





栗友们,大家好!我是Zarc
上期和大家分享了处理长文本序列的Transformer变种——Reformer,它主要引入了局部敏感哈希注意力和可逆Transformer两种方式来降低模型的注意力计算量,减少模型的复杂度,这期将带来本系列的最终篇,介绍处理长文本序列的Transformer变种模型中的Longformer和Big Bird。
01
—
Longformer
Longformer[1]是由艾伦人工智能研究院提出的一种基于稀疏注意力机制的模型,它可以将输入文本序列的最大长度扩充到4096,同时提出了三种稀疏注意力模式来降低复杂度,分别是滑动窗口注意力、扩张滑动窗口注意力和全局注意力,在上篇文章Reformer中讲到过全局注意力计算的必要性:
在传统的Transformer中,注意力矩阵的维度是 ,也就是一个以序列长度 为边长的方阵。也就是说,注意力矩阵的计算复杂度是随着序列长度呈平方级增长的,而这会极大限制模型对长文本的处理能力。
同时需要考虑的就是是否每个单词之间都需要计算注意力值?首先每个词与序列中的其他词之间的关联程度都不是均匀分布,而是只会对其中的一小部分词有较强的关联关系;另外实际上注意力机制中更关心的是经过 函数激活后的值,而不是激活前的值。通过 函数得到的结果主要取决于数值较大的若干元素,因此并不需要将所有的词都参与到注意力计算当中去。如果只计算那些与当前查询关联度最高的几个词,就可以极大降低注意力的计算量。
Longformer几种稀疏注意力模式
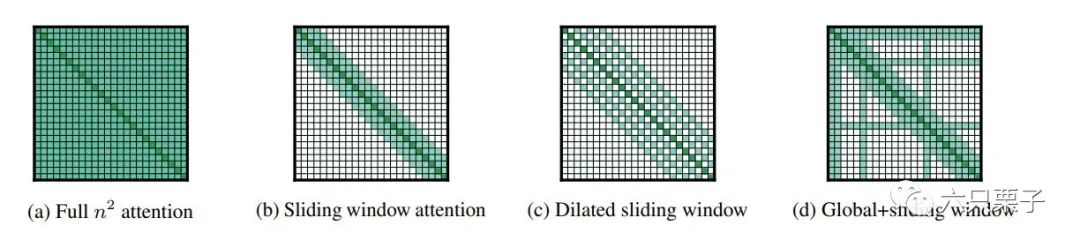
接下来看看这三种稀疏注意力模式:
滑动窗口注意力(图b)
如上文说到,在多数情况下,当前词只会和其相邻的若干个词之间存在一定的关联,因此对所有的词进行自注意力计算会存在一定的信息冗余。Longformer中引入了一种固定长度的滑动窗口注意力机制,使得每个词都只会与其左右相邻的 个词计算注意力。滑动窗口注意力机制可以将自注意力计算时的时空复杂度由 降低到 ,也就是它与输入序列的长度呈线性关系。
其实我仔细看了这种滑动窗口注意力机制,发现它和卷积神经网络的思想有点类似,在卷积神经网络中,卷积核很小,但是通过多个卷积层的叠加、池化等操作,最终可以获取到整个图形的特征信息,这里也是类似,虽然上述的滑动窗口计算出来的注意力是局部的,但是可以通过多个Transformer层的叠加,获取到更长距离的依赖信息,在一个深度为 层的 模型中,最顶层的词语的感受野是 。
扩张滑动窗口注意力(图c)
在上面的滑动窗口注意力中,可以发现感受野的大小与窗口宽度有很密切的关系,增加滑动窗口的宽度可以显著提升当前词的感受野,可以关注到更多的上下文信息,但是也会增加计算量,在这里,Longformer的解决办法是——扩张滑动窗口,这种方法也是借鉴了卷积神经网络中的扩张卷积思想。在扩张滑动窗口中,并不是利用窗口中所有的上下文信息,而是引入了扩张率 ,也就是说每隔 进行一次采样,在一个深度为 层的 模型中,最顶层的词语的感受野是 。
全局注意力(图d)
在预训练模型中,对于不同的任务,其输入的表示也是不同的。举个🌰,在掩码预训练模型中,模型利用局部上下文信息预测被掩码的单词是什么;在文本分类任务中,通常使用 为的表示来预测类别;对于文本匹配任务,需要将两段文本进行拼接,在通过多层Transformer来学习它们之间的联系。
然而,上述两种滑动窗口注意力模式是无法注意到任务特有的表示模式,因此,Longformer引入了全局注意力方法来使得模型特别关注一些被选中位置的词语信息,也让这些位置的词可以看到全局信息。在实际的应用中,可以根据任务特点设置全局注意力需要关注的位置。例如在文本分类任务中,可以设置 位置为全局可见;在问答类任务中,可以将所有的问题中的单词设置为全局可见。由于设置为全局可见的单词的长度远小于输入序列的长度,所以滑动窗口和全局注意力整体的计算复杂度还是 。
02
—
BigBird
Big Bird[2]也是谷歌公司推出的芝麻街新成员,它进一步优化了Transformer对于长文本的处理能力,也同样借鉴了稀疏注意力方法,如图所示:
Big Bird几种稀疏注意力模式
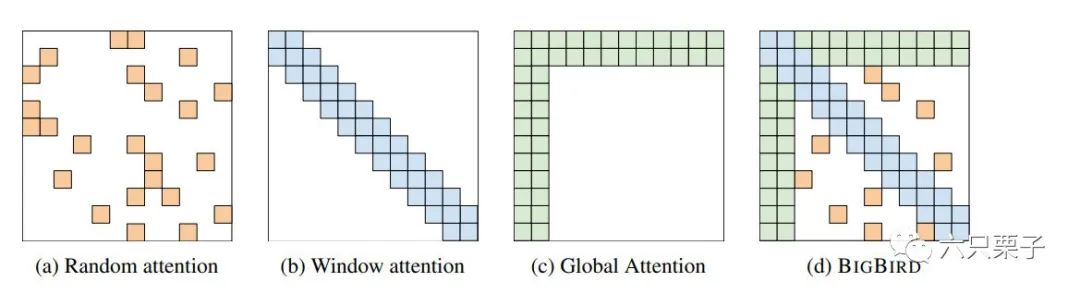
随机注意力:针对每个词,随机选取序列中的 个词参与注意力的计算,如图(a) 滑动窗口注意力:与上文的Longformer相同,只利用当前词周围的 个词计算注意力,如图(b) 全局注意力:与上文的Longformer相同,从输入序列中选择 个词,让其能够见到所有词的同时让所有词可以见到它,如图(c) Big Bird:结合了以上三种注意力模式,如图(d)
其实,我觉得Big Bird的思想还是比较容易理解的,里面的方法和Longformer也是比较相似,除此之外,论文中还提到了通过理论分析证明了稀疏Transformer的有效性,感兴趣的栗友们可以进一步阅读论文原文。
关于处理长文本序列的Transformer变种的介绍的最终篇到这里就结束啦!除了本文介绍的Longformer和Big Bird外,还有之前所提到的Transformer-XL和Reformer以及还没有介绍到的Set Transformer、Sparse Transformer、ETC、Performer和Linformer等模型变种,建议感兴趣的栗友们可以将它们比较阅读,欢迎大家一起交流讨论!呼~ 终于结束了
最后,关注六只栗子,面试不迷路!
作者 Zarc
编辑 一口栗子
参考资料
Longformer: https://arxiv.org/pdf/2004.05150.pdf
[2]Big Bird: https://arxiv.org/pdf/2007.14062.pdf




