




我们通过下面这张图先来看下一条SELECT语句在mysql里的执行流程
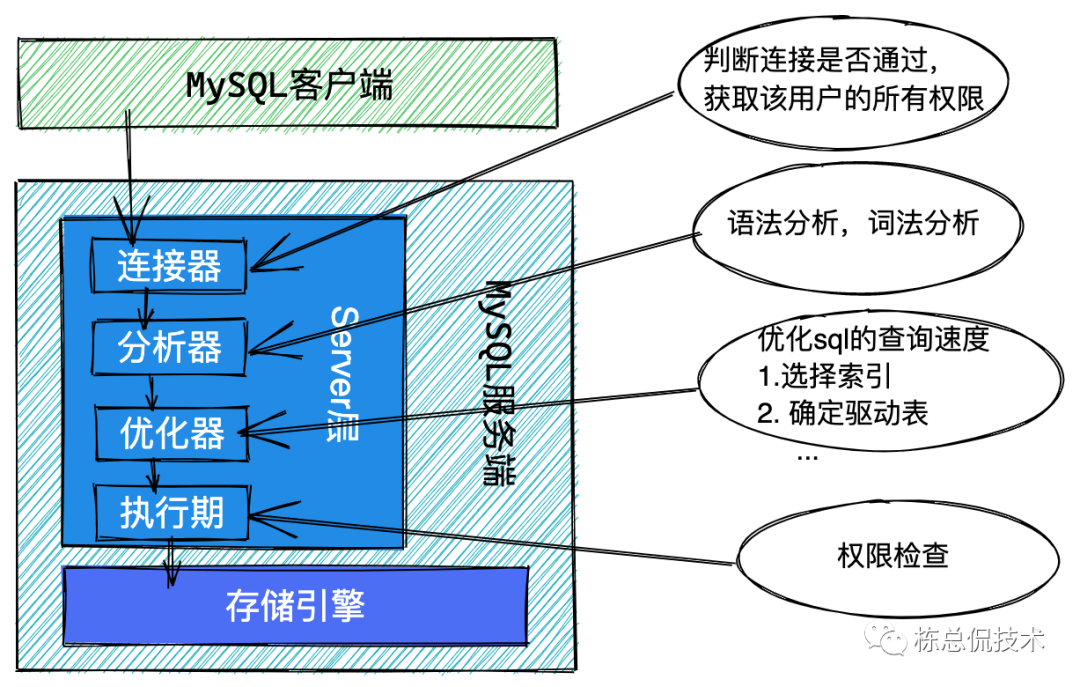
其中在连接器通过后会直接去缓存中看看,之前是否已经执行过该条语句,有则直接返回。(缓存失效是很频繁的,一条更新操作会把该表所有的缓存清空。MySQL8.0开始已经直接把查询缓存去掉了)
我们再通过下面一张图来看下一条UPDATE语句的执行过程,例如 update t set n= n+2 where id = 10;
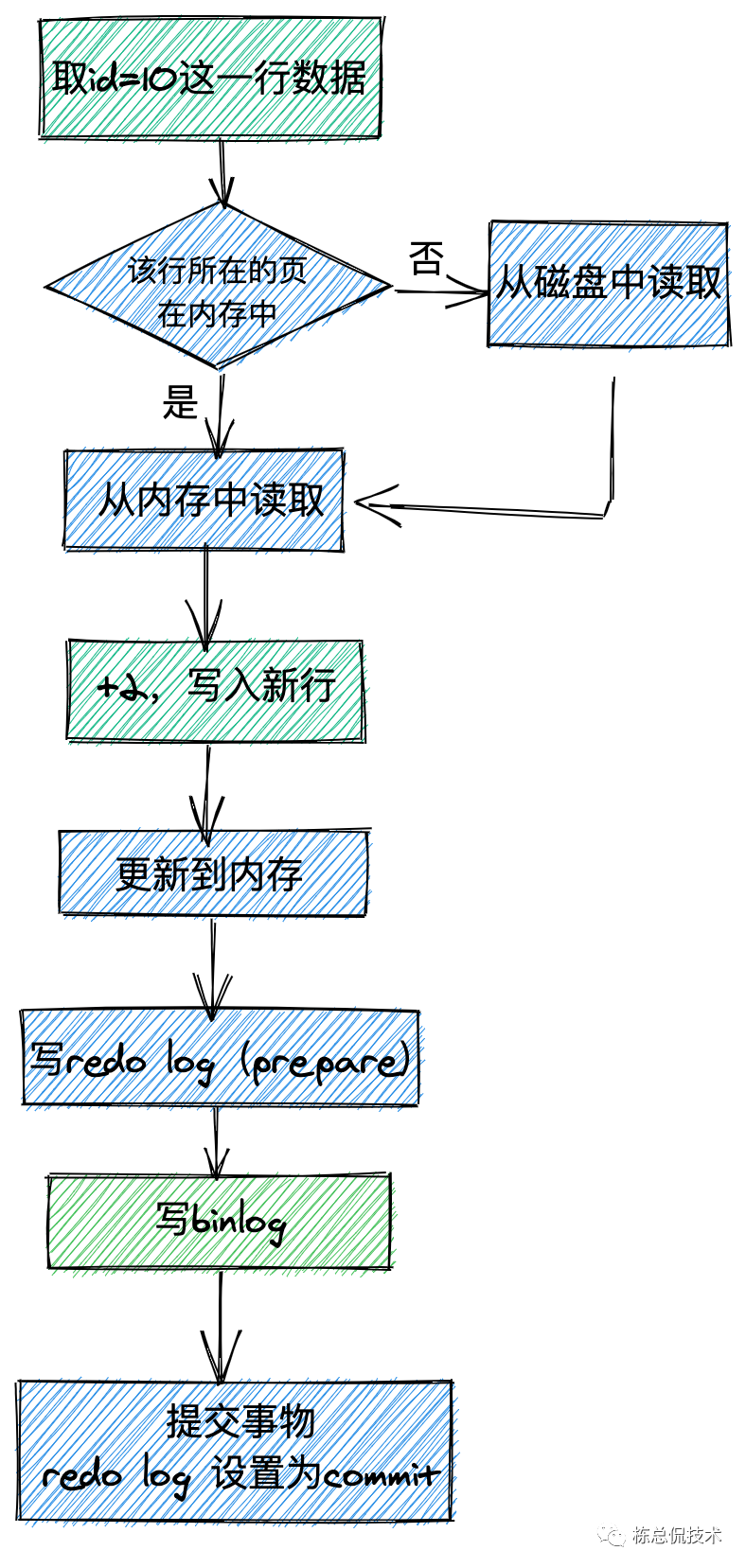
在执行update操作时,修改结果更新到内存后,会在redo log添加一条日志:在某个数据页上把id=10这行记录的n修改为3(假设最初为1),我们称之为物理日志。这就是 MySQL 里说到的WAL技术,WAL的全称是Write-Ahead Logging,即先写日志,再写磁盘。
在事务提交后,将此次事务中增加的redo log状态都设置为commit状态。之后数据写入磁盘中时,也会把commit状态的redo log 写入磁盘。
mysql的insert、update操作不会马上把数据写入磁盘,而是一段时间或者一定的量写入磁盘,减少IO次数。WAL技术可以保证在数据库发生宕机后可通过redo log 将没有写入磁盘的数据恢复。这个能力称为 crash-safe。
图中蓝色为在innoDB引擎中执行的,绿色在执行器中执行的。
既然有redo log了 为什么还存在binlog?
redo log是innoDB引擎所特有的。早期的mysql不是使用innoDB引擎的(自带的 MyISAM),所以还是得通过server层的binlog来归档数据(只是归档作用,没有crash-safe能力)。
binlog记录的是执行语句的原始逻辑,例如把id=10这行记录的n值增加2(与redo log的物理日志不同)
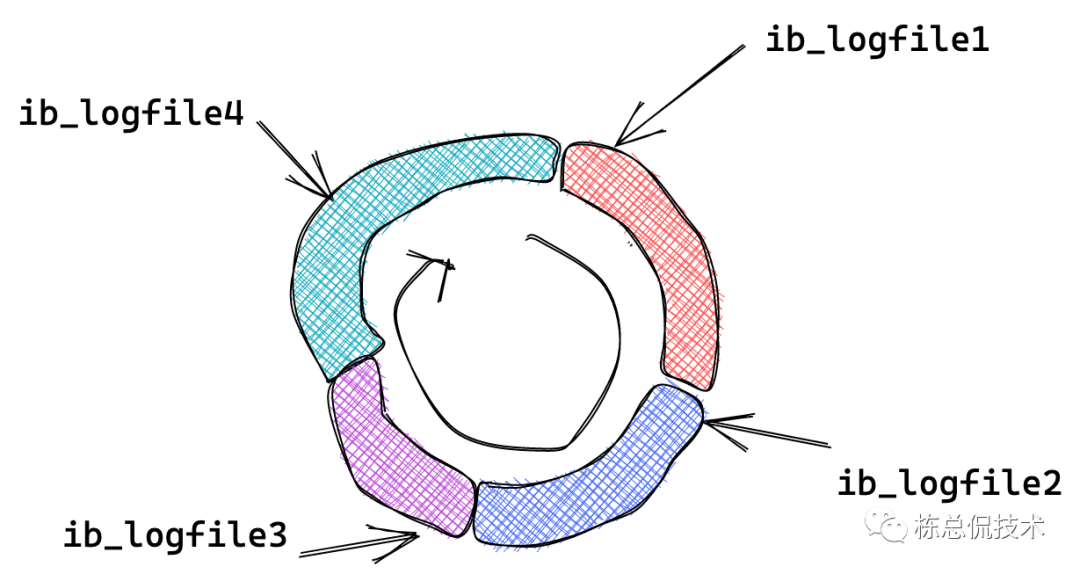
redo log的大小是固定的,当达到最大时,会覆盖最远的日志,可以理解为一个环形,见下图。而binlog是追加的方式写入的,可配置binlog文件的大小,当超过时,日志会记录到新的文件上。
由于特性3 redo log无法用于数据回滚/数据恢复等操作。如果误删数据等场景需要恢复数据,只能通过binlog实现。
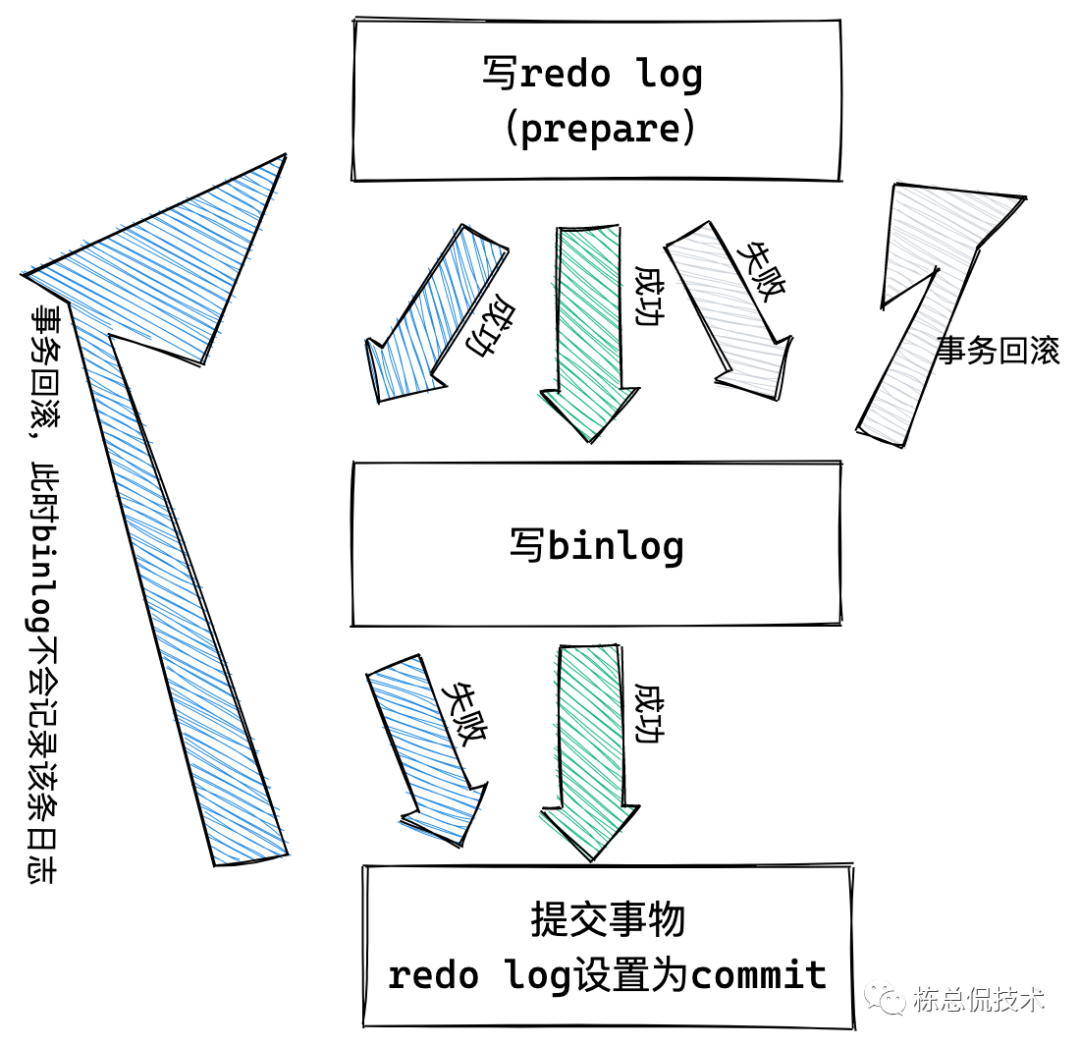
在UPDATE语句的执行过程中我们看到最后三步有点“绕”,redo log的写入有两步,分别是:prepare 和 commit,这就是"两阶段提交"。两阶段提交保证了两份日志中的数据统一。下图说明了两阶段提交的过程:
binlog如何恢复数据?
假设某位程序员在2号中午12点30分解决线上问题,由于到了饭点又赶着去干饭,误执行了某条sql,把一行数据删了。需要恢复数据怎样做呢?找到最近一次数据库的全量备份库(运气好就是昨晚备份的,运气差上周甚至上月备份的)从该备份库一条一条的执行binlog日志中的sql,直到误删数据前的那一条,即恢复了误删的那条数据。
正是两阶段提交保证了两份日志中的数据统一,从而保证了就算服务crash了也能保证恢复数据的完整性。
通过以上内容,大家应该对一条sql在mysql中执行的步骤比较清晰了。下节我将会带来sql在优化器中是如何做优化如何选择索引的,同时通过优化器选择索引的方式我们将如何正确的去创建索引。
这算是本人“职业生涯”第一次以文章的形式记录自己的积累,希望能够给您带来帮助,也借此希望后续不论工作多忙,自己也能够做到每周一到两篇的输出,后续也会带来redis、kafka、go语言、k8s等等相关的学习系列文章。就算哪天我在程序员这条道路上走不下去了,转到其他行业了,回头看一下,我这么些年还是留下了些东西的。
