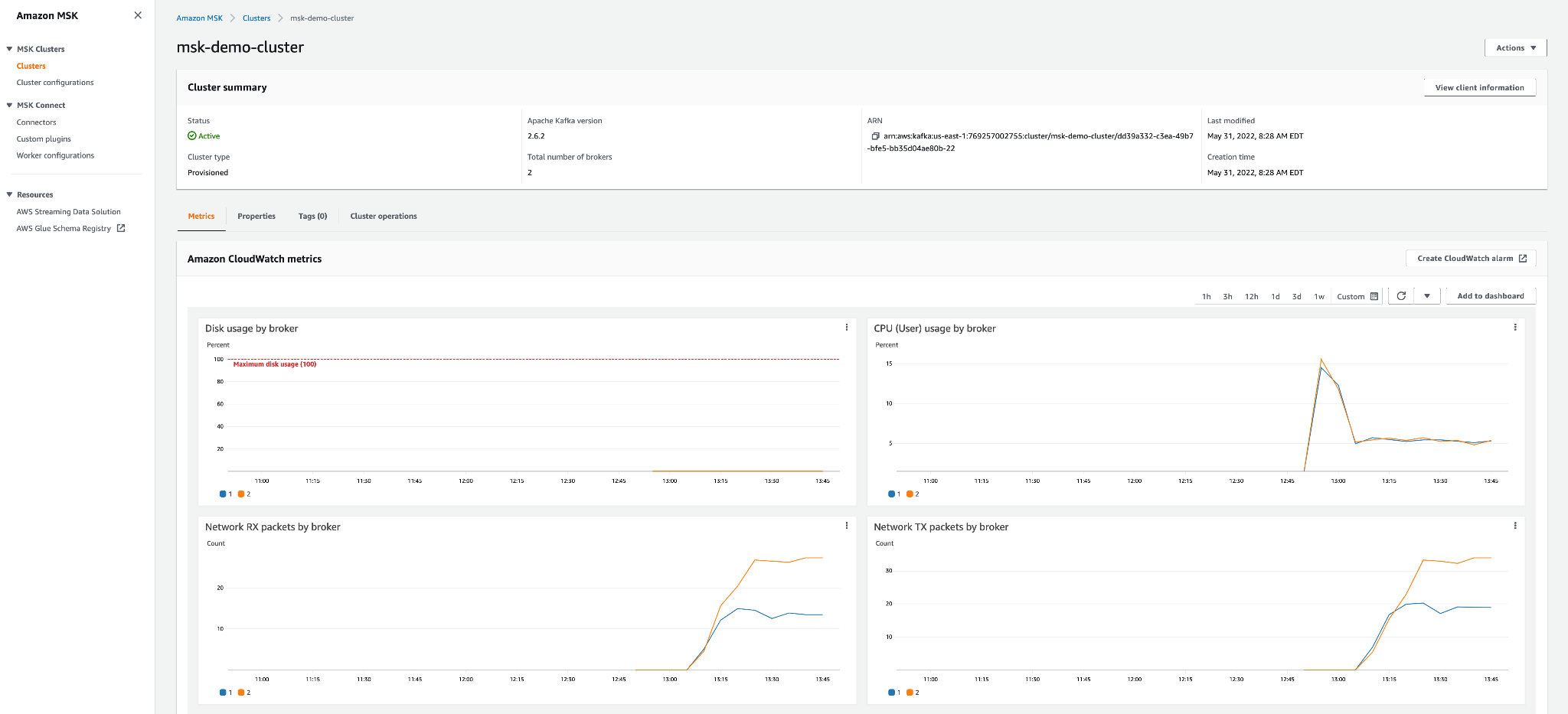
现在让我们连接到堡垒主机以查看正在生成的数据。由于堡垒主机位于公共子网中,我们可以使用 ssh 连接到它。您将需要分配给 EC2 实例的密钥和公共 IP 地址

使用 kafkacat 命令,我们可以连接到 Amazon MSK 集群并在屏幕上打印为三个主题生成的一些数据:
图书

书店

购买

结论
Amazon MSK 和 Amazon MSK Connect 提供完全托管、高度可用的 Apache Kafka 和 Apache Kafka Connect 版本。部署生产就绪型应用程序很容易,并受益于 AWS 平台的安全性、可靠性和可扩展性。此外,现收现付定价模式对大多数用例都很有吸引力。我们认为 Amazon MSK 和 Amazon MSK Connect 最适合以下客户:
- 想要使用 Apache Kafka 和 Apache Kafka Connect 的开源版本的客户
- 可以容忍在最新版本的 Apache Kafka 之后运行几个版本的客户端
如果客户想使用最新版本的 Apache Kafka 或 Confluent 的一些许可功能,那么Confluent Cloud将是一个更好的选择。此外,它还可以部署在 AWS 云上。
在这篇博文中,我们看到在 Amazon MSK 上预置集群以及在 Amazon MSK Connect 上部署数据生成器是多么容易。请继续关注第 2 部分,我们将在 Amazon KDA 上部署 Apache Flink 流应用程序。
原文标题:DATA STREAMING WITH KAFKA AND FLINK ON AWS – PART 1
原文作者:Enrique Lopez de Lara
原文地址:https://blog.pythian.com/data-streaming-with-kafka-and-flink-on-aws-part-1/
