




索引就相当于一本书的目录,便于快速找到具体内容。大家工作中出现慢查询语句了,第一反应就是给某张表的某个字段、某些字段建个索引。那你知道索引是如何工作的吗?
首先我们要知道,索引是在存储引擎内实现的,所以MySQL使用不同的存储引擎对应索引的实现是不同的。
目前mysql使用最广泛的存储引擎是innoDB存储引擎,我们在讲innoDB存储引擎是如何实现索引前,先大概了解下几种常见的索引模型,了解下不同模型的优劣点。
哈希表
哈希表是一种key-value键值对的存储数据结构。当数据量比较大时,不可避免的出现多个key哈希的结果是相同的,这个时候会拉出一个链表来存储多个value。下图就是哈希表的存储结构:
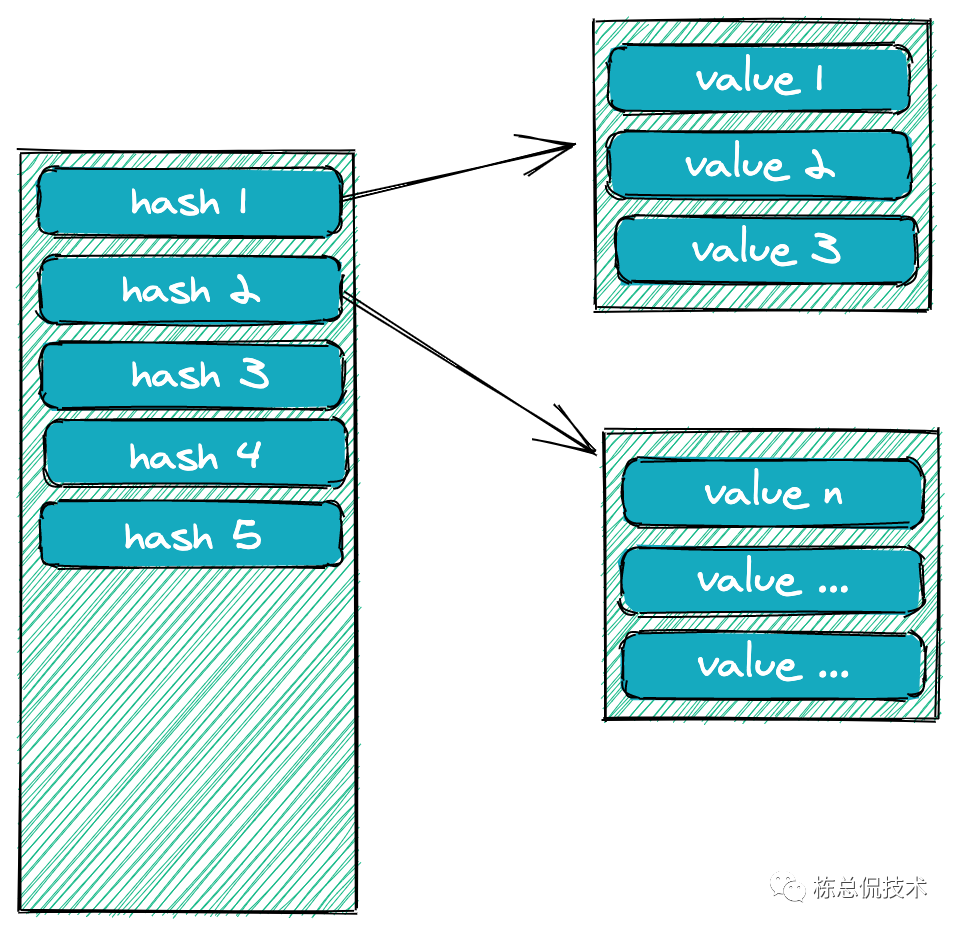
当查找某个key的值时,先找到对应的key再找对应链表里的该key所对应的值。哈希表模型当进行等值查询的时候是很快的,但是进行范围查询会很慢。 例如查找 key在[a,b]区间内的值时是要进行全表扫描,必定的查找的速度会很慢。
有序数组
顾名思义按照顺序(递增或者递减)存储。有序数组在等值查询或者范围查询都比较快,但是有序数组在进行增删改时就非常繁琐。无论增删改都得挪动其他的元素,这样效率就非常低,所以有序数组只适合递增或者递减增加元素,或者完全静态的数据存储场景。

二叉搜索树
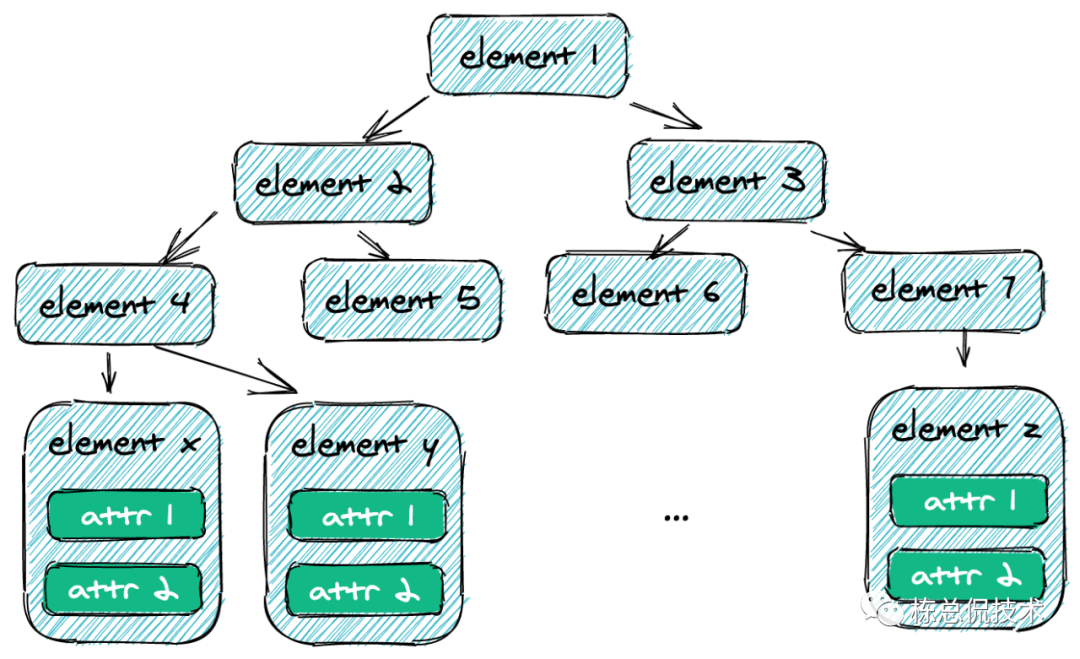
二叉树的特点是左子节点的值都小于父节点,右子节点的值都大于父节点。如下图如果需要找到elementx,则需要经过1->2->4->elementx,时间复杂度是 O(log(N))。
除了以上讲解到的数据结构,还有N叉树、跳表、LSM树等结构,大家可以了解下。
B+树
在innoDB中,每一个索引都是B+树,索引存储的值为该表的主键,表的完整结构是根据主键的顺序以索引的形式存放的。如下图,我们假设有一张简单的学生信息表,包含id (自增主键)、姓名(索引)、性别、家庭住址这些信息。
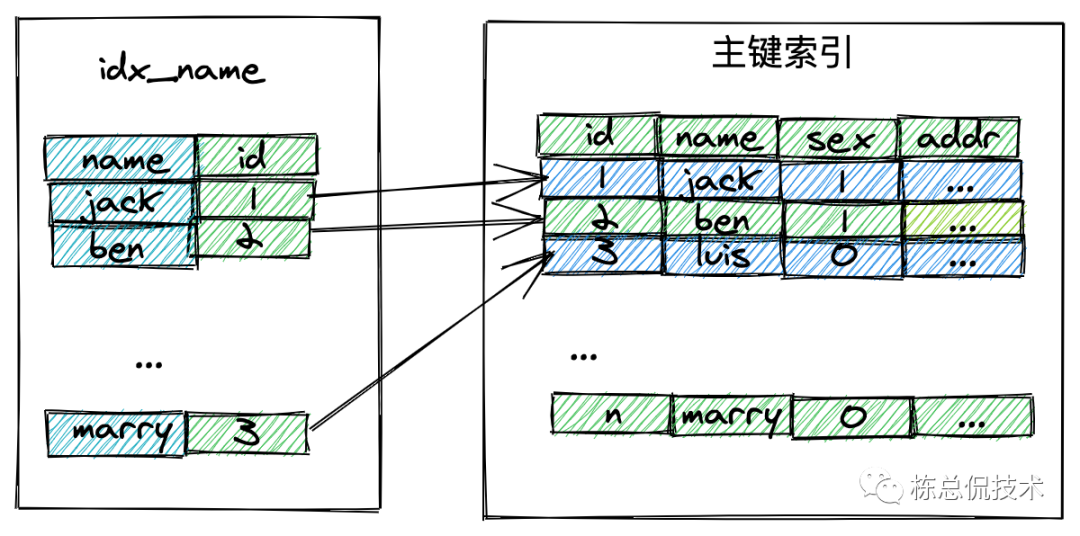
通过上面这张图,我们可以看下通过主键索引和一般索引的执行过程。
主键索引,从主键索引表查询一次就可以得到需要的结果:
select * from student where id =1;
普通索引,先从索引表获取jack这个学生的id,然后再到主键表通过id查找所要的信息再返回:
select * from student name =' jack'
从以上结构我们可以得出以下优化结论:
尽量使用主键查询,提升查询效率,减少回表次数。
主键索引要尽可能的小那么普通索引的叶子节点占用的空间比较小(建议使用自增id)
尽量使用覆盖索引也可以减少回表次数,例如:
select id from student where name =' jack';
我们如何来利用减少回表次数来提升搜索效率呢?
通过建立联合索引来实现覆盖查询
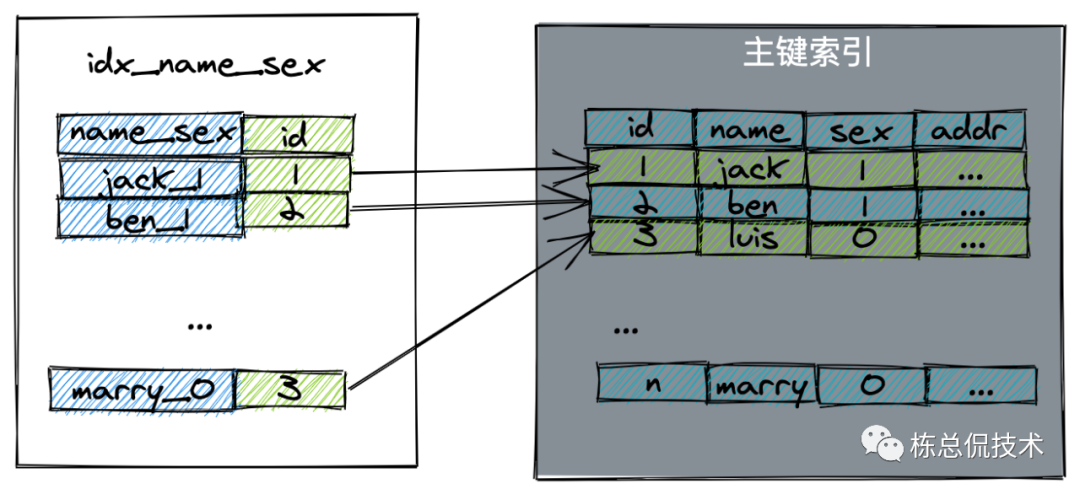
假设有个高频次场景需要通过姓名查找该学生的id和性别。如果我们建立的是name和sex联合索引(idx_name_sex)。下面这条语句不需要回表,在普通索引表就包含所有需要的查询信息。
select id,sex from student where name =' jack';
当然维护索引是需要付出代价的,多维护一个字段,对于索引变更的可能性是指数倍增加的。所以是否需要通过建立联合索引来实现覆盖查询,需要三思而后行。
最左前缀原则
如果已经存在name和sex联合索引(idx_name_sex)了,就没有存在单独的name索引的必要性了。
如果需要查找jack这个用户的信息,则根据联合索引的前缀匹配原则,会在idx_name_sex索引上匹配jack这个用户,直到找到第一个不是jack的行则停止扫描普通索引表。
索引下推原则
索引下推原则是在有回表操作的情况下尽可能的减少回表的行数。
如果一个学校有多个叫jack的学生,且有男生女生。我们要找一个叫jack的男性学生,该学生家里住光谷。
相比较建立idx_name单索引,idx_name_sex联合索引回表的次数要少一些。首先会根据联合索引在索引表找出所有的 name='jack' and sex=1的所有学生,然后再回到主键表匹配addr是否等于光谷。
优化器
在上一节我们在讲SQL语句的执行过程时谈到了优化器,那如果一张表有多个字段的索引,优化器是怎么选择索引来查询的呢?
判断使用哪个索引扫描的行数更少,优化器就选择该索引。扫描行数是影响执行的因素之一,扫描行数直接决定了磁盘io的次数以及cpu的消耗。当然不仅仅是扫描行数,还会考虑是否使用临时表、是否排序等因素。
那么MySQL是怎么判断扫描的行数的呢?
预估法,一条语句在执行前当然没法指定的扫描行数是多少。通过explain可以看到mysql预估该条语句扫描的行数,以及使用的索引。

通过采样统计预估后,InnoDB 默认会选择 N 个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。
当然mysql可能会选错了索引。这个时候,就得反思下是否是因为自己创建的所以不合理(多个单个索引替换成聚合索引),自己的sql语句是否可以进一步优化到通过主键索引查找。也可使用force index来强制使用某个索引进行查找:
select * from user force index(idx_name) where ....
在这一节我们对索引的原理和使用有了一定的了解,下一节我们会通过分析一些具体的场景和例子来说明怎样做到对查询进行优化的。码字不易,有讲解错误的地方欢迎读者主动拍砖。
历史回顾:
MySQL系列1 - sql语句的执行过程以及redo log和binlog扮演的角色

