




我们还是从一个例子开始,有两张表t1、t2,建表语句如下:
CREATE TABLE `t1` (`id` int(11) NOT NULL,`c1` int(11) DEFAULT NULL,`c2` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_c1` (`c1`)) ENGINE=InnoDB;CREATE TABLE `t2` (`id` int(11) NOT NULL,`c1` int(11) DEFAULT NULL,`c2` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_c1` (`c1`)) ENGINE=InnoDB;
给t1插入100条数据,t2插入10000条数据
for i:=1;i<=100;i++ {insert into t1 values(i, i, i);}for i:=1;i<=10000;i++ {insert into t2 values(i, i, i);}
Simple Nested-Loop Join
有一条查询语句如下:
select * from t1 straight_join t2 on (t1.c1=t2.c1);
为避免mysql的优化器作出选择驱动表的优化,影响我们分析该语句的执行过程,我们这里使用straight_join来指定驱动表为t1。我们通过如下图来看这条sql是如何执行的:
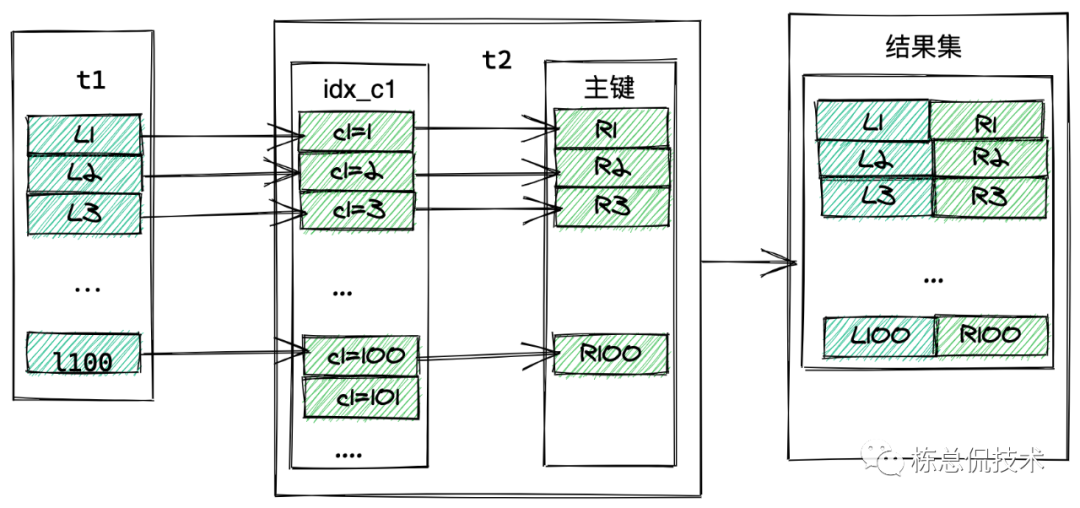
从t1表取出一行数据L
取出L的c1字段到表t2的索引表找到c1
根据从t2表取出的行到t2主键表取这一行数据
t1表的行和t2表的行组合成一行存到结果集
重复1,2,3,直到t1表循环结束
根据以上的步骤,我们可以分析得出t1表需要做全表扫描(100行),每一行L都要到t2表通过树索引查找一行。所以一共要扫描200行。
在被驱动表使用索引的情况下,我们选择小表作为驱动表性能更好。
如果表t2的c1字段并没有创建索引,将会怎样呢?
我们可以推测出,在第2步做一次t2表的扫描,那么这条语句扫描的行数是100*10000=100万条。这样这种算法就效率太低了。
Simple Nested-Loop Join
当被驱动表没有命中索引时,join语句的执行过程是这样的:
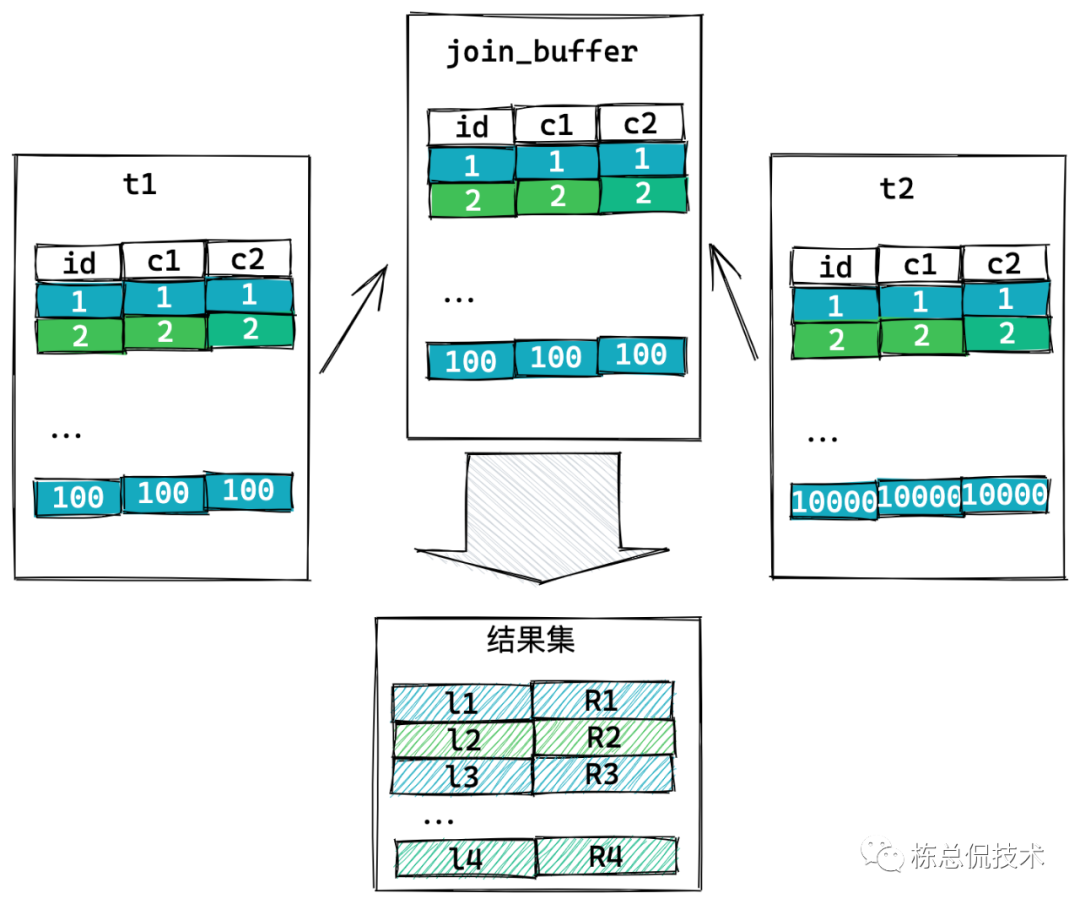
把t1表需要返回的结果(这里是*,所以存的是整行)存入join_buffer中。
扫描t2,把满足join条件的行和join_buffer中的t1的行存入结果集中。
这个时候对t1和t2都完成了一次全表扫描,总共扫描的行数为10000+100行。这个时候无论哪张表作为驱动表都是一样的。
join_buffer的空间大小是由join_buffer_size决定的,有可能join_buffer放不下t1表,这种情况又是怎么处理的呢?
把t1表 n 行需要返回的结果(这里是*,所以存的是整行)存入join_buffer中。
扫描t2,把满足join条件的行和join_buffer中的t1的行存入结果集
清空join_buffer
把t1表 n+1到2n的行放入到join_buffer中,再扫描t2表把满足join条件的行和join_buffer中的t1的行存入结果集。
重复前面的步骤。
这样t2表会全表扫描多次。为了减少t2表全表扫描的次数,我们一样的也要用小表作为驱动表。怎样定义小表呢?
查询驱动表的字段尽可能少,把*替换成需要返回的字段
扫描的行尽可能小的表,例如如下两条语句,sql2的效率会更高,虽然表t2更大,但是条件限制t2满足条件的表只有10行。
// sql1select * from t1 straight_join t2 on (t1.c2=t2.c2) where t2.id<10;//sql2select * from t2 straight_join t1 on (t1.c2=t2.c2) where t2.id<10;
所以,小表的定义是按照限定条件过滤后总占空间更小的表。
留个思考题,当被驱动表是一张非常大的冷表,且没有命中索引时。我们该如何做优化呢?给被驱动表的字段加上索引吗?在下一张,结合着实际场景我将给您带来优化的方法,您也不妨先思考下。
往期回顾:
MySQL系列1 - sql语句的执行过程以及redo log和binlog扮演的角色
MySQL系列4 - 你了解 order by 的工作原理吗?

