




1. 整体架构
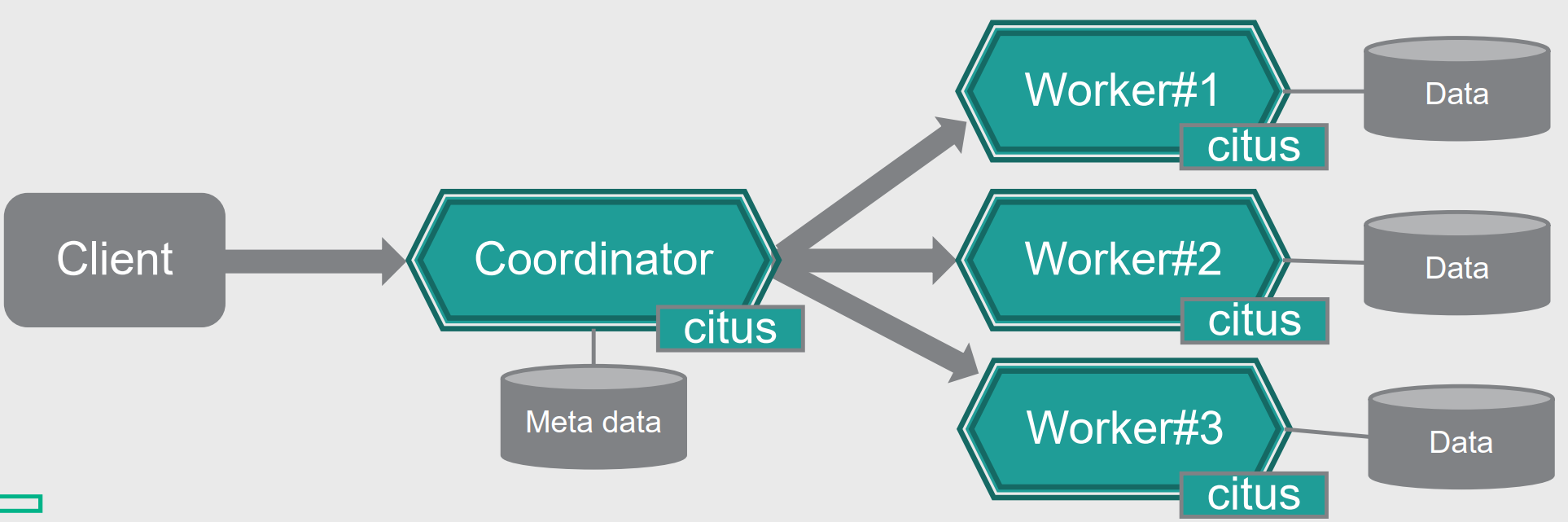

Citus的架构如上图所示,为Share Nothing的分布式架构,包含两种类型的节点:
- Coordinator协调者节点
- 负责接收来自客户端的交互请求,并把请求按照规则转发给对应Worker节点执行;
- 本地维护Metadata元数据,例如Shard分片信息,放置节点信息等;
- Worker工作节点,也叫数据节点
- 负责用户数据表的实际存储
Citus通过Extension的方式扩展了PostgreSQL下面的功能:
- System catalogs:新增分布式元数据表等
- Planner hook:新增"增删改查"操作的分布式查询计划
- Executor hook:新增"增删改查"操作的分布式执行逻辑
- Utility hook:修改Alter Table,Create Index,Vacuum等逻辑支持分布式;
- Transaction & resource handling:支持同时打开更多文件描述符
- Background worker process:新增后台任务进程如:死锁检测,任务跟踪进程等;
- Logical decoding:支持在线数据迁移
2. 支持的表类型
2.1 Distributed Tables 分布式表
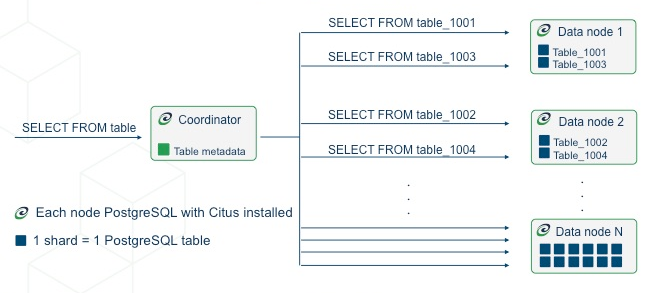

分布式表是Citus中最常见的表,一般建议把大于10GB的业务表创建为分布式表,以支持更大的数据量,以及可扩展的读写性能。
分布式表的数据按照指定分布式列的Hash值打散到多个Worker节点,每个Shard分片都有唯一的shardid编号,每个Shard对应Worker节点上名为tablename_shardid的普通表,该表并与Coordiantor节点上的表具有相同的表模式、索引和约束定义。
在创建分布式表时,选择合适的分布式列非常重要,一般是选择如tenant_id字段将不同租户的数据打散存储在不同节点,下面两种情况的列不建议选择为分布式列:
- Distinct结果非常多列,如时序数据中的timestamp字段,不适合用作分布式列,会导致关联数据没有亲和性;当然太少的列也不行,如果少于Worker节点数则会导致节点负载不均衡;
- 取值分布严重倾斜的列,会导致Worker节点负载不均衡;
分布式表的创建方式如下:
CREATE TABLE github_events
(
event_id bigint,
event_type text,
event_public boolean,
repo_id bigint,
payload jsonb,
repo jsonb,
actor jsonb,
org jsonb,
created_at timestamp
);
SELECT create_distributed_table('github_events', 'repo_id');
创建分布式表不仅可以用于空表,也可用于已经存储有数据的表,Citus会自动按照Sharding规则将表打散到多个Worker节点。
2.1.1 数据Sharding分片
具体步骤如下:
- 针对每行数据,计算分布式列值的Hash值;
- 对Hash值进行Range切割,每一个Range对应一个Shard,切割的边界值保存在Coordinator节点的
pg_dist_shard表中; - 再将Shard映射到不同的Worker/Data节点,映射关系保存在Coordinator节点的
pg_dist_placement表中;
元数据表pg_dist_shard的内容如下:
SELECT * from pg_dist_shard;
logicalrelid | shardid | shardstorage | shardminvalue | shardmaxvalue
---------------+---------+--------------+---------------+---------------
github_events | 102026 | t | 268435456 | 402653183
github_events | 102027 | t | 402653184 | 536870911
github_events | 102028 | t | 536870912 | 671088639
github_events | 102029 | t | 671088640 | 805306367
(4 rows)
其中logicalrelid为用户的分布式表名,shardminvalue和shardmaxvalue为Hash值的Range范围,落入这范围的行归宿对应的shardid
通过联合查询pg_dist_placement和pg_dist_node可以查看shard对应的节点信息:
SELECT
shardid,
node.nodename,
node.nodeport
FROM pg_dist_placement placement
JOIN pg_dist_node node
ON placement.groupid = node.groupid
AND node.noderole = 'primary'::noderole
WHERE shardid = 102027;
┌─────────┬───────────┬──────────┐
│ shardid │ nodename │ nodeport │
├─────────┼───────────┼──────────┤
│ 102027 │ localhost │ 5433 │
└─────────┴───────────┴──────────┘
通过元数据映射的方式,将不同shard放置到不同的worker节点。
2.1.2 分片数量和副本数
分布式表有两个重要的配置参数:
- 分片数量
citus.shard_count- 指定分布式表要被切分成多少个Shard,默认配置为32个Shard;
- 一般是建议配置为CPU总核数的2~4倍;
- 副本数
citus.shard_replication_factor- Citus还支持多副本存储Shard,并提供副本数量的配置参数;
- 在多副本存储情况下,同一个shard的不同副本使用相同的shardid,
pg_dist_placement表中针对每个副本都有一条记录; - 这里不同于PostgreSQL的Stream Replication,是Citus提供的副本能力,当然也可以选择使用Stream Replication而不是Citus的副本功能,将此处的副本数配置为1;
2.1.3 Co-Location 亲和性共存
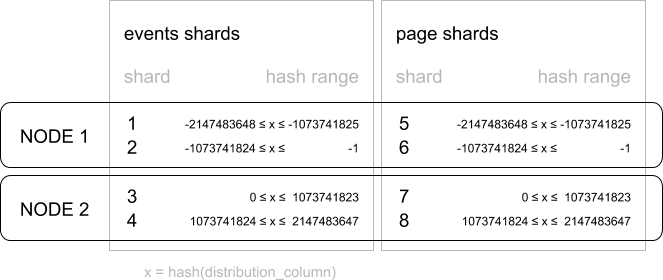
如果不同分布式表所指定的分布式列类型、shard分区数量及副本数量都相同,则这些分布式表都会按照相同的Hash值范围分片,并把相同范围的分片存储在相同的Worker节点上,这样分布式列值相同的行会亲和性的存储在同一个节点。
例如,通过下面方式创建的分布式表存在亲和性关系:
-- these tables are implicitly co-located by using the same
-- distribution column type and shard count with the default
-- co-location group
SELECT create_distributed_table('events', 'some_int_col');
SELECT create_distributed_table('page', 'other_int_col');
events和page两个表在Worker节点的布局示例如图:

创建分布式表时,也可以colocate_with参数主动指定和某个表亲和性共存:
-- distribute stores
SELECT create_distributed_table('stores', 'store_id');
-- add to the same group as stores
SELECT create_distributed_table('orders', 'store_id', colocate_with => 'stores');
SELECT create_distributed_table('products', 'store_id', colocate_with => 'stores');
不指定colocate_with参数时默认为default,和所有具有相同分布式列类型、shard分区数量及副本数量的分布式表亲和性共存。
Coordinator节点通过元数据表pg_dist_colocation维护亲和性共存关系:
SELECT * from pg_dist_colocation;
colocationid | shardcount | replicationfactor | distributioncolumntype | distributioncolumncollation
--------------+------------+-------------------+------------------------+-----------------------------
2 | 32 | 2 | 20 | 0
(1 row)
其中colocationid为co-location组id,其他为该组的属性字段。
通过将同一个租户的不同业务表进行亲和性共存,能带来以下好处:
- 同一租户的相关数据都在同一个节点,查询单个租户时,可以支持完整的SQL能力;
- 支持在同一个包含多条语句的事务中修改co-located相关shards;
- 支持INSERT…SELECT语句
- co-located shards间支持Foreign keys关系;
- 支持分布式outer joins
- Pushdown CTEs
一旦分布式表形成亲和性共存关系后,后续在集群扩容数据重均衡时,Citus也会保证亲和性共存关系,会相关shard一起迁移到新节点。
2.1.4 Append分片方式
除了Hash分片方式外,分布式表还支持Append分片方式,只适用于append only的负载如时序数据场景,新增数据都追加写入到最新一个shard分片,新增分片以轮询的方式创建在不同的Worker节点上,因此实时只有一个Worker节点在写入。
SELECT create_distributed_table('github_events', 'created_at', 'append');
实际上,即使是时序数据场景也很少用Append分片方式,一般都结合PostgreSQL分区表 + Citus Hash分片的方式适用,先按照时间列进行范围分区,再指定设备Id为分片列进行Hash打散。
2.2 Reference Tables 引用表
引用表不会进行Sharding分片,所有数据都在一个Shard内,并在所有Worker节点都复制存储一份,Citus通过2PC保证多个副本的强一致性。
引用表一般用于和具体租户无关的字典类的小表,这类表需要经常和其他业务表进行Join查询,因为所有Worker节点都可以本地访问到引用表数据,可以避免在Join查询时跨节点去获取数据。
引用表的创建方式如下:
-- a reference table
CREATE TABLE states (
code char(2) PRIMARY KEY,
full_name text NOT NULL,
general_sales_tax numeric(4,3)
);
-- distribute it to all workers
SELECT create_reference_table('states');
创建引用表时,不需要指定分布式列。
2.3 Local Tables 本地表
指存储在Coordinator节点本地的表,一般仅限于不需要和其他表进行Join查询的表,如用户身份认证的表,Citus自身的元数据表也可以认为是本地表。
3. 参考
http://docs.citusdata.com/en/v10.0/get_started/concepts.html
http://docs.citusdata.com/en/v10.0/develop/reference_ddl.html
http://docs.citusdata.com/en/v10.0/sharding/data_modeling.html
