




本文作为Data Science Blogathon的一部分发表。
介绍
早在2000年,人们就习惯从当地的超市购买食品杂货。然而,在过去的20年中,一些在线电子商务商店已经推出。因此,你可以在家里舒适地访问在线电子商务商店,而不是去实体商店。过去在实体店购物的客户随后开始从此类电子商务网站购买多种产品。此外,2020年,新冠肺炎严重影响了实体超市的销售。这使得电子商务需求激增,自2020年以来,越来越多的客户开始从此类在线商店购物。参见此处麦肯锡的详细报告摘要。
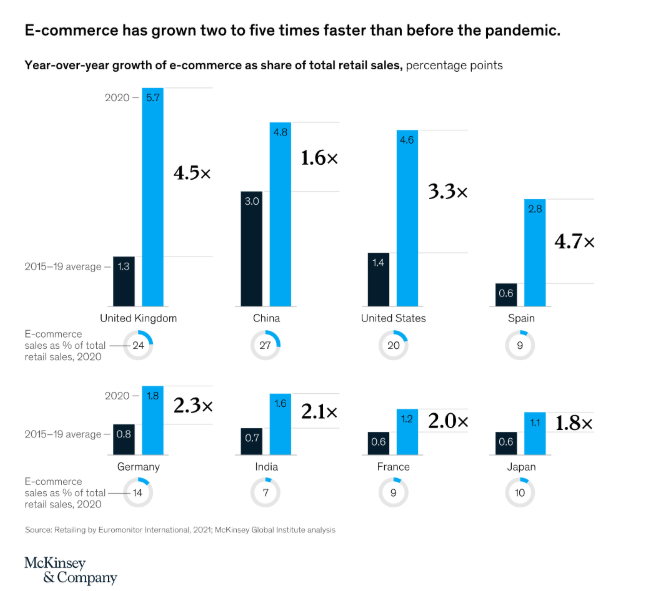
来源:https://www.mckinsey.com/~/media/mckinsey/featured%20insights/future%20of%20organizations/the%20future%20of%20work%20after%20covid%2019/svgz-mgi-covid-fow-ex2.svgz
从牙刷到汽车,许多产品都可以在这样的电子商务商店买到。如果你想买东西,只需在互联网上搜索,至少会有一个电子商务网站提供该产品。因此,近年来推出了许多新的电子商务参与者(这已成为一个竞争非常激烈的领域)。在这样一个竞争激烈的环境中,电子商务商店识别客户偏好并保持客户对其网站购物的兴趣是至关重要的。这就是为什么推荐系统有帮助。一个简单的例子是,如果你购买面包,你可能会购买黄油或牛奶。本文将展示如何为Bigbarket构建推荐系统。
推荐系统的重要性
Netflix:根据麦肯锡最近的一项研究,Netflix使用个性化推荐,它负责80%的流媒体内容。这使得Netflix在一年内赚了10亿美元。Netflix并没有在营销上花费太多,而是在提高客户保留率的建议上。
Amazon:同样,亚马逊网站35%的销售额来自个性化推荐。因此,即使是亚马逊也没有在营销上花费太多。然而,它仍然能够通过个性化推荐留住客户。
上述信息的来源。
推荐系统类型
基于人气:推荐最受欢迎或最畅销的产品。E、 g.Youtube上的趋势视频。
优势:
-
我们只需要产品信息。我们不需要客户偏好数据。
-
我们可以使用这种方法解决冷启动问题。
缺点:建议对所有客户都是类似的,并且不是个性化的。
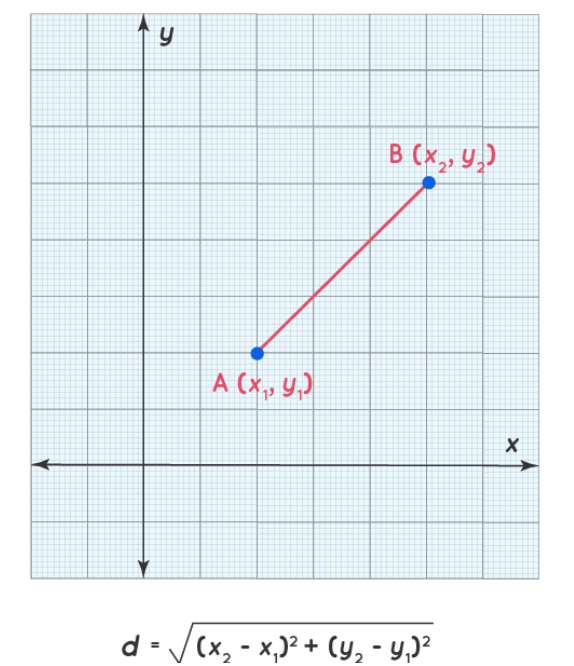
基于内容:基于产品之间的相似性。首先,我们必须创建一个表示所有产品特征的向量。然后,我们使用以下方法计算这些向量之间的相似度:
1.欧几里得距离
2.曼哈顿距离
3.雅卡距离
4.余弦距离(或余弦相似性——我们将在本文中使用此度量)
例如,如果一组用户喜欢成龙的动作电影,该算法可以推荐具有以下特征的电影。
-
有动作类型的
-
有成龙出演。
优点:快速实施
缺点:
-
对于一组客户,建议是类似的。
-
它们基于内容稍微个性化。
基于协作:基于用户之间的相似性。如果有2个用户。
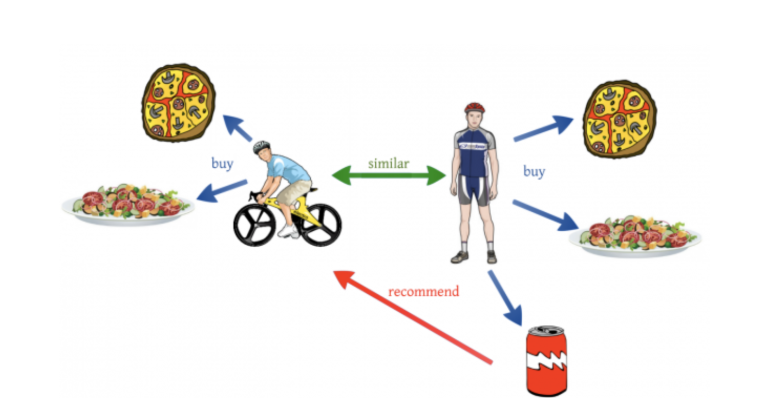
来源:https://miro.medium.com/max/1400/1*6_NlX6CJYhtxzRM-t6ywkQ.png
在上图中,有两个用户具有相似的口味偏好。他们两人都喜欢馅饼和蛋白质沙拉,看起来都是健身爱好者,所以他们很相似。现在,右边的用户喜欢一罐能量饮料,所以我们向左边的用户推荐相同的能量饮料。
优点:它根据每个用户的历史偏好为他们提供个性化推荐。
缺点:该算法需要大量的历史数据来训练,并且模型的精度随着数据的增加而增加。
Hybrid:在这里,我们将以上三种推荐系统结合起来。
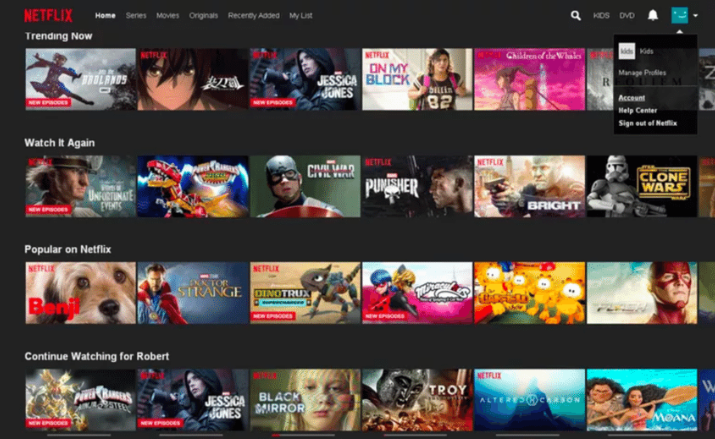
例如,Netflix主页有几个条带,用于向其用户推荐内容。
-
它有条像
-
现在趋势
-
在Netflix上流行
-
再看一遍
-
订阅者的个性化推荐
什么是Bigbasket?
Bigbarket是印度最大的在线杂货店之一。它于2011年推出,几家竞争对手对其市场份额提出了挑战。然而,它仍然可以保持其在市场中的公平份额。
了解推荐系统的数据
我们将使用Kaggle的公开数据集。可以从这里下载
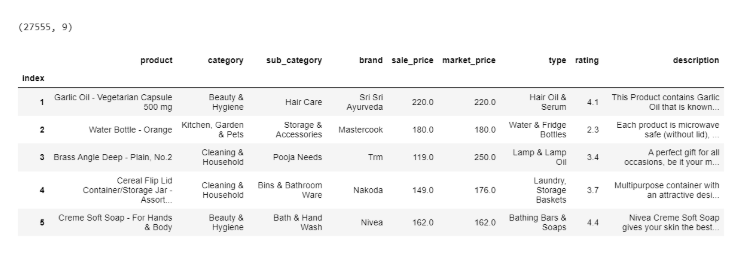
关于这个文件。此数据集包含以下10列:
1.索引–序列号
2.产品–产品名称(或名称)
3.类别–产品类别
4.sub_category–产品的子类别
5.品牌–产品的品牌
6.sale_price–产品在现场销售的价格
7.market_price–产品的市场价格
8.类型–产品所属的类型
9.评级–客户对产品的总评级(五分之一)
10.描述–产品描述
导入相关库
Python代码:
#Basic Libraries
import numpy as np
import pandas as pd
#Visualization Libraries
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
#Text Handling Libraries
import re
from sklearn.feature_extraction.text CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
EDA(探索性数据分析)和数据清理
“没有粘土我就做不成砖。”―亚瑟·柯南·道尔。
我们需要数据来建立推荐系统模型。因此,EDA是至关重要的,因为它允许我们理解数据。大约70-80%的时间用于此步骤。数据可能存在几个问题。我们需要花时间在这里,了解数据。
检查丢失的数据:如果数据为空或丢失,我们不能将其用于数据分析。那么,让我们看看数据分布。
缺失计数:
print('Null Data Count In Each Column')
print('-'*30)
print(df.isnull().sum())
print('-'*30)
print('Null Data % In Each Column')
print('-'*30)
for col in df.columns:
null_count = df[col].isnull().sum()
total_count = df.shape[0]
print("{} : {:.2f}".format(col,null_count/total_count * 100))
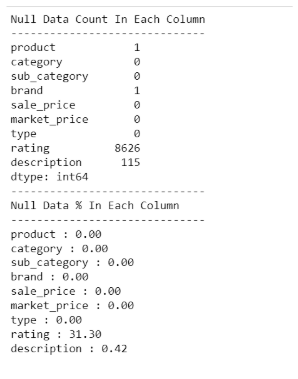
EDA的调查结果:
-
有一种产品没有名字。
-
有一种产品没有品牌。
-
115个产品没有说明。
-
8626种产品没有评级。
上述功能对于构建推荐系统非常重要。因此,我们将从包含缺失值的数据中删除行。
Python代码:
df = df.dropna()
print(df.shape)
输出:
(18840, 9)
即使在删除空值后,我们仍有18840条记录的良好数据大小。
了解列的数据类型
df.dtypes
输出:
product object
category object
sub_category object
brand object
sale_price float64
market_price float64
type object
rating float64
description object
此步骤的结果:
特性sale_price、market_prise和rating是数字的(使用float64表示)。其余的都是字符串特征(表示为对象)。
推荐系统中的单变量分析
在这里,我们将了解几个列的数据分布。查看类别列分布
counts = df['category'].value_counts()
count_percentage = df['category'].value_counts(1)*100
counts_df = pd.DataFrame({'Category':counts.index,'Counts':counts.values,'Percent':np.round(count_percentage.values,2)})
display(counts_df)
px.bar(data_frame=counts_df,
x='Category',
y='Counts',
color='Counts',
color_continuous_scale='blues',
text_auto=True,
title=f'Count of Items in Each Category')
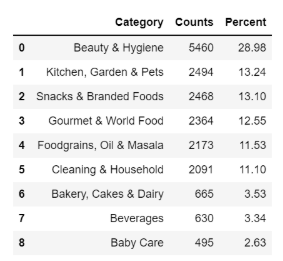
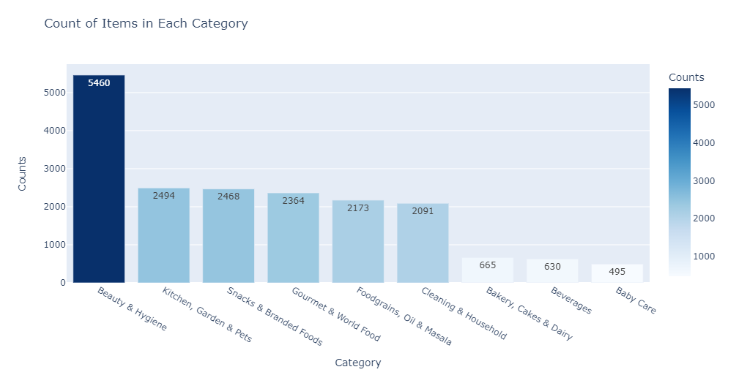
调查结果:
-
美容和卫生共有5460种产品。它占总产品组合的28.98%。
-
其次,最好的类别是厨房、花园和宠物,共有2494种产品。它占总产品组合的13.24%。
-
婴儿护理的产品数量最低,为495种。它占总产品组合的2.63%。
关于sub_category列分布的研究
counts = df['sub_category'].value_counts()
count_percentage = df['sub_category'].value_counts(1)*100
counts_df = pd.DataFrame({'sub_category':counts.index,'Counts':counts.values,'Percent':np.round(count_percentage.values,2)})
print('unique sub_category values',df['sub_category'].nunique())
print('Top 10 sub_category')
display(counts_df.head(10))
print('Bottom 10 sub_category')
display(counts_df.tail(10))
px.bar(data_frame=counts_df[:10],
x='sub_category',
y='Counts',
color='Counts',
color_continuous_scale='blues',
text_auto=True,
title=f'Top 10 Bought Sub_Categories')
px.bar(data_frame=counts_df[-10:],
x='sub_category',
y='Counts',
color='Counts',
color_continuous_scale='blues',
text_auto=True,
title=f'Bottom 10 Bought Sub_Categories')
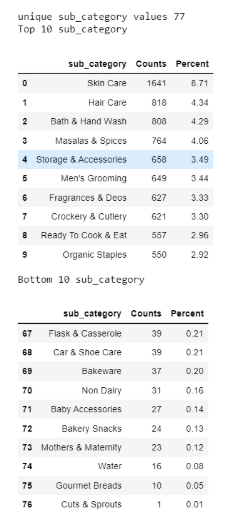
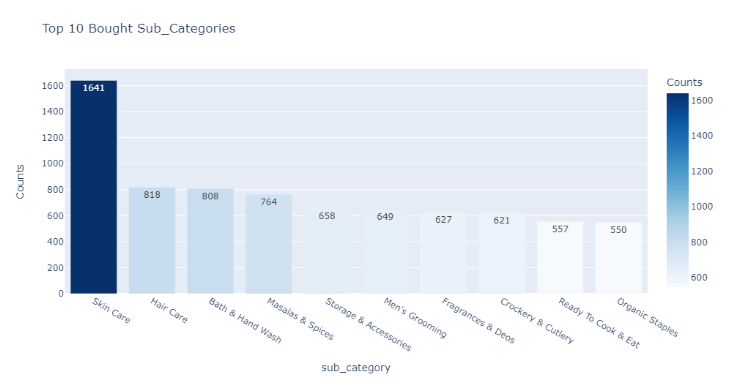
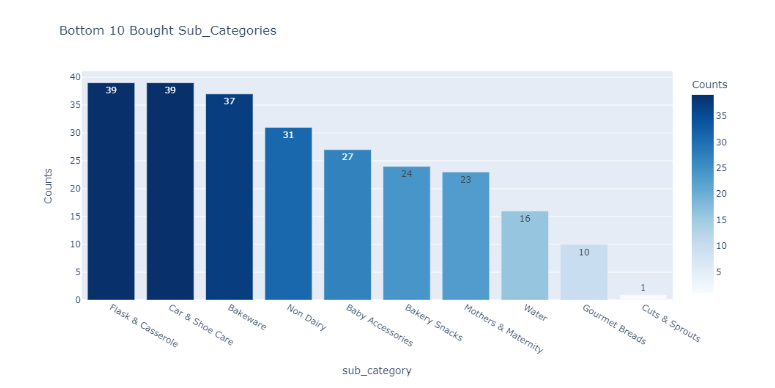
调查结果:
-
有77个唯一的sub_category值。
-
护肤品共有1641种产品。它占总产品组合的8.71%。
-
其次是护发产品,共有818种产品。它占总产品组合的4.34%。
-
Cuts&Sprouts的产品计数最低,为1个产品。它仅占总产品组合的0.01%。
品牌栏目分布
column = 'brand'
counts = df[column].value_counts()
count_percentage = df[column].value_counts(1)*100
counts_df = pd.DataFrame({column:counts.index,'Counts':counts.values,'Percent':np.round(count_percentage.values,2)})
print('unique '+str(column)+' values',df['sub_category'].nunique())
print('Top 10 '+str(column))
display(counts_df.head(10))
print('Bottom 10 '+str(column))
display(counts_df.tail(10))
px.bar(data_frame=counts_df.head(10),
x=column,
y='Counts',
color='Counts',
color_continuous_scale='blues',
text_auto=True,
title=f'Top 10 Brand Items based on Item Counts')
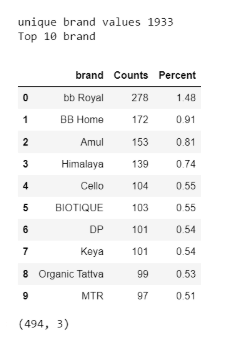
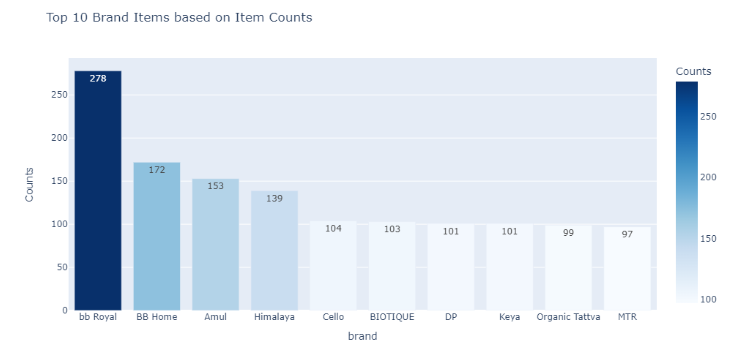
调查结果:
-
品牌有1933个独特价值。
-
有494个品牌拥有单一产品。
-
前两个品牌是Bigbarket。
-
bb Royal共有278种产品。它占总产品组合的1.48%。
-
第二大品牌是BB Home,拥有172种产品。它占总产品组合的0.91%。
查看类型列分布
column = 'type'
counts = df[column].value_counts()
count_percentage = df[column].value_counts(1)*100
counts_df = pd.DataFrame({column:counts.index,'Counts':counts.values,'Percent':np.round(count_percentage.values,2)})
print('unique '+str(column)+' values',df[column].nunique())
print('Top 10 '+str(column))
display(counts_df.head(10))
counts_df[counts_df['Counts']==1].shape
px.bar(data_frame=counts_df.head(10),
x='type',
y='Counts',
color='Counts',
color_continuous_scale='blues',
text_auto=True,
title=f'Top 10 Types of Products based on Item Counts')
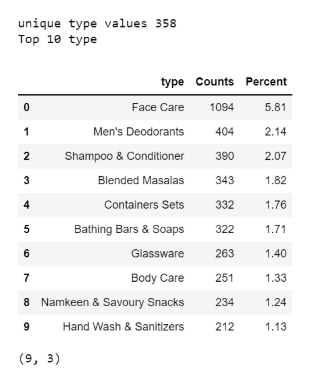
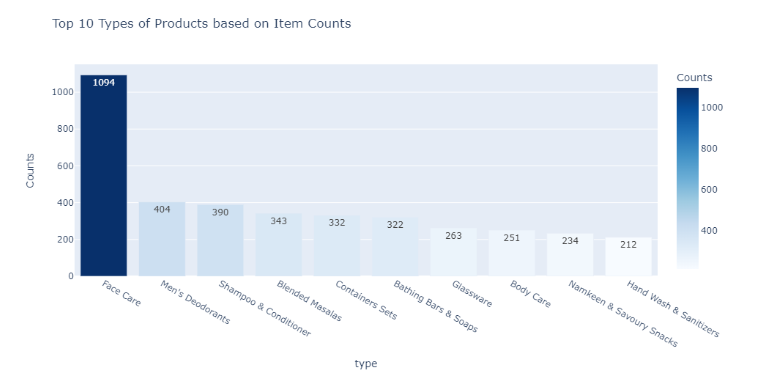
调查结果:
-
类型有358个唯一值。
-
有9种类型具有单一产品。
-
面部护理共有1094种产品。它占总产品组合的5.81%。
-
其次,最好的是男士除臭剂,有404种产品。它占总产品组合的2.14%。
评级分析
由于这是一个数字列,让我们看一下该列的直方图。
print(df['rating'].describe())
df['rating'].hist(bins=10)
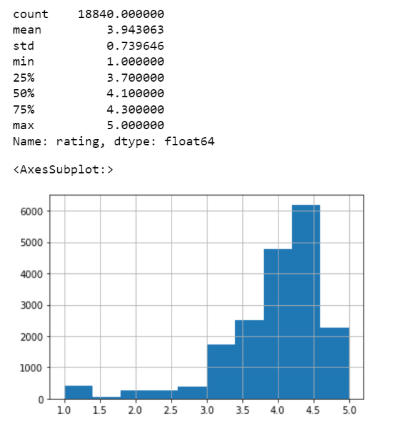
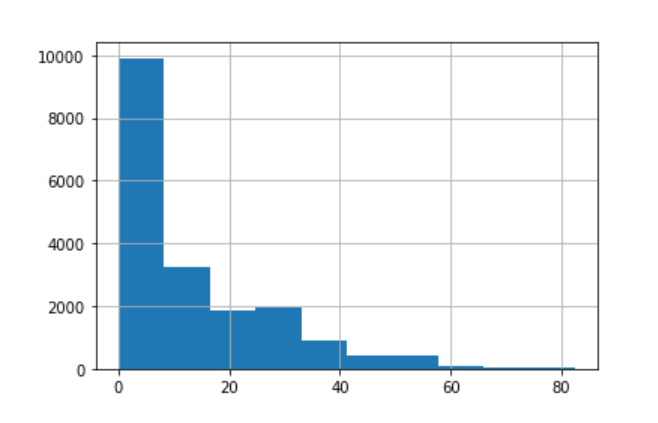
我们可以看到直方图向右倾斜,这意味着大多数产品的评级更高。
在0到1、1到2的间隔之间有多少评级,依此类推?
pd.cut(df.rating,bins = [0,1,2,3,4,5]).reset_index().groupby(['rating']).size()
输出:
rating
(0, 1] 387
(1, 2] 335
(2, 3] 1347
(3, 4] 6559
(4, 5] 10212
调查结果:
-
10212种产品的评级在4到5之间。
-
387种产品的评级介于0和1之间。
推荐系统的特征工程
在这里,我们可以创建新的功能来改进推荐。我们有销售价格和市场价格。让我们创建一个功能折扣%
公式=[(市场价格-销售价格)/销售价格]*100
df['discount'] = (df['market_price']-df['sale_price'])*100/df['market_price']
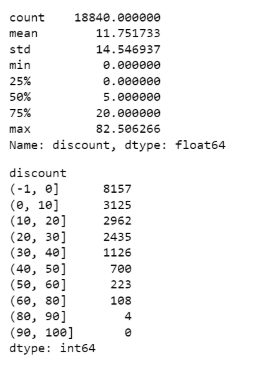
print(df['discount'].describe())
pd.cut(df.discount,bins = [-1,0,10,20,30,40,50,60,80,90,100]).reset_index().groupby(['discount']).size()
由于这是一个数字列,让我们看一下该列的直方图。
df['discount'].hist()
调查结果:
-
8157种产品没有任何折扣。
-
至少有4种产品有80%以上的折扣。
二元分析
评级和折扣之间有什么关系吗?
ax = df.plot.scatter(x='rating',y='discount')
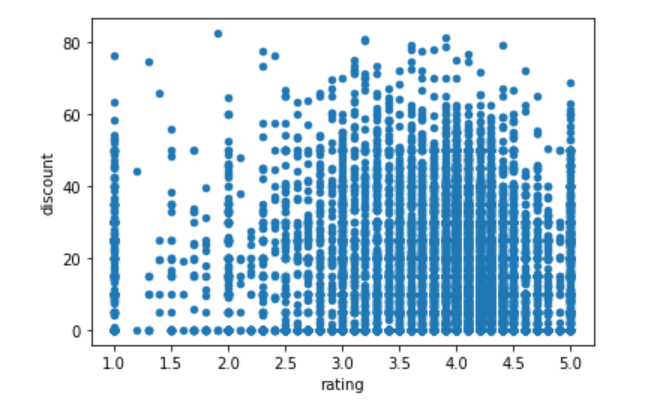
调查结果:从散点图来看,我们没有发现评级和折扣之间有任何关联。
让我们清理几个字符串列
类别栏包含“厨房、花园和宠物”我们将清理它,使它包含[厨房、花园、宠物]。类似的转换将应用于子类别、类型和品牌特征。
现在,让我们创建一个特性(product_classification_features),它附加了上述4个已清理的列。
df2 = df.copy()
rmv_spc = lambda a:a.strip()
get_list = lambda a:list(map(rmv_spc,re.split('& |, |*|n', a)))
for col in ['category', 'sub_category', 'type']:
df2[col] = df2[col].apply(get_list)
def cleaner(x):
if isinstance(x, list):
return [str.lower(i.replace(" ", "")) for i in x]
else:
if isinstance(x, str):
return str.lower(x.replace(" ", ""))
else:
return ''
for col in ['category', 'sub_category', 'type','brand']:
df2[col] = df2[col].apply(cleaner)
def couple(x):
return ' '.join(x['category']) + ' ' + ' '.join(x['sub_category']) + ' '+x['brand']+' ' +' '.join( x['type'])
df2['product_classification_features'] = df2.apply(couple, axis=1)
现在,我们已经准备好了数据。让我们为基于流行度的推荐构建一个简单的逻辑。我们将使用推荐源–type、category或sub_category。它将返回最受欢迎的产品或具有最高评级的产品。
def recomment_most_popular(col,col_value,top_n=5):
返回df[df[col]==col_value]。sort_values(by=‘rating’,升序=False)。head(top_n)[[product’,col,‘rating’]]
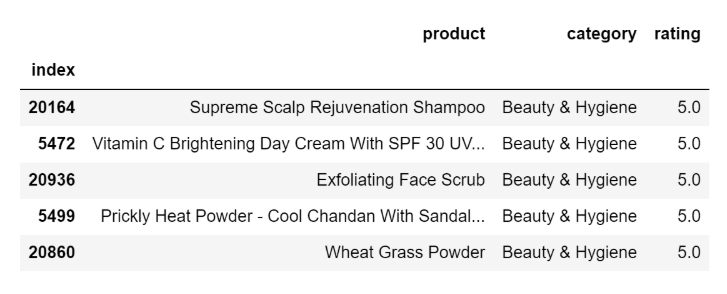
让我们看看最受欢迎的产品类别=美容与卫生
recommend_most_popular(col='category',col_value='Beauty & Hygiene')
让我们看看最受欢迎的sub_category=护发产品
recommend_most_popular(col='sub_category',col_value='Hair Care')

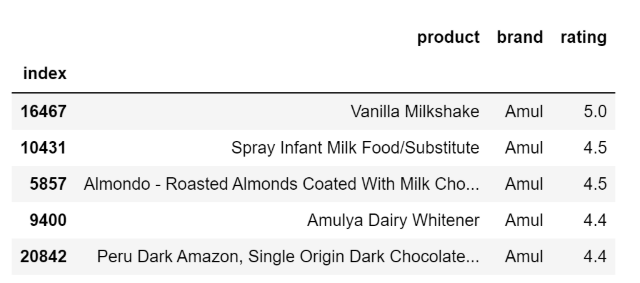
让我们看看品牌=Amul最受欢迎的产品
recommend_most_popular(col='brand',col_value='Amul')
让我们看看最受欢迎的type=面部护理产品
recommend_most_popular(col='type',col_value='Face Care')

让我们构建一个基于内容的推荐系统
顾名思义,这些算法使用我们想要推荐的产品的数据。E、 孩子们喜欢《玩具总动员1》电影。《玩具总动员》是皮克斯工作室制作的动画电影,因此系统可以推荐皮克斯工作室的其他动画电影,如《玩具总动员2》。例如,我们将使用产品元数据,如类别、子类别、类型、价格等。我们将根据这些功能从产品组合中提取类似产品。我们之前创建的功能(product_classification_features)在这里很有用。
我们将使用CountVector创建一个特征空间。
e、 例如,你有三句话:
s1=“拉姆是个男孩
s2=‘Ram良好
s3=“那男孩真好。”
因此,我们首先将它们转换为小写
s1=“拉姆是男孩”
s2=‘ram良好’
s3=‘那男孩真好’
因此,词汇表由{‘boy’、‘good’、‘is’、‘ram’、‘that’}作为独特的单词组成。
因此,当您使用CountVector时,它会创建5个特征,每个特征代表该单词的出现次数。
from sklearn.feature_extraction.text import CountVectorizer
from scipy.spatial import distance
vectorizer = CountVectorizer(lowercase=True)
X = vectorizer.fit_transform([s1,s2,s3])
X.toarray()
count_vect_df = pd.DataFrame(X.toarray(),columns=vectorizer.get_feature_names_out())
count_vect_df
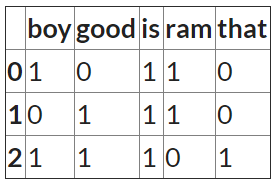
一旦我们有了这些向量,我们就可以使用下面的相似性度量来识别和推荐相似的产品
1.欧几里得距离:它测量两个向量之间的直线距离。
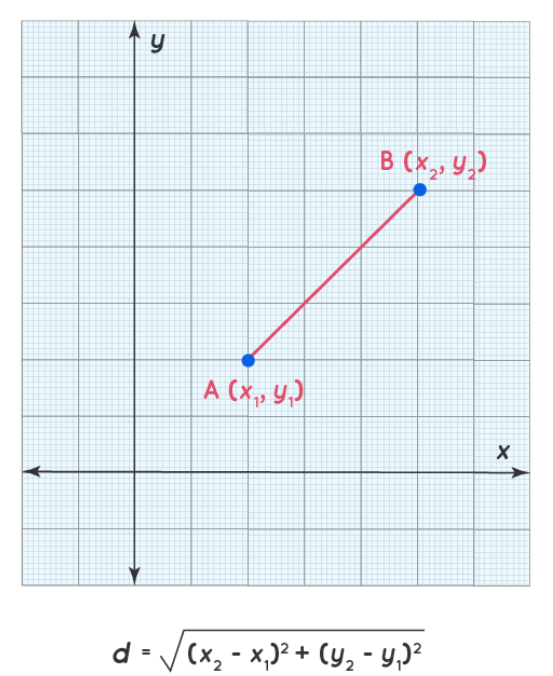
对于我们的示例,欧几里得距离如下所示:
distance.cdist(count_vect_df, count_vect_df, metric='euclidean').round(2)
输出:
array([[0. , 1. , 1.73],
[1. , 0. , 1.41],
[1.73, 1.41, 0. ]])
在上面的例子中,所有对角线条目都是0,这是直观的——每个句子的欧几里得距离都是0
-
s1和s2=1
-
s2和s3=1.41
-
s1和s3=1.73
因此,s1更接近s2
s2更接近s1
s3更接近s2
曼哈顿距离:它测量两个向量之间的绝对差。
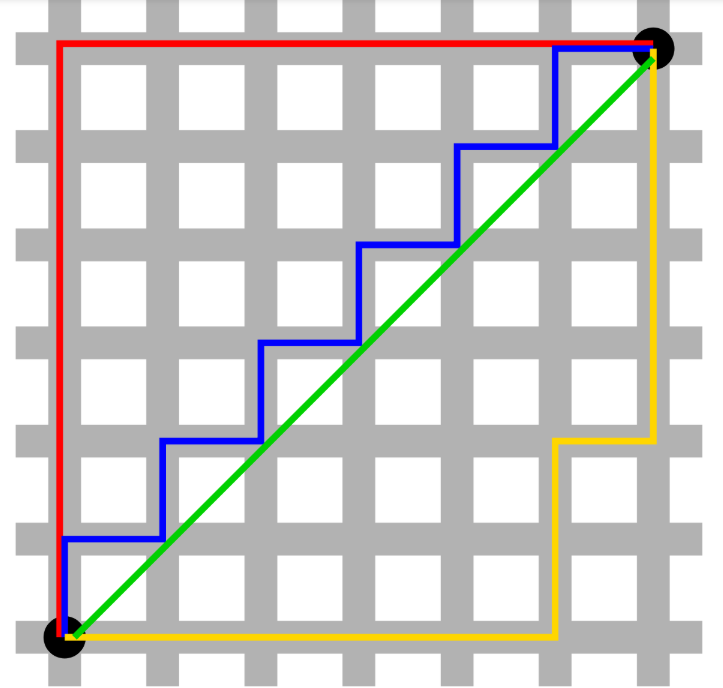
-
绿线表示欧几里得距离。
-
红色、蓝色和黄色线表示曼哈顿距离。
-
它是车辆从一个位置到达另一个位置的行驶路线。
对于我们的示例,曼哈顿距离如下所示:
distance.cdist(count_vect_df, count_vect_df, metric='cityblock').astype('int')
输出
array([[0, 2, 3],
[2, 0, 3],
[3, 3, 0]])
在上面的示例中,所有对角线条目均为0,这是直观的——每个句子与自身的曼哈顿距离为0。此外,每个句子之间的曼哈顿距离
-
s1和s2=2
-
s2和s3=3
-
s1和s3=3
因此,s1更接近s2
s2更接近s1
s3与s2和s1等距
Jaccard距离:它测量两个句子之间的常用词与这两个句子中的整体独特词的比率。
对于s1和s2,计算公式为
s1和s2=len({is’,ram})/len(}boy’,is’,‘ram’,good})=0.5
对于我们的示例,Jaccard距离如下所示:
distance.cdist(count_vect_df, count_vect_df, metric='jaccard').astype('int')
输出:
array([[0. , 0.5, 0.6],
[0.5, 0. , 0.6],
[0.6, 0.6, 0. ]])
那么,Jaccard和
-
s1和s2=0.5
-
s2和s3=0.6
-
s1和s3=0.6
因此,s1更接近s2
s2更接近s1
s3与s2和s1等距
余弦距离(或余弦相似性——我们将在本文中使用此度量)我们将使用余弦相似度来识别和推荐类似产品。
余弦相似性度量两个向量之间的角度。
余弦相似性可以给出-1到+1之间的值。值-1表示乘积相反或不相似,值+1表示两个乘积相同。
余弦相似性如下所示:
余弦相似性是1-余弦距离
1-distance.cdist(count_vect_df, count_vect_df, metric='cosine').round(2)
输出:
array([[1. , 0.67, 0.58],
[0.67, 1. , 0.58],
[0.58, 0.58, 1. ]])
在上面的例子中,所有对角线条目都是1,这是直观的——每个句子的余弦相似度都是1。
此外,两者之间的余弦相似性
-
s1和s2=0.67
-
s2和s3=0.58
-
s1和s3=0.58
因此,s1更接近s2
s2更接近s1
s3与s2和s1等距
让我们计算所有产品的product_classification_features的余弦相似度。
count = CountVectorizer(stop_words='english')
count_matrix = count.fit_transform(df2['product_classification_features'])
cosine_sim = cosine_similarity(count_matrix, count_matrix)
cosine_sim_df = pd.DataFrame(cosine_sim)
上述矩阵包含每个产品与目录中其他产品的余弦相似性。让我们使用余弦相似性构建一个推荐器
def content_recommendation_v1(title):
a = df2.copy().reset_index().drop('index',axis=1)
index = a[a['product']==title].index[0]
top_n_index = list(cosine_sim_df[index].nlargest(10).index)
try:
top_n_index.remove(index)
except:
pass
similar_df = a.iloc[top_n_index][['product']]
similar_df['cosine_similarity'] = cosine_sim_df[index].iloc[top_n_index]
return similar_df
让我们看看一些产品的建议。
title = 'Water Bottle - Orange'
content_recommendation_v1(title)
输出:
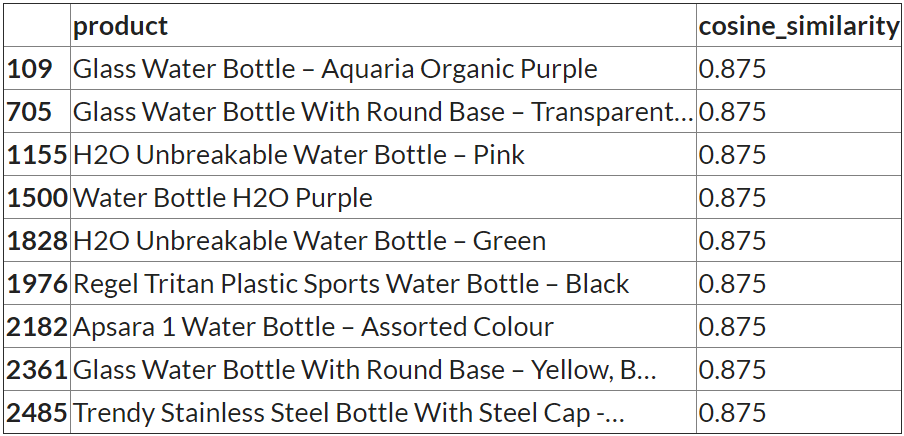
研究结果:即使在这里,我们也看到黑巧克力产品具有更高的相似性。
让我们运行更多产品的推荐。
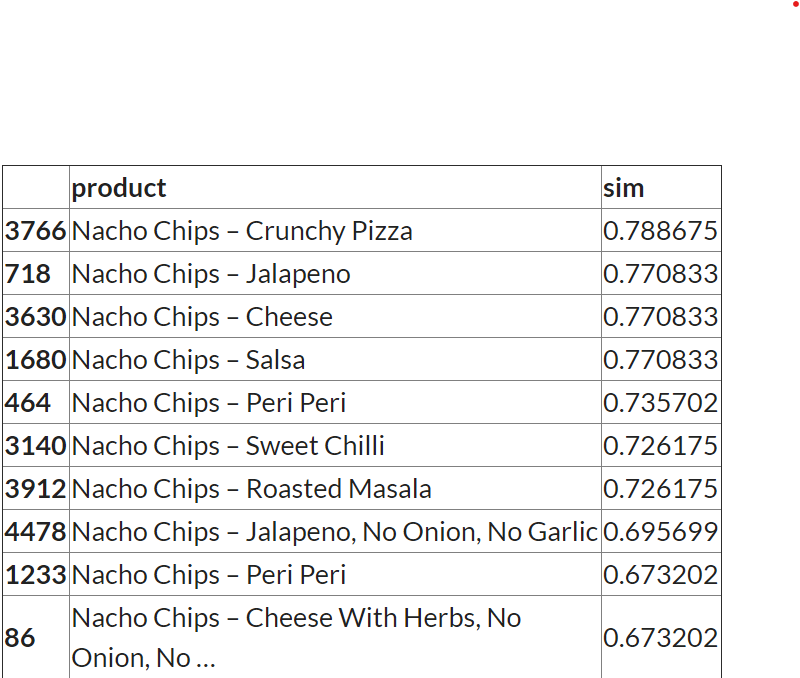
title = 'Nacho Round Chips'
content_recommendation_v2(title)
输出:
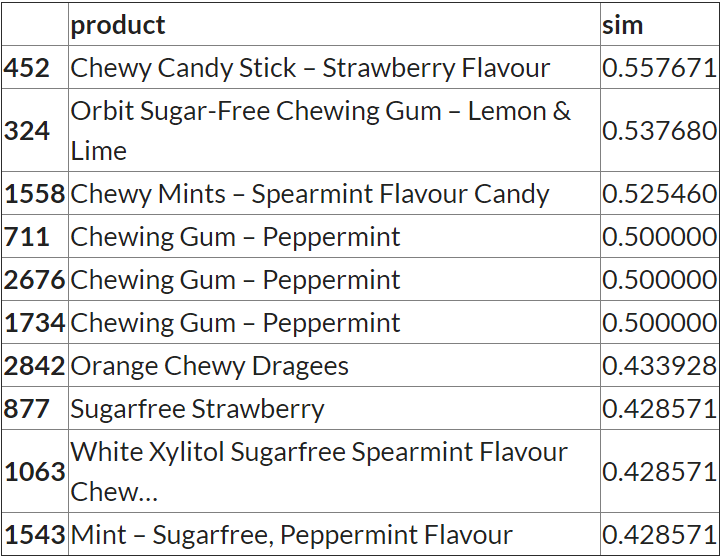
title = 'Chewy Mints - Lemon'
content_recommendation_v2(title)
输出:
title = 'Veggie - Fingers'
content_recommendation_v2(title)
输出:
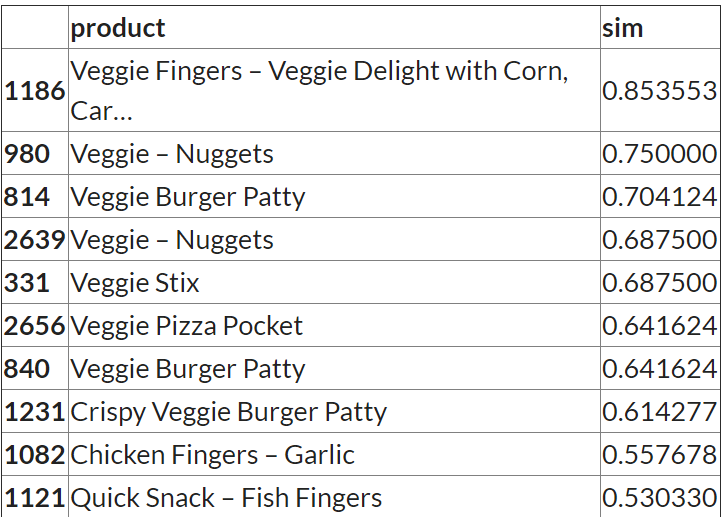
建议结果看起来相关。
使用NLP构建内容推荐系统值得称赞。
结论
像Amazon和Netflix这样的公司可以通过使用推荐系统获得大量收入。他们可以通过向现有客户推荐相关内容来吸引和留住现有客户。在本文中,我们看到了不同类型的推荐系统。然后,我们使用了一个公开可用的数据集,进行了彻底的EDA,并开发了一个基于内容的推荐系统。我们可以使用几个指标来识别产品之间的相似性。我们在推荐系统中使用了余弦相似性。
主要收获:
-
对于冷启动问题,我们应该使用基于流行度的推荐系统。推荐最受欢迎或最畅销的产品。这为所有用户提供了一般建议。
-
如果我们想向一组用户推荐类似的产品,我们可以使用基于内容的推荐系统。
-
一旦我们有了大量的用户偏好数据,我们就可以构建基于协作的推荐。这里,我们为每个用户提供个性化推荐。
我希望您喜欢这本关于构建内容推荐的指南。在下面的评论部分与我分享您的反馈。
如果你想和我讨论这个问题,请随时在LinkedIn上与我联系。
本文中显示的媒体并非Analytics Vidhya所有,由作者自行决定使用。
原文标题:Building a Content-Based Recommendation System
原文作者:Aakash93 Makwana
原文链接:https://www.analyticsvidhya.com/blog/2022/08/building-a-content-based-recommendation-system/
