




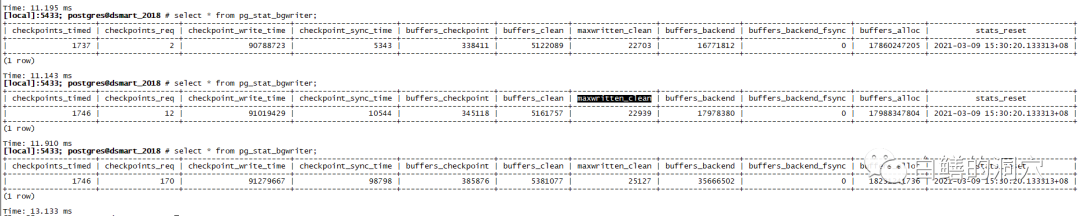
checkpoints_timed:计划检查点的发生次数,这种检查点是checkpoint_timeout参数规定的超时达到后系统启动的checkpoint;
checkpoints_req:非计划检查点的次数。有些朋友把这个指标定义为手工检查点的次数,实际上这是不准确的。手工检查点是因为执行某些命令触发的检查点,这个指标包含这类检查点,除此之外,还有一类xlog checkpoint检查点也属于这类检查点。xlog ckpt是指当某些数据库预定的阈值达到时启动的检查点,比如WAL已经超出了max_wal_size或者checkpoint_segments,也会触发xlog ckpt;
checkpoint_write_time:ckpt写入的总时长;
checkpoint_sync_time:ckpt同步文件的总时长;
buffers_checkpoint:由checkpointer清理的脏块;
buffers_clean:由bgwriter清理的脏块数量;
buffers_backend:由backend清理的脏块数量;
maxwritten_clean:bgwriter清理脏块的时候达到bgwriter_lru_maxpages后终止写入批处理的次数,为了防止一次批量写入太大影响数据块IO性能,bgwriter每次都有写入的限制。不过这个参数的缺省值100太小,对于负载较高的数据库,需要加大;
buffers_backend_fsync:backend被迫自己调用fsync来同步数据的计数,如果这个计数器不为零,说明当时的fsync队列已经满了,存储子系统肯定出现了性能问题;
stats_reset:上一次RESET这些统计值的时间。

bgwriter_delay:bgwriter两个任务之间的休眠时间的初始值为200毫秒;
bgwriter_lru_maxpages:每次bgwriter任务写buffer的最大page数,一旦达到这个数量,bgwriter就结束任务开始休息,也就是说bgwriter休眠200毫秒,然后写入几十毫秒就又开始了休息,这比欧洲人民的工作时间都短得多,怪不得干不了多少活呢;
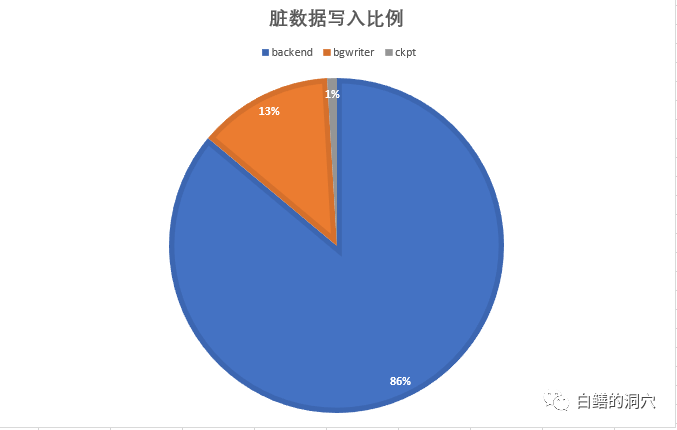
bgwriter_lru_multiplier:这个参数用于评估下一次写任务的数量,其依据是这段时间内新申请的buffer数量的倍数,如果这个参数乘以新增加buffer分配的数量后小于bgwriter_lru_maxpages,那么有可能下一个写任务的数量会小于预期的写入量。将这个参数调大,会增加bgwriter回写脏块的数量,不过会增加写IO压力,将这个参数调小,可以降低写IO压力,不过可能导致backend写脏块的比例增加。不同负载的系统中,这个参数的值应该是需要做调整的,而不是只是用缺省值2。如果你发现你的系统的写IO压力还不大,但是 bgwriter写比例偏低,backend写比例偏高,那么尝试加大这个参数还是有效的。
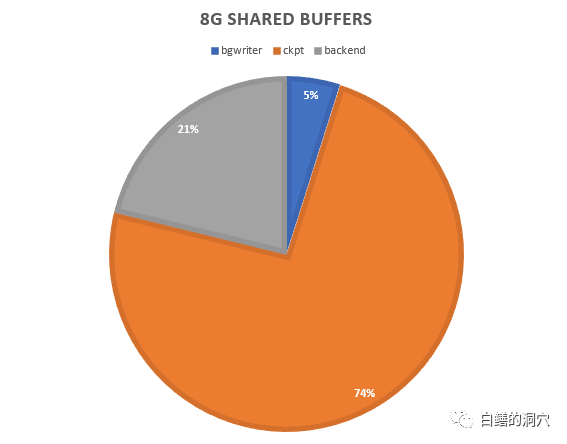
老白在上面的那个系统中,把bgwriter_delay调整到最低(10),bgwrite_lru_maxpages调整到3000,bgwriter_lru_multiplier调整为0,然后再跑一下压测,看到的三种脏块回写的比例有了明显的变化。
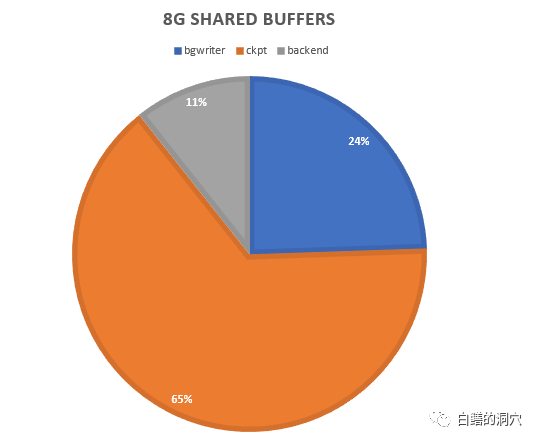
同时整个数据库的TPMC也从63万提高到70万,居然提升了10%。看样子PG数据库的参数,不认真调整调整,整体性能还是发挥不出来啊。
PG的动态性能视图并没有Oracle那么丰富,不过实际上如果认真去看,还是能看到很多十分有价值的信息的。从pg_stat_bgwriter这一行数据里我们居然能看出这么多门道来,是不是感觉有点意外。学习PG数据库,只要认真的去研究,你会有更多的发现。
